PExA: Parallel Exploration Agent for Complex Text-to-SQL
Pith reviewed 2026-05-08 11:51 UTC · model grok-4.3
The pith
An agent for complex text-to-SQL breaks queries into parallel atomic test cases to achieve semantic coverage before generating the final SQL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
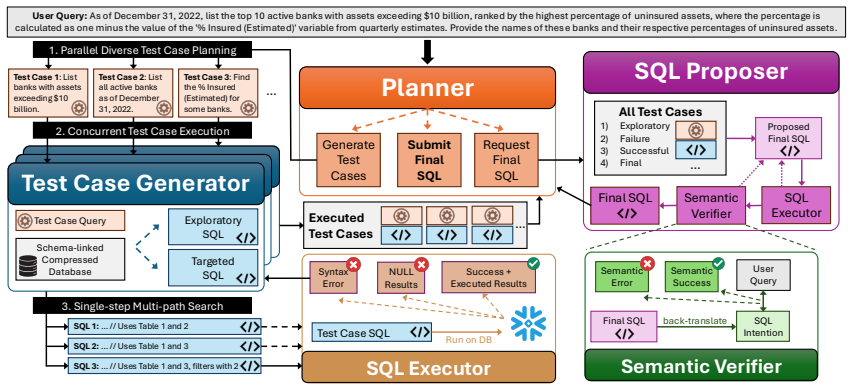
We reformulate text-to-SQL generation within the lens of software test coverage where the original query is prepared with a suite of test cases with simpler, atomic SQLs that are executed in parallel and together ensure semantic coverage of the original query. After iterating on test case coverage, the final SQL is generated only when enough information is gathered, leveraging the explored test case SQLs to ground the final generation. Validation on Spider 2.0 shows 70.2% execution accuracy, establishing a new state of the art.
What carries the argument
The reformulation of text-to-SQL as software test coverage using suites of simpler atomic SQL test cases executed in parallel to ensure semantic coverage.
If this is right
- The parallel execution of atomic test cases allows more efficient information gathering than sequential methods.
- Grounding final SQL generation on the results of explored test cases improves accuracy for complex queries.
- The iteration on test case coverage ensures sufficient semantic information before producing the final output.
- This yields higher execution accuracy on standard benchmarks like Spider 2.0 without proportional latency increases.
Where Pith is reading between the lines
- The explicit coverage approach could extend to other structured generation tasks such as code synthesis or query languages in different domains.
- Making semantic coverage measurable may help identify specific components where LLM agents fail on complex inputs.
- Automatically selecting optimal atomic test cases might reduce the total number of LLM calls required.
Load-bearing premise
That suites of simpler atomic SQL test cases executed in parallel can ensure semantic coverage of the original complex query and that iterating on this coverage gathers enough information to ground accurate final generation.
What would settle it
An experiment on Spider 2.0 showing that the parallel atomic test suite reaches high coverage but the generated final SQL still fails to execute correctly against the database.
Figures






read the original abstract
LLM-based agents for text-to-SQL often struggle with latency-performance trade-off, where performance improvements come at the cost of latency or vice versa. We reformulate text-to-SQL generation within the lens of software test coverage where the original query is prepared with a suite of test cases with simpler, atomic SQLs that are executed in parallel and together ensure semantic coverage of the original query. After iterating on test case coverage, the final SQL is generated only when enough information is gathered, leveraging the explored test case SQLs to ground the final generation. We validated our framework on a state-of-the-art benchmark for text-to-SQL, Spider 2.0, achieving a new state-of-the-art with 70.2% execution accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PExA, a Parallel Exploration Agent for text-to-SQL. It reformulates complex query generation as the parallel execution of simpler atomic SQL test cases designed to ensure semantic coverage of the original query. The framework iterates on coverage until sufficient information is gathered, then generates the final SQL grounded in the explored test cases. It reports a new state-of-the-art execution accuracy of 70.2% on the Spider 2.0 benchmark.
Significance. If the reported result holds under rigorous controls, the work could be significant for LLM-based text-to-SQL agents by offering a structured, coverage-driven approach that may improve both accuracy and latency through parallelism and iteration. The analogy to software test coverage is a fresh framing that could generalize to other agentic generation tasks. The explicit SOTA claim on a standard benchmark provides a clear, falsifiable prediction that future work can test.
major comments (2)
- [method description and experimental validation] The central claim rests on the assertion that parallel atomic SQL test cases plus iteration achieve semantic coverage of complex queries (abstract and method description). No quantitative coverage metric, failure-mode analysis, or ablation on coverage quality is supplied, leaving the weakest assumption untested beyond the aggregate 70.2% accuracy figure.
