AFFormer: Adaptive Feature Fusion Transformer for V2X Cooperative Perception under Channel Impairments
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
AFFormer fuses multi-vehicle features with attention and distillation to keep 3D detection accurate despite channel noise and fading.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
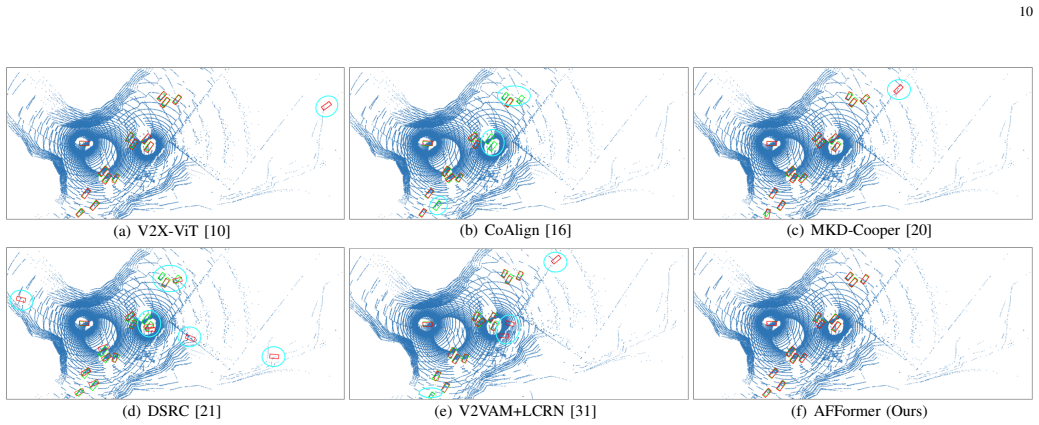
AFFormer is a Transformer-based framework that mitigates the adverse effects of corrupted features in V2X cooperative perception by modeling temporal, inter-agent, and spatial correlations. It deploys three modules—Multi-Agent and Temporal Aggregation for context-aware fusion across agents and time, Dual Spatial Attention for efficient spatial dependencies, and Uncertainty-Guided Fusion for entropy-driven refinement—plus a teacher-student knowledge distillation step that aligns the output with reliable early-collaboration supervision. The resulting model outperforms prior methods on the V2XSet and DAIR-V2X datasets under both ideal and impaired communication conditions.
What carries the argument
Adaptive Feature Fusion Transformer that combines Multi-Agent and Temporal Aggregation, Dual Spatial Attention, and Uncertainty-Guided Fusion with teacher-student distillation to counteract feature corruption.
If this is right
- The method delivers higher detection accuracy than existing approaches on both V2XSet and DAIR-V2X when communication is impaired.
- Robustness gains come without sacrificing a competitive accuracy-efficiency trade-off.
- The same architecture can be applied to other cooperative perception tasks that rely on shared intermediate features.
- Knowledge distillation from an early-collaboration teacher provides a practical way to train robust models when perfect channel conditions are unavailable at inference.
Where Pith is reading between the lines
- If the gains hold under real-world channel measurements, the approach could be integrated into existing V2X stacks to reduce the safety buffer needed for unreliable links.
- The temporal and multi-agent aggregation pattern might transfer to other multi-sensor fusion settings where data arrive asynchronously and with variable quality.
- One could test whether replacing the simulated impairments with traces from actual roadside units changes the ranking of the proposed modules.
Load-bearing premise
That the attention and fusion modules plus distillation can effectively counteract the specific forms of feature degradation caused by channel noise, fading, and interference.
What would settle it
A controlled experiment in which the performance advantage of AFFormer over baselines shrinks to zero or reverses when the test channel impairments are generated from a model that differs substantially from the one used during training or when real measured channel traces replace the simulated impairments.
