From Spherical to Gaussian: A Comparative Analysis of Point Cloud Cropping Strategies in Large-Scale 3D Environments
Pith reviewed 2026-05-22 09:47 UTC · model grok-4.3
The pith
Gaussian cropping strategies improve semantic segmentation accuracy over spherical crops on large outdoor 3D point clouds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Replacing spherical cropping with Gaussian, exponential, or linear strategies allows subclouds to cover larger physical areas at comparable point counts; when these subclouds are fed to standard 3D segmentation networks, accuracy rises, most markedly on large-scale outdoor environments, and new state-of-the-art results are reached.
What carries the argument
Gaussian cropping geometry that samples points according to a Gaussian distribution to enlarge the covered volume without increasing the total point count.
If this is right
- Gaussian cropping yields higher segmentation accuracy than spherical cropping on outdoor datasets.
- The same gain appears across multiple network architectures without architecture-specific redesign.
- Indoor scenes benefit less, indicating the advantage scales with scene extent.
- New state-of-the-art numbers are obtained on standard large-scale outdoor benchmarks simply by changing the cropping routine.
Where Pith is reading between the lines
- If larger context at fixed point count is the driver, then multi-scale or adaptive cropping schedules could further reduce context loss without extra memory.
- The same geometric principle might transfer to other dense 3D tasks such as instance segmentation or surface reconstruction where boundary context matters.
- Parameter sweeps over the Gaussian spread could reveal an optimal scale per environment type without changing network capacity.
Load-bearing premise
Observed performance differences arise from the shape of the crop region itself rather than from uncontrolled variations in point density, code implementation, or per-dataset hyperparameter tuning.
What would settle it
Re-run the same models on the same data after forcing every cropping method to produce identical point-density statistics and identical code paths; if the accuracy gap vanishes, the claim is falsified.
Figures
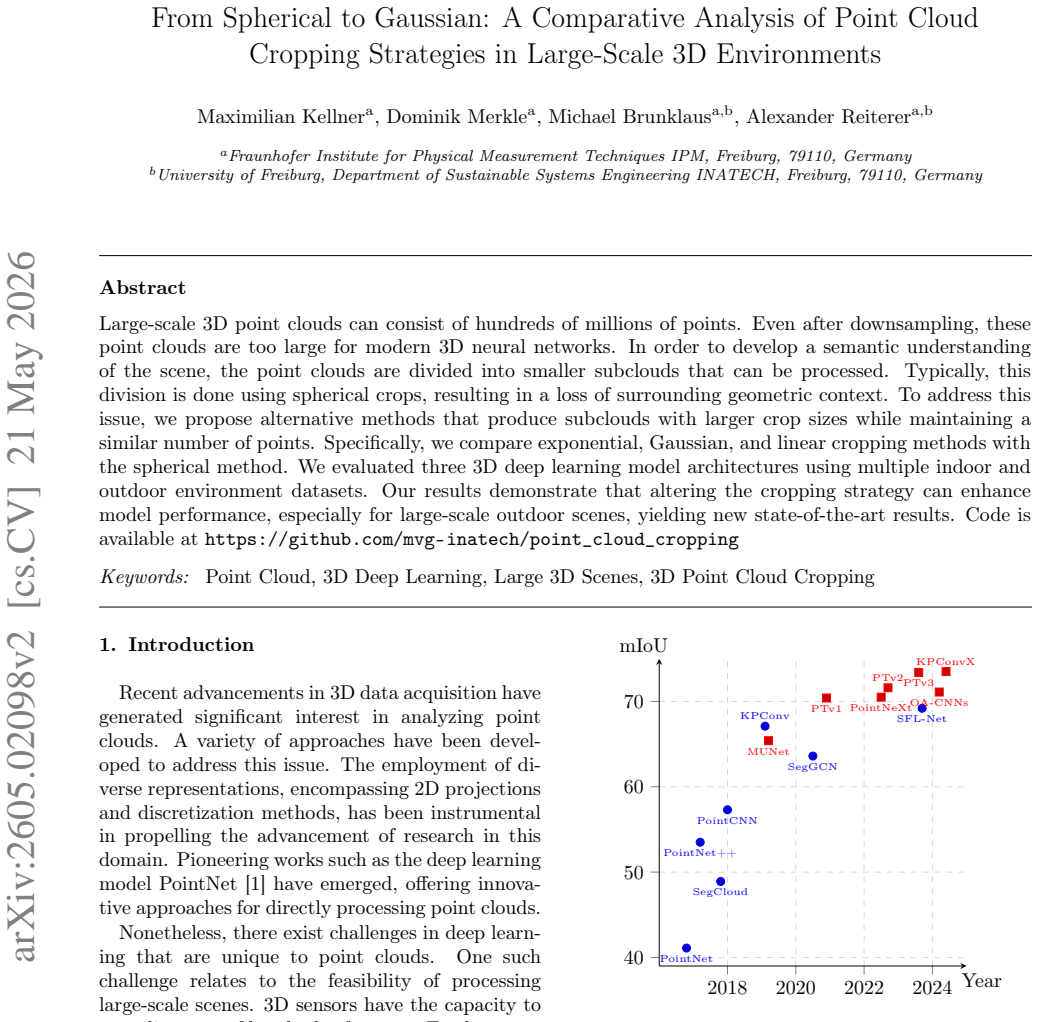







read the original abstract
Large-scale 3D point clouds can consist of hundreds of millions of points. Even after downsampling, these point clouds are too large for modern 3D neural networks. In order to develop a semantic understanding of the scene, the point clouds are divided into smaller subclouds that can be processed. Typically, this division is done using spherical crops, resulting in a loss of surrounding geometric context. To address this issue, we propose alternative methods that produce subclouds with larger crop sizes while maintaining a similar number of points. Specifically, we compare exponential, Gaussian, and linear cropping methods with the spherical method. We evaluated three 3D deep learning model architectures using multiple indoor and outdoor environment datasets. Our results demonstrate that altering the cropping strategy can enhance model performance, especially for large-scale outdoor scenes, yielding new state-of-the-art results. Code is available at https://github.com/mvg-inatech/point_cloud_cropping
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares spherical cropping to exponential, Gaussian, and linear alternatives for dividing large 3D point clouds into subclouds suitable for neural network processing. The alternatives are designed to retain more surrounding context while keeping a comparable number of points. Experiments across three 3D architectures and multiple indoor/outdoor datasets report performance gains, especially for large-scale outdoor scenes, with claims of new state-of-the-art results.
