Recognition: unknown
Incentivizing Parametric Knowledge via Reinforcement Learning with Verifiable Rewards for Cross-Cultural Entity Translation
Pith reviewed 2026-05-10 07:01 UTC · model grok-4.3
The pith
Reinforcement learning anchored on verifiable entity rewards improves cross-cultural entity translation accuracy in LLMs by unlocking pre-existing parametric knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
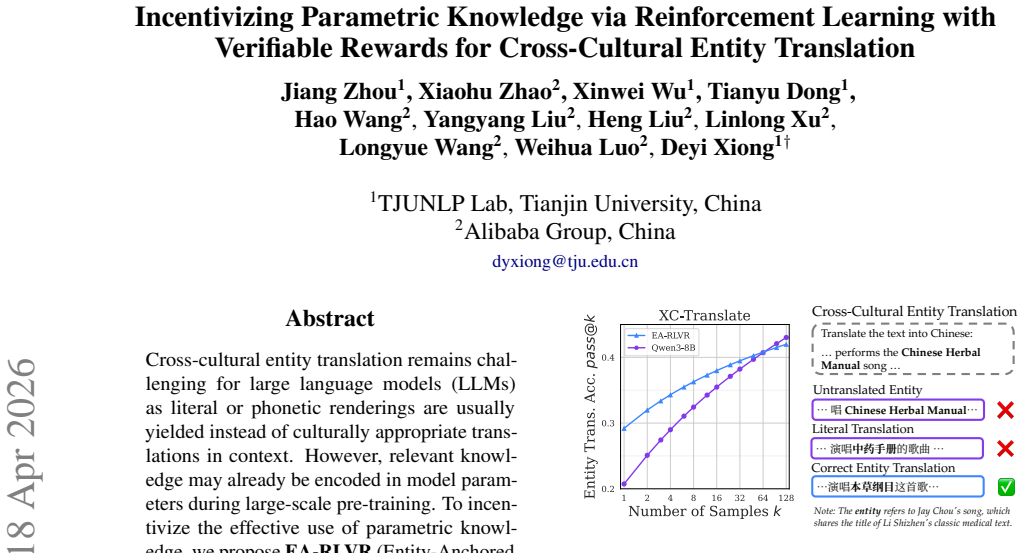
EA-RLVR optimizes cross-cultural entity translation by anchoring supervision on a verifiable entity-level reward signal and incorporating structural gates to stabilize training. This steers the model toward robust reasoning processes instead of imitation. On the XC-Translate benchmark, training Qwen3-14B on only 7k samples raises entity translation accuracy from 23.66% to 31.87% on a 50k test set of entirely unseen entities, while the same ability transfers to general translation with +1.35 XCOMET on WMT24++ that rises to +1.59 under extended optimization.
What carries the argument
EA-RLVR, a reinforcement learning framework that uses entity-anchored verifiable rewards and structural gates to incentivize use of parametric knowledge for culturally appropriate translations.
If this is right
- Training on small sets of 7k samples produces consistent accuracy gains on large held-out sets of unseen entities.
- The acquired entity translation skill transfers directly to improve general translation quality on WMT24++.
- Gains arise from improved sampling efficiency and a more stable optimization landscape rather than simple imitation.
- The method yields out-of-domain generalization benefits without requiring reference translations for supervision.
Where Pith is reading between the lines
- The same reward-anchoring technique could be tested on other latent knowledge domains such as factual consistency or stylistic adaptation where external supervision is costly.
- Extending the approach to multilingual or low-resource language pairs might reduce dependence on large parallel corpora for specialized translation.
- If the gains persist across model scales, the method points to a general recipe for eliciting culturally situated behavior from pre-trained parameters.
Load-bearing premise
Relevant cross-cultural knowledge for entity translation is already encoded in model parameters during pre-training and can be activated through a verifiable entity-level reward signal defined without external knowledge bases.
What would settle it
Apply the identical 7k-sample training procedure to a model variant that demonstrably lacks the relevant cross-cultural entity facts in its parameters and measure whether the accuracy lift on the 50k unseen test set disappears.
