Recognition: unknown
Synthetic Computers at Scale for Long-Horizon Productivity Simulation
Pith reviewed 2026-05-07 06:59 UTC · model grok-4.3
The pith
Synthetic computers at scale let agents simulate month-long productivity work to generate training signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
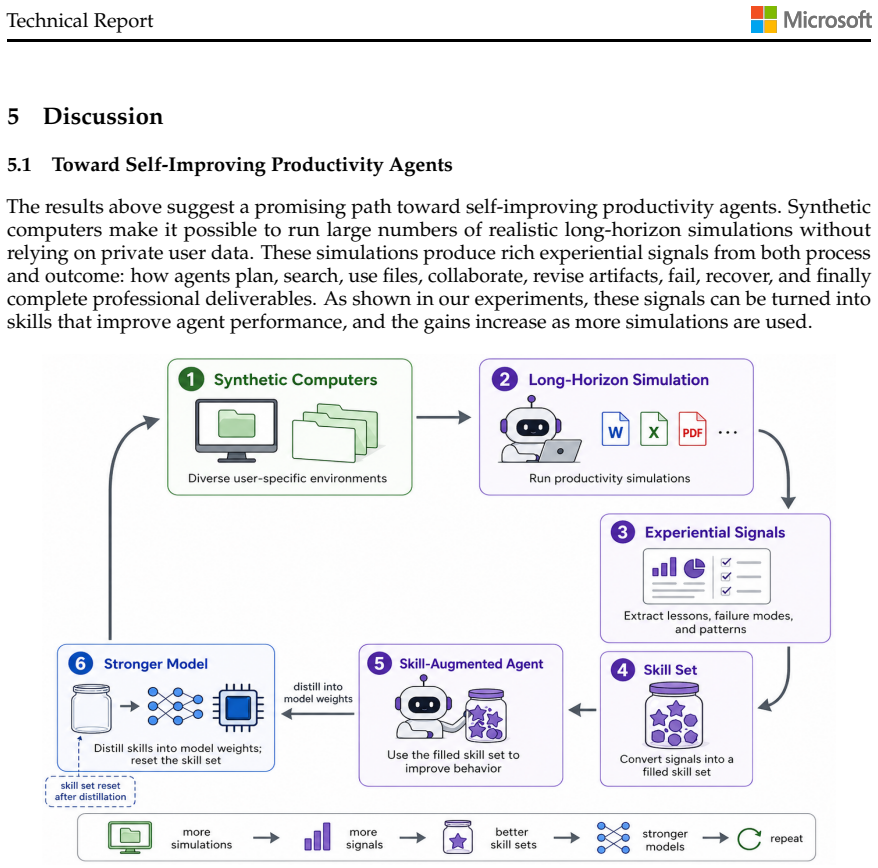
By constructing 1,000 synthetic computers with realistic folder hierarchies and content-rich artifacts, and conducting long-horizon simulations where one agent creates user-specific objectives requiring multiple professional deliverables over roughly a month of work while another agent fulfills them by navigating the system, coordinating with simulated collaborators, and producing outputs, the approach yields experiential learning signals. These signals produce significant improvements in agent performance on both in-domain and out-of-domain productivity evaluations. The method can in principle scale to millions or billions of such environments given sufficient compute.
What carries the argument
Synthetic Computers at Scale: the creation of synthetic user computers with realistic folder hierarchies and artifacts, on which long-horizon agent simulations are run to produce training data for productivity tasks.
If this is right
- Significant improvements appear in agent performance on both in-domain and out-of-domain productivity evaluations.
- The method can scale in principle to millions or billions of synthetic user worlds with enough compute.
- It supplies a substrate for agent self-improvement and agentic reinforcement learning.
- Broader coverage of diverse professions, roles, contexts, and productivity needs becomes possible.
Where Pith is reading between the lines
- This method could reduce the need to collect real user data, lowering privacy risks in agent training.
- The same environment-generation idea might extend to other long-horizon domains such as software development or research.
- If the simulations prove effective, they could serve as a testbed for measuring how well agents sustain work across changing contexts.
Load-bearing premise
The synthetic computer environments and simulations must be realistic enough that the learning signals transfer effectively to real user computers and actual productivity work.
