SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
Pith reviewed 2026-05-22 10:45 UTC · model grok-4.3
The pith
SpecBlock uses block-iterative drafting to combine path dependence with low-cost token prediction for faster LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
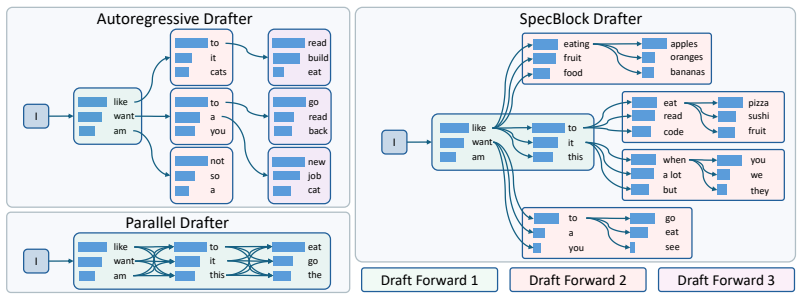
SpecBlock grows a draft tree by repeated expansions where each drafter call produces a block of K positions with explicit path dependence carried via layer-wise hidden state shifts and cross-block inheritance, replacing fixed top-k with a co-trained rank head for dynamic branching and using a valid-prefix mask during training to match inference prefixes.
What carries the argument
Block-iterative drafter with layer-wise shift for intra-block dependence and inheritance for inter-block extension, plus rank head and valid-prefix mask.
If this is right
- Mean speedup improves by 8-13% over EAGLE-3 while drafting cost drops to 44-52% of that baseline.
- Cost-aware adaptation at deployment further boosts the speedup lead to 11-19%.
- The dynamic branching allocates verifier effort to positions with higher expected acceptance.
- Training aligns better with inference by dropping loss on positions after an early error in the prefix.
Where Pith is reading between the lines
- This method suggests that hybrid dependence mechanisms could improve other parallel prediction approaches in sequence generation tasks.
- Runtime adaptation via bandit feedback might be extended to tune other hyperparameters in LLM inference pipelines.
- Applying similar block structures to non-autoregressive models could reduce latency in different generation settings.
Load-bearing premise
The path dependence carried by layer shifts and inheritance, together with the rank head and mask, keeps draft accuracy high enough that the lower number of drafter calls produces net gains in speed without a large rise in rejections by the verifier.
What would settle it
Measuring a substantial drop in the average number of accepted tokens per verification step that cancels out the savings from fewer drafter forwards.
Figures






read the original abstract
Speculative decoding accelerates LLM inference by drafting a tree of candidate continuations and verifying it in one target forward. Existing drafters fall into two camps with opposite weaknesses. Autoregressive drafters such as EAGLE-3 preserve dependence along each draft path but call the drafter once per tree depth, making drafting a non-trivial share of per-iteration latency. Parallel drafters cut drafter calls by predicting multiple future positions in one forward, but each position is predicted without seeing the others, producing paths the verifier rejects. In this paper, we propose SpecBlock, a block-iterative drafter that combines path dependence with cheap drafting. Each drafter forward produces K dependent positions and we call this a block. The draft tree grows through repeated block expansions. Two mechanisms explicitly carry path dependence to keep later draft positions accurate. Within each block, a layer-wise shift carries the previous position's hidden state into every decoder layer. Across blocks, each new block can start from any position of the previous block, inheriting its hidden state to extend the path. To spend verifier budget where acceptance is likely, a co-trained rank head replaces the fixed top-k tree by allocating per-position branching during drafting. To avoid training the drafter on prefixes it never produces at inference, a valid-prefix mask drops the loss at later positions once an earlier one is wrong. Beyond static drafting, a cost-aware bandit at deployment uses free verifier feedback to update the drafter selectively, only when the expected throughput gain exceeds the update cost. Experiments show that SpecBlock improves mean speedup by 8-13% over EAGLE-3 at 44-52% of its drafting cost, and cost-aware adaptation extends this lead to 11-19%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpecBlock, a block-iterative speculative decoding framework for LLMs. Each drafter forward pass generates a block of K dependent tokens; the draft tree is expanded iteratively across blocks. Path dependence is maintained via layer-wise hidden-state shifts within a block and selective inheritance of hidden states from any prior-block position to the next block. Additional components include a co-trained rank head for dynamic per-position branching, a valid-prefix mask that drops loss on positions after an early error, and a cost-aware bandit that selectively updates the drafter at deployment using verifier feedback. The central empirical claim is an 8-13% mean speedup improvement over EAGLE-3 at 44-52% of its drafting cost, rising to 11-19% with the bandit adaptation.
