Recognition: unknown
Quantamination: Dynamic Quantization Leaks Your Data Across the Batch
Pith reviewed 2026-05-07 10:49 UTC · model grok-4.3
The pith
Dynamic quantization in ML frameworks leaks private user data across inputs in the same batch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
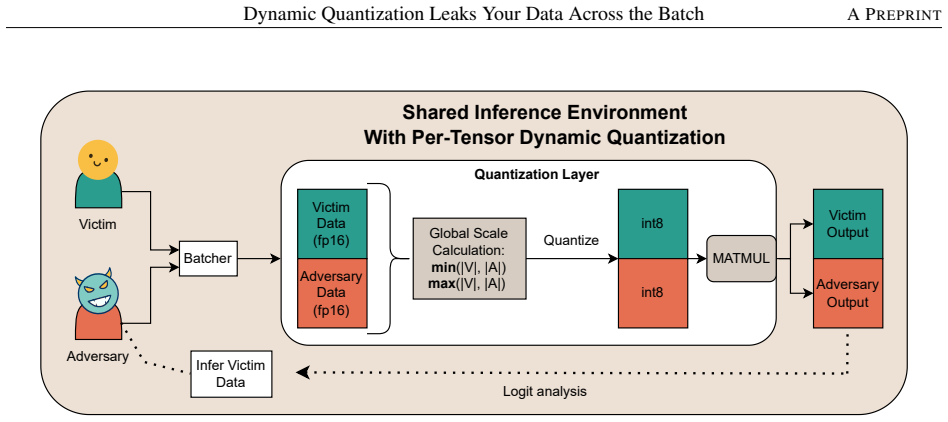
Dynamic quantization creates side channels that allow an adversary to steal sensitive user data placed in the same batch as the adversary's input. When quantization parameters are computed over the full batch without isolating individual contributions, information about other inputs leaks through the adapted scales and representations. This enables partial or full recovery of batched input data in vulnerable configurations of popular frameworks, despite the efficiency gains from runtime adaptation.
What carries the argument
Quantamination, the leakage of input data that occurs when dynamic quantization computes its scaling parameters over the entire batch rather than per input.
If this is right
- Attackers can partially or fully recover other users' batched input data through the side channel.
- At least four major ML frameworks are vulnerable either by default or in standard configurations.
- Efficiency recommendations for dynamic quantization in model serving must now include privacy considerations.
- Data leakage can occur in shared serving environments even when models retain high accuracy.
Where Pith is reading between the lines
- Similar batch-level statistics in other runtime optimizations like pruning or caching could create parallel privacy leaks.
- Cloud ML providers may need to enforce per-user batch isolation to block cross-input observation.
- For sensitive data, static quantization or single-input inference becomes preferable over dynamic methods.
Load-bearing premise
Dynamic quantization implementations derive scaling parameters from the full batch content without isolating each input's contribution.
What would settle it
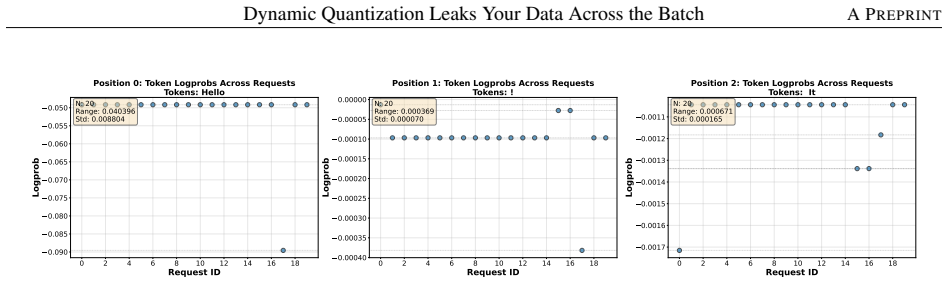
An experiment that adds a known adversarial input to a batch and checks whether the observed quantization scale or zero-point for a target input changes in a way that permits reconstruction of the target's original values.
