Recognition: unknown
TingIS: Real-time Risk Event Discovery from Noisy Customer Incidents at Enterprise Scale
Pith reviewed 2026-05-09 21:41 UTC · model grok-4.3
The pith
TingIS links noisy customer messages into stable incidents using LLMs and indexing to reach 95% high-priority discovery at 3.5-minute P90 latency in production.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
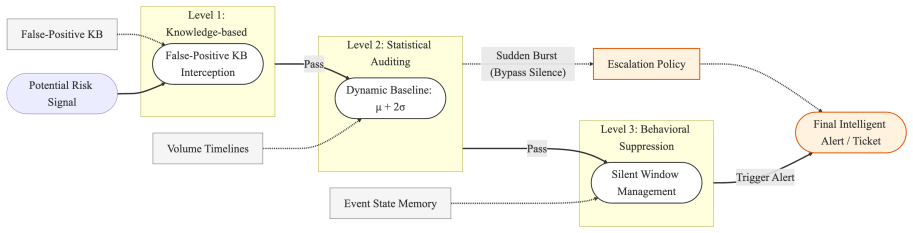
At the core of TingIS is a multi-stage event linking engine that synergizes efficient indexing techniques with Large Language Models (LLMs) to make informed decisions on event merging, enabling the stable extraction of actionable incidents from just a handful of diverse user descriptions. This engine is complemented by a cascaded routing mechanism for precise business attribution and a multi-dimensional noise reduction pipeline that integrates domain knowledge, statistical patterns, and behavioral filtering. Deployed in a production environment handling a peak throughput of over 2,000 messages per minute and 300,000 messages per day, TingIS achieves a P90 alert latency of 3.5 minutes and a
What carries the argument
The multi-stage event linking engine that combines efficient indexing techniques with LLMs to decide which customer descriptions refer to the same incident.
If this is right
- High-priority incidents are discovered at a 95 percent rate with P90 latency of 3.5 minutes under sustained production loads exceeding 2,000 messages per minute.
- Cascaded routing improves attribution of incidents to the correct business units.
- Multi-dimensional noise reduction raises the signal-to-noise ratio while preserving clustering quality.
- Actionable events can be extracted even when each incident is described by only a small number of semantically varied customer messages.
Where Pith is reading between the lines
- Similar LLM-plus-indexing hybrids could be applied to other high-volume noisy text streams such as security alerts or operational logs.
- The achieved latency opens the possibility of shifting from reactive to near-proactive risk mitigation in cloud operations.
- If the reported performance generalizes, the approach could lower the human review burden required for enterprise-scale incident monitoring.
Load-bearing premise
Benchmarks built from real-world data remain representative across diverse business lines and are free of selection bias or post-hoc tuning that would inflate the reported 95 percent discovery rate and latency figures.
What would settle it
A test on a fresh, randomly sampled collection of customer incidents drawn from previously unseen business lines that yields a high-priority discovery rate below 80 percent or a P90 latency above 5 minutes would falsify the production performance claims.
Figures




read the original abstract
Real-time detection and mitigation of technical anomalies are critical for large-scale cloud-native services, where even minutes of downtime can result in massive financial losses and diminished user trust. While customer incidents serve as a vital signal for discovering risks missed by monitoring, extracting actionable intelligence from this data remains challenging due to extreme noise, high throughput, and semantic complexity of diverse business lines. In this paper, we present TingIS, an end-to-end system designed for enterprise-grade incident discovery. At the core of TingIS is a multi-stage event linking engine that synergizes efficient indexing techniques with Large Language Models (LLMs) to make informed decisions on event merging, enabling the stable extraction of actionable incidents from just a handful of diverse user descriptions. This engine is complemented by a cascaded routing mechanism for precise business attribution and a multi-dimensional noise reduction pipeline that integrates domain knowledge, statistical patterns, and behavioral filtering. Deployed in a production environment handling a peak throughput of over 2,000 messages per minute and 300,000 messages per day, TingIS achieves a P90 alert latency of 3.5 minutes and a 95\% discovery rate for high-priority incidents. Benchmarks constructed from real-world data demonstrate that TingIS significantly outperforms baseline methods in routing accuracy, clustering quality, and Signal-to-Noise Ratio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TingIS, an end-to-end production system for real-time risk event discovery from noisy customer incidents in large-scale cloud services. Its core is a multi-stage event linking engine that combines efficient indexing with LLMs for stable event merging from sparse user descriptions, augmented by cascaded routing for business attribution and a multi-dimensional noise reduction pipeline using domain knowledge, statistics, and behavioral filters. The system is deployed at >2,000 messages/minute and 300k/day, claiming a P90 alert latency of 3.5 minutes, 95% discovery rate for high-priority incidents, and significant outperformance over baselines in routing accuracy, clustering quality, and signal-to-noise ratio, with all metrics derived from real-world data benchmarks.