Figures









read the original abstract
Cross-cultural entity translation remains challenging for large language models (LLMs) as literal or phonetic renderings are usually yielded instead of culturally appropriate translations in context. However, relevant knowledge may already be encoded in model parameters during large-scale pre-training. To incentivize the effective use of parametric knowledge, we propose EA-RLVR (Entity-Anchored Reinforcement Learning with Verifiable Rewards), a training framework that optimizes cross-cultural entity translation without relying on external knowledge bases. EA-RLVR anchors supervision on a verifiable, entity-level reward signal and incorporates lightweight structural gates to stabilize optimization. This design steers the model toward learning a robust reasoning process rather than merely imitating reference translations. We evaluate EA-RLVR on XC-Translate and observe consistent improvements in both entity translation accuracy and out-of-domain generalization. Specifically, training on merely 7k samples boosts Qwen3-14B's entity translation accuracy from 23.66\% to 31.87\% on a 50k test set comprising entirely unseen entities. The learned entity translation ability also transfers to general translation, yielding +1.35 XCOMET on WMT24++, which scales to +1.59 with extended optimization. Extensive analyses of $pass@k$ dynamics and reward formulations attribute these gains to superior sampling efficiency and a stable optimization landscape.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents EA-RLVR, an entity-anchored reinforcement learning approach with verifiable rewards and structural gates, to improve cross-cultural entity translation in LLMs by leveraging parametric knowledge. Key results include boosting Qwen3-14B's accuracy from 23.66% to 31.87% on 50k unseen entities using only 7k training samples, with positive transfer to general translation tasks on WMT24++ (+1.35 XCOMET, scaling to +1.59).
Significance. Should the results prove robust and the reward mechanism confirmed to be free of external references, this could represent a meaningful advance in efficient fine-tuning for cultural NLP tasks, highlighting how RL can unlock pre-existing model knowledge with small datasets and demonstrating generalization beyond the training domain.
major comments (2)
- [Abstract] Abstract: The central claim that EA-RLVR 'optimizes cross-cultural entity translation without relying on external knowledge bases' via 'a verifiable, entity-level reward signal' is load-bearing, yet the abstract (and post-hoc reward formulation analysis referenced in the text) provides no equation, pseudocode, or precise definition of how the reward is computed for the 7k samples. If the signal involves string matching to gold translations, semantic similarity, or an auxiliary LLM judge, it would constitute an external reference and explain the reported accuracy lift on the 50k unseen test set rather than purely incentivizing parametric knowledge.
- [Evaluation section] Evaluation section: The accuracy improvement (23.66% to 31.87%) and XCOMET transfer gains (+1.35 to +1.59) are reported without error bars, number of runs, statistical tests, or detailed baseline descriptions (e.g., how the initial 23.66% was obtained or comparisons to standard SFT/RL baselines), which is necessary to substantiate the claims of superior sampling efficiency and stable optimization landscape from the pass@k and reward analyses.
minor comments (2)
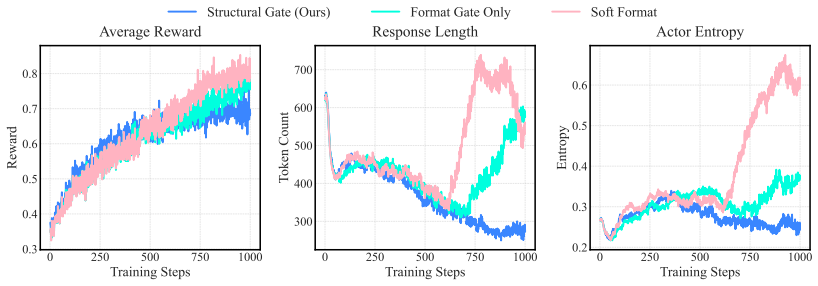
- The abstract references 'lightweight structural gates' and 'pass@k dynamics' without specifying their hyperparameters, exact formulation, or pointing to the relevant figures/tables, which reduces clarity on how they contribute to stabilization.
- The manuscript would benefit from explicit discussion of limitations, such as applicability to low-resource languages or potential overfitting to the XC-Translate entity distribution.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below and will revise the manuscript to enhance clarity, rigor, and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that EA-RLVR 'optimizes cross-cultural entity translation without relying on external knowledge bases' via 'a verifiable, entity-level reward signal' is load-bearing, yet the abstract (and post-hoc reward formulation analysis referenced in the text) provides no equation, pseudocode, or precise definition of how the reward is computed for the 7k samples. If the signal involves string matching to gold translations, semantic similarity, or an auxiliary LLM judge, it would constitute an external reference and explain the reported accuracy lift on the 50k unseen test set rather than purely incentivizing parametric knowledge.
