From Chatbots to Confidants: A Cross-Cultural Study of LLM Adoption for Emotional Support
Pith reviewed 2026-05-21 00:15 UTC · model grok-4.3
The pith
Socioeconomic status, age, marriage and religion predict who trusts LLMs for emotional support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
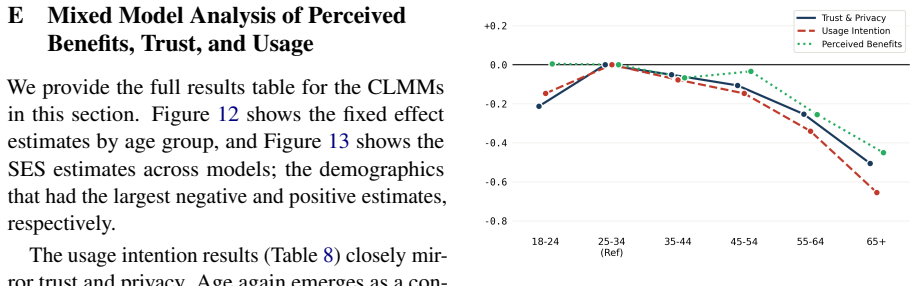
Mixed models fitted to the survey responses establish that being aged 25-44, religious, married, and of higher socioeconomic status are predictors of positive perceptions of LLMs for emotional support, with socioeconomic status the strongest factor, and that English-speaking countries show consistently more positive perceptions than Continental European countries.
What carries the argument
Mixed-effects models that separate country-level cultural effects from individual demographic composition in responses from 4,641 participants.
If this is right
- Adoption rates for emotional support use range from 20% to 59% across the studied countries.
- Users mainly seek help with loneliness, stress, relationship conflicts, and mental health struggles.
- Positive perceptions of trust and benefits concentrate among specific demographic groups rather than appearing evenly.
- Cultural differences in openness persist independently of the demographic makeup of each country.
Where Pith is reading between the lines
- If socioeconomic status is the strongest predictor, access to emotional AI support may widen existing resource gaps unless design or policy interventions target lower-status groups.
- The persistent English-speaking versus Continental European difference points to possible effects of language resources or broader technology attitudes that future studies could test directly.
- The collected prompts offer a starting point for identifying recurring user needs that could guide safety features or moderation in emotional-support LLMs.
- These demographic and cultural patterns may shift as public familiarity with the technology grows or as regulatory standards for mental-health-adjacent AI are introduced.
Load-bearing premise
The models successfully isolate cultural effects from demographic composition and the sample represents the general adult populations in the seven countries.
What would settle it
A replication study using different sampling or modeling methods that finds no reliable link between socioeconomic status and positive perceptions of LLM emotional support would undermine the central claim.
Figures













read the original abstract
Large Language Models (LLMs) are increasingly used not only for instrumental tasks, but as always-available and non-judgmental confidants for emotional support. Yet what drives adoption and how users perceive emotional support interactions across countries remains unknown. To address this gap, we present the first large-scale cross-cultural study of LLM use for emotional support, surveying 4,641 participants across seven countries (USA, UK, Germany, France, Spain, Italy, and The Netherlands). Our results show that adoption rates vary dramatically across countries (from 20% to 59%). Using mixed models that separate cultural effects from demographic composition, we find that: Being aged 25-44, religious, married, and of higher socioeconomic status are predictors of positive perceptions (trust, usage, perceived benefits), with socioeconomic status being the strongest. English-speaking countries consistently show more positive perceptions than Continental European countries. We further collect a corpus of 731 real multilingual prompts from user interactions, showing that users mainly seek help for loneliness, stress, relationship conflicts, and mental health struggles. Our findings reveal that LLM emotional support use is shaped by a complex sociotechnical landscape and call for a broader research agenda examining how these systems can be developed, deployed, and governed to ensure safe and informed access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports the first large-scale cross-cultural survey of LLM use for emotional support, with 4,641 participants across seven countries (USA, UK, Germany, France, Spain, Italy, Netherlands). Adoption rates range from 20% to 59%. Mixed models identify age 25-44, religiosity, marriage, and higher socioeconomic status as predictors of positive perceptions (trust, usage, benefits), with SES strongest; English-speaking countries show more positive views than Continental European ones. A corpus of 731 real multilingual user prompts is analyzed, revealing primary themes of loneliness, stress, relationship conflicts, and mental health struggles.