- [experimental results] The SOTA claim of 70.2% execution accuracy on Spider 2.0 is presented without any description of baselines, number of runs, error analysis, or how coverage iteration is operationalized and measured. This information is load-bearing for assessing whether the framework actually outperforms prior methods or simply benefits from unstated implementation choices.
minor comments (1)
- [abstract and §3] The abstract and method overview use the term 'semantic coverage' without a formal definition or pseudocode for how atomic cases are generated or when iteration stops.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each of the major comments below and will revise the paper accordingly to incorporate additional details and analyses as suggested.
read point-by-point responses
-
Referee: [method description and experimental validation] The central claim rests on the assertion that parallel atomic SQL test cases plus iteration achieve semantic coverage of complex queries (abstract and method description). No quantitative coverage metric, failure-mode analysis, or ablation on coverage quality is supplied, leaving the weakest assumption untested beyond the aggregate 70.2% accuracy figure.
Authors: We agree that the current manuscript would benefit from a more explicit quantitative evaluation of the coverage achieved by the parallel atomic test cases. In the revised version, we will add a coverage metric defined as the fraction of semantic components (tables, columns, conditions) from the original query that are verified through successful execution of the atomic test cases. Additionally, we will include an ablation study removing the iteration step and a failure-mode analysis identifying queries where coverage remains incomplete despite iteration. This will provide stronger evidence for the effectiveness of our approach beyond the final accuracy score. revision: yes
-
Referee: [experimental results] The SOTA claim of 70.2% execution accuracy on Spider 2.0 is presented without any description of baselines, number of runs, error analysis, or how coverage iteration is operationalized and measured. This information is load-bearing for assessing whether the framework actually outperforms prior methods or simply benefits from unstated implementation choices.
Authors: We acknowledge that the experimental section in the current draft lacks sufficient detail on the evaluation protocol. The revised manuscript will include: (1) a table comparing against all relevant baselines on Spider 2.0 with their reported accuracies, (2) results averaged over 3 independent runs with standard deviations to account for variability in LLM outputs, (3) a detailed error analysis breaking down failure cases by query complexity and coverage issues, and (4) a precise description of the coverage iteration process, including the stopping criteria (e.g., when coverage exceeds 90% or after a maximum of 5 iterations) and how the explored test cases are used to ground the final SQL generation. These additions will allow readers to better evaluate the validity of the SOTA claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical agent framework that reformulates text-to-SQL as parallel execution of atomic SQL test cases for coverage, followed by grounded final generation. No equations, fitted parameters, predictions, or derivation steps are present that reduce by construction to the inputs. Validation is performed directly on the external Spider 2.0 benchmark with a reported execution accuracy result. The approach is self-contained as a new method without load-bearing self-citations, self-definitions, or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sqlfixagent: Towards semantic-accurate text- to-sql parsing via consistency-enhanced multi-agent collaboration. InAAAI-25, Sponsored by the Associ- ation for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 49–57. AAAI Press. Yanxi Chen, Xuchen Pan, Yaliang Li, Bolin Ding, and Jingren Zhou. 2024. A simp...
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.CoRR, abs/2501.12948. Minghang Deng, Ashwin Ramachandran, Canwen Xu, Lanxiang Hu, Zhewei Yao, Anupam Datta, and Hao Zhang. 2025. Reforce: A text-to-sql agent with self-refinement, format restriction, and column explo- ration.CoRR, abs/2502.00675. Xiang Deng, Ahmed Hassan ...
work page internal anchor Pith review arXiv 2025
-
[3]
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Xi Victoria Lin, Richard Socher, and Caiming Xiong
work page 2024
-
[4]
InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4870–4888, Online
Bridging textual and tabular data for cross- domain text-to-SQL semantic parsing. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4870–4888, Online. Association for Computational Linguistics. Aiwei Liu, Xuming Hu, Lijie Wen, and Philip S. Yu
work page 2020
-
[5]
A comprehensive evaluation of chatgpt’s zero- shot text-to-sql capability.CoRR, abs/2303.13547. Tao Liu, Hongying Zan, Yifan Li, Dixuan Zhang, Lulu Kong, Haixin Liu, Jiaming Hou, Aoze Zheng, Rui Li, Yiming Qiao, Zewei Luo, Qi Wang, Zhiqiang Zhang, Jiaxi Li, Supeng Liu, Kunli Zhang, and Min Peng. 2025. Logiccat: A chain-of-thought text-to-sql benchmark for...
