Cost-optimal Sequential Testing via Doubly Robust Q-learning
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
A doubly robust Q-learning framework learns cost-optimal sequential testing policies from retrospective data with informative missingness using path-specific weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a sequential missing-at-random mechanism, path-specific inverse probability weights that account for heterogeneous test trajectories and satisfy a conditional normalization property are combined with auxiliary contrast models to produce orthogonal pseudo-outcomes. These pseudo-outcomes enable unbiased estimation of the value of any sequential testing policy when either the acquisition model or the contrast model is correctly specified. The resulting Q-learning procedure yields oracle inequalities for the contrast estimators together with convergence rates, regret bounds, and misclassification rates for the learned policy.
What carries the argument
Path-specific inverse probability weights combined with auxiliary contrast models to generate orthogonal pseudo-outcomes inside a Q-learning recursion.
If this is right
- Unbiased policy learning holds if the acquisition model is correct, regardless of whether the contrast model is correct.
- Unbiased policy learning also holds if the contrast model is correct, regardless of whether the acquisition model is correct.
- Stage-wise contrast estimators satisfy oracle inequalities that translate into finite-sample regret bounds and misclassification rates for the learned policy.
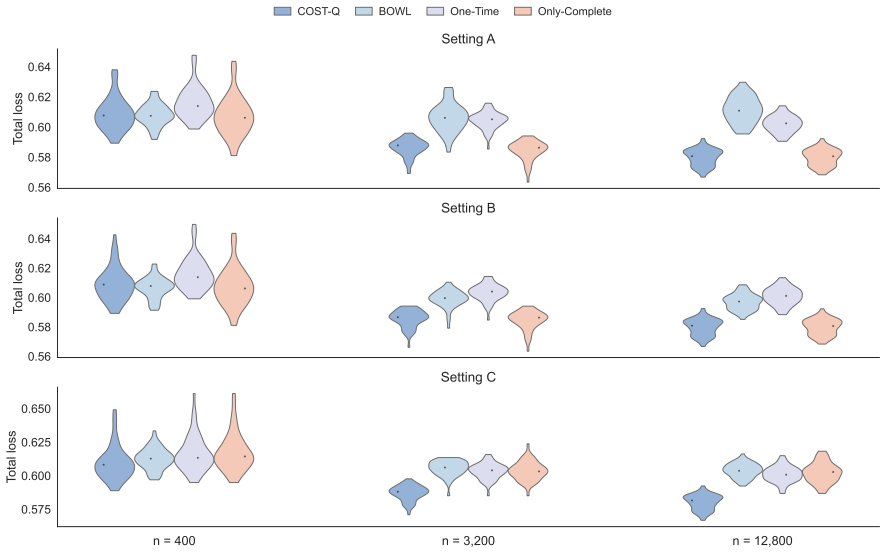
- The method produces lower cost-adjusted regret than inverse-probability-weighted or complete-case Q-learning in finite samples.
- In a prostate cancer cohort the procedure selects testing sequences that reduce total cost while maintaining the same level of predictive accuracy as more expensive policies.
Where Pith is reading between the lines
- The same weighting-and-contrast construction could be applied to other sequential decision problems that involve costly actions and history-dependent missingness, such as dynamic treatment regimes.
- The conditional normalization property of the path-specific weights may simplify variance estimation and enable scalable computation when the number of possible test sequences grows large.
- Combining the orthogonal pseudo-outcomes with modern function approximators such as neural networks would produce a doubly robust deep Q-learning variant for high-dimensional clinical state spaces.
Load-bearing premise
Test missingness follows a sequential missing-at-random process that depends only on the observed history up to each stage.
What would settle it
A simulation in which missingness depends on unobserved factors shows that the policy regret of the doubly robust estimator does not converge to zero at the stated rate even when one of the two models is correctly specified.
Figures


read the original abstract
Clinical decision-making often involves selecting tests that are costly, invasive, or time-consuming, motivating individualized, sequential strategies for what to measure and when to stop ascertaining. We study the problem of learning cost-optimal sequential decision policies from retrospective data, where test availability depends on prior results, inducing informative missingness. Under a sequential missing-at-random mechanism, we develop a doubly robust Q-learning framework for estimating optimal policies. The method introduces path-specific inverse probability weights that account for heterogeneous test trajectories and satisfy a normalization property conditional on the observed history. By combining these weights with auxiliary contrast models, we construct orthogonal pseudo-outcomes that enable unbiased policy learning when either the acquisition model or the contrast model is correctly specified. We establish oracle inequalities for the stage-wise contrast estimators, along with convergence rates, regret bounds, and misclassification rates for the learned policy. Simulations demonstrate improved cost-adjusted performance over weighted and complete-case baselines, and an application to a prostate cancer cohort study illustrates how the method reduces testing cost without compromising predictive accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a doubly robust Q-learning framework for estimating cost-optimal sequential testing policies from retrospective data with informative missingness induced by prior test results. Under a sequential missing-at-random mechanism, it introduces path-specific inverse probability weights that account for heterogeneous trajectories and satisfy a normalization property conditional on observed history; these are combined with auxiliary contrast models to form orthogonal pseudo-outcomes enabling unbiased policy learning when either the acquisition or contrast model is correctly specified. Theoretical contributions include oracle inequalities for stage-wise contrast estimators, convergence rates, regret bounds, and misclassification rates for the learned policy, with supporting simulations and an application to a prostate cancer cohort.