What would settle it
If agents that improve from these synthetic simulations show no performance gains when tested on real user computers performing actual productivity tasks, the transfer of learning signals would be falsified.
Figures







read the original abstract
Realistic long-horizon productivity work is strongly conditioned on user-specific computer environments, where much of the work context is stored and organized through directory structures and content-rich artifacts. To scale synthetic data creation for such productivity scenarios, we introduce Synthetic Computers at Scale, a scalable methodology for creating such environments with realistic folder hierarchies and content-rich artifacts (e.g., documents, spreadsheets, and presentations). Conditioned on each synthetic computer, we run long-horizon simulations: one agent creates productivity objectives that are specific to the computer's user and require multiple professional deliverables and about a month of human work; another agent then acts as that user and keeps working across the computer -- for example, navigating the filesystem for grounding, coordinating with simulated collaborators, and producing professional artifacts -- until these objectives are completed. In preliminary experiments, we create 1,000 synthetic computers and run long-horizon simulations on them; each run requires over 8 hours of agent runtime and spans more than 2,000 turns on average. These simulations produce rich experiential learning signals, whose effectiveness is validated by significant improvements in agent performance on both in-domain and out-of-domain productivity evaluations. Given that personas are abundant at billion scale, this methodology can in principle scale to millions or even billions of synthetic user worlds with sufficient compute, enabling broader coverage of diverse professions, roles, contexts, environments, and productivity needs. We argue that scalable synthetic computer creation, together with at-scale simulations, is highly promising as a foundational substrate for agent self-improvement and agentic reinforcement learning in long-horizon productivity scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Synthetic Computers at Scale, a methodology for generating large numbers of realistic synthetic user computer environments complete with folder hierarchies and content-rich artifacts such as documents and spreadsheets. Conditioned on these environments, it runs long-horizon simulations in which one agent generates user-specific productivity objectives requiring multiple deliverables over roughly a month of work, while a second agent simulates the user completing those objectives through filesystem navigation, collaboration, and artifact production. Preliminary experiments create 1,000 such computers and execute simulations averaging over 2,000 turns each (more than 8 hours of runtime), producing experiential data that yields significant performance gains on both in-domain and out-of-domain productivity evaluations. The authors argue this approach can scale to millions or billions of synthetic worlds and serves as a foundational substrate for agent self-improvement and agentic RL in long-horizon productivity tasks.
Significance. If the generated trajectories prove sufficiently close in distribution to real user-computer interactions, the method could supply scalable, diverse training signals that are currently scarce for long-horizon agent training. The reported improvements on out-of-domain tasks would indicate that synthetic environments can support generalization beyond the training distribution, addressing a key bottleneck in agentic RL. The explicit scaling argument to billion-scale personas is a concrete strength, as is the focus on full computer states rather than isolated tasks.
major comments (3)
- [Experiments / preliminary results] Experiments section (preliminary results paragraph): the abstract states that the 1,000 simulations produce 'significant improvements' on in-domain and out-of-domain evaluations, yet provides no quantitative metrics, baseline agents, statistical tests, or error analysis. Because the central claim rests on these performance gains demonstrating effective learning signals, the absence of these details makes it impossible to assess effect size or reliability.
- [Methodology / Synthetic Computers at Scale] Synthetic computer generation subsection: the description of folder hierarchies and artifact distributions is high-level and does not specify the exact prompting strategies, base models, or any quantitative validation (e.g., distributional similarity to real user data or human realism ratings). This construction is load-bearing for the realism assumption required for transfer to genuine productivity tasks.
- [Evaluation / out-of-domain] Out-of-domain evaluation paragraph: the manuscript must define the out-of-domain test suite explicitly (e.g., held-out professions, different artifact types, or real user traces) and report any measured overlap with the synthetic training distribution. Without this, the generalization claim cannot be evaluated.
minor comments (3)
- [Abstract] Abstract: the phrase 'about a month of human work' is vague; replace with a concrete estimate of total turns or wall-clock time per objective.
- [Introduction / Related Work] Related work: the manuscript should cite prior synthetic data generation efforts for agents (e.g., work on synthetic environments for RL or computer-use agents) to clarify novelty.