Figures








read the original abstract
Accurate 3D object detection is essential for ensuring the safety of autonomous vehicles. Cooperative perception, which leverages vehicle-to-everything (V2X) communication to share perceptual data, enhances detection but is vulnerable to channel impairments, such as noise, fading, and interference. To strengthen the reliability of intelligent transportation systems, this work improves the robustness of V2X cooperative perception under communication conditions that reflect common channel impairments. This paper proposes an Adaptive Feature Fusion Transformer (AFFormer), a Transformer-based framework that mitigates the adverse effects of corrupted features by modeling temporal, inter-agent, and spatial correlations. AFFormer introduces three key modules: Multi-Agent and Temporal Aggregation for context-aware fusion across agents and over time, Dual Spatial Attention for efficient modeling of spatial dependencies, and Uncertainty-Guided Fusion for entropy-driven refinement of fused features. A teacher-student knowledge distillation strategy further enhances robustness by aligning fused features with reliable early-collaboration supervision. AFFormer is validated on the V2XSet and DAIR-V2X datasets, where it consistently outperforms existing methods under both ideal and impaired communication conditions, demonstrating improved robustness to communication-induced feature degradation while maintaining a competitive efficiency-accuracy trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AFFormer, a Transformer-based framework for V2X cooperative 3D object detection designed to improve robustness against channel impairments such as noise, fading, and interference. It introduces three modules—Multi-Agent and Temporal Aggregation for context-aware fusion across agents and time, Dual Spatial Attention for spatial dependencies, and Uncertainty-Guided Fusion for entropy-driven refinement—combined with teacher-student knowledge distillation to align features with reliable supervision. The model is claimed to outperform existing methods on the public V2XSet and DAIR-V2X benchmarks under both ideal and impaired communication conditions while preserving a competitive efficiency-accuracy trade-off.
Significance. If the empirical claims hold with proper validation, the work would be significant for autonomous driving and intelligent transportation systems by addressing a practical vulnerability in V2X feature sharing that directly impacts safety. The use of independent public benchmarks rather than synthetic data is a strength, and the focus on modeling temporal, inter-agent, and spatial correlations with uncertainty guidance offers a targeted approach to corrupted features. The efficiency-accuracy balance could support real-world deployment if substantiated.
major comments (2)
- The central robustness claim relies on the three proposed modules and distillation strategy mitigating channel impairments, but the manuscript provides no visible quantitative results, ablation studies, error bars, or detailed impairment simulation protocols (e.g., specific noise/fading models and their parameters) to support outperformance on V2XSet and DAIR-V2X. This is load-bearing for the main contribution as the abstract asserts consistent superiority without evidence that can be assessed.
- The method section lacks concrete equations or mechanisms showing how Multi-Agent and Temporal Aggregation, Dual Spatial Attention, and Uncertainty-Guided Fusion explicitly model or compensate for communication-induced feature degradation (noise, fading, interference); without these, the assumption that the modules provide targeted robustness cannot be verified or falsified.
minor comments (2)
- The abstract would be strengthened by including at least one key quantitative metric (e.g., mAP improvement under impairment) to convey the magnitude of the claimed gains.
- Notation for the modules (e.g., definitions of entropy in Uncertainty-Guided Fusion) should be introduced with explicit equations early in the method description for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below. We will revise the manuscript accordingly to strengthen the empirical validation and methodological clarity.
read point-by-point responses
-
Referee: The central robustness claim relies on the three proposed modules and distillation strategy mitigating channel impairments, but the manuscript provides no visible quantitative results, ablation studies, error bars, or detailed impairment simulation protocols (e.g., specific noise/fading models and their parameters) to support outperformance on V2XSet and DAIR-V2X. This is load-bearing for the main contribution as the abstract asserts consistent superiority without evidence that can be assessed.
Authors: We appreciate the referee's emphasis on rigorous empirical support for the robustness claims. The manuscript does report quantitative comparisons on the V2XSet and DAIR-V2X datasets under both ideal and impaired conditions, demonstrating consistent outperformance. However, we agree that additional details would enhance verifiability. In the revised version, we will expand the experimental section to include: explicit channel impairment simulation protocols with specific parameters (e.g., AWGN noise at defined SNR levels, Rayleigh fading coefficients, and interference models); comprehensive ablation studies quantifying the contribution of each module and the distillation strategy; and error bars or standard deviations computed over multiple random seeds/runs to indicate statistical reliability. These additions will directly address the load-bearing nature of the claims. revision: yes
-
Referee: The method section lacks concrete equations or mechanisms showing how Multi-Agent and Temporal Aggregation, Dual Spatial Attention, and Uncertainty-Guided Fusion explicitly model or compensate for communication-induced feature degradation (noise, fading, interference); without these, the assumption that the modules provide targeted robustness cannot be verified or falsified.