Significance. If performance differences can be isolated to crop geometry rather than sampling density or implementation details, the work offers a lightweight way to improve context preservation in large-scale point cloud tasks such as semantic segmentation. Open-sourced code aids reproducibility and potential follow-up studies.
major comments (2)
- [Abstract and experimental protocol] Abstract and experimental protocol: The claim that alternative cropping methods maintain 'a similar number of points' is not accompanied by a description of the point selection procedure inside each crop region. Without specifying whether uniform sampling, farthest-point sampling, rejection sampling, or another method is applied uniformly across spherical, exponential, Gaussian, and linear crops, differences in local density profiles cannot be ruled out as a confound. This directly affects attribution of gains to crop shape, especially for the outdoor SOTA results where scale amplifies any uncontrolled variation.
- [Results section] Results section: While gains are reported across models and datasets, the manuscript provides no error bars, statistical significance tests, or ablations that hold point count and augmentation pipeline fixed while varying only crop boundary. This leaves open whether the central empirical claim rests on geometry or on secondary factors in the data preparation pipeline.
minor comments (2)
- [Methods] The mathematical definitions of the exponential, Gaussian, and linear cropping functions would benefit from explicit equations in the methods section to allow exact reproduction.
- [Figures] Figure captions describing crop visualizations should note the sampling density used inside each shape to aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript comparing cropping strategies for large-scale point clouds. We address each major comment below and will revise the manuscript to improve clarity and empirical rigor where feasible.
read point-by-point responses
-
Referee: [Abstract and experimental protocol] The claim that alternative cropping methods maintain 'a similar number of points' is not accompanied by a description of the point selection procedure inside each crop region. Without specifying whether uniform sampling, farthest-point sampling, rejection sampling, or another method is applied uniformly across spherical, exponential, Gaussian, and linear crops, differences in local density profiles cannot be ruled out as a confound.
Authors: We agree that explicit details on point selection are necessary to attribute performance differences to crop geometry. In our implementation, cropping strategies define geometric boundaries, and every point falling strictly inside the boundary is retained with no further subsampling (uniform, FPS, or otherwise) applied inside the region. Crop parameters for the exponential, Gaussian, and linear methods are chosen via dataset-wide statistics to yield average point counts comparable to spherical crops. The identical inclusion rule is used for all four strategies. We will add a precise description of this procedure to the experimental protocol section in the revision. revision: yes
-
Referee: [Results section] While gains are reported across models and datasets, the manuscript provides no error bars, statistical significance tests, or ablations that hold point count and augmentation pipeline fixed while varying only crop boundary. This leaves open whether the central empirical claim rests on geometry or on secondary factors in the data preparation pipeline.
