Continuous-time Online Learning via Mean-Field Neural Networks: Regret Analysis in Diffusion Environments
Pith reviewed 2026-05-10 16:07 UTC · model grok-4.3
The pith
Mean-field neural networks achieve constant static regret for continuous-time online learning from diffusion data under displacement convexity, and explicit linear regret otherwise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The mean-field limit of non-anticipative parameter updates driven by diffusion data corresponds to a stochastic Wasserstein gradient flow adapted to the filtration; under displacement convexity this flow yields constant static regret, while in the non-convex case explicit linear regret bounds are obtained that isolate the effects of data variation, entropic exploration, and quadratic regularization. The analysis relies on the logarithmic Sobolev inequality, the Polyak-Lojasiewicz condition, Malliavin calculus, and uniform propagation of chaos to extend the bounds from the mean-field limit to finite-particle systems.
What carries the argument
the stochastic Wasserstein gradient flow adapted to the data filtration, which evolves the empirical measure of network parameters and permits regret control via functional inequalities
If this is right
- Constant regret independent of time horizon is attained whenever the loss is displacement convex.
- In non-convex regimes the linear growth rate is explicitly modulated by the size of data variation, the entropic exploration coefficient, and the strength of quadratic regularization.
- Finite-width networks inherit the same regret guarantees once uniform-in-time propagation of chaos is established.
- The results apply directly to any data stream whose law is a diffusion with fixed coefficients.
Where Pith is reading between the lines
- The same functional-inequality approach might extend regret analysis to data generated by other continuous-time processes such as jump diffusions, provided analogous Sobolev-type inequalities hold.
- Discretizing the mean-field flow could yield practical online algorithms whose performance tracks the continuous-time bounds for streaming neural-network training.
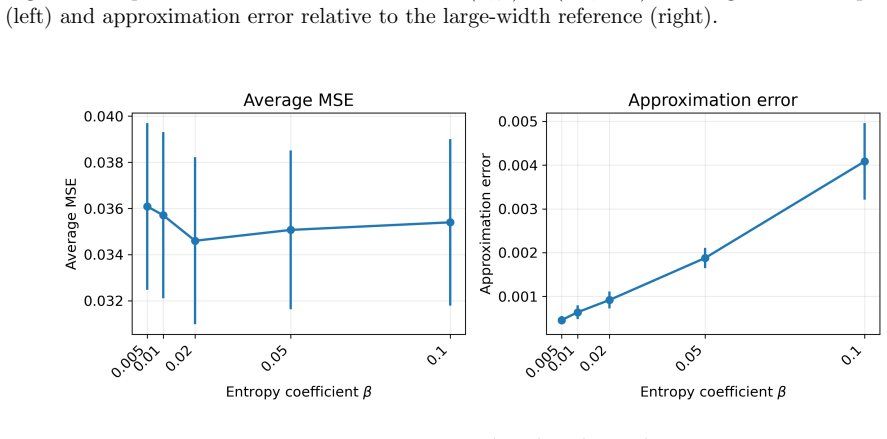
- The explicit dependence on regularization and width parameters supplies a guide for tuning finite networks on real diffusion-like data streams.
Load-bearing premise
The data must be generated by a diffusion process whose coefficients are unknown but fixed, and the loss must satisfy either displacement convexity or the Polyak-Lojasiewicz condition.
What would settle it
Empirical observation that regret grows faster than linear when diffusion coefficients vary arbitrarily or when the loss violates displacement convexity and the Polyak-Lojasiewicz condition would disprove the stated bounds.
