Assessing Cognitive Effort in L2 Idiomatic Processing: An Eye-Tracking Dataset
Pith reviewed 2026-05-08 17:21 UTC · model grok-4.3
The pith
L2 learners of English show more regressive eye movements on idioms at lower proficiency levels in a new eye-tracking dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
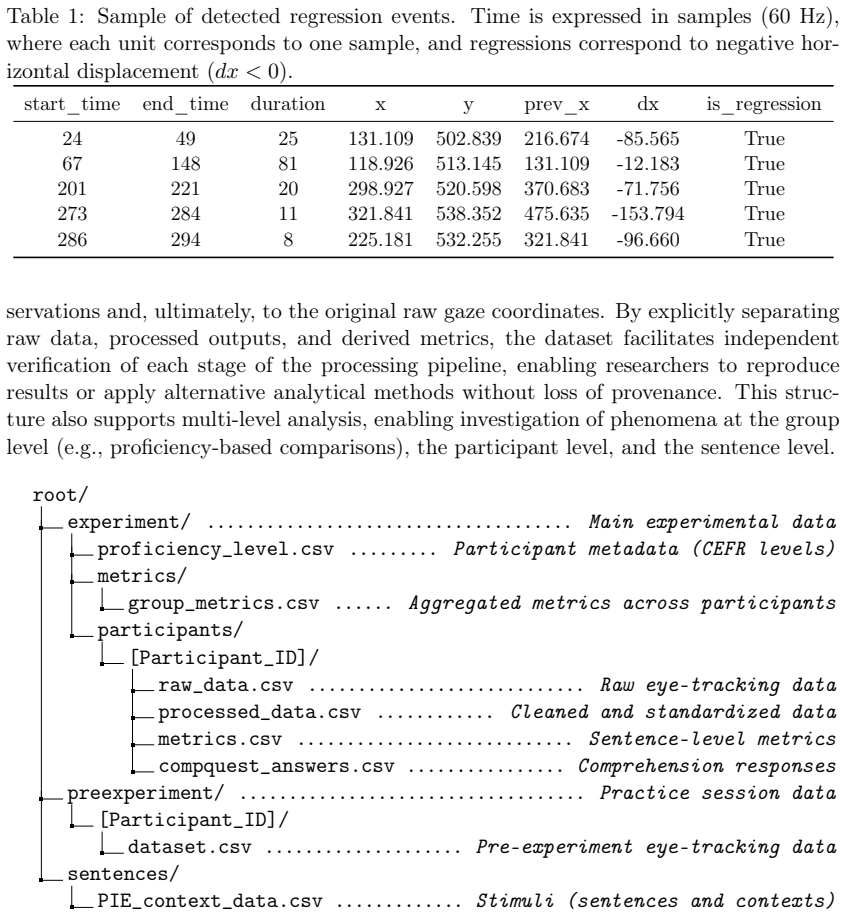
The central claim is that a new eye-tracking dataset recorded at 60 Hz from L2 learners across proficiency levels A1-C2 reliably indexes cognitive costs in idiomatic processing through ocular metrics, as evidenced by a strong inverse correlation between proficiency and regressive movements, while confirming sufficient data density for macro-cognitive events.
What carries the argument
Ocular metrics of fixations and regressions at 60 Hz sampling, used to index the cognitive cost of literal-first strategies in L2 idiom reading.
If this is right
- The dataset supplies a cognitively grounded benchmark for evaluating alignment between large language models and human figurative processing.
- Entry-level 60 Hz eye-trackers can support research on macro-cognitive events in second-language reading.
- Proficiency level modulates the frequency of regressions during idiom comprehension, with lower levels showing greater reliance on literal analysis.
- Integration into broader modeling initiatives enables direct comparisons of idiomaticity across human and artificial systems.
Where Pith is reading between the lines
- The same metrics could be applied to test whether language models internally simulate regression-like reprocessing when handling idioms.
- Educators might identify specific idioms that trigger extra regressions at particular proficiency thresholds to target instruction.
- Comparison with native-speaker eye data from the same idioms would quantify the added L2 processing cost in concrete terms.
Load-bearing premise
That regressive eye movements directly and reliably measure the extra cognitive cost of literal-first idiom processing in L2 learners and that 60 Hz hardware records these events without missing critical details that would weaken the proficiency correlation.
What would settle it
A replication with the same idioms and proficiency-grouped participants that finds no significant inverse correlation between CEFR level and regression frequency, or a higher-rate recording that shows systematic fixation differences missed at 60 Hz.