Authors: We recognize that error bars, significance testing, and targeted ablations would strengthen isolation of the crop-boundary effect. The reported experiments already kept the augmentation pipeline and target point-count distribution fixed across methods, varying only boundary shape. However, the computational cost of retraining multiple 3D architectures on large outdoor datasets precluded repeated runs. In the revision we will add a dedicated ablation that strictly controls point count and pipeline while varying only the boundary, and we will report variance from a limited set of additional seeds where compute permits; full statistical testing may remain constrained by resources. revision: partial
Circularity Check
No circularity in empirical cropping comparison
full rationale
The paper is an empirical comparative study that evaluates spherical, exponential, Gaussian, and linear cropping strategies on public indoor and outdoor point cloud datasets using three standard 3D network architectures. Performance claims rest on direct experimental measurements of model accuracy after applying each cropping method while attempting to hold point count approximately constant. No derivation chain, fitted parameters renamed as predictions, self-referential equations, or load-bearing self-citations appear in the provided text. The methodology is self-contained against external benchmarks because results are obtained by running the same models on fixed public data splits with the proposed cropping variants, and code is released for independent verification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. R. Qi, H. Su, K. Mo, L. J. Guibas, Point- Net: Deep Learning on Point Sets for 3D Clas- sification and Segmentation, arXiv:1612.00593 [cs] (Feb. 2016).doi:10.48550/arXiv.1612. 00593. URLhttp://arxiv.org/abs/1612.00593
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1612 2016
-
[2]
Joint 2D-3D-Semantic Data for Indoor Scene Understanding
I. Armeni, S. Sax, A. R. Zamir, S. Savarese, Joint 2D-3D-Semantic Data for Indoor Scene Understanding, arXiv:1702.01105 [cs] (Apr. 2017).doi:10.48550/arXiv.1702.01105. URLhttp://arxiv.org/abs/1702.01105
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1702.01105 2017
-
[3]
I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, S. Savarese, 3D Seman- tic Parsing of Large-Scale Indoor Spaces, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Las Vegas, NV, USA, 2016, pp. 1534–1543. doi:10.1109/CVPR.2016.170. URLhttp://ieeexplore.ieee.org/ document/7780539/
- [4]
-
[5]
H. Thomas, Y.-H. H. Tsai, T. D. Bar- foot, J. Zhang, KPConvX: Modernizing Ker- nel Point Convolution with Kernel Attention, arXiv:2405.13194 [cs] (May 2024).doi:10. 48550/arXiv.2405.13194. URLhttp://arxiv.org/abs/2405.13194
-
[6]
Y. Guo, H. Wang, Q. Hu, H. Liu, L. Liu, M. Bennamoun, Deep Learning for 3D Point Clouds: A Survey, IEEE Transac- tions on Pattern Analysis and Machine Intelligence 43 (12) (2021) 4338–4364. doi:10.1109/TPAMI.2020.3005434. URLhttps://ieeexplore.ieee.org/ document/9127813/
-
[7]
R. Zhang, Y. Wu, W. Jin, X. Meng, Deep-Learning-Based Point Cloud Se- mantic Segmentation: A Survey, Elec- tronics 12 (17) (2023) 3642.doi: 10.3390/electronics12173642. URLhttps://www.mdpi.com/2079-9292/ 12/17/3642
-
[8]
ALTRO: A Fast Solver for Constrained Trajectory Optimization,
A. Milioto, I. Vizzo, J. Behley, C. Stach- niss, RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation, in: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Macau, China, 2019, pp. 4213–4220. doi:10.1109/IROS40897.2019.8967762. URLhttps://ieeexplore.ieee.org/ document/8967762/
-
[9]
T. Cortinhal, G. Tzelepis, E. Erdal Aksoy, SalsaNext: Fast, Uncertainty-Aware Seman- tic Segmentation of LiDAR Point Clouds, in: G. Bebis, Z. Yin, E. Kim, J. Bender, K. Subr, B. C. Kwon, J. Zhao, D. Kalkofen, G. Baciu (Eds.), Advances in Visual Com- puting, Vol. 12510, Springer International Publishing, Cham, 2020, pp. 207–222, series Title: Lecture Notes...
