An Underexplored Frontier: Large Language Models for Rare Disease Patient Education and Communication -- A scoping review
Pith reviewed 2026-05-14 21:55 UTC · model grok-4.3
The pith
Scoping review shows LLM use for rare disease patient education stays early and narrow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
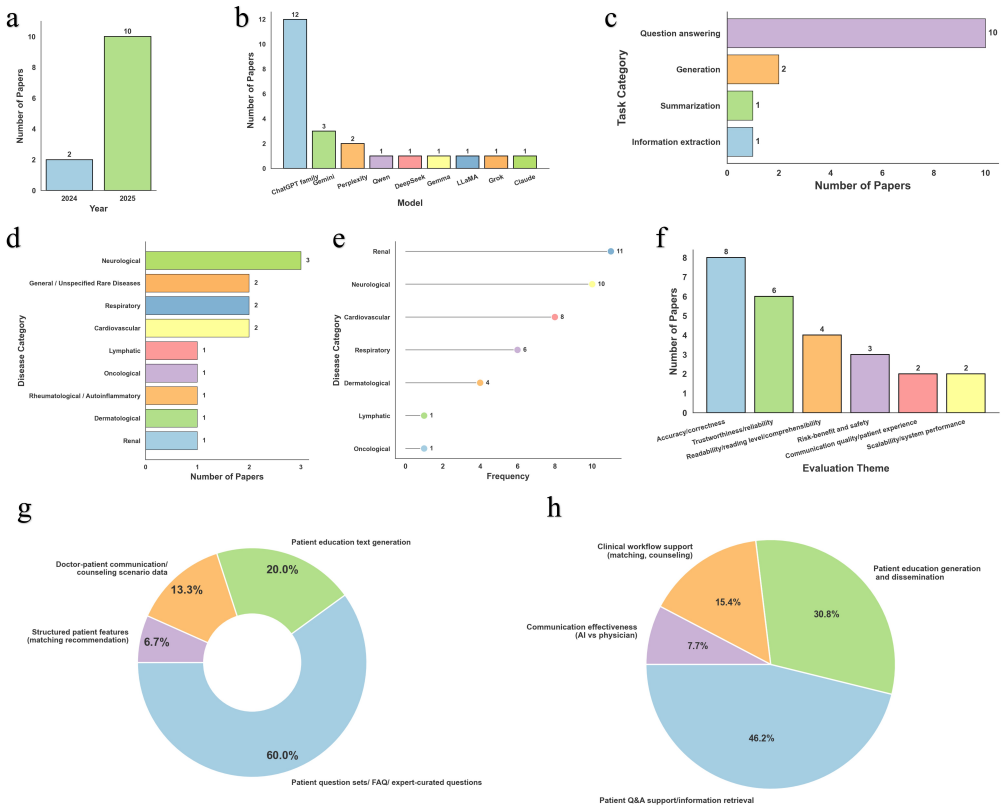
The literature is highly recent and dominated by general-purpose models, particularly ChatGPT. Most studies focus on patient question answering using curated question sets, with limited use of real-world data or longitudinal communication scenarios. Evaluations are primarily centered on accuracy, with limited attention to patient-centered dimensions such as readability, empathy, and communication quality. Multilingual communication is rarely addressed. Overall, the field remains at an early stage.
What carries the argument
The scoping review that located and analyzed 12 studies, extracting details on application scenarios, model types, and evaluation approaches.
If this is right
- Patient-centered design must be added to future work so responses address readability, empathy, and overall communication quality.
- Domain-adapted models should replace reliance on general-purpose systems like ChatGPT.
- Real-world testing with actual patient data and ongoing scenarios is required for safe deployment.
- Multilingual capabilities need explicit development to serve diverse patient populations.
Where Pith is reading between the lines
- Filling these gaps could let LLMs reduce isolation for patients who lack easy access to specialists during extended care journeys.
- Similar evaluation shortfalls may appear when LLMs are applied to other low-prevalence or complex medical topics.
- Direct trials that compare accuracy scores against patient-reported outcomes would test whether current metrics predict practical benefit.
- Specialized training on rare-disease knowledge bases could produce more reliable outputs than general models alone.
Load-bearing premise
The search across major databases from January 2022 to March 2026 captured every relevant study on LLM-based rare disease patient education and communication without major omissions from database limits or keyword choices.
What would settle it
A later or broader search that locates many additional studies using specialized models, real patient records, longitudinal interactions, or evaluations of empathy and readability would show the field is further along than the review concludes.