Authors: We acknowledge that the current description of the modules could be made more explicit in linking their operations to impairment compensation. While the manuscript outlines the high-level design of Multi-Agent and Temporal Aggregation for context-aware fusion, Dual Spatial Attention for spatial dependencies, and Uncertainty-Guided Fusion for entropy-based refinement, we will revise the method section to include detailed mathematical formulations. These will specify, for example, how attention weights in the aggregation modules are modulated by feature reliability estimates to downweight degraded inputs, how spatial attention reconstructs corrupted regions via learned correlations, and how uncertainty (entropy) guidance explicitly filters interference-affected features. This will enable direct verification of the targeted robustness mechanisms. revision: yes
Circularity Check
No significant circularity; architecture and evaluation are self-contained
full rationale
The paper introduces a new AFFormer architecture with three explicitly described modules (Multi-Agent and Temporal Aggregation, Dual Spatial Attention, Uncertainty-Guided Fusion) plus teacher-student distillation. These are presented as novel components rather than reductions of prior fitted parameters or self-citations. Validation occurs on independent public benchmarks (V2XSet, DAIR-V2X) under both ideal and impaired conditions, with no evidence that any claimed performance gain is forced by construction from the model's own equations or from load-bearing self-citations. Minor self-citation of related perception work is present but not central to the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- Model hyperparameters (learning rate, attention heads, layer sizes, etc.)
axioms (2)
- domain assumption Channel impairments primarily degrade features in a manner that can be mitigated by modeling temporal, inter-agent, and spatial correlations.
- domain assumption Transformer-based attention mechanisms are suitable for fusing corrupted multi-agent perceptual data.
invented entities (3)
-
Multi-Agent and Temporal Aggregation module
no independent evidence
-
Dual Spatial Attention module
no independent evidence
-
Uncertainty-Guided Fusion module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Z. Bai, G. Wu, M. J. Barth, Y . Liu, E. Akin Sisbot, K. Oguchi, and Z. Huang, “A survey and framework of cooperative perception: From heterogeneous singleton to hierarchical cooperation,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 11, pp. 15191–15209, Nov. 2024
work page 2024
-
[2]
Multi-Sensor Fusion Technology for 3D Object Detection in Autonomous Driving: A Review,
X. Wang, K. Li and A. Chehri, “Multi-Sensor Fusion Technology for 3D Object Detection in Autonomous Driving: A Review,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 2, pp. 1148–1165, Feb. 2024
work page 2024
-
[3]
Vehicle-to-everything cooperative perception for autonomous driving,
T. Huang, J. Liu, X. Zhou, D. C. Nguyen, M. R. Azghadi, Y . Xia, Q.- L. Han, and S. Sun, “Vehicle-to-everything cooperative perception for autonomous driving,”Proc. IEEE, vol. 113, no. 5, pp. 443–477, May 2025
work page 2025
-
[4]
MASS: Mobility-aware sensor scheduling of cooperative perception for connected automated driving,
Y . Jia, R. Mao, Y . Sun, S. Zhou, and Z. Niu, “MASS: Mobility-aware sensor scheduling of cooperative perception for connected automated driving,”IEEE Trans. Veh. Technol., vol. 72, no. 11, pp. 14962–14977, Nov. 2023
work page 2023
-
[5]