-
[10]
B. Wu, A. Wan, X. Yue, K. Keutzer, Squeeze- Seg: Convolutional Neural Nets with Recur- rent CRF for Real-Time Road-Object Seg- mentation from 3D LiDAR Point Cloud, arXiv:1710.07368 [cs] (Oct. 2017).doi:10. 48550/arXiv.1710.07368. URLhttp://arxiv.org/abs/1710.07368
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
B. Wu, X. Zhou, S. Zhao, X. Yue, K. Keutzer, SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road- Object Segmentation from a LiDAR Point Cloud, in: 2019 International Conference on Robotics and Automation (ICRA), IEEE, Montreal, QC, Canada, 2019, pp. 4376–4382. doi:10.1109/ICRA.2019.8793495. URLhttps://ieeexplore.ieee.org/ d...
- [12]
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer 25 Vision and Pattern Recognition, pp
Y. Zhang, Z. Zhou, P. David, X. Yue, Z. Xi, B. Gong, H. Foroosh, PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Seattle, WA, USA, 2020, pp. 9598–9607. doi:10.1109/CVPR42600.2020.00962. URLhttps://ieeexplore.ieee.org/ docume...
-
[14]
G.Shi, R.Li, C.Ma, PillarNet: Real-Timeand High-Performance Pillar-Based 3D Object De- tection, in: S. Avidan, G. Brostow, M. Cissé, G. M. Farinella, T. Hassner (Eds.), Computer Vision – ECCV 2022, Vol. 13670, Springer Nature Switzerland, Cham, 2022, pp. 35–52, series Title: Lecture Notes in Computer Sci- ence.doi:10.1007/978-3-031-20080-9_3. URLhttps://l...
-
[15]
Lee, Matthew Tan, Yuke Zhu, and Jeannette Bohg
M. Gerdzhev, R. Razani, E. Taghavi, L. Bingbing, TORNADO-Net: mulTi- view tOtal vaRiatioN semAntic segmen- tation with Diamond inceptiOn module, in: 2021 IEEE International Conference on Robotics and Automation (ICRA), IEEE, Xi’an, China, 2021, pp. 9543–9549. doi:10.1109/ICRA48506.2021.9562041. URLhttps://ieeexplore.ieee.org/ document/9562041/
-
[16]
K. Chen, R. Oldja, N. Smolyanskiy, S. Birch- field, A. Popov, D. Wehr, I. Eden, J. Pehserl, MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views, arXiv:2006.05518 [cs] (Aug. 2020).doi:10.48550/arXiv.2006.05518. URLhttp://arxiv.org/abs/2006.05518
- [17]
-
[18]
Ö. Çiçek, A. Abdulkadir, S. S. Lienkamp, T. Brox, O. Ronneberger, 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation, in: S. Ourselin, L. Joskowicz, M. R. Sabuncu, G. Unal, W. Wells (Eds.), Medical Image Computing and Computer- Assisted Intervention – MICCAI 2016, Springer International Publishing, Cham, 2016, pp. 424–432
work page 2016
-
[19]
SEGCloud: Semantic Segmentation of 3D Point Clouds
L.P.Tchapmi, C.B.Choy, I.Armeni, J.Gwak, S. Savarese, SEGCloud: Semantic Segmen- tation of 3D Point Clouds, arXiv:1710.07563 [cs] (Oct. 2017).doi:10.48550/arXiv.1710. 07563. URLhttp://arxiv.org/abs/1710.07563
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1710 2017
-
[20]
B. Graham, M. Engelcke, L. V. D. Maaten, 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks, in: 2018 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, IEEE, Salt Lake City, UT, USA, 2018, pp. 9224–9232. doi:10.1109/CVPR.2018.00961. URLhttps://ieeexplore.ieee.org/ document/8579059/
-
[21]
C. Choy, J. Gwak, S. Savarese, 4D Spatio- Temporal ConvNets: Minkowski Convolu- tional Neural Networks, in: 2019 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), IEEE, Long Beach, CA, USA, 2019, pp. 3070–3079. doi:10.1109/CVPR.2019.00319. URLhttps://ieeexplore.ieee.org/ document/8953494/
-
[22]
Contributors, Spconv: Spatially Sparse Convolution Library (2022)
S. Contributors, Spconv: Spatially Sparse Convolution Library (2022). URLhttps://github.com/traveller59/ spconv
work page 2022
-
[23]
X. Ding, X. Zhang, J. Han, G. Ding, Scal- ing Up Your Kernels to 31×31: Revisiting Large Kernel Design in CNNs, in: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, New Orleans, LA, USA, 2022, pp. 11953–11965. doi:10.1109/CVPR52688.2022.01166. URLhttps://ieeexplore.ieee.org/ document/9880273/
-
[24]
Y. Chen, J. Liu, X. Zhang, X. Qi, J. Jia, LargeKernel3D: Scaling up Kernels in 3D 15 Sparse CNNs, in: 2023 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), IEEE, Vancou- ver, BC, Canada, 2023, pp. 13488–13498. doi:10.1109/CVPR52729.2023.01296. URLhttps://ieeexplore.ieee.org/ document/10203060/