Figures

read the original abstract
Rare diseases affect over 300 million people worldwide and are characterized by complex care pathways, limited clinical expertise, and substantial unmet communication needs throughout the long patient journey. Recent advances in large language models (LLMs) offer new opportunities to support patient education and communication, yet their application in rare diseases remains unclear. We conducted a scoping review of studies published between January 2022 and March 2026 across major databases, identifying 12 studies on LLM-based rare disease patient education and communication. Data were extracted on study characteristics, application scenarios, model usage, and evaluation methods, and synthesized using descriptive and qualitative analyses. The literature is highly recent and dominated by general-purpose models, particularly ChatGPT. Most studies focus on patient question answering using curated question sets, with limited use of real-world data or longitudinal communication scenarios. Evaluations are primarily centered on accuracy, with limited attention to patient-centered dimensions such as readability, empathy, and communication quality. Multilingual communication is rarely addressed. Overall, the field remains at an early stage. Future research should prioritize patient-centered design, domain-adapted methods, and real-world deployment to support safe, adaptive, and effective communication in rare diseases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a scoping review of LLM applications for rare disease patient education and communication. It searched major databases from January 2022 to March 2026, identified 12 studies, extracted data on characteristics, scenarios, models, and evaluations, and used descriptive/qualitative synthesis to conclude that the literature is recent and ChatGPT-dominated, focuses on curated QA sets with accuracy-centric evaluations, shows limited real-world/longitudinal or patient-centered elements (e.g., empathy, readability), and remains at an early stage with recommendations for future patient-centered and domain-adapted work.
Significance. If the 12-study sample is representative, the review usefully maps an emerging area relevant to over 300 million people with rare diseases, where communication needs are high. It provides a clear baseline by documenting model preferences, scenario limitations, and evaluation gaps, which can guide subsequent research toward safer, more adaptive LLM tools. The scoping design is appropriate for this nascent topic.
major comments (2)
- [Methods] Methods: The search process is described only at a high level (major databases, January 2022–March 2026) with no explicit search strings, keyword/MeSH combinations, database list, inclusion/exclusion criteria, or PRISMA flow diagram. This makes it impossible to verify the completeness of the 12-study count or rule out omissions from synonym coverage or indexing, which directly affects the reliability of the headline synthesis on model dominance, scenario focus, and evaluation practices.
- [Results] Results: The claims that 'most studies focus on patient question answering using curated question sets' and 'evaluations are primarily centered on accuracy' with 'limited attention to patient-centered dimensions' are presented without a supporting table or breakdown (e.g., counts or percentages across the 12 studies for each metric). This weakens the ability to assess the strength and distribution of these patterns.
minor comments (1)
- [Abstract] The search end date of March 2026 should be clarified (e.g., whether it reflects a planned cutoff or requires updating), as it affects the currency of the review.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our scoping review and for the constructive suggestions for minor revisions. We have carefully considered the comments on the Methods and Results sections and will incorporate the recommended changes to improve the manuscript's transparency and clarity.
read point-by-point responses
-
Referee: [Methods] Methods: The search process is described only at a high level (major databases, January 2022–March 2026) with no explicit search strings, keyword/MeSH combinations, database list, inclusion/exclusion criteria, or PRISMA flow diagram. This makes it impossible to verify the completeness of the 12-study count or rule out omissions from synonym coverage or indexing, which directly affects the reliability of the headline synthesis on model dominance, scenario focus, and evaluation practices.
Authors: We agree that a more detailed description of the search process is necessary to ensure the review's reproducibility. In the revised manuscript, we will provide the explicit search strings and keyword combinations used in each database, a complete list of the databases searched, the full inclusion and exclusion criteria, and a PRISMA flow diagram illustrating the identification and selection of the 12 studies. This will enable verification of the search strategy and support the reliability of our findings on model usage and evaluation practices. revision: yes
-
Referee: [Results] Results: The claims that 'most studies focus on patient question answering using curated question sets' and 'evaluations are primarily centered on accuracy' with 'limited attention to patient-centered dimensions' are presented without a supporting table or breakdown (e.g., counts or percentages across the 12 studies for each metric). This weakens the ability to assess the strength and distribution of these patterns.