H.-k. Chiu, C.-Y . Wang, M.-H. Chen, and S. F. Smith, “Probabilistic 3D multi-object cooperative tracking for autonomous driving via dif- ferentiable multi-sensor Kalman filter,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), Yokohama, Japan, May 2024, pp. 18458–18464
work page 2024
-
[6]
S2R-ViT for multi-agent cooperative perception: Bridging the gap from simulation to reality,
J. Li, R. Xu, X. Liu, B. Li, Q. Zou, J. Ma, and H. Yu, “S2R-ViT for multi-agent cooperative perception: Bridging the gap from simulation to reality,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), Yokohama, May Japan, 2024, pp. 16374–16380
work page 2024
-
[7]
Cooperative spectrum sensing in cognitive radio networks: A survey,
I. F. Akyildiz, B. F. Lo, and R. Balakrishnan, “Cooperative spectrum sensing in cognitive radio networks: A survey,”Phys. Commun., vol. 4, no. 1, pp. 40–62, Mar. 2011. 14
work page 2011
-
[8]
ETSI. (2019, May) Intelligent transport systems (ITS); Access Layer; Part 1: Channel Models for the 5,9 GHz frequency band. ETSI TR 103 257-1 V1.1.1. [Online]. Available: https://www.etsi.org/deliver/etsi tr/103200 103299/10325701/01.01.01 60/tr 10325701v010101p.pdf
work page 2019
-
[9]
Bazzi A, Bartoletti S, Zanella A, et al. “Performance analysis of IEEE 802.11 p preamble insertion in C-V2X sidelink signals for co-channel coexistence,”Vehicular Communications, vol. 45, pp. 100710, 2024
work page 2024
-
[10]
V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer,
R. Xu, H. Xiang, Z. Tu, X. Xia, M.-H. Yang, and J. Ma, “V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer,” inProc. Eur. Conf. Comput. Vis. (ECCV), Tel Aviv, Israel, Oct. 2022, pp. 107–124
work page 2022
-
[11]
DAIR-V2X: A large-scale dataset for vehicle- infrastructure cooperative 3D object detection,
H. Yu, Y . Luo, M. Shu, Y . Huo, Z. Yang, Y . Shi, Z. Guo, H. Li, X. Hu, J. Yuan, and Z. Nie, “DAIR-V2X: A large-scale dataset for vehicle- infrastructure cooperative 3D object detection,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, Jun. 2022, pp. 21329–21338
work page 2022
-
[12]
Q. Chen, X. Ma, S. Tang, J. Guo, Q. Yang, and S. Fu, “F-Cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds,” inProc. 4th ACM/IEEE Symp. Edge Comput., Arlington, Virginia, Nov. 2019, pp. 88–100
work page 2019
-
[13]
Collaboration helps camera overtake LiDAR in 3D detection,
Y . Hu, Y . Lu, R. Xu, W. Xie, S. Chen, and Y . Wang, “Collaboration helps camera overtake LiDAR in 3D detection,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Vancouver, Canada, Jun. 2023, pp. 9243–9252
work page 2023
-
[14]
Systematic Literature Review: Anomaly Detection in Connected and Autonomous Vehicles,
J. R. V . Solaas, E. Mariconti and N. Tuptuk, “Systematic Literature Review: Anomaly Detection in Connected and Autonomous Vehicles,” IEEE Trans. Intell. Transp. Syst., vol. 26, no. 1, pp. 43–58, Jan. 2025
work page 2025
-
[15]
Z. Xiao, P. Li, C. Liu, H. Gao, and X. Wang, “MACNS: A generic graph neural network integrated deep reinforcement learning based multi-agent collaborative navigation system for dynamic trajectory planning,”Inf. Fusion, vol. 105, May 2024, Art. no. 102250
work page 2024
-
[16]
Robust collaborative 3D object detection in presence of pose errors,
Y . Lu, Q. Li, B. Liu, M. Dianati, C. Feng, S. Chen, and Y . Wang, “Robust collaborative 3D object detection in presence of pose errors,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), London, UK, 2023, pp. 4812–4818
work page 2023
-
[17]
Graph attention based feature fusion for collaborative perception,
A. N. Ahmed, S. Mercelis, and A. Anwar, “Graph attention based feature fusion for collaborative perception,” inProc. IEEE Intell. Veh. Symp. (IV), Jeju Island, Korea, Jun. 2024, pp. 2317–2324