-
[25]
T. Feng, W. Wang, F. Ma, Y. Yang, LSK3DNet: Towards Effective and Efficient 3D Perception with Large Sparse Kernels, in: 2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), IEEE, Seattle, WA, USA, 2024, pp. 14916–14927. doi:10.1109/CVPR52733.2024.01413. URLhttps://ieeexplore.ieee.org/ document/10656196/
-
[26]
B. Peng, X. Wu, L. Jiang, Y. Chen, H. Zhao, Z. Tian, J. Jia, OA-CNNs: Omni-Adaptive Sparse CNNs for 3D Semantic Segmentation, in: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Seattle, WA, USA, 2024, pp. 21305– 21315.doi:10.1109/CVPR52733.2024.02013. URLhttps://ieeexplore.ieee.org/ document/10655421/
-
[27]
C. R. Qi, L. Yi, H. Su, L. J. Guibas, Point- Net++: Deep Hierarchical Feature Learn- ing on Point Sets in a Metric Space, arXiv:1706.02413 [cs] (Jun. 2017).doi:10. 48550/arXiv.1706.02413. URLhttp://arxiv.org/abs/1706.02413
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Q. Hu, B. Yang, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, A. Markham, RandLA- Net: Efficient Semantic Segmentation of Large-Scale Point Clouds, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Seattle, WA, USA, 2020, pp. 11105–11114. doi:10.1109/CVPR42600.2020.01112. URLhttps://ieeexplore.ieee.org/ document/9156466/
-
[29]
Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs
L. Landrieu, M. Simonovsky, Large-scale Point CloudSemanticSegmentationwithSuperpoint Graphs, arXiv:1711.09869 [cs] (Mar. 2018). doi:10.48550/arXiv.1711.09869. URLhttp://arxiv.org/abs/1711.09869
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.09869 2018
-
[30]
Y. Wang, Y. Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, J. M. Solomon, Dynamic Graph CNN for Learning on Point Clouds, ACM Transactions on Graphics 38 (5) (2019) 1–12. doi:10.1145/3326362. URLhttps://dl.acm.org/doi/10.1145/ 3326362
-
[31]
H. Lei, N. Akhtar, A. Mian, SegGCN: Efficient 3D Point Cloud Segmentation With Fuzzy Spherical Kernel, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Seattle, WA, USA, 2020, pp. 11608–11617. doi:10.1109/CVPR42600.2020.01163. URLhttps://ieeexplore.ieee.org/ document/9157177/
-
[32]
M. Tatarchenko, J. Park, V. Koltun, Q.-Y. Zhou, Tangent Convolutions for Dense Predic- tion in 3D, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, Salt Lake City, UT, USA, 2018, pp. 3887–3896.doi:10.1109/CVPR.2018.00409. URLhttps://ieeexplore.ieee.org/ document/8578507/
- [33]
-
[34]
Kpconv: Flexible and deformable convolution for point clouds,
H. Thomas, C. R. Qi, J.-E. Deschaud, B. Mar- cotegui, F. Goulette, L. J. Guibas, KPConv: Flexible and Deformable Convolution for Point Clouds, arXiv:1904.08889 [cs] (Aug. 2019). doi:10.48550/arXiv.1904.08889. URLhttp://arxiv.org/abs/1904.08889
-
[35]
X. Li, Z. Zhang, Y. Li, M. Huang, J. Zhang, SFL-NET: Slight Filter Learn- ing Network for Point Cloud Semantic Segmentation, IEEE Transactions on Geo- science and Remote Sensing 61 (2023) 1–14. doi:10.1109/TGRS.2023.3313876. URLhttps://ieeexplore.ieee.org/ document/10250869/
-
[36]
H. Zhao, L. Jiang, J. Jia, P. Torr, V. Koltun, Point Transformer, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Mon- treal, QC, Canada, 2021, pp. 16239–16248. doi:10.1109/ICCV48922.2021.01595. 16 URLhttps://ieeexplore.ieee.org/ document/9710703/
-
[37]
M.-H. Guo, J.-X. Cai, Z.-N. Liu, T.-J. Mu, R. R. Martin, S.-M. Hu, PCT: Point cloud transformer, Computational Visual Media 7 (2) (2021) 187–199. doi:10.1007/s41095-021-0229-5. URLhttps://ieeexplore.ieee.org/ document/10897555/
-
[38]
X. Wu, Y. Lao, L. Jiang, X. Liu, H. Zhao, Point Transformer V2: Grouped Vector Attention and Partition-based Pooling, in: S. Koyejo, S. Mohamed, A. Agarwal, D. Bel- grave, K. Cho, A. Oh (Eds.), Advances in Neural Information Processing Systems, Vol. 35, Curran Associates, Inc., 2022, pp. 33330–33342. URLhttps://proceedings.neurips. cc/paper_files/paper/20...