Authors: We appreciate this observation and agree that quantitative breakdowns would strengthen the results section. We will add a summary table to the revised manuscript that reports the number and percentage of studies for each category of application scenario (e.g., curated question-answering), model type (e.g., ChatGPT), and evaluation focus (accuracy vs. patient-centered metrics such as empathy and readability). This table will provide the requested counts and percentages, allowing readers to better evaluate the distribution and strength of the observed patterns. revision: yes
Circularity Check
No significant circularity in descriptive scoping review synthesis
full rationale
This is a scoping review that performs descriptive and qualitative synthesis of 12 external studies identified via database search. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The central claims (recent literature, ChatGPT dominance, curated QA focus, accuracy-centric evaluation) are direct summaries of the included papers rather than results that reduce to the paper's own inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. The search methodology is stated as a standard scoping process (Jan 2022–Mar 2026 across major databases) without any internal loop that would make the count or gap analysis circular.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard scoping review methodology following established guidelines for literature identification and synthesis
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We conducted a scoping review of studies published between January 2022 and March 2026 across major databases, identifying 12 studies on LLM-based rare disease patient education and communication.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Evaluations are primarily centered on accuracy, with limited attention to patient-centered dimensions such as readability, empathy, and communication quality.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The landscape for rare diseases in 2024,
The Lancet Global Health, “The landscape for rare diseases in 2024,” The Lancet Global Health, vol. 12, no. 3, p. e341, 2024. [Online]. Available: https://doi.org/10.1016/S2214-109X(24)00056-1
-
[2]
100,000 genomes pilot on rare-disease diagnosis in health care—preliminary report,
G. P. P. I. 100, “100,000 genomes pilot on rare-disease diagnosis in health care—preliminary report,”New England Journal of Medicine, vol. 385, no. 20, pp. 1868–1880, 2021
work page 2021
-
[3]
The diagnostic odyssey: insights from parents of children living with an undiagnosed condition,
A. Bauskis, C. Strange, C. Molster, and C. Fisher, “The diagnostic odyssey: insights from parents of children living with an undiagnosed condition,”Orphanet journal of rare diseases, vol. 17, no. 1, p. 233, 2022
work page 2022
-
[4]
D. Gunes, M. Karaca, A. Durmus, B. Ak, N. Aktay Ayaz, Z. Altınel, A. Aslanger, F. Atalar, M. Balci, L. Bilginet al., “Challenges in the clinical management of rare diseases and center-based multidisciplinary approach to creating solutions,”European Journal of Pediatrics, vol. 184, no. 5, p. 281, 2025
work page 2025
-
[5]
L. Devisetti, “Embracing the unknown: investigating medical commu- nication around uncertainty and the implications on patient and family well-being,”Orphanet Journal of Rare Diseases, vol. 19, no. 1, p. 37, 2024
work page 2024
-
[6]
Patient passports for rare diseases: results of a pilot study,
J. Balfour, V . Morrison, L. Seed, J. Clymer, E. Warnants, A. Lampkin, S. M. Leiter, and G. Chandratillake, “Patient passports for rare diseases: results of a pilot study,”European Journal of Human Genetics, vol. 34, no. 1, pp. 99–107, 2026
work page 2026
-
[7]
Reimagining care of people living with rare diseases with artificial intelligence,
T. Groza, G. Baynam, and S. S. Jamuar, “Reimagining care of people living with rare diseases with artificial intelligence,”Plos Medicine, vol. 23, no. 2, p. e1004966, 2026
work page 2026
-
[8]
Rare disease research: breaking the privacy barrier,
D. Mascalzoni, A. Paradiso, and M. Hansson, “Rare disease research: breaking the privacy barrier,”Applied & Translational Genomics, vol. 3, no. 2, pp. 23–29, 2014
work page 2014
-
[9]
V . L. Merker, S. R. Plotkin, M. P. Charns, M. Meterko, J. T. Jordan, and A. R. Elwy, “Effective provider-patient communication of a rare disease diagnosis: A qualitative study of people diagnosed with schwannomato- sis,”Patient education and counseling, vol. 104, no. 4, pp. 808–814, 2021