Figures




read the original abstract
We study continuous-time online learning where data are generated by a diffusion process with unknown coefficients. The learner employs a two-layer neural network, continuously updating its parameters in a non-anticipative manner. The mean-field limit of the learning dynamics corresponds to a stochastic Wasserstein gradient flow adapted to the data filtration. We establish regret bounds for both the mean-field limit and finite-particle system. Our analysis leverages the logarithmic Sobolev inequality, Polyak-Lojasiewicz condition, Malliavin calculus, and uniform-in-time propagation of chaos. Under displacement convexity, we obtain a constant static regret bound. In the general non-convex setting, we derive explicit linear regret bounds characterizing the effects of data variation, entropic exploration, and quadratic regularization. Finally, our simulations demonstrate the outperformance of the online approach and the impact of network width and regularization parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies continuous-time online learning with data generated by a diffusion process with unknown but fixed coefficients. A two-layer neural network is updated continuously in a non-anticipative manner; its mean-field limit is a stochastic Wasserstein gradient flow. Regret bounds are derived for both the mean-field limit and the finite-particle system by combining the logarithmic Sobolev inequality, the Polyak-Łojasiewicz condition, Malliavin calculus, and uniform-in-time propagation of chaos. Under displacement convexity a constant static regret bound is obtained; in the general non-convex case explicit linear regret bounds are given that isolate the effects of data variation, entropic exploration, and quadratic regularization. Simulations illustrate the advantage of the online approach and the role of network width and regularization.
Significance. If the stated assumptions hold, the work supplies the first explicit regret guarantees for mean-field neural-network dynamics in a continuous-time diffusive environment, cleanly separating the contributions of convexity, data variation, and regularization. The technical toolkit (Malliavin calculus plus propagation of chaos) is appropriate and the distinction between the displacement-convex and PL regimes is useful. The results remain conditional on strong structural hypotheses whose validity for two-layer networks under diffusion measures is not established in the manuscript, which tempers the immediate scope of the contribution.
major comments (2)
- [Abstract] Abstract and the statement of the main theorems: the constant-regret claim under displacement convexity and the linear-regret claim in the non-convex case both rest on the standing assumption that the population loss satisfies displacement convexity or the Polyak-Łojasiewicz inequality with respect to the diffusion measure. The manuscript does not verify that the two-layer neural-network loss obeys either condition; if the assumption fails, the Gronwall-type estimates used to convert the continuous-time flow into a regret bound no longer close. This is load-bearing for both headline results.
- [Introduction / Model section] The analysis throughout invokes that the data-generating diffusion has time-independent coefficients. No argument is given that the regret bounds remain valid (or can be modified) when the diffusion coefficients vary with time in a non-diffusive manner, yet the title and abstract present the setting as general diffusion environments.
minor comments (2)
- [Main theorems] The dependence of the linear regret bound on the quadratic regularization strength and network width should be stated explicitly in the theorem statements rather than only in the simulation discussion.
- [Preliminaries] Notation for the stochastic Wasserstein gradient flow and the filtration-adapted processes is introduced without a consolidated table of symbols; this makes the propagation-of-chaos argument harder to follow.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. The comments raise important points about the assumptions underlying our regret bounds and the scope of the diffusion setting. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract and the statement of the main theorems: the constant-regret claim under displacement convexity and the linear-regret claim in the non-convex case both rest on the standing assumption that the population loss satisfies displacement convexity or the Polyak-Łojasiewicz inequality with respect to the diffusion measure. The manuscript does not verify that the two-layer neural-network loss obeys either condition; if the assumption fails, the Gronwall-type estimates used to convert the continuous-time flow into a regret bound no longer close. This is load-bearing for both headline results.
Authors: We thank the referee for highlighting this point. The main theorems are indeed stated under the assumption that the population loss satisfies either displacement convexity or the Polyak-Łojasiewicz (PL) inequality with respect to the underlying diffusion measure. This is explicitly noted in the statements of the main theorems. Verifying these structural properties for the specific two-layer neural network loss function under a general diffusion measure is a non-trivial task that depends on the choice of activation functions, network architecture, and the specific form of the loss; it lies beyond the scope of the current work, which focuses on deriving regret bounds conditional on these properties. We will revise the abstract and the introduction to more clearly state that the results hold under these assumptions, and add a discussion regarding the plausibility of these conditions for neural network losses in diffusive settings. revision: yes
-
Referee: [Introduction / Model section] The analysis throughout invokes that the data-generating diffusion has time-independent coefficients. No argument is given that the regret bounds remain valid (or can be modified) when the diffusion coefficients vary with time in a non-diffusive manner, yet the title and abstract present the setting as general diffusion environments.