-
[6]
OpenReview.net. 10 A Additional Related Work We provide a broader related work and the relative position of our work here. Datasets for Text-to-SQLOne of the promi- nent datasets utilized for Text-to-SQL is Spider 1.0 (Yu et al., 2018). Subsequent works also cre- ated various variants like Spider-Realistic (Deng et al., 2021), Spider-DK (Gan et al., 2021)...
work page 2018
-
[7]
Check Question Completeness: If the question is not self-contained or unanswerable, use the "not enough informa- tion" tool with an explanation
-
[8]
Generate many Diverse SQL queries: If answerable, generate as many diverse SQL queries as possible (even if you are confident about your first choice). Each SQL should use a different set of tables. Do NOT simply use the same table with different joins, filters, or aliases and call them diverse. True diversity means using fundamentally different tables or...
-
[9]
Explore Table Schema: Make sure that you are entirely sure about the attribute values before writing the SQL. If you are unsure, you can explore table columns or values using the "execute_sql" tool (using regex or ILIKE functions). Set the exploration attribute to True for such queries. Batch and execute all such exploration queries in a single tool call....
-
[10]
average measurement in a month
Tool Usage: In every response, you must use one of the tools. SQL Writing Guidelines: - MUST stay faithful to the exact wording of the question. Prefer exact table/column matches over partial matches. If an exact-match table exists, do not union with partial matches; only explore alternates if no exact match is found. Examples: If the question mentions ‘t...
work page 2022
-
[11]
Probe: Retrieve a count of banks that reported total assets exceeding 10,000,000,000 (ten billion) dollars for the quarter ending ‘2022-12-31’. SQL: SELECT "V ARIABLE", "V ARIABLE_NAME" FROM "FINANCE_ECONOMICS"."CYBERSYN". "FINAN- CIAL_INSTITUTION_ATTRIBUTES" WHERE LOWER("V ARIABLE_NAME") LIKE ‘%total asset%’; Executed Result (truncated): V ARIABLE,V ARIA...
work page 2022
-
[12]
Back-translate the SQL query: Convert the SQL query (conditioned on the executed result) into natural language query that captures what the SQL query is trying to achieve. This should be a faithful representation of the SQL query and the executed result in natural language
-
[13]
The back-translated query should capture the same intent and meaning as the original question
Comparison for Semantic Verification:Compare the back-translated natural language query (from part 1) with the original question. The back-translated query should capture the same intent and meaning as the original question. - If the back-translated query matches the original question, it indicates that the SQL query is semantically correct. - If the back...
-
[14]
Return a response: Your final response should be a structured JSON of three fields - "correct", "explanation", and "back_translated_query". The "back_translated_query" should always be the query back-translated from step 1. Based on the comparison in step 2: - If the SQL query is semantically correct: "correct" = true and "explanation" = <Provide a one li...
work page 2022
-
[15]
SQL: SELECT "name" AS "package_name", "version", "project_urls", "upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" WHERE "name" IS NOT NULL LIMIT 100; Execution Output (truncated): package_name,version,project_urls,upload_time sparganothis-vim,0.1.15,[],1720561327687084 sparganothis-vim,0.1.15,[],1720561419667601 safa,0.0.1,[],1720564065701497
-
[16]
SQL: WITH "downloads" AS ( SELECT "project" AS "name", "file":"version"::string AS "version", MIN("timestamp") AS "first_download_ts" FROM "PYPI"."PYPI"."FILE_DOWNLOADS" GROUP BY "project", "file":"version"::string ) SELECT d."name" AS "package_name", d."version", d."project_urls", d."upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" d JOIN "downloa...
-
[17]
SQL: SELECT d."name" AS "package_name", d."version", d."project_urls", d."upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" d JOIN "PYPI"."INFORMATION_SCHEMA"."TABLES" t ON t."TABLE_NAME" = ’DISTRIBU- TION_METADATA’ LIMIT 100; Execution Output (truncated): package_name,version,project_urls,upload_time sparganothis-vim,0.1.15,[],1720561327687084 spar...
-
[18]
SQL: SELECT "project" AS "package_name", "file":"version"::string AS "version", NULL AS "project_urls", MIN("timestamp") AS "upload_time" FROM "PYPI"."PYPI"."FILE_DOWNLOADS" GROUP BY "project", "file":"version"::string LIMIT 100; Execution Output (truncated): package_name,version,project_urls,upload_time bs- solevaluator,0.1.1„1649607460000000 django-grap...
-
[19]
SQL: SELECT "name" AS "package_name", "version", "project_urls" AS "project_urls", "up- load_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" LIMIT 10; Execution Output (truncated): package_name,version,project_urls,upload_time sparganothis-vim,0.1.15,[],1720561327687084 sparganothis-vim,0.1.15,[],1720561419667601 safa,0.0.1,[],1720564065701497 24 Table 1...