Figures


read the original abstract
Dynamic quantization emerged as a practical approach to increase the utilization and efficiency of the machine learning serving flow. Unlike static quantization, which applies quantization offline, dynamic quantization operates on tensors at run-time, adapting its parameters to the actual input data. Today's mainstream machine learning frameworks, including ML compilers and inference engines, frequently recommend dynamic quantization as an initial step for optimizing model serving. This is because dynamic quantization can significantly reduce memory usage and computational load, leading to faster token generation and improved model serving efficiency without substantial loss in model accuracy. In this paper, we reveal a critical vulnerability in dynamic quantization: an adversary can exploit such quantization strategy to steal sensitive user data placed in the same batch as the adversary's input. Our analysis demonstrates that dynamic quantization, when improperly implemented or configured, can create side channels that expose information about other inputs within the same batch. We call this phenomenon Quantamination, describing contamination from quantization. Specifically, we show that at least 4 of the most popular ML frameworks in use today either default to or can use configurations that leak data across the batch boundary. This data leakage, in theory, allows attackers to partially or even fully recover other users' batched input data, representing a serious privacy risk for existing ML serving frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that dynamic quantization implementations in at least four popular ML frameworks create side-channel leakage of other users' data across batch boundaries, enabling partial or full recovery of sensitive inputs by an adversary sharing the batch; the authors term this 'Quantamination' and present it as a privacy risk in production serving.
Significance. If the recovery claim holds with concrete, reproducible attacks, the result would identify a practical privacy flaw in widely deployed inference optimizations and could affect multi-tenant serving practices.
major comments (2)
- Abstract: the assertion that the side-channel 'allows attackers to partially or even fully recover other users' batched input data' is not supported by the described evidence. Shared min/max or scale/zero-point statistics create dependence on the batch aggregate, but the manuscript does not demonstrate an invertible mapping from an adversary's observable outputs back to arbitrary victim inputs.
- Experimental section (implied by abstract): the claim of demonstration 'across four frameworks' lacks reported attack success rates, false-positive rates, input-recovery fidelity metrics, or controls for batch composition, leaving the practical exploitability of the leakage unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, clarifying the evidence for the side-channel leakage and committing to strengthen the presentation with additional details and experiments where appropriate.
read point-by-point responses
-
Referee: Abstract: the assertion that the side-channel 'allows attackers to partially or even fully recover other users' batched input data' is not supported by the described evidence. Shared min/max or scale/zero-point statistics create dependence on the batch aggregate, but the manuscript does not demonstrate an invertible mapping from an adversary's observable outputs back to arbitrary victim inputs.
Authors: The manuscript establishes that dynamic quantization computes min/max (or scale/zero-point) over the entire batch, creating a direct mathematical dependence: the adversary's quantized output is a function of both their own input and the victim's input. This is formalized in the analysis of the quantization parameter computation and illustrated with concrete examples across frameworks showing that victim inputs alter the adversary's observable results. While we do not claim or demonstrate a universal closed-form inversion for arbitrary victim inputs (which would require solving an underdetermined system without distributional assumptions), the leakage enables practical partial recovery of victim features and full recovery in restricted settings (e.g., small batches or low-entropy inputs). The abstract's phrasing 'in theory, allows... partially or even fully recover' reflects this. We will revise the abstract for precision and add an explicit discussion of invertibility conditions and attack feasibility. revision: partial
-
Referee: Experimental section (implied by abstract): the claim of demonstration 'across four frameworks' lacks reported attack success rates, false-positive rates, input-recovery fidelity metrics, or controls for batch composition, leaving the practical exploitability of the leakage unclear.
Authors: The current manuscript demonstrates the leakage mechanism across four frameworks through implementation analysis, parameter formulas, and illustrative cases where co-batching changes outputs. We acknowledge that quantitative attack metrics are absent, as the focus was on identifying the fundamental side channel. We will add a new experimental evaluation section reporting: success rates for feature and full-input recovery, false-positive rates for batch-membership inference, fidelity metrics (e.g., exact match rate and MSE for recovered tensors), and controls over batch size/composition. These will be run on the four frameworks to quantify exploitability. revision: yes