work page 2022
-
[39]
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y. Qiao, W. Ouyang, T. He, H. Zhao, Point Transformer V3: Simpler, Faster, Stronger, in: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Seattle, WA, USA, 2024, pp. 4840– 4851.doi:10.1109/CVPR52733.2024.00463. URLhttps://ieeexplore.ieee.org/ document/10658198/
-
[40]
Y. Yue, D. Robert, J. Wang, S. Hong, J. D. Wegner, C. Rupprecht, K. Schindler, LitePT: Lighter Yet Stronger Point Trans- former, arXiv:2512.13689 (Mar. 2026).doi: 10.48550/arXiv.2512.13689. URLhttp://arxiv.org/abs/2512.13689
-
[41]
Z. Liu, H. Hu, Y. Lin, Z. Yao, Z. Xie, Y. Wei, J. Ning, Y. Cao, Z. Zhang, L. Dong, F. Wei, B. Guo, Swin Transformer V2: Scal- ing Up Capacity and Resolution, in: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, New Orleans, LA, USA, 2022, pp. 11999–12009. doi:10.1109/CVPR52688.2022.01170. URLhttps://ieeexplore.ieee.org/ do...
-
[42]
Y.-Q. Yang, Y.-X. Guo, J.-Y. Xiong, Y. Liu, H. Pan, P.-S. Wang, X. Tong, B. Guo, Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding, Compu- tational Visual Media 11 (1) (2025) 83–101. doi:10.26599/CVM.2025.9450383. URLhttps://ieeexplore.ieee.org/ document/10901941/
-
[43]
M. Kellner, B. Stahl, A. Reiterer, Fused Projection-Based Point Cloud Segmen- tation, Sensors 22 (3) (2022) 1139. doi:10.3390/s22031139. URLhttps://www.mdpi.com/1424-8220/ 22/3/1139
-
[44]
Y.Hou, X.Zhu, Y.Ma, C.C.Loy, Y.Li, Point- to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation, arXiv:2206.02099 [cs] (Jun. 2022).doi:10.48550/arXiv.2206. 02099. URLhttp://arxiv.org/abs/2206.02099
-
[45]
J. Xu, R. Zhang, J. Dou, Y. Zhu, J. Sun, S. Pu, RPVNet: A Deep and Efficient Range-Point-Voxel Fusion Network for Li- DAR Point Cloud Segmentation, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Mon- treal, QC, Canada, 2021, pp. 16004–16013. doi:10.1109/ICCV48922.2021.01572. URLhttps://ieeexplore.ieee.org/ document/9709941/
-
[46]
Walk in the cloud: Learning curves for point clouds shape analysis, pp
M. Caron, H. Touvron, I. Misra, H. Jegou, J. Mairal, P. Bojanowski, A. Joulin, Emerging Properties in Self-Supervised Vision Trans- formers, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Montreal, QC, Canada, 2021, pp. 9630– 9640.doi:10.1109/ICCV48922.2021.00951. URLhttps://ieeexplore.ieee.org/ document/9709990/
-
[47]
K. He, X. Chen, S. Xie, Y. Li, P. Dollar, R. Girshick, Masked Autoencoders Are Scal- able Vision Learners, in: 2022 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), IEEE, New Orleans, LA, USA, 2022, pp. 15979–15988. doi:10.1109/CVPR52688.2022.01553. URLhttps://ieeexplore.ieee.org/ document/9879206/
-
[48]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, 17 D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y. Huang, S.-W. Li, I. Misra, M. Rabbat, V. Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, P. Bojanowski, DI- NOv2: Learning Robust Visual Features with- out Superv...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.07193 2024
-
[49]
O. Siméoni, H. V. Vo, M. Seitzer, F. Bal- dassarre, M. Oquab, C. Jose, V. Khali- dov, M. Szafraniec, S. Yi, M. Ramamon- jisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sen- tana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. Jé- gou, P. Labatut, P. Bojanowski, DINOv3, arXiv:2508.10104 [cs] (Aug. 202...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
S. Xie, J. Gu, D. Guo, C. R. Qi, L. Guibas, O. Litany, PointContrast: Unsupervised Pre- training for 3D Point Cloud Understand- ing, in: A. Vedaldi, H. Bischof, T. Brox, J.-M. Frahm (Eds.), Computer Vision – ECCV 2020, Springer International Publish- ing, Cham, 2020, pp. 574–591
work page 2020
-
[51]
Y. Pang, W. Wang, F. E. H. Tay, W. Liu, Y. Tian, L. Yuan, Masked Autoencoders for Point Cloud Self-supervised Learning, in: S. Avidan, G. Brostow, M. Cissé, G. M. Farinella, T. Hassner (Eds.), Computer Vision – ECCV 2022, Vol. 13662, Springer Nature Switzerland, Cham, 2022, pp. 604–621, series Title: Lecture Notes in Computer Science. doi:10.1007/978-3-03...
