DiZiNER: Disagreement-guided Instruction Refinement via Pilot Annotation Simulation for Zero-shot Named Entity Recognition
Pith reviewed 2026-05-10 08:42 UTC · model grok-4.3
The pith
DiZiNER refines zero-shot named entity recognition instructions by simulating pilot annotation disagreements among multiple LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
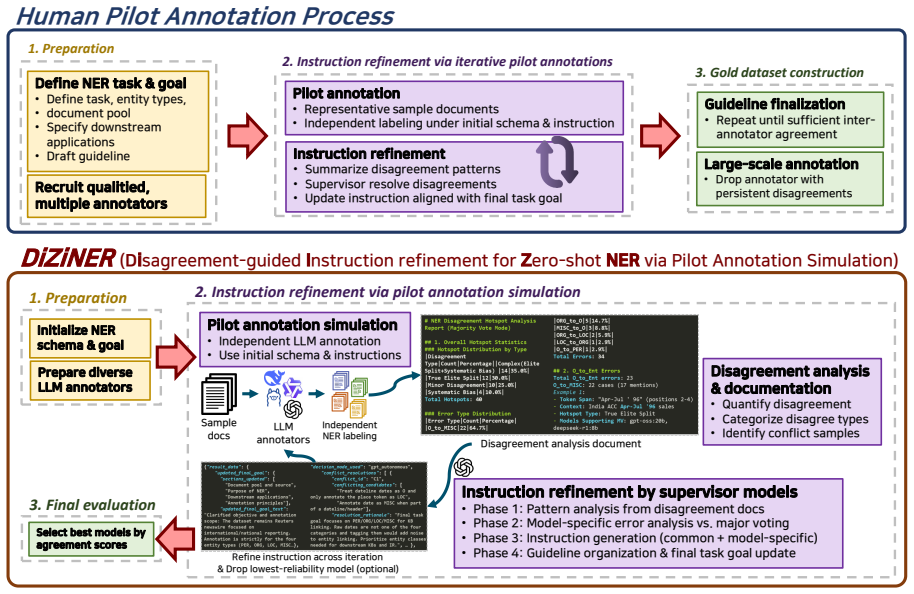
DiZiNER simulates the pilot annotation process for zero-shot NER by having multiple heterogeneous LLMs act as annotators on shared texts and a supervisor model analyze their disagreements to refine the task instructions. This yields zero-shot state-of-the-art results on 14 of 18 benchmarks, with an average improvement of +8.0 F1 over prior methods and a reduction of the gap to supervised performance by more than 11 points. The refined system also beats the supervisor model GPT-5 mini on the tasks, and pairwise agreement among models correlates positively with NER performance.
What carries the argument
Disagreement-guided instruction refinement, in which a supervisor LLM examines differing annotations from multiple models to update the instructions.
Load-bearing premise
Disagreements between outputs of different LLMs reliably highlight instruction deficiencies that, when fixed, improve entity recognition across varied datasets.
What would settle it
If experiments on held-out NER datasets show that instructions refined via LLM disagreement analysis do not lead to higher F1 scores than the original instructions, the approach would be falsified.
Figures


read the original abstract
Large language models (LLMs) have advanced information extraction (IE) by enabling zero-shot and few-shot named entity recognition (NER), yet their generative outputs still show persistent and systematic errors. Despite progress through instruction fine-tuning, zero-shot NER still lags far behind supervised systems. These recurring errors mirror inconsistencies observed in early-stage human annotation processes that resolve disagreements through pilot annotation. Motivated by this analogy, we introduce DiZiNER (Disagreement-guided Instruction Refinement via Pilot Annotation Simulation for Zero-shot Named Entity Recognition), a framework that simulates the pilot annotation process, employing LLMs to act as both annotators and supervisors. Multiple heterogeneous LLMs annotate shared texts, and a supervisor model analyzes inter-model disagreements to refine task instructions. Across 18 benchmarks, DiZiNER achieves zero-shot SOTA results on 14 datasets, improving prior bests by +8.0 F1 and reducing the zero-shot to supervised gap by over +11 points. It also consistently outperforms its supervisor, GPT-5 mini, indicating that improvements stem from disagreement-guided instruction refinement rather than model capacity. Pairwise agreement between models shows a strong correlation with NER performance, further supporting this finding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiZiNER, a framework for zero-shot NER that simulates human pilot annotation by having multiple heterogeneous LLMs annotate the same texts and then using a supervisor LLM (GPT-5 mini) to analyze inter-model disagreements and refine the task instructions. It claims this yields zero-shot SOTA results on 14 of 18 benchmarks (+8.0 F1 average improvement over prior bests), reduces the zero-shot-to-supervised gap by >11 points, consistently beats the supervisor model, and shows strong correlation between pairwise model agreement and final NER F1.
Significance. If the central empirical claims hold after proper controls and details are supplied, the work would be significant for zero-shot IE: it offers a training-free, disagreement-driven instruction refinement procedure that appears to improve over both prior zero-shot methods and the supervisor LLM itself, with a plausible human-annotation analogy. The reported correlation between agreement and performance, if causally supported, could inform broader LLM consistency research.
major comments (2)
- The central claim attributes the +8 F1 gains and outperformance of GPT-5 mini specifically to disagreement-guided refinement, yet the manuscript supplies no ablation in which the supervisor receives the same pilot texts and original instructions but is prompted to refine without seeing or referencing the inter-model disagreement annotations (e.g., a generic refinement prompt). Without this control, the observed correlation between pairwise agreement and NER F1 cannot establish that disagreement analysis is the causal mechanism rather than iterative supervisor prompting alone.