- [Figures] Figure captions: any diagrams of folder hierarchies or simulation traces should include scale bars or example counts to convey the realism and diversity achieved.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments below, indicating the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [Experiments / preliminary results] Experiments section (preliminary results paragraph): the abstract states that the 1,000 simulations produce 'significant improvements' on in-domain and out-of-domain evaluations, yet provides no quantitative metrics, baseline agents, statistical tests, or error analysis. Because the central claim rests on these performance gains demonstrating effective learning signals, the absence of these details makes it impossible to assess effect size or reliability.
Authors: We acknowledge that the preliminary nature of the experiments section does not include the detailed quantitative metrics, baselines, statistical tests, or error analysis that would be expected in a full paper. The current manuscript emphasizes the scale and methodology of the synthetic computer simulations, with performance claims stated at a high level. In the revised manuscript, we will expand this section to report specific metrics showing the performance gains, include comparisons against baseline agents without the synthetic data, perform statistical tests where appropriate, and provide error analysis. This will strengthen the evidence for the effectiveness of the learning signals. revision: yes
-
Referee: [Methodology / Synthetic Computers at Scale] Synthetic computer generation subsection: the description of folder hierarchies and artifact distributions is high-level and does not specify the exact prompting strategies, base models, or any quantitative validation (e.g., distributional similarity to real user data or human realism ratings). This construction is load-bearing for the realism assumption required for transfer to genuine productivity tasks.
Authors: The referee correctly identifies that the synthetic computer generation is described at a high level in the current version. We will revise the methodology subsection to include more specific details on the prompting strategies used to generate folder hierarchies and content-rich artifacts, as well as the base models employed for this generation process. Regarding quantitative validation, we will add any distributional similarity measures we have computed and discuss the limitations of the current validation approach. We note that human realism ratings were not conducted in this preliminary work but plan to include them in future extensions. revision: partial
-
Referee: [Evaluation / out-of-domain] Out-of-domain evaluation paragraph: the manuscript must define the out-of-domain test suite explicitly (e.g., held-out professions, different artifact types, or real user traces) and report any measured overlap with the synthetic training distribution. Without this, the generalization claim cannot be evaluated.
Authors: We agree that the out-of-domain evaluation requires clearer definition. In the revision, we will explicitly describe the out-of-domain test suite, specifying that it consists of held-out professions and different artifact types not used in training. We will also report any analysis of overlap with the synthetic training distribution using embedding-based similarity metrics. This will help substantiate the generalization claims. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents a methodology for constructing synthetic computer environments with folder hierarchies and artifacts, then running long-horizon agent simulations (objective generation followed by user-agent execution) to produce experiential trajectories. These trajectories are used to improve agent policies, with effectiveness shown via reported performance gains on separate in-domain and out-of-domain productivity evaluations. No load-bearing step reduces by definition or construction to its own inputs: the synthetic creation process, simulation mechanics, and validation metrics are described as independent procedures whose outputs are empirically tested rather than presupposed. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. The chain from environment generation to simulation data to measured improvements is self-contained and externally checkable through the stated experimental setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic computer environments with generated folder hierarchies and artifacts are sufficiently realistic to produce transferable learning signals for AI agents in productivity scenarios.
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-04-29. 22 Technical Report Ahmed Awadallah, Yash Lara, Raghav Magazine, Hussein Mozannar, Akshay Nambi, Yash Pandya, Aravind Rajeswaran, Corby Rosset, Alexey Taymanov, Vibhav Vineet, et al. Fara-7b: An efficient agentic model for computer use.arXiv preprint arXiv:2511.19663, 2025. Shihao Cai, Runnan Fang, Jialong Wu, Baixuan Li, Xinyu Wang,...
-
[2]
Executive Summary 24 Technical Report Margaret Forsythe is a Senior Financial Advisor at Meridian Wealth Partners (Denver office, $640M AUM) responsible for managing 80+ client households ($340M AUM). Over a 20-day simulation, she was tasked with five concurrent deliverables: (1) a VCMM 2026 model portfolio refresh for Investment Committee presentation, (...
2026
-
[3]
slide 1 = recommendation not background
Deliverable-by-Deliverable Analysis 2.1 DLV 001: VCMM 2026 Model Portfolio Refresh (Hartley) — 127/168 (75.6%) Key Strengths: • All 8 output files created and properly located on D: drive • VCMM 2026 data currency excellent: 2025-12-31 data-as-of cited throughout • Complete 12-asset-class delta table with signed changes • Monte Carlo: 10,000 paths, 10-yea...