Significance. If the central doubly robust construction and associated bounds hold, the work provides a practically relevant extension of Q-learning and doubly robust estimation to sequential testing problems with cost considerations and missingness. The path-specific weights and normalization property address a key challenge in heterogeneous trajectories, and the provision of regret and misclassification guarantees strengthens the case for deployment in clinical decision support. Simulations and the real-data illustration offer concrete evidence of improved cost-adjusted performance over baselines.
major comments (2)
- [Assumptions and Method] The unbiasedness and orthogonality of the pseudo-outcomes (central to all subsequent oracle inequalities, regret bounds, and misclassification rates) are derived under the sequential missing-at-random assumption. No sensitivity analysis or robustness result is provided for violations where missingness depends on unobserved factors at any stage; this is load-bearing because misspecification of the acquisition probabilities would invalidate the weights and break the double-robustness property even if the contrast model is correct.
- [Theoretical Results] The normalization property of the path-specific IPW conditional on observed history is invoked to construct the orthogonal pseudo-outcomes, but the theoretical analysis should explicitly verify that this property propagates through the stage-wise recursion to guarantee that the expectation of the pseudo-outcome equals the true Q-function (or contrast) under correct specification of either model.
minor comments (2)
- [Simulations] The simulation section would benefit from additional detail on the data-generating process for heterogeneous test trajectories and the specific forms of the acquisition and contrast models used in the baselines.
- [Application] In the prostate cancer application, reporting quantitative cost reductions alongside confidence intervals or p-values for the predictive accuracy comparison would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which highlight important aspects of our doubly robust framework. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Assumptions and Method] The unbiasedness and orthogonality of the pseudo-outcomes (central to all subsequent oracle inequalities, regret bounds, and misclassification rates) are derived under the sequential missing-at-random assumption. No sensitivity analysis or robustness result is provided for violations where missingness depends on unobserved factors at any stage; this is load-bearing because misspecification of the acquisition probabilities would invalidate the weights and break the double-robustness property even if the contrast model is correct.
Authors: We agree that the sequential missing-at-random assumption is foundational to the unbiasedness and double robustness of the pseudo-outcomes. The manuscript derives all theoretical guarantees under this assumption and does not include sensitivity analyses for violations involving unobserved factors. In the revised version, we will add a new subsection in the Discussion that explicitly acknowledges this limitation, explains the potential impact on the acquisition model and weights, and outlines possible future extensions such as sensitivity parameters or alternative robust estimation strategies. revision: yes
-
Referee: [Theoretical Results] The normalization property of the path-specific IPW conditional on observed history is invoked to construct the orthogonal pseudo-outcomes, but the theoretical analysis should explicitly verify that this property propagates through the stage-wise recursion to guarantee that the expectation of the pseudo-outcome equals the true Q-function (or contrast) under correct specification of either model.
Authors: We appreciate this observation. While the normalization property is used to establish the form of the orthogonal pseudo-outcomes and is implicitly relied upon in the stage-wise derivations, the manuscript does not contain an explicit recursive verification across stages. In the revision, we will expand the relevant lemma and proof (in the section on orthogonal pseudo-outcomes and oracle inequalities) to include a direct inductive argument showing that the normalization holds conditionally on the observed history at each stage, thereby confirming that the expectation of the pseudo-outcome recovers the true contrast when either model is correctly specified. revision: yes
Circularity Check
No circularity: standard doubly robust construction with independent theory
full rationale
The paper adapts established doubly robust Q-learning to sequential testing under a sequential missing-at-random assumption. Path-specific IPW and orthogonal pseudo-outcomes are constructed from auxiliary models in the usual way; the resulting oracle inequalities, convergence rates, and regret bounds are derived from standard concentration and empirical process arguments rather than by re-expressing the target policy value as a fitted quantity. No self-citation chain, self-definitional step, or fitted-input-renamed-as-prediction appears in the derivation. The framework is self-contained against external benchmarks once the MAR mechanism is granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption sequential missing-at-random mechanism
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under a sequential missing-at-random mechanism, we develop a doubly robust Q-learning framework... path-specific inverse probability weights... orthogonal pseudo-outcomes... E[E_s] < ∞ and treat C_s as pre-calibrated
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Assumption 1 (Sequential MAR)... Assumption 2 (Positivity)... oracle inequalities... regret bounds
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anderson, G. F., P. Hussey, and B. Varkey (2019). It’s still the prices, stupid: Why the us spends so much on health care, and a tribute to uwe reinhardt.Health Affairs 38(1), 7–11. Bang, H. and J. M. Robins (2005). Doubly robust estimation in missing data and causal inference models.Biometrics 61(4), 962–973. 26 Blumenthal, D., E. D. Gumas, A. Shah, M. Z...
work page 2019
-
[2]
Lloyd-Jones, D. M., L. T. Braun, C. E. Ndumele, S. C. Smith, L. S. Sperling, S. S. Virani, and R. S. Blumenthal (2019). Use of risk assessment tools to guide decision-making in the primary prevention of atherosclerotic cardiovascular disease: a special report from the american heart association and american college of cardiology.Journal of the American Co...
work page 2019
-
[3]
Stone, C. J. (1982). Optimal global rates of convergence for nonparametric regression.The Annals of Statistics 10(4), 1040 –
work page 1982
-
[4]
28 Sutton, R. S., A. G. Barto, et al. (1998).Introduction to Reinforcement Learning, Volume
work page 1998
-
[5]
MIT press Cambridge. Szepesv´ ari, C. (2022).Algorithms for Reinforcement Learning. Springer nature. Thompson, I. M., D. P. Ankerst, C. Chi, P. J. Goodman, C. M. Tangen, M. S. Lucia, Z. Feng, H. L. Parnes, and C. A. Coltman Jr (2006). Assessing prostate cancer risk: results from the prostate cancer prevention trial.Journal of the National Cancer Institute...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.