work page 2024
-
[18]
V2VFormer: Vehicle-to-vehicle cooperative perception with spatial-channel trans- former,
C. Lin, D. Tian, X. Duan, J. Zhou, D. Zhao, and D. Cao, “V2VFormer: Vehicle-to-vehicle cooperative perception with spatial-channel trans- former,”IEEE Trans. Intell. Veh., vol. 9, no. 2, pp. 3384–3395, Feb. 2024
work page 2024
-
[19]
V2VFormer++: Multi-modal vehicle-to-vehicle cooperative perception via global-local transformer,
H. Yin, D. Tian, C. Lin, X. Duan, J. Zhou, D. Zhao, and D. Cao, “V2VFormer++: Multi-modal vehicle-to-vehicle cooperative perception via global-local transformer,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 2, pp. 2153–2166, Feb. 2024
work page 2024
-
[20]
Z. Li, H. Liang, H. Wang, M. Zhao, J. Wang, and X. Zheng, “MKD- Cooper: Cooperative 3D object detection for autonomous driving via multi-teacher knowledge distillation,”IEEE Trans. Intell. Veh., vol. 9, no. 1, pp. 1490–1500, Jan. 2024
work page 2024
-
[21]
J. Zhang, Y . Wang, L. Qian, P. Sun, Z. Li, S. Jiang, M. Liu, and L. Song, “DSRC: Learning density-insensitive and semantic-aware collaborative representation against corruptions,” inProc. AAAI Conf. Artif. Intell., vol. 39, Philadelphia, PA, USA, 2025, pp. 9942–9950
work page 2025
-
[22]
Where2comm: Communication-efficient collaborative perception via spatial confidence maps,
Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confidence maps,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 35, New Orleans, LA, USA, Nov. 2022, pp. 4874–4886
work page 2022
-
[23]
Learning distilled collaboration graph for multi-agent perception,
Y . Li, S. Ren, P. Wu, S. Chen, C. Feng, and W. Zhang, “Learning distilled collaboration graph for multi-agent perception,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), Dec. 2021, pp. 29541–29552
work page 2021
-
[24]
COOPERNAUT: End-to- end driving with cooperative perception for networked vehicles,
J. Cui, H. Qiu, D. Chen, P. Stone, and Y . Zhu, “COOPERNAUT: End-to- end driving with cooperative perception for networked vehicles,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Louisiana, USA, Jun. 2022, pp. 17252–17262
work page 2022
-
[25]
What2comm: Towards communication-efficient collaborative percep- tion via feature decoupling,
K. Yang, D. Yang, J. Zhang, H. Wang, P. Sun, and L. Song, “What2comm: Towards communication-efficient collaborative percep- tion via feature decoupling,” inProc. ACM Int. Conf. Multimedia, Ottawa, ON, Canada, 2023, pp. 7686–7695
work page 2023
-
[26]
SmartCooper: Vehicular collaborative perception with adaptive fusion and judger mechanism,
Y . Zhang, H. An, Z. Fang, G. Xu, Y . Zhou, X. Chen, and Y . Fang, “SmartCooper: Vehicular collaborative perception with adaptive fusion and judger mechanism,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), Yokohama, Japan, May 2024, pp. 4450–4456
work page 2024
-
[27]
V2VNet: Vehicle-to-vehicle communication for joint perception and prediction,
T.-H. Wang, S. Manivasagam, M. Liang, B. Yang, W. Zeng, and R. Ur- tasun, “V2VNet: Vehicle-to-vehicle communication for joint perception and prediction,” inProc. Eur. Conf. Comput. Vis. (ECCV), Glasgow, UK, Aug. 2020, pp. 605–621
work page 2020
-
[28]
Latency-aware collaborative perception,
Z. Lei, S. Ren, Y . Hu, W. Zhang, and S. Chen, “Latency-aware collaborative perception,” inProc. Eur. Conf. Comput. Vis. (ECCV), Tel Aviv, Israel, Oct. 2022, pp. 316–332
work page 2022
-
[29]
Asynchrony-robust collaborative perception via bird’s eye view flow,