-
[20]
SQL: SELECT COUNT(*) AS cnt_non_empty FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" WHERE "project_urls" IS NOT NULL AND ARRAY_SIZE("project_urls") > 0; Execution Output (truncated): CNT_NON_EMPTY 42893
-
[21]
SQL: SELECT "name" AS "package_name", "version", "project_urls", "upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" WHERE "project_urls" IS NOT NULL AND ARRAY_SIZE("project_urls") > 0 LIMIT 10; Execution Output (truncated): package_name,version,project_urls,upload_time renovosolutions.aws- cdk-aspects-security-group,1.0.214,"[ ""Source, https://gith...
-
[22]
SQL: SELECT COUNT(*) FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" WHERE "project_url" IS NOT NULL; Failure Message: SQL execution generated an error: ##ERROR##000904 (42000): SQL compilation error: error line 3 at position 6 invalid identifier ’"project_url"’ Please correct the query. Finish SELECT "name"AS"package_name", "version", "project_urls", "upload_...
-
[23]
SQL: SELECT "project" AS "package_name", COUNT(*) AS "total_downloads" FROM "PYPI"."PYPI"."FILE_DOWNLOADS" GROUP BY "project" ORDER BY "total_downloads" DESC; Execution Output (truncated): package_name,total_downloads s3transfer,2962234 attrs,1787211 col- orama,1567249
-
[24]
SQL: SELECT dm."name" AS "package_name", COUNT(*) AS "total_downloads" FROM "PYPI"."PYPI"."FILE_DOWNLOADS" fd JOIN ( SELECT DISTINCT "name" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" ) dm ON fd."project" = dm."name" GROUP BY dm."name" ORDER BY "total_downloads" DESC; Execution Output (truncated): package_name,total_downloads wheel,1481586 tabulate,1478960...
-
[25]
SQL: SELECT "name", "version", "project_urls", "upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" WHERE "project_urls"::string ILIKE ’%github.com%’ LIMIT 10; Execution Output (truncated): name,version,project_urls,upload_time track-viz,0.5.0,"[ ""Changelog, https://github.com/JulienMBABD/track-viz/releases"", ""Documentation, https://track- viz.read...
-
[26]
SQL: SELECT DISTINCT dm."name", dm."version", dm."project_urls", dm."upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" dm JOIN "PYPI"."PYPI"."FILE_DOWNLOADS" fd ON dm."name" = fd."project" WHERE dm."project_urls"::string ILIKE ’%github.com%’ LIMIT 10; Execution Output (truncated): name,version,project_urls,upload_time iron- toolbox,1.0.45,"[ ""Bug T...
-
[27]
SQL: SELECT dm."name", dm."version", dm."project_urls", dm."upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" dm JOIN "PYPI"."INFORMATION_SCHEMA"."TABLES" t ON t."TABLE_NAME" = ’DISTRIBU- TION_METADATA’ AND t."TABLE_SCHEMA" = ’PYPI’ WHERE dm."project_urls"::string ILIKE ’%github.com%’ LIMIT 10; Execution Output (truncated): name,version,project_urls...
-
[28]
SQL: SELECT DISTINCT dm."name", dm."version", dm."project_urls", dm."upload_time" FROM "PYPI"."PYPI"."DISTRIBUTION_METADATA" dm JOIN "PYPI"."PYPI"."FILE_DOWNLOADS" fd ON dm."name" = fd."project" JOIN "PYPI"."INFORMATION_SCHEMA"."TABLES" t ON t."TABLE_NAME" = ’DISTRIBUTION_METADATA’ AND t."TABLE_SCHEMA" = ’PYPI’ WHERE dm."project_urls"::string ILIKE ’%gith...
- [29]
-
[30]
Extract theraw GitHub URL substring, then normalise it to the repo root--(https://github.com/<owner>/<repo>), removing trailing path fragments-- and apossible ".git".-- 4. Join these packages to their total download counts and pickthe top 3.------------------------------------------------------------------------ WITH "latest_metadata" AS ( SELECT "name" A...
-
[31]
Extract the substring up to repo root (owner/repo)
-
[32]
git" (with optional slash). */ SELECT DISTINCT
Remove a trailing ".git" (with optional slash). */ SELECT DISTINCT"package_name", /* step-A: repo root substring */ REGEXP_SUBSTR(LOWER("url_element"),'https?://github\\.com/[^/]+/[^/]+')AS "root_url" FROMflattened ), normalised_urlsAS( SELECT"package_name", -- step-B: drop trailing .git and any trailing slash RTRIM(REGEXP_REPLACE("root_url",'\\.git$','')...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.