-
[52]
X. Wu, X. Wen, X. Liu, H. Zhao, Masked Scene Contrast: A Scalable Framework for Unsupervised 3D Representation Learning, in: 2023 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), IEEE, Vancouver, BC, Canada, 2023, pp. 9415–9424. doi:10.1109/CVPR52729.2023.00908. URLhttps://ieeexplore.ieee.org/ document/10203752/
- [53]
-
[54]
Y. Zhang, X. Wu, Y. Lao, C. Wang, Z. Tian, N. Wang, H. Zhao, Concerto: Joint 2D- 3D Self-Supervised Learning Emerges Spatial Representations, arXiv:2510.23607 [cs] (Oct. 2025).doi:10.48550/arXiv.2510.23607. URLhttp://arxiv.org/abs/2510.23607
-
[55]
H. Zhu, H. Yang, X. Wu, D. Huang, S. Zhang, X. He, H. Zhao, C. Shen, Y. Qiao, T. He, W. Ouyang, PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre- trainingParadigm, arXiv:2310.08586[cs](Apr. 2025).doi:10.48550/arXiv.2310.08586. URLhttp://arxiv.org/abs/2310.08586
- [56]
-
[57]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, S. Zhao, S. Cheng, Y. Zhang, J. Shlens, Z. Chen, D. Anguelov, Scalability in Percep- tion for Autonomous Driving: Waymo Open Dataset, arXiv:1912.04838 [...
-
[58]
nuScenes: A multimodal dataset for autonomous driving
H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, O. Beijbom, nuScenes: A mul- timodal dataset for autonomous driving, arXiv:1903.11027 [cs] (May 2020).doi:10. 48550/arXiv.1903.11027. URLhttp://arxiv.org/abs/1903.11027
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[59]
X. Roynard, J.-E. Deschaud, F. Goulette, Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification, 18 The International Journal of Robotics Re- search 37 (6) (2018) 545–557.doi:10.1177/ 0278364918767506. URLhttps://journals.sagepub.com/doi/ 10.1177/0278364918767506
-
[60]
W. Tan, N. Qin, L. Ma, Y. Li, J. Du, G. Cai, K. Yang, J. Li, Toronto-3D: A Large-scale Mo- bile LiDAR Dataset for Semantic Segmenta- tion of Urban Roadways, in: 2020 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition Workshops (CVPRW), IEEE, Seattle, WA, USA, 2020, pp. 797–806. doi:10.1109/CVPRW50498.2020.00109. URLhttps://ieeexplore.ieee.or...