S. Wei, Y . Wei, Y . Hu, Y . Lu, Y . Zhong, S. Chen, and Y . Zhang, “Asynchrony-robust collaborative perception via bird’s eye view flow,” inAdv. Neural Inf. Process. Syst. (NeurIPS), vol. 36, Louisiana, USA, Dec. 2023, pp. 28462–28477
work page 2023
-
[30]
V2X-PC: Vehicle-to-everything collaborative perception via point cluster,
S. Liu, Z. Ding, J. Fu, H. Li, S. Chen, S. Zhang, and X. Zhou, “V2X-PC: Vehicle-to-everything collaborative perception via point cluster,” 2024, arXiv:2403.16635
-
[31]
Learning for vehicle-to-vehicle cooperative perception under lossy communication,
J. Li, R. Xu, X. Liu, J. Ma, Z. Chi, J. Ma, and H. Yu, “Learning for vehicle-to-vehicle cooperative perception under lossy communication,” IEEE Trans. Intell. Veh., vol. 8, no. 4, pp. 2650–2660, Apr. 2023
work page 2023
-
[32]
Self- Supervised Adaptive Weighting for Cooperative Perception in V2V Communications,
C. Liu, J. Chen, Y . Chen, R. Payton, M. Riley and S. -H. Yang, “Self- Supervised Adaptive Weighting for Cooperative Perception in V2V Communications,”IEEE Trans. Intell. Veh., vol. 9, no. 2, pp. 3569-3580, Feb. 2024
work page 2024
-
[33]
Interruption-aware cooperative perception for V2X communication-aided autonomous driving,
S. Renet al., “Interruption-aware cooperative perception for V2X communication-aided autonomous driving,”IEEE Trans. Intell. Veh., vol. 9, no. 4, pp. 4698–4714, Apr. 2024
work page 2024
-
[34]
RoCooper: Robust Cooperative Perception Under Vehicle-to-Vehicle Communication Impairments,
T. Tang, C. Zhang, G. Chen and J. E, “RoCooper: Robust Cooperative Perception Under Vehicle-to-Vehicle Communication Impairments,” in Proc. IEEE INFOCOM, London, United Kingdom, May 2025, pp. 1-10
work page 2025
-
[35]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, Jun. 2019, pp. 12697–12705
work page 2019
-
[36]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, Jun. 2022, pp. 5728–5739
work page 2022
-
[37]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” 2015,arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[38]
On information and sufficiency,
S. Kullback and R. A. Leibler, “On information and sufficiency,”Ann. Math. Stat., vol. 22, no. 1, pp. 79–86, Mar. 1951
work page 1951
-
[39]
CARLA: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “CARLA: An open urban driving simulator,” inProc. Conf. Robot Learn. (CoRL), Mountain View, CA, USA, Nov. 2017, pp. 1–16
work page 2017
-
[40]
The OpenCDA open-source ecosystem for cooperative driving automation research,
R. Xu, H. Xiang, X. Han, X. Xia, Z. Meng, C.-J. Chen, and J. Ma, “The OpenCDA open-source ecosystem for cooperative driving automation research,”IEEE Trans. Intell. Veh., vol. 8, no. 4, pp. 2698–2711, Apr. 2023
work page 2023
-
[41]
K. C. Dey, A. Rayamajhi, M. Chowdhury, P. Bhavsar, and J. Martin, “Vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communi- cation in a heterogeneous wireless network—Performance evaluation,” Transp. Res. Part C: Emerg. Technol., vol. 68, pp. 168–184, Jul. 2016
work page 2016
-
[42]
M. Elloumi, G. Kaddoum, M. Zoheb Hassan and B. Selim, “Digital- Twin-Empowered Interference Management for Multihop Internet of Vehicles Networks Over Millimeter Wave Bands,” inIEEE Internet Things J., vol. 12, no. 11, pp. 17807-17827, Jun. 2025. [43]IEEE Standard for Information Technology—Local and Metropolitan Area Networks—Specific Requirements—Part 1...
work page 2025
-
[43]
R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, “OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle-to- vehicle communication,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), Philadelphia, PA, USA, May 2022, pp. 2583–2589
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.