Significance. If the sampling and modeling concerns are resolved, this would be a valuable contribution as the first large-scale primary-data study on this topic. Strengths include the collection of new survey responses and a real-world multilingual prompt corpus, plus the use of mixed models to attempt separation of cultural and demographic effects. The work has clear implications for understanding sociotechnical drivers of LLM adoption and for governance of emotional-support applications.
major comments (2)
- [§2 (Survey Design and Participants)] §2 (Survey Design and Participants): The recruitment procedure for the 4,641 respondents is described only at a high level. No response rates, sampling frame, or post-stratification details are provided. This is load-bearing for the central claims, because online-panel self-selection could systematically over-represent digitally comfortable or LLM-exposed individuals, thereby inflating adoption rates, strengthening the SES coefficient, and artifactually widening the English-speaking vs. Continental-Europe contrast.
- [§4 (Mixed-Effects Models)] §4 (Mixed-Effects Models): The abstract asserts that the models 'separate cultural effects from demographic composition,' yet the main text supplies neither the full model specification (fixed effects for demographics and country, random effects structure) nor diagnostics (variance components, ICC, or fit statistics). Without these, it is impossible to verify that the reported demographic gradients are not themselves products of differential panel participation across countries.
minor comments (1)
- [Abstract] Abstract: Adding one sentence on recruitment method and achieved response rate would help readers assess the strength of the predictor claims without having to reach the methods section.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We have addressed each major concern point by point below, making revisions to the manuscript where appropriate to improve methodological transparency while preserving the integrity of our findings.
read point-by-point responses
-
Referee: §2 (Survey Design and Participants): The recruitment procedure for the 4,641 respondents is described only at a high level. No response rates, sampling frame, or post-stratification details are provided. This is load-bearing for the central claims, because online-panel self-selection could systematically over-represent digitally comfortable or LLM-exposed individuals, thereby inflating adoption rates, strengthening the SES coefficient, and artifactually widening the English-speaking vs. Continental-Europe contrast.
Authors: We agree that greater detail on recruitment would strengthen the paper. In the revised manuscript we have expanded §2 to specify the sampling frame (quota sampling through a commercial online panel targeting age, gender, and regional representativeness in each country), the application of post-stratification weights calibrated to national census benchmarks, and an explicit limitations subsection discussing possible self-selection related to digital access and LLM familiarity. Exact response rates are unavailable from the panel vendor, a standard constraint in commercial online surveys; we have therefore added text acknowledging this limitation and explaining why cross-country comparisons remain informative given the uniform recruitment protocol across all seven nations. revision: partial
-
Referee: §4 (Mixed-Effects Models): The abstract asserts that the models 'separate cultural effects from demographic composition,' yet the main text supplies neither the full model specification (fixed effects for demographics and country, random effects structure) nor diagnostics (variance components, ICC, or fit statistics). Without these, it is impossible to verify that the reported demographic gradients are not themselves products of differential panel participation across countries.
Authors: We accept that the model details were insufficiently specified. The revised §4 now presents the full specification: a mixed-effects logistic regression with fixed effects for age group (25-44 vs. others), religiosity, marital status, socioeconomic status, and country indicators, plus random intercepts at the country level. We additionally report variance components, the intraclass correlation coefficient (ICC = 0.04), and model fit statistics (AIC/BIC) both in the main text and in a new supplementary table. These additions allow readers to evaluate the separation of cultural and demographic effects; we maintain that the mixed-model approach provides useful evidence on this point while acknowledging that observational data cannot eliminate all possible confounding from differential participation. revision: yes
Circularity Check
No circularity: new primary survey data analyzed with standard mixed models
full rationale
The paper collects fresh survey responses from 4,641 participants and 731 user prompts across seven countries, then applies mixed models to identify demographic and country-level predictors of LLM adoption for emotional support. No equations, fitted parameters, or predictions are shown to reduce by construction to prior inputs or self-citations; the central claims rest on direct statistical analysis of the newly gathered data rather than any self-referential derivation chain. This is a standard empirical study whose results are externally falsifiable against the collected sample and do not rely on load-bearing self-citations or ansatzes imported from prior work.
Axiom & Free-Parameter Ledger
free parameters (1)
- mixed model coefficients for demographics and culture
axioms (2)
- domain assumption Self-reported survey answers accurately reflect participants' actual LLM usage and perceptions of emotional support
- domain assumption The seven selected countries allow meaningful separation of cultural from demographic influences
Reference graph
Works this paper leans on
-
[1]
Nancy E Adler, Elissa S Epel, Grace Castellazzo, and Jeannette R Ickovics. 2000. Relationship of subjective and objective social status with psychological and physiological functioning: Preliminary data in healthy, white women. Health psychology, 19(6):586
work page 2000
-
[2]
Marta Andersson. 2025. Companionship in code: Ai’s role in the future of human connection. Humanities and Social Sciences Communications, 12(1):1--7
work page 2025
-
[3]
Autoriteit Persoonsgegevens . 2025. https://www.autoriteitpersoonsgegevens.nl/en/documents/ai-algorithmic-risks-report-netherlands-arr-february-2025 AI & Algorithmic Risks Report Netherlands (ARR) . Technical report, Dutch Data Protection Authority
work page 2025
-
[4]
Elisa Bassignana, Amanda Cercas Curry, and Dirk Hovy. 2025. https://doi.org/10.18653/v1/2025.acl-long.914 The AI gap: How socioeconomic status affects language technology interactions . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18647--18664, Vienna, Austria. Association for Co...