Significance. If the reported speedups and cost reductions hold under rigorous conditions, the work offers a practical middle ground between fully autoregressive drafters (high dependence, high latency) and parallel drafters (low latency, low dependence). The explicit mechanisms for carrying path dependence across blocks and the online adaptation strategy are technically interesting and could influence subsequent speculative-decoding designs, especially in throughput-sensitive serving scenarios. The paper does not claim parameter-free derivations or machine-checked proofs.
major comments (2)
- [§4.2] §4.2 (Path-Dependence Mechanisms): The central performance claim rests on the premise that layer-wise hidden-state shift inside each block plus selective cross-block inheritance (combined with the valid-prefix mask) preserve per-position draft accuracy sufficiently that the measured 44-52% drafter-cost reduction yields net wall-clock gains rather than being offset by shorter accepted prefixes or higher verifier rejection rates. No ablation isolating these two mechanisms (e.g., acceptance-length histograms or per-position rejection rates with/without the shift and inheritance) is presented; without such evidence the translation from cost reduction to speedup remains an unverified assumption.
- [§5] §5 (Experiments): The headline numbers (8-13% and 11-19% speedups, 44-52% cost) are load-bearing for the contribution. The manuscript should report error bars across multiple runs, exact dataset/model configurations, and statistical significance tests; the current presentation leaves open whether the gains are robust or configuration-specific.
minor comments (2)
- [Introduction] The definition of block size K and its interaction with tree depth should be stated once in the introduction and used consistently thereafter.
- [Figure 3] Figure captions for the draft-tree diagrams would benefit from explicit annotation of which positions inherit hidden states from the prior block.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the technical interest of the path-dependence mechanisms and online adaptation in SpecBlock. We address each major comment below and will incorporate revisions to strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Path-Dependence Mechanisms): The central performance claim rests on the premise that layer-wise hidden-state shift inside each block plus selective cross-block inheritance (combined with the valid-prefix mask) preserve per-position draft accuracy sufficiently that the measured 44-52% drafter-cost reduction yields net wall-clock gains rather than being offset by shorter accepted prefixes or higher verifier rejection rates. No ablation isolating these two mechanisms (e.g., acceptance-length histograms or per-position rejection rates with/without the shift and inheritance) is presented; without such evidence the translation from cost reduction to speedup remains an unverified assumption.
Authors: We agree that dedicated ablations isolating the layer-wise hidden-state shift and cross-block inheritance would strengthen the manuscript by directly verifying their contribution to maintaining draft accuracy. In the revised version we will add these ablations, including acceptance-length histograms and per-position rejection rates for configurations with and without the shift and inheritance (while retaining the valid-prefix mask). This will provide explicit evidence that the mechanisms enable the observed net speedups at reduced drafting cost. revision: yes
-
Referee: [§5] §5 (Experiments): The headline numbers (8-13% and 11-19% speedups, 44-52% cost) are load-bearing for the contribution. The manuscript should report error bars across multiple runs, exact dataset/model configurations, and statistical significance tests; the current presentation leaves open whether the gains are robust or configuration-specific.
Authors: We concur that reporting error bars, precise configurations, and statistical significance tests will better establish robustness. In the revision we will update the experimental section to include results from multiple independent runs with error bars, fully specify the models, datasets, and hardware, and add statistical significance tests (e.g., paired t-tests) comparing SpecBlock against EAGLE-3. revision: yes
Circularity Check
No circularity: empirical speedups rest on experimental comparison, not self-referential derivations
full rationale
The paper introduces SpecBlock via architectural descriptions of block-iterative drafting, layer-wise hidden-state shifts, cross-block inheritance, a valid-prefix mask, rank head, and cost-aware bandit adaptation. All performance claims (8-13% mean speedup over EAGLE-3 at 44-52% drafting cost, extended to 11-19% with adaptation) are presented strictly as measured experimental outcomes on standard benchmarks. No equations, first-principles derivations, or fitted parameters are shown that reduce the reported gains to inputs by construction; the mechanisms are motivated by qualitative weaknesses of prior drafters and validated externally via wall-clock and acceptance-rate measurements. The derivation chain is therefore self-contained against independent benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- block size K
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Within each block, a layer-wise shift carries the previous position’s hidden state into every decoder layer... Across blocks, each new block can start from any position of the previous block, inheriting its hidden state
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
K=4 and M=2 blocks per inference iteration, materializing a verifier tree of up to 60 nodes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
work page 2023
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating large language model serving with tree-based speculative inference and verification. InProceedings of the 29th ACM I...