-
[62]
H. Thomas, F. Goulette, J.-E. Deschaud, B. Marcotegui, Y. LeGall, Semantic Clas- sification of 3D Point Clouds with Multi- scale Spherical Neighborhoods, in: 2018 International Conference on 3D Vision (3DV), IEEE, Verona, 2018, pp. 390–398. doi:10.1109/3DV.2018.00052. URLhttps://ieeexplore.ieee.org/ document/8490990/
-
[63]
N. Varney, V. K. Asari, Q. Graehling, Pyra- mid Point: A Multi-Level Focusing Network for Revisiting Feature Layers (2020).doi: 10.48550/ARXIV.2011.08692. URLhttps://arxiv.org/abs/2011.08692
-
[64]
S. Yoo, Y. Jeong, M. Jameela, G. Sohn, Human Vision Based 3D Point Cloud Se- mantic Segmentation of Large-Scale Outdoor Scenes, in: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Vancou- ver, BC, Canada, 2023, pp. 6577–6586. doi:10.1109/CVPRW59228.2023.00699. URLhttps://ieeexplore.ieee.org/ document/10208664/
-
[65]
S. Yoo, Y. Jeong, M. M. Sheikholeslami, G. Sohn, EyeNet++: A Multiscale and Multidensity Approach for Outdoor 3-D Semantic Segmentation Inspired by the Hu- man Visual Field, IEEE Transactions on Geoscience and Remote Sensing 63 (2025) 1–19.doi:10.1109/TGRS.2025.3589287. URLhttps://ieeexplore.ieee.org/ document/11080501/
-
[66]
S. Contributors, Spconv: Spatially sparse convolution library,https://github.com/ traveller59/spconv(2022)
work page 2022
-
[67]
M. Fey, J. E. Lenssen, Fast Graph Repre- sentation Learning with PyTorch Geometric, arXiv:1903.02428 [cs] (Apr. 2019).doi:10. 48550/arXiv.1903.02428. URLhttp://arxiv.org/abs/1903.02428
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[68]
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, C. Ré, FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, version Number: 2 (2022).doi:10.48550/ARXIV. 2205.14135. URLhttps://arxiv.org/abs/2205.14135
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2022
-
[69]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
T. Dao, FlashAttention-2: Faster Attention with Better Parallelism and Work Partition- ing, version Number: 1 (2023).doi:10. 48550/ARXIV.2307.08691. URLhttps://arxiv.org/abs/2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
S. Ioffe, C. Szegedy, Batch Normalization: Accelerating Deep Network Training by Re- ducing Internal Covariate Shift, in: F. Bach, D. Blei (Eds.), Proceedings of the 32nd In- ternational Conference on Machine Learning, Vol. 37 of Proceedings of Machine Learning Research, PMLR, Lille, France, 2015, pp. 448–456. URLhttps://proceedings.mlr.press/ v37/ioffe15.html
work page 2015
-
[71]
J. L. Ba, J. R. Kiros, G. E. Hinton, Layer Nor- malization, version Number: 1 (2016).doi: 10.48550/ARXIV.1607.06450. URLhttps://arxiv.org/abs/1607.06450
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.06450 2016
-
[72]
C. R. Harris, K. J. Millman, S. J. Van Der Walt, R. Gommers, P. Virtanen, D. Cour- napeau, E. Wieser, J. Taylor, S. Berg, N. J. Smith, R. Kern, M. Picus, S. Hoyer, M. H. Van Kerkwijk, M. Brett, A. Hal- dane, J. F. Del Río, M. Wiebe, P. Peterson, P. Gérard-Marchant, K. Sheppard, T. Reddy, 19 W. Weckesser, H. Abbasi, C. Gohlke, T. E. Oliphant, Array program...
-
[73]
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, PyTorch: An Imperative Style, High-Performance Deep Learning Library, in: H. Wallach, H. Larochelle, A. Beygelzimer, F. d....
work page 2019
-
[74]
S. K. Lam, A. Pitrou, S. Seibert, Numba: a LLVM-based Python JIT compiler, in: Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, ACM, Austin Texas, 2015, pp. 1– 6.doi:10.1145/2833157.2833162. URLhttps://dl.acm.org/doi/10.1145/ 2833157.2833162
-
[75]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutter, Decoupled Weight Decay Regularization, version Number: 3 (2017).doi:10.48550/ARXIV.1711.05101. URLhttps://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2017
-
[76]
L. N. Smith, N. Topin, Super-Convergence: Very Fast Training of Neural Networks Us- ing Large Learning Rates, version Number: 3 (2017).doi:10.48550/ARXIV.1708.07120. URLhttps://arxiv.org/abs/1708.07120
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1708.07120 2017
-
[77]
Rethinking the Inception Architecture for Computer Vision
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the Inception Architec- ture for Computer Vision, version Number: 3 (2015).doi:10.48550/ARXIV.1512.00567. URLhttps://arxiv.org/abs/1512.00567
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1512.00567 2015
-
[78]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020).doi:10.48550/ ARXIV.2010.11929. URLhttps://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[79]
X. Jiao, C. Lv, J. Zhao, R. Yi, Y.-H. Wen, Z. Pan, Z. Wu, Y.-J. Liu, Weighted Poisson- disk Resampling on Large-Scale Point Clouds, Proceedings of the AAAI Conference on Artificial Intelligence 39 (4) (2025) 4084–4092. doi:10.1609/aaai.v39i4.32428. URLhttps://ojs.aaai.org/index.php/ AAAI/article/view/32428
-
[80]
M. Kellner, A. Schmitt, A. Reiterer, Automatic Generation of 3D Bridge Models from 3D Point Clouds, Re- sults in Engineering (2026) 109532doi: 10.1016/j.rineng.2026.109532. URLhttps://linkinghub.elsevier.com/ retrieve/pii/S2590123026005724 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.