Figures

read the original abstract
This paper presents the development and validation of an eye-tracking dataset designed to investigate how second-language (L2) learners process idiomatic expressions. While native speakers often rely on direct retrieval of figurative meanings, L2 speakers frequently adopt a literal-first approach, which incurs measurable cognitive costs. This resource captures these costs through ocular metrics recorded from Portuguese L1 speakers of English across all CEFR proficiency levels (A1-C2). Although the study uses entry-level 60 Hz hardware (Tobii Pro Spark), we demonstrate that this sampling rate provides sufficient data density to detect macro-cognitive events such as fixations and regressions in reading. Preliminary analysis validates the dataset by revealing a strong inverse correlation between language proficiency and regressive eye movements. Integrated into the MIA (Modeling Idiomaticity in Human and Artificial Language Processing) initiative, this dataset serves as a cognitively grounded benchmark for evaluating both human processing models and the alignment of large language models with human-like figurative understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a new eye-tracking dataset collected from Portuguese L1 speakers of English across CEFR proficiency levels A1-C2 to study cognitive effort in L2 idiomatic processing. It uses entry-level 60 Hz Tobii Pro Spark hardware and claims this rate yields sufficient data density for detecting fixations and regressions. Preliminary analysis is reported to show a strong inverse correlation between proficiency and regressive eye movements, positioning the resource as a benchmark within the MIA initiative for human and AI models of figurative language.
Significance. If the sampling-rate validation and correlation can be substantiated with full methodological details, the dataset would supply a useful, cognitively grounded resource for psycholinguistic work on literal-first strategies in L2 idiom processing and for benchmarking LLM alignment with human figurative comprehension. The emphasis on accessible hardware could also facilitate wider data collection.
major comments (2)
- [Abstract] Abstract: The claim that 60 Hz sampling 'provides sufficient data density to detect macro-cognitive events such as fixations and regressions' is unsupported. No section describes the fixation/saccade detection algorithm (velocity or dispersion thresholds), reports a comparison against higher-rate ground truth, or tests for systematic under-counting of regressions in lower-proficiency readers who may produce shorter or more variable saccades. This directly undermines the interpretability of the reported proficiency-regression correlation as evidence of dataset validity rather than a possible measurement artifact.
- [Preliminary analysis] Preliminary analysis / Results section: The manuscript states a 'strong inverse correlation' between CEFR proficiency and regressive eye movements but provides no participant counts per level, stimulus details, exact statistical tests, effect sizes, error bars, or controls for confounds such as overall reading speed or individual saccade variability. These omissions prevent verification that the correlation supports the central validation claim.
minor comments (1)
- [Abstract] The abstract mentions integration into the MIA initiative but does not clarify how the dataset will be released or what specific evaluation protocols it supports for human vs. model comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for strengthening the methodological transparency and reporting of our dataset. We respond to each major comment below and will incorporate revisions as outlined.
read point-by-point responses
-
Referee: The claim that 60 Hz sampling 'provides sufficient data density to detect macro-cognitive events such as fixations and regressions' is unsupported. No section describes the fixation/saccade detection algorithm (velocity or dispersion thresholds), reports a comparison against higher-rate ground truth, or tests for systematic under-counting of regressions in lower-proficiency readers who may produce shorter or more variable saccades. This directly undermines the interpretability of the reported proficiency-regression correlation as evidence of dataset validity rather than a possible measurement artifact.
Authors: We agree that the manuscript requires expanded methodological detail to substantiate the sampling-rate claim. In revision we will fully describe the fixation and saccade detection algorithm, including the exact velocity and dispersion thresholds applied. We will add an analysis of saccade duration and variability across CEFR levels to evaluate potential under-counting of regressions. Although paired higher-rate ground-truth recordings are not available, we will cite established reading-research literature on 60 Hz sufficiency for macro-events and discuss this limitation explicitly. These additions will clarify that the observed correlation is not an artifact. revision: partial
-
Referee: The manuscript states a 'strong inverse correlation' between CEFR proficiency and regressive eye movements but provides no participant counts per level, stimulus details, exact statistical tests, effect sizes, error bars, or controls for confounds such as overall reading speed or individual saccade variability. These omissions prevent verification that the correlation supports the central validation claim.
Authors: We acknowledge the reporting gaps in the preliminary analysis. The revised manuscript will supply participant counts per CEFR level, complete stimulus specifications, the precise statistical tests performed (with p-values), effect sizes accompanied by error bars or confidence intervals, and confound controls via partial-correlation or regression models that account for reading speed and saccade variability. This will permit full verification of the correlation's validity. revision: yes
Circularity Check
No circularity: empirical dataset validation rests on independent correlation finding
full rationale
The paper presents an eye-tracking dataset and reports a preliminary empirical finding of an inverse correlation between CEFR proficiency and regressive eye movements. No equations, derivations, fitted parameters, or self-citations are invoked to derive or validate this result; the correlation is computed directly from the collected data. The claim that 60 Hz sampling suffices for macro-event detection is presented as a demonstration from the recordings themselves rather than a self-referential fit or imported uniqueness theorem. The analysis chain is self-contained against external benchmarks (standard psycholinguistic ocular metrics) with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Eye-tracking metrics such as number of regressions reflect cognitive effort and literal-first processing strategies in L2 idiom comprehension.