Circularity Check
No circularity: empirical security demonstration
full rationale
The paper presents an empirical security analysis demonstrating that dynamic quantization in popular ML frameworks can leak batch-level information. The central claim rests on direct testing of framework implementations (TensorFlow, PyTorch, ONNX Runtime, etc.) and observation of shared min/max/scale computation across inputs, with no equations, fitted parameters, or mathematical derivations that could reduce to prior results by construction. No self-citations form a load-bearing chain, and the work does not rename known results or import uniqueness theorems. The finding is self-contained against external benchmarks of framework behavior.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stealing user prompts from mixture of experts
Itay Yona, Ilia Shumailov, Jamie Hayes, and Nicholas Carlini. Stealing user prompts from mixture of experts. arXiv preprint arXiv:2410.22884,
-
[2]
Buffer overflow in mixture of experts
Jamie Hayes, Ilia Shumailov, and Itay Yona. Buffer overflow in mixture of experts. arXiv preprint arXiv:2402.05526,
-
[3]
Architectural backdoors for within-batch data stealing and model inference manipulation
Nicolas Küchler, Ivan Petrov, Conrad Grobler, and Ilia Shumailov. Architectural backdoors for within-batch data stealing and model inference manipulation. arXiv preprint arXiv:2505.18323,
-
[4]
I know what you asked: Prompt leakage via kv-cache sharing in multi-tenant llm serving
Guanlong Wu, Zheng Zhang, Yao Zhang, Weili Wang, Jianyu Niu, Ye Wu, and Yinqian Zhang. I know what you asked: Prompt leakage via kv-cache sharing in multi-tenant llm serving. In Proceedings of the 2025 Network and Distributed System Security (NDSS) Symposium. San Diego, CA, USA,
2025
-
[5]
Forensicability of deep neural network inference pipelines
Alexander Schlögl, Tobias Kupek, and Rainer Böhme. Forensicability of deep neural network inference pipelines. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2515–2519,
2021
-
[6]
doi:10.1109/ICASSP39728.2021.9414301. Alexander Schlögl, Tobias Kupek, and Rainer Böhme. iNNformant: Boundary samples as tell-tale watermarks. In Workshop on Information Hiding and Multimedia Security (IH&MMSec), pages 81–86. ACM,
-
[7]
URL https://openreview. net/forum?id=kdmjVF1iDO. Eleanor Clifford, Adhithya Saravanan, Harry Langford, Cheng Zhang, Yiren Zhao, Robert Mullins, Ilia Shumailov, and Jamie Hayes. Locking machine learning models into hardware. arXiv preprint arXiv:2405.20990,
-
[8]
Exploiting verified neural networks via floating point numerical error
Kai Jia and Martin Rinard. Exploiting verified neural networks via floating point numerical error. In Static Analysis: 28th International Symposium, SAS 2021, Chicago, IL, USA, October 17–19, 2021, Proceedings 28, pages 191–205. Springer,
2021
-
[9]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review arXiv
-
[10]
Quantizing deep convolutional networks for efficient inference: A whitepaper
Raghuraman Krishnamoorthi. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv preprint arXiv:1806.08342,
-
[11]
Integer quantization for deep learning inference: Principles and empirical evaluation
Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev, and Paulius Micikevicius. Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv preprint arXiv:2004.09602,
-
[12]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer
Accessed: 2025-02-04. Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in neural information processing systems, 35:30318–30332,
2025
-
[13]
Microsoft
Accessed: 2025-02-04. Microsoft. Onnx runtime quantization documentation. https://onnxruntime.ai/docs/performance/ model-optimizations/quantization.html,
2025
-
[14]
PyTorch Team
Accessed: 2025-02-04. PyTorch Team. Pytorch quantization documentation. https://pytorch.org/docs/stable/quantization.html,
2025
-
[15]
12 Dynamic Quantization Leaks Your Data Across the BatchA PREPRINT Google
Accessed: 2025-02-04. 12 Dynamic Quantization Leaks Your Data Across the BatchA PREPRINT Google. Post-training quantization. https://ai.google.dev/edge/litert/conversion/tensorflow/ quantization/post_training_quantization,
2025
-
[16]
Alan Kelly
Accessed: 2025-02-04. Alan Kelly. Faster dynamically quantized inference with xnnpack. https://blog.tensorflow.org/2024/04/ faster-dynamically-quantized-inference-with-xnnpack.html, April
2025
-
[17]
Red Hat AI and vLLM Project
Accessed: 2025-02-09. Red Hat AI and vLLM Project. LLM Compressor, 8
2025
-
[18]
PyTorch Contributors
Accessed: 2025-02-09. PyTorch Contributors. PerTensor — PyTorch documentation,
2025
-
[19]
Tinystories: How small can language models be and still speak coherent english?
URL https://docs.pytorch.org/docs/ stable/generated/torch.ao.quantization.observer.PerTensor.html. Accessed: 2025-02-22. Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english? arXiv preprint arXiv:2305.07759,
-
[20]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
URLhttps://arxiv.org/abs/2502.02737. Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Leandro von Werra, and Thomas Wolf. Smollm - blazingly fast and remarkably powerful,
work page internal anchor Pith review arXiv
-
[21]
URL https://doi.org/10.5281/zenodo.5297715. If you use this software, please cite it using these metadata. Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027,
-
[22]
nii.ac.jp/crid/1571417126193283840
URL https://cir. nii.ac.jp/crid/1571417126193283840. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.