Significance. If the quantitative claims can be substantiated with transparent evaluation protocols, the work would be significant for applied NLP and systems research on noisy, high-throughput incident streams. It demonstrates a practical integration of LLMs with classical indexing and filtering for enterprise-scale deployment, addressing a real operational pain point where minutes of latency matter. The production throughput numbers and latency figures, if reproducible, would constitute a strong empirical contribution.
major comments (3)
- [Abstract] Abstract: The headline claims of 95% discovery rate for high-priority incidents and outperformance on routing/clustering/SNR are presented without any definition of the baseline methods, ground-truth construction process for labeling high-priority incidents, dataset construction details, or controls for selection bias across business lines. These omissions make the central empirical claims unverifiable from the text.
- [Abstract] Abstract and Evaluation sections: No quantitative baseline definitions, error bars, ablation results, or description of how discovery is verified (manual review, downstream impact, or oracle) are supplied, despite the metrics being the primary evidence for the system's value. This directly undermines the soundness of the outperformance assertions.
- [Abstract] Abstract: The P90 latency of 3.5 minutes and 95% discovery rate are reported as direct production observations without specifying measurement methodology, data exclusion rules, or how the subset of high-priority incidents was sampled, raising the possibility that figures reflect curated rather than representative conditions.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief high-level diagram or pseudocode of the multi-stage linking engine and cascaded routing to clarify the flow for readers unfamiliar with the architecture.
- Terminology such as 'Signal-to-Noise Ratio' in the context of incident clustering should be explicitly defined or referenced to a standard formulation to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the practical value of TingIS in production-scale incident discovery. We agree that the abstract and evaluation sections require additional detail to make the empirical claims verifiable. We have revised the manuscript to incorporate definitions of baselines, ground-truth processes, ablation studies, error bars, and measurement methodologies. These changes are made while respecting the proprietary and privacy constraints of the real-world production data.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of 95% discovery rate for high-priority incidents and outperformance on routing/clustering/SNR are presented without any definition of the baseline methods, ground-truth construction process for labeling high-priority incidents, dataset construction details, or controls for selection bias across business lines. These omissions make the central empirical claims unverifiable from the text.
Authors: We acknowledge this limitation in the original submission. The revised manuscript now defines the baseline methods explicitly in both the abstract and Evaluation section, including TF-IDF + K-means, DBSCAN, and LLM-only linking without the indexing stage. Ground-truth construction is described as expert annotation by domain specialists on a stratified sample drawn from production logs across 12 business lines, with inter-annotator agreement metrics. Dataset construction details and bias controls via proportional sampling are added to Section 4. These textual additions improve verifiability without releasing sensitive data. revision: yes
-
Referee: [Abstract] Abstract and Evaluation sections: No quantitative baseline definitions, error bars, ablation results, or description of how discovery is verified (manual review, downstream impact, or oracle) are supplied, despite the metrics being the primary evidence for the system's value. This directly undermines the soundness of the outperformance assertions.
Authors: We have addressed this by adding quantitative baseline definitions with concrete accuracy and F1 scores in the Evaluation section. Error bars derived from bootstrap resampling over multiple evaluation windows are now reported. A new ablation subsection quantifies the contribution of each stage (indexing, LLM merging, routing, and filtering). Discovery verification is clarified as a hybrid process combining manual review by incident response teams with correlation to downstream mitigation outcomes and ticket resolution rates. These revisions directly support the soundness of the outperformance claims. revision: yes
-
Referee: [Abstract] Abstract: The P90 latency of 3.5 minutes and 95% discovery rate are reported as direct production observations without specifying measurement methodology, data exclusion rules, or how the subset of high-priority incidents was sampled, raising the possibility that figures reflect curated rather than representative conditions.
Authors: We have expanded the description of the measurement methodology in the revised manuscript. P90 latency is computed from distributed tracing logs across the full production pipeline over a 30-day window, with P90 calculated on all generated alerts. Data exclusion rules now explicitly list removal of synthetic test traffic and scheduled maintenance periods. The high-priority subset for the 95% discovery rate is defined via an internal risk-severity model, sampled proportionally across business lines and validated against post-incident resolution records. These details confirm the figures reflect representative production conditions. revision: yes
- Full release of the raw production incident dataset, exact annotation guidelines, and business-line-specific sampling procedures, which are restricted by enterprise confidentiality and customer privacy policies.