Reference graph
Works this paper leans on
-
[1]
On catching on to idiomatic expressions , author=. Memory & Cognition , volume=
-
[2]
Journal of Experimental Psychology: General , year=
Toward a compositional view of idiom processing , author=. Journal of Experimental Psychology: General , year=
-
[3]
Second Language Research , volume=
Literal salience in on-line processing of idiomatic expressions by second language learners , author=. Second Language Research , volume=
-
[4]
Formulaic sequences: Are they processed more quickly than nonformulaic language by native and nonnative speakers? , author=. Applied Linguistics , volume=
-
[5]
Studies in Second Language Acquisition , volume=
Adding more fuel to the fire: An eye-tracking study of idiom processing by native and non-native speakers , author=. Studies in Second Language Acquisition , volume=
-
[6]
MAGPIE: A large corpus of potentially idiomatic expressions , author=. Proceedings of LREC , year=
-
[7]
Proceedings of SemEval , year=
SemEval-2025 Task 1: Advancing Multimodal Idiomaticity Representation (AdMIRe) , author=. Proceedings of SemEval , year=
work page 2025
-
[8]
Journal of Neuroscience Methods , volume=
PsychoPy—Psychophysics software in Python , author=. Journal of Neuroscience Methods , volume=
-
[9]
Behavior Research Methods , volume=
PyGaze: An open-source, cross-platform toolbox for minimal-effort programming of eyetracking experiments , author=. Behavior Research Methods , volume=
-
[10]
Rambelli, Giulia and Chersoni, Emmanuele and Senaldi, Marco and Blache, Philippe and Lenci, Alessandro , urldate =. Are Frequent Phrases Directly Retrieved like Idioms? An Investigation with Self-paced Reading and Language Models , url =. Workshop on Multiword Expressions (. 2023 , file =
work page 2023
-
[11]
Frontiers in Computational Neuroscience , author =
How the Brain Represents Language and Answers Questions? Using an. Frontiers in Computational Neuroscience , author =. 2019 , file =
work page 2019
-
[12]
Investigating Idiomaticity in Word Representations
Investigating Idiomaticity in Word Representations , volume =. Computational Linguistics , author =. 2025 , file =. doi:10.1162/coli_a_00546 , abstract =
-
[13]
and Wilkens, Rodrigo and Villavicencio, Aline and Hubner, Lilian C
Ribeiro, Marina and Malcorra, Bárbara and Mota, Natália B. and Wilkens, Rodrigo and Villavicencio, Aline and Hubner, Lilian C. and Rennó-Costa, César , urldate =. A Methodology for Explainable Large Language Models with Integrated Gradients and Linguistic Analysis in Text Classification , url =. 2024 , eprinttype =. doi:10.48550/arXiv.2410.00250 , abstrac...
-
[14]
Swinney, David A. and Cutler, Anne , urldate =. The access and processing of idiomatic expressions , volume =. Journal of Verbal Learning and Verbal Behavior , shortjournal =. 1979 , file =. doi:10.1016/S0022-5371(79)90284-6 , abstract =
-
[15]
Sag, Timothy Baldwin, Francis Bond, Ann Copestake, and Dan Flickinger
Sag, Ivan A. and Baldwin, Timothy and Bond, Francis and Copestake, Ann and Flickinger, Dan , editor =. Multiword Expressions: A Pain in the Neck for. Computational Linguistics and Intelligent Text Processing , publisher =. 2002 , langid =. doi:10.1007/3-540-45715-1_1 , shorttitle =
-
[16]
Cieślicka, Anna , urldate =. Literal salience in on-line processing of idiomatic expressions by second language learners , volume =. Second Language Research , publisher =. doi:10.1191/0267658306sr263oa , abstract =
- [17]
-
[18]
Leon, Frances Laureano De and Madabushi, Harish Tayyar and Lee, Mark G. , urldate =. Evaluating Large Language Models on Multiword Expressions in Multilingual and Code-Switched Contexts , url =. doi:10.48550/arXiv.2504.20051 , abstract =. 2504.20051 [cs] , keywords =
-
[19]
Bollepally, Samhita and Sloman-Moll, Aurora and Yamauchi, Takashi , urldate =. Can. doi:10.48550/arXiv.2601.09041 , shorttitle =. 2601.09041 [cs] , keywords =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.