work page 2021
-
[10]
K. A. Cribbs, L. T. Blackmore, A. R. Banks, D. S. Kim, and B. J. Lahue, “Capturing real-world rare disease patient journeys: Are current methodologies sufficient for informed healthcare decisions?”Journal of Evaluation in Clinical Practice, vol. 31, no. 1, p. e70010, 2025
work page 2025
-
[11]
A scoping review of health literacy in rare disorders: key issues and research directions,
U. Stenberg, L. Westfal, A. Dybesland Rosenberger, K. Ørstavik, M. Flink, H. Holmen, S. Systad, K. F. Westermann, and G. Velvin, “A scoping review of health literacy in rare disorders: key issues and research directions,”Orphanet Journal of Rare Diseases, vol. 19, no. 1, p. 328, 2024
work page 2024
-
[12]
Global health for rare diseases through primary care,
G. Baynam, A. L. Hartman, M. C. V . Letinturier, M. Bolz-Johnson, P. Carrion, A. C. Grady, X. Dong, M. Dooms, L. Dreyer, H. Graessner et al., “Global health for rare diseases through primary care,”The Lancet Global Health, vol. 12, no. 7, pp. e1192–e1199, 2024
work page 2024
-
[13]
Large language models for disease diagnosis: A scoping review,
S. Zhou, Z. Xu, M. Zhang, C. Xu, Y . Guo, Z. Zhan, Y . Fang, S. Ding, J. Wang, K. Xuet al., “Large language models for disease diagnosis: A scoping review,”npj Artificial Intelligence, vol. 1, no. 1, p. 9, 2025
work page 2025
-
[14]
Z. Zhan, S. Zhou, M. Li, and R. Zhang, “Ramie: retrieval-augmented multi-task information extraction with large language models on dietary supplements,”Journal of the American Medical Informatics Association, vol. 32, no. 3, pp. 545–554, 2025
work page 2025
-
[15]
N. Ghenimi, R. Govender, and K. Moodley, “The paradox of artificial intelligence (ai) and narrative-based medicine: challenges and potential for enhanced patient care,”AI & SOCIETY, pp. 1–7, 2025
work page 2025
-
[16]
Benchmark- ing gpt-5 for biomedical natural language processing,
Y . Hou, Z. Zhan, M. Zeng, Y . Wu, S. Zhou, and R. Zhang, “Benchmark- ing gpt-5 for biomedical natural language processing,”arXiv preprint arXiv:2509.04462, 2025
-
[17]
M. Zeng, S. Zhou, Z. Zhan, and R. Zhang, “Medcl-bench: Benchmarking stability-efficiency trade-offs and scaling in biomedical continual learning,” 2026. [Online]. Available: https://arxiv.org/abs/2603.16738
-
[18]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
“can chatgpt answer patient’s questions?
D. Tao, K. M. Kochendorfer, T. Griffin, Q. McCrary, A. Gautam, B. S. Labib, M. Arvan, J. Flynn, and K. Jiang, ““can chatgpt answer patient’s questions?”: a preliminary analysis,” inMEDINFO 2025—Healthcare Smart×Medicine Deep. IOS Press, 2025, pp. 1586–1587
work page 2025
-
[20]
S. Sevinc ¸, M. Candemir, B. A. Yamak, E. Kızıltunc ¸, B. Sezen¨oz, O. B. S ¸ahin, S. Topal, Y . Demir, M. R. Yalc ¸ın, and A. S ¸ahinarslan, “An academic evaluation of chatgpt’s ability and accuracy in creating patient education resources for rare cardiovascular diseases,”Scientific Reports, vol. 15, no. 1, p. 25929, 2025
work page 2025
-
[21]
Artificial intelligence chatbots and narcolepsy: friend or foe for patient information?
F. Henriques, C. Costa, B. Oliveiros, J. B. Melo, C. Santos, and J. Jesus- Ribeiro, “Artificial intelligence chatbots and narcolepsy: friend or foe for patient information?”European Neurology, vol. 88, no. 3-4, pp. 122– 128, 2025
work page 2025
-
[22]
M. Valentini, J. Szkandera, M. A. Smolle, S. Scheipl, A. Leithner, and D. Andreou, “Artificial intelligence large language model chatgpt: is it a trustworthy and reliable source of information for sarcoma patients?” Frontiers in Public Health, vol. 12, p. 1303319, 2024
work page 2024
-
[23]
R. Lambert, Z.-Y . Choo, K. Gradwohl, L. Schroedl, and A. Ruiz De Luzuriaga, “Assessing the application of large language models in generating dermatologic patient education materials according to reading level: qualitative study,”JMIR dermatology, vol. 7, p. e55898, 2024
work page 2024
-
[24]
Automating evaluation of llm-generated responses to patient questions about rare diseases,
M. Zhao, I. Y . Oh, A. Gupta, S. Cohen-Cutler, K. M. Harmoney, A. M. Lai, and B. A. Sisk, “Automating evaluation of llm-generated responses to patient questions about rare diseases,”medRxiv, pp. 2025–10, 2025
work page 2025
-
[25]
Chatgpt, gemini, and grok on familial mediterranean fever: are they trustworthy?