Authors: We agree that an explicit definition of the reward is needed for full transparency. The verifiable reward is computed via entity-level exact string matching to the gold translation (R = 1 if the extracted entity string matches the gold exactly, else 0), with no external knowledge base, retrieval system, semantic similarity model, or auxiliary LLM judge involved. This formulation is presented in Section 3.2 along with the structural gates that prevent reward hacking or collapse to rote copying. The phrase 'without relying on external knowledge bases' distinguishes our approach from methods that retrieve from Wikipedia, dictionaries, or other corpora; the 7k gold pairs serve only as the minimal verifiable signal to unlock parametric knowledge already present from pre-training. The pass@k curves and ablation studies support that gains arise from improved sampling efficiency rather than memorization. We will add the reward equation and pseudocode directly to the abstract and expand the reward section for clarity. revision: yes
-
Referee: [Evaluation section] Evaluation section: The accuracy improvement (23.66% to 31.87%) and XCOMET transfer gains (+1.35 to +1.59) are reported without error bars, number of runs, statistical tests, or detailed baseline descriptions (e.g., how the initial 23.66% was obtained or comparisons to standard SFT/RL baselines), which is necessary to substantiate the claims of superior sampling efficiency and stable optimization landscape from the pass@k and reward analyses.
Authors: We acknowledge that additional statistical details and baseline comparisons are required to strengthen the claims. The reported 23.66% is the zero-shot accuracy of the base Qwen3-14B model on the 50k unseen test entities. We will revise the evaluation section to include: (i) results from three independent runs with different random seeds, reporting means and standard deviations; (ii) p-values from paired statistical tests against baselines; and (iii) explicit descriptions of all baselines, including SFT on the same 7k samples, standard PPO without structural gates, and a random-reward ablation. The pass@k and reward-curve analyses will be updated with these statistics to better substantiate the claims of superior sampling efficiency and optimization stability. revision: yes
Circularity Check
No significant circularity; derivation relies on held-out evaluation and independent reward signal
full rationale
The paper's core derivation chain trains EA-RLVR on 7k samples using an entity-level verifiable reward claimed to operate without external KBs, then measures gains on a 50k test set of entirely unseen entities plus transfer to WMT24++. No equations or text in the abstract reduce the reported accuracy lift (23.66% → 31.87%) or XCOMET gains to a fitted parameter or self-citation by construction. The reward is presented as steering toward parametric knowledge rather than reference imitation, and pass@k analyses are invoked as supporting evidence. This structure keeps the central claim independent of the training inputs; the evaluation protocol on unseen data prevents direct reduction to the reward definition itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- structural gate hyperparameters
axioms (1)
- domain assumption Relevant cross-cultural entity knowledge is already encoded in LLM parameters during large-scale pre-training
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Simone Conia, Daniel Lee, Min Li, Umar Farooq Min- has, Saloni Potdar, and Yunyao Li. 2024. Towards cross-cultural machine translation with retrieval- augmented generation from multilingual knowledge graphs. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Daniel Deutsch, Eleftheria Briakou, Isaac Rayburn Caswell, Mara Finkelstein, Rebecca Galor, Juraj Juraska, Geza Kovacs, Alison Lui, Ricardo Rei, Ja- son Riesa, and 1 others. 2025. Wmt24++: Expanding the language coverage of wmt24 to 55 language...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Proximal Policy Optimization Algorithms
COMET-22: Unbabel-IST 2022 submission for the metrics shared task. InProceedings of the Seventh Conference on Machine Translation (WMT), pages 578–585, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics. Ricardo Rei, Nuno M. Guerreiro, Marcos Treviso, Luisa Coheur, Alon Lavie, and André Martins. 2023. The inside story: Tow...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Lei Yang, Wei Bi, Chenxi Sun, Renren Jin, and Deyi Xiong. 2026. SOUP: Token-level Single-sample Mix-policy Reinforcement Learning for large lan- guage models.CoRR, abs/2601.21476. Binwei Yao, Ming Jiang, Tara Bobinac, Diyi Yang, and Junjie Hu. 2024. Benchmarking machine translation with cultural awar...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Know what you know: Metacognitive entropy calibration for verifiable rl reasoning.arXiv preprint arXiv:2602.22751. Yu Zhao, Huifeng Yin, Bo Zeng, Hao Wang, Tianqi Shi, Chenyang Lyu, Longyue Wang, Weihua Luo, and Kaifu Zhang. 2024a. Marco-o1: Towards open reasoning models for open-ended solutions.Preprint, arXiv:2411.14405. Yuze Zhao, Jintao Huang, Jinghan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.