Brain-CLIPLM: Decoding Compressed Semantic Representations in EEG for Language Reconstruction
Pith reviewed 2026-05-15 01:03 UTC · model grok-4.3
The pith
EEG signals encode compressed semantic anchors rather than full sentence structure, making direct reconstruction overparameterized.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EEG signals encode a compressed set of semantic anchors rather than full linguistic structure. Direct sentence reconstruction is therefore overparameterized relative to the intrinsic information capacity of EEG. Brain-CLIPLM decomposes the task into semantic anchor extraction via contrastive learning followed by sentence reconstruction through a retrieval-grounded large language model that uses chain-of-thought reasoning, aligned by a granularity-matching principle.
What carries the argument
Brain-CLIPLM two-stage framework that separates contrastive semantic-anchor extraction from LLM-based retrieval and chain-of-thought reconstruction under a granularity-matching principle.
If this is right
- Framing EEG-to-text as semantic recovery rather than full reconstruction raises retrieval accuracy and reduces overfitting.
- The two-stage separation enables robust cross-subject generalization on the evaluated corpus.
- Control permutation tests show EEG representations carry sentence-specific content beyond language model priors.
- Granularity matching aligns model complexity with measured neural information capacity.
Where Pith is reading between the lines
- Practical brain-computer interfaces may shift from verbatim generation toward semantic matching against large language model outputs.
- The same compression logic could apply to other low-bandwidth recordings such as fMRI or MEG when sentence-level detail is required.
- Extending the anchor vocabulary size would provide a direct test of how much semantic content EEG can reliably support.
Load-bearing premise
EEG signals under realistic conditions carry only compressed semantic anchors and lack the bandwidth for full sentence structure.
What would settle it
A direct end-to-end decoding model that achieves equal or higher top-5 and top-25 retrieval accuracy than the two-stage framework on the same Zurich corpus without using retrieval or chain-of-thought steps.
Figures





read the original abstract
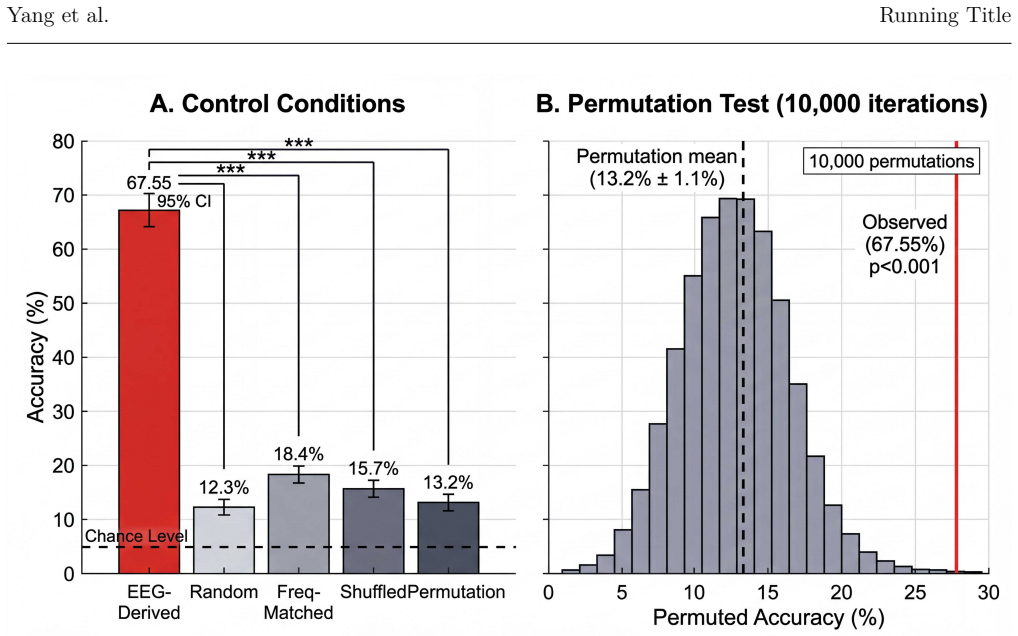
Decoding natural language from non-invasive electroencephalography (EEG) remains fundamentally limited by low signal-to-noise ratio and restricted information bandwidth. This raises a fundamental question regarding whether sentence-level linguistic structure can be reliably recovered from such signals. In this work, we suggest that this assumption may not hold under realistic information constraints, and instead propose a semantic compression hypothesis in which EEG signals encode a compressed set of semantic anchors rather than full linguistic structure. Under our new perspective, direct sentence reconstruction becomes an overparameterized objective relative to the intrinsic information capacity of EEG. To address this mismatch, we introduce Brain-CLIPLM, a two-stage framework that decomposes EEG-to-text decoding into semantic anchor extraction via contrastive learning and sentence reconstruction using a retrieval-grounded large language model (LLM) with Chain-of-Thought (CoT) reasoning, following a granularity matching principle that aligns decoding complexity with neural information capacity. Evaluated on the Zurich Cognitive