S. Cilli Hayıro ˘glu and T. Bozkurt, “Chatgpt, gemini, and grok on familial mediterranean fever: are they trustworthy?”Clinical Rheumatology, vol. 45, no. 1, pp. 521–530, 2026
work page 2026
-
[26]
Enhancing rare disease education through ai-driven podcast genera- tion,
E. Perez-Palma, I. Miller, K. Johannesen, L. Chaby, L. Randall, M. Graglia, C. Grzeskowiak, L. Manaster, L. Lubbers, A. Freedet al., “Enhancing rare disease education through ai-driven podcast genera- tion,”medRxiv, pp. 2025–01, 2025
work page 2025
-
[27]
S. Jeon, S.-A. Lee, H.-S. Chung, J. Y . Yun, E. A. Park, M.-K. So, and J. Huh, “Evaluating the use of generative artificial intelligence to support genetic counseling for rare diseases,”Diagnostics, vol. 15, no. 6, p. 672, 2025
work page 2025
-
[28]
Large language models in rare disease: accuracy in addressing fibromuscular dysplasia questions,
L. Tefera, A. Rosenzveig, J. Rajendran, B. Rajasekar, J. Kassab, D. Hor- nacek, M. McCarthy, T. Wu, N. F. Mahlay, and P. Chaudhury, “Large language models in rare disease: accuracy in addressing fibromuscular dysplasia questions,”VASA. Zeitschrift fur Gefasskrankheiten, vol. 54, no. 3, pp. 218–219, 2025
work page 2025
-
[29]
M. T. Weber, R. Noll, A. Marchl, C. Facchinello, A. Gr ¨unewaldt, C. H ¨ugel, K. Musleh, T. O. Wagner, H. Storf, and J. Schaaf, “Medbot vs realdoc: efficacy of large language modeling in physician-patient communication for rare diseases,”Journal of the American Medical Informatics Association, vol. 32, no. 5, pp. 775–783, 2025
work page 2025
-
[30]
A. M. van Eerde, A. Teixeira, F. Galletti, M. Maternik, V . Capone, R. Westland, J. Mulder, J. Halbritter, T. Osterholt, V . Neukelet al., “Risks and benefits of chatgpt in informing patients and families with rare kidney diseases: an explorative assessment by the european rare kidney disease reference network (erknet),”Pediatric Nephrology, vol. 40, no. ...
work page 2025
-
[31]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Gemma: Open Models Based on Gemini Research and Technology
G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivi `ere, M. S. Kale, J. Loveet al., “Gemma: Open models based on gemini research and technology,”arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Large lan- guage models in patient education: a scoping review of applications in medicine,
S. Aydin, M. Karabacak, V . Vlachos, and K. Margetis, “Large lan- guage models in patient education: a scoping review of applications in medicine,”Frontiers in medicine, vol. 11, p. 1477898, 2024
work page 2024
-
[36]
The use of large language models in generating patient education materials: a scoping review,
A. AlSammarraie and M. Househ, “The use of large language models in generating patient education materials: a scoping review,”Acta Informatica Medica, vol. 33, no. 1, p. 4, 2025
work page 2025
-
[37]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
work page 2022
-
[38]
Y . Zhu, Z. Wang, J. Gao, Y . Tong, J. An, W. Liao, E. M. Harrison, L. Ma, and C. Pan, “Prompting large language models for zero-shot clinical prediction with structured longitudinal electronic health record data,”arXiv preprint arXiv:2402.01713, 2024
-
[39]
Z. Zhan, J. Wang, S. Zhou, J. Deng, and R. Zhang, “Mmrag: multi-mode retrieval-augmented generation with large language models for biomed- ical in-context learning,”Journal of the American Medical Informatics Association, vol. 32, no. 10, pp. 1505–1516, 2025
work page 2025
-
[40]
Z. Zhan, S. Zhou, X. Zhou, Y . Xiao, J. Wang, J. Deng, H. Zhu, Y . Hou, Y . Song, M. Lin, and R. Zhang, “Retrieval-augmented in-context learning for multimodal large language models in disease classification,”Journal of Biomedical Informatics, vol. 178, p. 105017, 2026. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1532046426000419
work page 2026
-
[41]
X. Luoet al., “Cross-cultural adaptation framework for enhancing large language model outputs in multilingual contexts,”Journal of Advanced Computing Systems, vol. 3, no. 5, pp. 48–62, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.