Authors: The problem formulation in Section 2 explicitly assumes a diffusion process with time-independent coefficients, which enables the uniform-in-time propagation of chaos and the application of Malliavin calculus in the analysis. The title and abstract refer to 'diffusion environments' in this context, but we agree that greater precision is warranted to avoid misinterpretation. We will revise the abstract to specify 'time-homogeneous diffusion processes with unknown coefficients' and add a remark in the introduction clarifying the time-independence assumption, noting that extensions to time-varying coefficients are left for future research. revision: yes
- The verification that the two-layer neural-network loss satisfies displacement convexity or the Polyak-Łojasiewicz inequality with respect to the diffusion measure.
Circularity Check
Regret bounds derived from external inequalities and stated assumptions with no reduction to inputs by construction
full rationale
The derivation applies standard tools (logarithmic Sobolev, PL inequality, Malliavin calculus, uniform propagation of chaos) to the stochastic Wasserstein gradient flow under explicitly stated standing assumptions on the diffusion coefficients and on the loss (displacement convexity or PL). These assumptions are not derived from the two-layer NN model itself within the paper, nor are any regret quantities fitted to data and then relabeled as predictions. No self-citation chain is load-bearing for the central bounds, and no equation reduces to a prior equation by renaming or self-definition. The analysis is therefore self-contained against external analytic benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- network width
- quadratic regularization strength
axioms (2)
- domain assumption Data generated by a diffusion process with unknown coefficients
- domain assumption Loss satisfies displacement convexity or Polyak-Lojasiewicz condition
Reference graph
Works this paper leans on
-
[1]
Existence, uniqueness, and the uniformL ∞ bound.We use the fixed-point argument in Proposition 4.3 of Monmarch´ e et al. (2024). FixT∈(0,∞), and define X:=C [0, T];L 1(Rd)∩ P(R d) equipped with the uniform metric d(µ, ν) := sup t∈[0,T] ∥µt −ν t∥L1, forµ, ν∈ X. Ifµ∈ X, thenµ t is a probability measure and has a density function, still denoted byµ t. Clearl...
work page 2024
-
[2]
Uniform moment bound.We can calculate the expectation of the Lyapunov function Vk(θ) := (1 +|θ| 2)k/2. This gives a differential inequality for Z Rd Vk(θ)ρ t(dθ), from which we obtain the uniform bound on thek-th moment. The details are omitted here for simplicity
-
[3]
Define bε(µt, Zt, θ) =λθ+ 2 ⟨µt, σε(Xt,·)⟩ −Y t ∇σε(Xt, θ)
Stability with respect to the approximation.Letσ ε =σ∗η ε be the mollified function. Define bε(µt, Zt, θ) =λθ+ 2 ⟨µt, σε(Xt,·)⟩ −Y t ∇σε(Xt, θ). Thenb ε satisfies the same conditions asbin Monmarch´ e et al. (2024, Proposition A.1). It follows that ∥ρt −ρ ε t ∥L1 ≤e C′t∥ρ0 −ρ ε 0∥L1 +C ′√ tsup s∈[0,t] ∥b(ρs, Zs, θ)−b ε(ρε s, Zs, θ)∥L∞, whereρ ε is the uni...
work page 2024
-
[4]
Supposeφ t =φ 1,t +φ 2,t with boundedφ 1,t andL 2-Lipschitzφ 2,t for allt∈[0, T], then ∥∇ut∥L∞ ≤Ce −ct∥∇u0∥L∞ +C Z t 0 e−cs ∥φ1,t−s∥L∞ √ s∧1 +L 2 ds, t∈[0, T],(A.5) whereC,c >0and depend only onκ ˜b andβ
-
[5]
If additionally,∇φ t ∈L ∞ for allt∈[0, T], then ∥D2ut∥L∞ ≤ C′e−c′t √ t∧1 ∥∇u0∥L∞ + Z t 0 C′e−c′v √ v∧1 ∥∇φt−v∥L∞ +∥∇ ˜bt−v · ∇ut−v∥L∞ dv, (A.6) for allt∈[0, T], whereC ′,c ′ >0and depend only onκ ˜b,β,∥∇u 0∥L∞, andsup t∈[0,T] ∥φt∥L∞. Proof of Lemma A.1.A direct calculation shows thatu t satisfies ∂tut =β∆u t −β|∇u t|2 + ˜bt · ∇ut +φ t =β∆u t + inf α β|α|2...