Language Processing Corpus, Brain-CLIPLM achieves 67.55\% top-5 and 85.00\% top-25 sentence retrieval accuracy, significantly outperforming direct decoding baseline, while cross-subject evaluation confirms robust generalization. Control analyses, including permutation testing, further demonstrate that EEG-derived representations carry sentence-specific information beyond language model priors. These results suggest that EEG-to-text decoding is better framed as recovering compressed semantic content rather than reconstructing full sentences, providing a biologically grounded and data-efficient pathway for non-invasive brain-computer interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that EEG signals encode only a compressed set of semantic anchors rather than full linguistic structure, making direct sentence reconstruction overparameterized relative to EEG information capacity. It introduces Brain-CLIPLM, a two-stage framework that first extracts semantic anchors from EEG via contrastive learning and then performs sentence reconstruction using a retrieval-grounded LLM with Chain-of-Thought reasoning, guided by a granularity-matching principle. On the Zurich Cognitive Language Processing Corpus, the method achieves 67.55% top-5 and 85.00% top-25 closed-set sentence retrieval accuracy, outperforming a direct decoding baseline, with cross-subject generalization and permutation testing showing sentence-specific information beyond language model priors. The work reframes EEG-to-text decoding as recovery of compressed semantic content for more biologically plausible and data-efficient BCIs.
Significance. If the central hypothesis and framework hold, the paper provides a principled alternative to direct reconstruction paradigms in non-invasive EEG decoding, with potential for improved alignment to neural bandwidth limits and reduced data requirements. Credit is due for the explicit use of contrastive learning to isolate anchors, permutation controls to rule out LM priors, and cross-subject evaluation. The retrieval results are concrete and controlled, though the reconstruction component remains unquantified.
major comments (2)
- Abstract and Results section: The reported metrics are exclusively closed-set sentence retrieval accuracies (67.55% top-5, 85% top-25) plus permutation controls. No quantitative evaluation is provided for the LLM reconstruction stage itself (e.g., semantic similarity, BLEU/ROUGE, fluency, or human ratings on held-out novel inputs). Because the central claim is that the two-stage contrastive-plus-retrieval framework aligns decoding complexity with EEG capacity and enables reconstruction, the absence of reconstruction-specific metrics leaves the reconstruction component and the overparameterization argument untested.
- Framework description (granularity matching principle): The manuscript invokes a 'granularity matching principle' to justify decomposing the task into anchor extraction followed by retrieval-grounded LLM reconstruction, yet provides no explicit quantitative definition, ablation, or validation showing that this decomposition actually matches EEG information capacity rather than simply improving retrieval. This is load-bearing for the semantic compression hypothesis.
minor comments (2)
- Abstract: The phrase 'significantly outperforming direct decoding baseline' lacks the baseline method name and its exact performance numbers, making the improvement magnitude hard to assess without the full results table.