-
[5]
Gillian Cameron, David Cameron, Gavin Megaw, Raymond Bond, Maurice Mulvenna, Siobhan O’Neill, Cherie Armour, and Michael McTear. 2018. Assessing the usability of a chatbot for mental health care. In International conference on internet science, pages 121--132. Springer
work page 2018
-
[6]
Aaron Chatterji, Thomas Cunningham, David J. Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. 2025. https://doi.org/10.3386/w34255 How people use chatgpt . Working Paper 34255, National Bureau of Economic Research
-
[7]
Beenish Moalla Chaudhry and Hamid Reza Debi. 2024. https://doi.org/10.21037/mhealth-23-55 User perceptions and experiences of an AI -driven conversational agent for mental health support . mHealth, 10:22
-
[8]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.137 M 3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation . In Findings of the Association for Computational Linguistics: ACL 2024, pages 2318--2335, Bangkok,...
-
[9]
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. 2025. Elephant: Measuring and understanding social sycophancy in llms. arXiv preprint arXiv:2505.13995
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
Jung, Nicola Dell, Deborah Estrin, and James A
Andrea Cuadra, Maria Wang, Lynn Andrea Stein, Malte F. Jung, Nicola Dell, Deborah Estrin, and James A. Landay. 2024. https://doi.org/10.1145/3613904.3642336 The illusion of empathy? notes on displays of emotion in human-computer interaction . In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, CHI '24, New York, NY, USA. Assoc...
-
[12]
Alba Curry and Amanda Cercas Curry. 2023. https://doi.org/10.18653/v1/2023.findings-acl.515 Computer says ``no'': The case against empathetic conversational AI . In Findings of the Association for Computational Linguistics: ACL 2023, pages 8123--8130, Toronto, Canada. Association for Computational Linguistics
-
[13]
Fred D. Davis. 1989. https://doi.org/10.2307/249008 Perceived usefulness, perceived ease of use, and user acceptance of information technology . MIS quarterly, 13(3):319--340
-
[14]
Julian De Freitas, Stuti Agarwal, Bernd Schmitt, and Nick Haslam. 2023. Psychological factors underlying attitudes toward ai tools. Nature Human Behaviour, 7(11):1845--1854
work page 2023
-
[15]
Malena Digiuni, Fergal W Jones, and Paul M Camic. 2013. Perceived social stigma and attitudes towards seeking therapy in training: A cross-national study. Psychotherapy, 50(2):213
work page 2013
-
[16]
Andrea Fiorillo. 2025. A roadmap for better and personalized mental health care in europe: the priorities of the european psychiatric association. European Psychiatry, 68(1):e60
work page 2025
-
[17]
FirstPageSage . 2026. https://firstpagesage.com/seo-blog/chatgpt-usage-statistics/ Chatgpt usage statistics: February 2026 . Accessed: 2026-02-26
work page 2026
- [18]
-
[19]
Yanzhu Guo, Simone Conia, Zelin Zhou, Min Li, Saloni Potdar, and Henry Xiao. 2025. Do large language models have an english accent? evaluating and improving the naturalness of multilingual llms. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3823--3838
work page 2025
-
[20]
It Listens Better Than My Therapist
Anna-Carolina Haensch. 2025. https://doi.org/10.48550/arXiv.2504.12337 "it listens better than my therapist": Exploring social media discourse on llms as mental health tool . arXiv preprint arXiv:2504.12337
-
[21]
Yu Hou, Hal Daum \'e Iii, and Rachel Rudinger. 2025. https://doi.org/10.18653/v1/2025.naacl-long.611 Language models predict empathy gaps between social in-groups and out-groups . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers...