- Abstract and results sections report quantitative gains across 18 benchmarks but provide no implementation details, ablation studies, statistical significance tests, error analysis, or exact model configurations. This absence prevents evaluation of whether the reported SOTA numbers are reproducible or robust.
minor comments (2)
- Clarify the exact set of heterogeneous annotator LLMs, the precise disagreement quantification method, and the supervisor prompt template used for refinement.
- The abstract refers to 'GPT-5 mini'; confirm the model identity and whether it is the same across all experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which identifies key areas where additional controls and transparency will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: The central claim attributes the +8 F1 gains and outperformance of GPT-5 mini specifically to disagreement-guided refinement, yet the manuscript supplies no ablation in which the supervisor receives the same pilot texts and original instructions but is prompted to refine without seeing or referencing the inter-model disagreement annotations (e.g., a generic refinement prompt). Without this control, the observed correlation between pairwise agreement and NER F1 cannot establish that disagreement analysis is the causal mechanism rather than iterative supervisor prompting alone.
Authors: We agree that a dedicated ablation isolating disagreement analysis from generic iterative refinement by the supervisor is required to establish causality. While the manuscript shows DiZiNER outperforming the supervisor and a correlation between pairwise agreement and F1, these do not fully rule out benefits from repeated prompting alone. In the revision we will add the requested control: the supervisor will receive the same pilot texts and original instructions but will be prompted to refine without any reference to inter-model disagreements. We will report the results, compare them to the full DiZiNER pipeline, and update the causal claims and discussion as warranted. revision: yes
-
Referee: Abstract and results sections report quantitative gains across 18 benchmarks but provide no implementation details, ablation studies, statistical significance tests, error analysis, or exact model configurations. This absence prevents evaluation of whether the reported SOTA numbers are reproducible or robust.
Authors: We acknowledge that the current manuscript omits critical details needed for reproducibility and robustness evaluation. In the revised version we will expand the Experimental Setup and Results sections to include: exact model identifiers and hyperparameter settings for all LLMs (including GPT-5 mini temperature, top-p, and generation parameters), full prompt templates for annotation and supervision stages, complete ablation studies, statistical significance testing (bootstrap confidence intervals on F1 and paired tests for model comparisons), and a categorized error analysis of failure modes. We will also release code, prompts, and data splits to support independent reproduction. revision: yes
Circularity Check
No significant circularity; empirical method with direct measurements
full rationale
The paper presents DiZiNER as an empirical framework that runs heterogeneous LLMs as annotators, has a supervisor analyze disagreements, and reports measured F1 scores on 18 fixed benchmarks. No equations, fitted parameters, or derivations appear in the provided text. Performance gains and outperformance of GPT-5 mini are stated as direct experimental outcomes, not quantities defined by construction from the method's own inputs. The central claim rests on benchmark results rather than any self-referential loop or renamed known result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple heterogeneous LLMs can generate diverse annotations whose disagreements reveal deficiencies in task instructions.
Reference graph
Works this paper leans on
-
[1]
Nuner: Entity recognition encoder pre- training via llm-annotated data.arXiv preprint arXiv:2402.15343. Jiawei Chen, Yaojie Lu, Hongyu Lin, Jie Lou, Wei Jia, Dai Dai, Hua Wu, Boxi Cao, Xianpei Han, and Le Sun. 2023. Learning in-context learn- ing for named entity recognition.arXiv preprint arXiv:2305.11038. Alexander Philip Dawid and Allan M Skene. 1979. ...
-
[2]
Broad twitter corpus: A diverse named entity recognition resource. InProceedings of COLING 2016, the 26th international conference on compu- tational linguistics: Technical papers, pages 1169– 1179. Yuyang Ding, Juntao Li, Pinzheng Wang, Zecheng Tang, Bowen Yan, and Min Zhang. 2024. Rethinking nega- tive instances for generative named entity recognition. ...
-
[3]
InLinguistic Annotation Workshop, pages 142–145
Towards a methodology for named entities an- notation. InLinguistic Annotation Workshop, pages 142–145. Quanjiang Guo, Yihong Dong, Ling Tian, Zhao Kang, Yu Zhang, and Sijie Wang. 2024a. Baner: Boundary- aware llms for few-shot named entity recognition. arXiv preprint arXiv:2412.02228. Yucan Guo, Zixuan Li, Xiaolong Jin, Yantao Liu, Yu- tao Zeng, Wenxuan ...
-
[4]
arXiv preprint arXiv:2402.12801
Few-shot clinical entity recognition in english, french and spanish: masked language models out- perform generative model prompting.arXiv preprint arXiv:2402.12801. Chaoxu Pang, Yixuan Cao, Qiang Ding, and Ping Luo
-
[5]
Guideline learning for in-context information extraction.arXiv preprint arXiv:2310.05066. Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Hwee Tou Ng, Anders Björkelund, Olga Uryupina, Yuchen Zhang, and Zhi Zhong. 2013. Towards robust linguistic analysis using ontonotes. InProceedings of the Seventeenth Conference on Computational Nat- ural Language Le...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.