- Notation and terminology: Ensure 'CoT' and 'LLM' are expanded on first use in the main text; the abstract uses them without definition.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below, providing clarifications on our evaluation choices while committing to revisions that strengthen the quantification of the reconstruction stage and the granularity matching principle.
read point-by-point responses
-
Referee: Abstract and Results section: The reported metrics are exclusively closed-set sentence retrieval accuracies (67.55% top-5, 85% top-25) plus permutation controls. No quantitative evaluation is provided for the LLM reconstruction stage itself (e.g., semantic similarity, BLEU/ROUGE, fluency, or human ratings on held-out novel inputs). Because the central claim is that the two-stage contrastive-plus-retrieval framework aligns decoding complexity with EEG capacity and enables reconstruction, the absence of reconstruction-specific metrics leaves the reconstruction component and the overparameterization argument untested.
Authors: We agree that direct metrics on the LLM-generated outputs would provide stronger support for the full pipeline. Our primary focus was on retrieval accuracy because it isolates the semantic anchor extraction stage and directly tests the hypothesis that EEG encodes compressed semantics rather than full linguistic structure; the retrieval-grounded LLM then uses these anchors for reconstruction via CoT. We did not include BLEU, ROUGE, or embedding similarity on generated sentences because the closed-set retrieval already demonstrates sentence-specific information beyond LM priors, and generation quality is heavily influenced by the LLM backbone. In revision we will add quantitative reconstruction metrics, including cosine similarity between sentence embeddings of generated and ground-truth text, plus a small-scale human fluency rating on a subset of outputs, to better quantify the second stage. revision: yes
-
Referee: Framework description (granularity matching principle): The manuscript invokes a 'granularity matching principle' to justify decomposing the task into anchor extraction followed by retrieval-grounded LLM reconstruction, yet provides no explicit quantitative definition, ablation, or validation showing that this decomposition actually matches EEG information capacity rather than simply improving retrieval. This is load-bearing for the semantic compression hypothesis.
Authors: The referee is correct that the granularity matching principle requires more explicit support. We conceptualize it as aligning the information granularity of the decoded representation (low-dimensional semantic anchors obtained via contrastive learning) with the limited bandwidth of non-invasive EEG, thereby rendering direct sentence-level reconstruction overparameterized. While the superior performance over direct decoding baselines and the permutation controls provide indirect evidence, we did not include a formal ablation or information-theoretic quantification (e.g., dimensionality reduction ratios or mutual information estimates). In the revised manuscript we will add a dedicated subsection that (i) formally defines the principle in terms of embedding dimensionality and retrieval efficiency, and (ii) reports an ablation comparing the two-stage model against a direct EEG-to-sentence baseline on both retrieval and reconstruction metrics. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained with external components and empirical controls
full rationale
The paper's chain proceeds from the semantic compression hypothesis to a two-stage framework (contrastive anchor extraction plus retrieval-grounded LLM with CoT) and then to reported top-k retrieval accuracies plus permutation tests. No step reduces a claimed prediction to its own inputs by construction, no parameters are fitted and then relabeled as predictions, and no load-bearing uniqueness or ansatz is imported via self-citation. The evaluation metrics are independent of the hypothesis statement itself and rely on external pre-trained models plus held-out data controls, keeping the derivation non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption EEG signals have low signal-to-noise ratio and restricted information bandwidth that limits them to encoding compressed semantic anchors rather than full linguistic structure
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a semantic compression hypothesis in which EEG signals encode a compressed set of semantic anchors rather than full linguistic structure... factorized formulation X → K → Y
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
granularity matching principle that aligns decoding complexity with neural information capacity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address annote author booktitle chapter doi edition editor eid howpublished institution journal key language month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := ...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter doi edition editor eid howpublished institution journal key language month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid...
-
[4]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in "" FUNCTION format.date year ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.