2026
-
[4]
Do not submit the stress test workbook to IC with the current values
Simulated-Collaborator Communication Analysis 3.1 David Hartley (ext hartley) — Managing Director Interactions:10 outbound messages, 10 responses. 2 blank messages (Days 14, 15). Effectiveness:Strong in Weeks 1–2. The agent proactively secured VCMM data, confirmed IC agenda, obtained direction on 3 open decision points (REIT rotation, FI parallel scenario...
2022
-
[5]
Workflow & Efficiency 4.1 Error Patterns from Turn Log Thedaily sim turns.jsonlcontains213 error entriesacross 5,114 total turns (4.2% error rate). Key patterns: • dotnet-script path errors:multiple instances of cd .claude/skills/minimax-docx: No such file or directory — suggesting the agent repeatedly tried to use document-creation skills with incorrect ...
-
[6]
Alternatives vehicle selection should have been finalized before analysis began.The agent started quantitative analysis before definitively choosing between GSCI/PDBC for commodities and QSPIX/VMNVX for liquid alts, leading to the analysis being performed on different funds than those recommended
-
[7]
Supporting workbooks should have been updated before narrative documents.The agent wrote updated figures in narrative documents (v2.docx, CMO, FINAL PDF) but left the supporting Excel workbooks with old numbers, breaking the evidence chain
-
[8]
Cross-document reconciliation should have been a dedicated final-day activity.The agent spent Day 20 on miscellaneous tasks rather than systematic reconciliation. A single day dedicated to printing all weight tables side-by-side and verifying consistency would have caught the Conservative US LC (14%/20%/27.4%/19%) discrepancy and the Growth EM direction reversal
-
[9]
Domain-Specific Insights 5.1 Missing Professional Knowledge
-
[10]
check every number in every document
Cross-document reconciliation discipline:In wealth management, a single inconsistent number in a client-facing document can destroy trust. The agent did not demonstrate the “check every number in every document” discipline that a senior financial advisor would apply before an IC presentation or client delivery
-
[11]
Substituting different items than those confirmed by the committee chair is a serious governance failure
IC vote item fidelity:In an investment committee context, the voting resolution list is a quasi-legal document. Substituting different items than those confirmed by the committee chair is a serious governance failure. An expert would have treated Hartley’s enumerated list as immutable
-
[12]
The agent delivered the Castellano package with compliance still pending — exactly what the client said he didn’t want
Compliance as gating function:Whitfield explicitly stated that compliance sign-off must precede client delivery. The agent delivered the Castellano package with compliance still pending — exactly what the client said he didn’t want
-
[13]
Fund product knowledge:The GSCI/PDBC confusion reveals incomplete knowledge of the commodity ETF universe. A senior advisor would know that iShares GSCI Commodity Indexed Trust (ticker: GSG) and Invesco Optimum Yield Diversified Commodity Strategy (ticker: PDBC) are completely different products with different expense ratios and index methodologies. 5.2 W...
-
[14]
single source of truth
Created a “single source of truth” spreadsheetmapping every key figure (weights, returns, correlations, expense ratios, vehicle tickers) with cross-references to every document that cites it. Any change in the source would propagate to all documents
-
[15]
Treated simulated-collaborator corrections as blocking items.Sandra’s Day 17 corrections and Whitfield’s verbatim language insertions should have been completed within hours of receipt, not deferred to future days
-
[16]
red team
Scheduled a final “red team” review day(Day 19 or 20) devoted entirely to printing all deliverable tables side-by-side and checking every number. This is standard practice before IC presentations
-
[17]
open items
Maintained a running “open items” trackerwith simulated collaborator, date, item, status, and deadline. This would have prevented the Sandra Day 17 items and Whitfield verbatim insertions from falling through the cracks
-
[18]
[Whitfield verbatim, Jan 20]
Actionable Recommendations Recommendation 1: Implement Cross-Document Reconciliation Tables What happened:Conservative US Large Cap weight appeared as 14%, 20%, 27.4%, and 19% across four documents in dlv 001. Growth EM appeared with opposite directional signs in different documents. What should have happened:Before packaging, create a reconciliation matr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.