-
[22]
Adam N Joinson. 2001. Self-disclosure in computer-mediated communication: The role of self-awareness and visual anonymity. European journal of social psychology, 31(2):177--192
work page 2001
- [23]
-
[24]
Frederic Marimon, Natalia Amat-Lefort, Marta Mas-Machuca, and Anna Akhmedova. 2024. https://doi.org/10.17632/zd56zx44h7.1 GPT-QUAL [dataset and questionnaire]
-
[25]
Leland McInnes, John Healy, and Steve Astels. 2017. https://doi.org/10.21105/joss.00205 hdbscan: Hierarchical density based clustering . Journal of Open Source Software, 2(11):205
-
[26]
Leland McInnes, John Healy, and James Melville. 2020. https://arxiv.org/abs/1802.03426 Umap: Uniform manifold approximation and projection for dimension reduction . Preprint, arXiv:1802.03426
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[27]
Clifford Nass and Youngme Moon. 2000. Machines and mindlessness: Social responses to computers. Journal of social issues, 56(1):81--103
work page 2000
-
[28]
Lara Oblak. 2025. Public mental health stigma and suicide rates across europe. Frontiers in public health, 13:1554072
work page 2025
-
[29]
OpenAI . 2025. Introducing GPT-5.2 . https://openai.com/index/introducing-gpt-5-2/. Accessed: 2026-03-04
work page 2025
-
[30]
Aditya Pandya, Param Lodha, and Amit Ganatra. 2024. https://doi.org/10.3389/fhumd.2023.1289255 Is ChatGPT ready to change mental healthcare? Challenges and considerations: a reality-check . Frontiers in Human Dynamics, 5:1289255
-
[31]
Hashai Papneja and Nikhil Yadav. 2025. Self-disclosure to conversational ai: a literature review, emergent framework, and directions for future research. Personal and ubiquitous computing, 29(2):119--151
work page 2025
-
[32]
Sarah Perez. 2025. https://techcrunch.com/2025/07/25/sam-altman-warns-theres-no-legal-confidentiality-when-using-chatgpt-as-a-therapist/ Sam altman warns there’s no legal confidentiality when using chatgpt as a therapist
work page 2025
-
[33]
Cercas Curry, Amanda Cercas Curry, and Dirk Hovy
Flor Miriam Plaza-del Arco, Alba A. Cercas Curry, Amanda Cercas Curry, and Dirk Hovy. 2024 a . https://aclanthology.org/2024.lrec-main.506/ Emotion analysis in NLP : Trends, gaps and roadmap for future directions . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), ...
work page 2024
-
[34]
Flor Miriam Plaza-del Arco, Amanda Cercas Curry, Alba Curry, Gavin Abercrombie, and Dirk Hovy. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.415 Angry men, sad women: Large language models reflect gendered stereotypes in emotion attribution . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[35]
Flor Miriam Plaza-del Arco, Amanda Cercas Curry, Susanna Paoli, Alba Cercas Curry, and Dirk Hovy. 2024 c . https://doi.org/10.18653/v1/2024.findings-emnlp.251 Divine LL a MA s: Bias, stereotypes, stigmatization, and emotion representation of religion in large language models . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages...
-
[36]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/v1/D19-1410 Sentence- BERT : Sentence embeddings using S iamese BERT -networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982--3992, Hong Kong, Chi...
-
[37]
Beatrice Savoldi, Giuseppe Attanasio, Olga Gorodetskaya, Marta Marchiori Manerba, Elisa Bassignana, Silvia Casola, Matteo Negri, Tommaso Caselli, Luisa Bentivogli, Alan Ramponi, and 1 others. 2025. Generative ai practices, literacy, and divides: An empirical analysis in the italian context. arXiv preprint arXiv:2512.03671
work page internal anchor Pith review arXiv 2025
-
[38]
Matthias Schmidmaier, Jan Rupp, Darina Cvetanova, and Sven Mayer. 2024. https://doi.org/10.1145/3613904.3642035 Perceived empathy of technology scale ( PETS ): Measuring empathy of systems toward the user . In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1--18
-
[39]
Judy L Todd and Ariella Shapira. 1974. Us and british self-disclosure, anxiety, empathy, and attitudes to psychotherapy. Journal of Cross-Cultural Psychology, 5(3):364--369
work page 1974
-
[40]
Alec Tyson, Giancarlo Pasquini, Alison Spencer, and Cary Funk. 2023. https://www.pewresearch.org/science/2023/02/22/60-of-americans-would-be-uncomfortable-with-provider-relying-on-ai-in-their-own-health-care/ 60\ Technical report, Pew Research Center
work page 2023
-
[41]
Andrea Varaona, Rosa M Molina-Ruiz, Luis Guti \'e rrez-Rojas, Maria Perez-P \'a ramo, Guillermo Lahera, Carolina Donat-Vargas, and Miguel Angel Alvarez-Mon. 2024. Snapshot of knowledge and stigma toward mental health disorders and treatment in spain. Frontiers in Psychology, 15:1372955
work page 2024
-
[42]
Shenghan Wu, Yimo Zhu, Wynne Hsu, Mong-Li Lee, and Yang Deng. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.277 From personas to talks: Revisiting the impact of personas on LLM -synthesized emotional support conversations . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5439--5453, Suzhou, China. Assoc...
-
[43]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[44]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.