work page 2016
-
[6]
Denoteu i(t) :=⟨ρ ∗ i , σ(Xt,·)⟩,i= 1,2
Note that Hi(θ) := λ 2β |θ|2 + 2 βT Z T 0 (⟨ρ∗ i , σ(Xt,·)⟩ −Y t)σ(X t, θ)dt=−logρ ∗ i (θ)−logA i, i= 1,2, whereA i is the normalization constant inρ ∗ i . Denoteu i(t) :=⟨ρ ∗ i , σ(Xt,·)⟩,i= 1,2. Then the first form ofH i implies that H1(θ)−H 2(θ) = 2 βT Z T 0 (u1(t)−u 2(t))σ(Xt, θ)dt. Multiplying both sides byρ ∗ 1 −ρ ∗ 2 and integrating overθ, Z (ρ∗ 1(...
work page 2008
-
[7]
Theb 1 term inA[F](ρ t, Zt)− A[F](µ ∗ t , Zt). |(Fx(ρt, Zt)−F x(µ∗ t , Zt))⊤b1| ≤2|b 1||⟨ρt, σ(Xt,·)⟩⟨ρ t, σx(Xt,·)⟩ − ⟨µ ∗ t , σ(Xt,·)⟩⟨µ ∗ t , σx(Xt,·)⟩| + 2Cz|b1||⟨ρt, σx(Xt,·)⟩ − ⟨µ ∗ t , σx(Xt,·)⟩|. Thanks to Assumption 3.1 and the strong duality of Wasserstein distance of order 1, we have |⟨ρt, σ(Xt,·)⟩⟨ρ t, σx(Xt,·)⟩ − ⟨µ ∗ t , σ(Xt,·)⟩⟨µ ∗ t , σx(...
-
[8]
Theb 2 term inA[F](ρ t, Zt)− A[F](µ ∗ t , Zt). We use|σ θ| ≤C 1 to obtain |(Fy(ρt, Zt)−F y(µ∗ t , Zt))b2| ≤2|b 2| |⟨ρt, σ(Xt,·)⟩ − ⟨µ ∗ t , σ(Xt,·)⟩| ≤2|b 2|C1W1(ρt, µ∗ t )
-
[9]
We need to bound 1 2tr[(Fxx(ρt, Zt)−F xx(µ∗ t , Zt))Σ1Σ⊤ 1 ]
The Σ 1Σ⊤ 1 term inA[F](ρ t, Zt)− A[F](µ ∗ t , Zt). We need to bound 1 2tr[(Fxx(ρt, Zt)−F xx(µ∗ t , Zt))Σ1Σ⊤ 1 ]. It suffices to bound the norm of the difference of the Hessian matrices. |Fxx(ρt, Zt)−F xx(µ∗ t , Zt)| ≤2|⟨ρ t, σ⟩⟨ρt, σxx⟩ − ⟨µ∗ t , σ⟩⟨µ∗ t , σxx⟩| + 2|⟨ρt, σx⟩⟨ρt, σx⟩⊤ − ⟨µ∗ t , σx⟩⟨µ∗ t , σx⟩⊤| + 2|Yt||⟨ρt, σxx⟩ − ⟨µ∗ t , σxx⟩|. We handle...
-
[10]
The Σ 1Σ⊤ 2 term inA[F](ρ t, Zt)− A[F](µ ∗ t , Zt). We have |tr[(Fyx(ρt, Zt)−F yx(µ∗ t , Zt))Σ1Σ⊤ 2 ]| ≤ |Σ1Σ⊤ 2 ||Fyx(ρt, Zt)−F yx(µ∗ t , Zt)| = 2|Σ1Σ⊤ 2 ||⟨ρt, σx⟩ − ⟨µ∗ t , σx⟩| ≤2|Σ 1Σ⊤ 2 |C2W1(ρt, µ∗ t )≤C 2(|Σ1Σ⊤ 1 |+|Σ 2Σ⊤ 2 |)W1(ρt, µ∗ t ). In the last inequality, we used|Σ 1Σ⊤ 2 | ≤ 1 2(|Σ1Σ⊤ 1 |+|Σ 2Σ⊤ 2 |). 51 For notational simplicity, we defi...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.