Circularity Check
No circularity: production metrics reported as direct observations, no derivations or fitted parameters
full rationale
The paper is a systems description of a deployed incident discovery pipeline. It reports P90 latency and discovery rates as measured outcomes from live production traffic (over 2,000 messages/min) rather than quantities computed from a model whose parameters were tuned on the same data. No equations, ansatzes, uniqueness theorems, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The central claims rest on external production telemetry and benchmark construction details that are presented as independent evidence, not tautological re-statements of the system itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Customer incidents serve as a vital signal for discovering risks missed by monitoring
Reference graph
Works this paper leans on
-
[1]
2025 , url =
Ann Cao , title =. 2025 , url =
2025
-
[2]
2025 , url =
Barry Elad , title =. 2025 , url =
2025
-
[3]
Density-Based Clustering over an Evolving Data Stream with Noise , booktitle =
Feng Cao and Martin Ester and Weining Qian and Aoying Zhou , editor =. Density-Based Clustering over an Evolving Data Stream with Noise , booktitle =. 2006 , url =. doi:10.1137/1.9781611972764.29 , timestamp =
-
[4]
Aggarwal and Jiawei Han and Jianyong Wang and Philip S
Charu C. Aggarwal and Jiawei Han and Jianyong Wang and Philip S. Yu , editor =. A Framework for Clustering Evolving Data Streams , booktitle =. 2003 , url =. doi:10.1016/B978-012722442-8/50016-1 , timestamp =
-
[5]
Available: https://doi.org/10.1145/3292500.3330680
Mateusz Fedoryszak and Brent Frederick and Vijay Rajaram and Changtao Zhong , editor =. Real-time Event Detection on Social Data Streams , booktitle =. 2019 , url =. doi:10.1145/3292500.3330689 , timestamp =
-
[6]
Embed2Detect: temporally clustered embedded words for event detection in social media , journal =
Hansi Hettiarachchi and Mariam Adedoyin. Embed2Detect: temporally clustered embedded words for event detection in social media , journal =. 2022 , url =. doi:10.1007/S10994-021-05988-7 , timestamp =
-
[7]
Kailash Karthik Saravanakumar and Miguel Ballesteros and Muthu Kumar Chandrasekaran and Kathleen R. McKeown , editor =. Event-Driven News Stream Clustering using Entity-Aware Contextual Embeddings , booktitle =. 2021 , url =. doi:10.18653/V1/2021.EACL-MAIN.198 , timestamp =
-
[8]
Vijay Viswanathan and Kiril Gashteovski and Carolin Lawrence and Tongshuang Wu and Graham Neubig , title =. Trans. Assoc. Comput. Linguistics , volume =. 2024 , url =. doi:10.1162/TACL\_A\_00648 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[9]
Matos-Carvalho and Nuno Fachada , keywords =
Alina Petukhova and João P. Matos-Carvalho and Nuno Fachada , keywords =. Text clustering with large language model embeddings , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.ijcce.2024.11.004 , url =
-
[10]
Proceedings of the 2025 Annual International
Chen Huang and Guoxiu He , title =. Proceedings of the 2025 Annual International. 2025 , url =. doi:10.1145/3767695.3769519 , timestamp =
-
[11]
Ioannidis and Changhe Yuan and Chandan K
Sindhu Tipirneni and Ravinarayana Adkathimar and Nurendra Choudhary and Gaurush Hiranandani and Rana Ali Amjad and Vassilis N. Ioannidis and Changhe Yuan and Chandan K. Reddy , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2405.00988 , eprinttype =. 2405.00988 , timestamp =
-
[12]
Ying Wang and Mengye Ren and Andrew Gordon Wilson , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.08466 , eprinttype =. 2510.08466 , timestamp =
-
[13]
Wei Lu and Ali A. Ghorbani , title =. 2009 , url =. doi:10.1155/2009/837601 , timestamp =
-
[14]
Faraz Rasheed and Peter Peng and Reda Alhajj and Jon G. Rokne , editor =. Fourier Transform Based Spatial Outlier Mining , booktitle =. 2009 , url =. doi:10.1007/978-3-642-04394-9\_39 , timestamp =
-
[15]
Available: https://doi.org/10.1145/3292500.3330680
Hansheng Ren and Bixiong Xu and Yujing Wang and Chao Yi and Congrui Huang and Xiaoyu Kou and Tony Xing and Mao Yang and Jie Tong and Qi Zhang , editor =. Time-Series Anomaly Detection Service at Microsoft , booktitle =. 2019 , url =. doi:10.1145/3292500.3330680 , timestamp =
-
[16]
Joung, Junegak and Kim, Harrison M. , title =. Journal of Mechanical Design , volume =. 2021 , month =. doi:10.1115/1.4048960 , url =
-
[17]
Dense Passage Retrieval for Open-Domain Question Answering
Vladimir Karpukhin and Barlas Oguz and Sewon Min and Patrick Lewis and Ledell Wu and Sergey Edunov and Danqi Chen and Wen. Dense Passage Retrieval for Open-Domain Question Answering , booktitle =. 2020 , url =. doi:10.18653/V1/2020.EMNLP-MAIN.550 , timestamp =
-
[18]
Shichen Liu and Fei Xiao and Wenwu Ou and Luo Si , title =. Proceedings of the 23rd. 2017 , url =. doi:10.1145/3097983.3098011 , timestamp =
-
[19]
Priyaranjan Pattnayak and Amit Agarwal and Hansa Meghwani and Hitesh Laxmichand Patel and Srikant Panda , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.02097 , eprinttype =. 2506.02097 , timestamp =
-
[20]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[21]
Jianlyu Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu , editor =. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.137 , timestamp =
-
[22]
Kimi K2: Open Agentic Intelligence
Kimi Team , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.20534 , eprinttype =. 2507.20534 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2507.20534 2025
-
[23]
D 2 LLM : Decomposed and Distilled Large Language Models for Semantic Search
Liao, Zihan and Yu, Hang and Li, Jianguo and Wang, Jun and Zhang, Wei. D 2 LLM : Decomposed and Distilled Large Language Models for Semantic Search. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.791
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.