work page 2024
-
[4]
Spectr: Fast speculative decoding via optimal transport
Ziteng Sun, Ananda Theertha Suresh, Jae Hun Ro, Ahmad Beirami, Himanshu Jain, and Felix Yu. Spectr: Fast speculative decoding via optimal transport. volume 36, pages 30222–30242, 2023
work page 2023
-
[5]
Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Ros- tamizadeh, Sanjiv Kumar, Jean-François Kagy, and Rishabh Agarwal. Distillspec: Improving speculative decoding via knowledge distillation.arXiv preprint arXiv:2310.08461, 2023
-
[6]
Sequoia: Scalable and robust speculative decoding
Zhuoming Chen, Avner May, Ruslan Svirschevski, Yuhsun Huang, Max Ryabinin, Zhihao Jia, and Beidi Chen. Sequoia: Scalable and robust speculative decoding. volume 37, pages 129531–129563, 2024
work page 2024
-
[7]
Eagle: Speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty. 2024
work page 2024
-
[8]
Eagle-2: Faster inference of language models with dynamic draft trees
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees. pages 7421–7432, 2024
work page 2024
-
[9]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint arXiv:2503.01840, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Medusa: Simple llm inference acceleration framework with multiple decoding heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. 2024
work page 2024
-
[11]
Learning harmonized represen- tations for speculative sampling.arXiv preprint arXiv:2408.15766, 2024
Lefan Zhang, Xiaodan Wang, Yanhua Huang, and Ruiwen Xu. Learning harmonized represen- tations for speculative sampling.arXiv preprint arXiv:2408.15766, 2024
-
[12]
Draft& verify: Lossless large language model acceleration via self-speculative decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. Draft& verify: Lossless large language model acceleration via self-speculative decoding. pages 11263–11282, 2024
work page 2024
-
[13]
Fangcheng Liu, Yehui Tang, Zhenhua Liu, Yunsheng Ni, Kai Han, and Yunhe Wang. Kangaroo: Lossless self-speculative decoding via double early exiting.arXiv preprint arXiv:2404.18911, 2024
-
[14]
Rest: Retrieval-based speculative decoding
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason Lee, and Di He. Rest: Retrieval-based speculative decoding. pages 1582–1595, 2024
work page 2024
-
[15]
Break the sequential dependency of llm inference using lookahead decoding
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm inference using lookahead decoding.arXiv preprint arXiv:2402.02057, 2024. 10
-
[16]
Blockwise parallel decoding for deep autoregressive models
Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models. volume 31, 2018
work page 2018
-
[17]
Feng Lin, Hanling Yi, Yifan Yang, Hongbin Li, Xiaotian Yu, Guangming Lu, and Rong Xiao. Bita: Bi-directional tuning for lossless acceleration in large language models.Expert Systems with Applications, 279:127305, 2025
work page 2025
-
[18]
Zilin Xiao, Hongming Zhang, Tao Ge, Siru Ouyang, Vicente Ordonez, and Dong Yu. Paral- lelspec: Parallel drafter for efficient speculative decoding.arXiv preprint arXiv:2410.05589, 2024
-
[19]
Zihao An, Huajun Bai, Ziqiong Liu, Dong Li, and Emad Barsoum. Pard: Accelerating llm inference with low-cost parallel draft model adaptation.arXiv preprint arXiv:2504.18583, 2025
-
[20]
Fuliang Liu, Xue Li, Ketai Zhao, Yinxi Gao, Ziyan Zhou, Zhonghui Zhang, Zhibin Wang, Wanchun Dou, Sheng Zhong, and Chen Tian. Dart: Diffusion-inspired speculative decoding for fast llm inference.arXiv preprint arXiv:2601.19278, 2026
-
[21]
Hydra: Sequentially-dependent draft heads for medusa decoding.arXiv preprint arXiv:2402.05109, 2024
Zachary Ankner, Rishab Parthasarathy, Aniruddha Nrusimha, Christopher Rinard, Jonathan Ragan-Kelley, and William Brandon. Hydra: Sequentially-dependent draft heads for medusa decoding.arXiv preprint arXiv:2402.05109, 2024
-
[22]
Fasteagle: Cascaded drafting for accelerating speculative decoding
Haiduo Huang, Jiangcheng Song, Wenzhe Zhao, and Pengju Ren. Fasteagle: Cascaded drafting for accelerating speculative decoding. pages 4111–4115, 2026
work page 2026
-
[23]
Xiangxiang Gao, Weisheng Xie, Yiwei Xiang, and Feng Ji. Falcon: Faster and parallel inference of large language models through enhanced semi-autoregressive drafting and custom-designed decoding tree. 39(22):23933–23941, 2025
work page 2025
-
[24]
Tianyu Liu, Yun Li, Qitan Lv, Kai Liu, Jianchen Zhu, Winston Hu, and Xiao Sun. Pearl: Parallel speculative decoding with adaptive draft length.arXiv preprint arXiv:2408.11850, 2024
-
[25]
Exploring and improving drafts in blockwise parallel decoding.arXiv preprint arXiv:2404.09221, 2024
Taehyeon Kim, Ananda Theertha Suresh, Kishore Papineni, Adrian Benton, and Michael Riley. Exploring and improving drafts in blockwise parallel decoding.arXiv preprint arXiv:2404.09221, 2024
-
[26]
Set block decoding is a language model inference accelerator.arXiv preprint arXiv:2509.04185, 2025
Itai Gat, Heli Ben-Hamu, Marton Havasi, Daniel Haziza, Jeremy Reizenstein, Gabriel Synnaeve, David Lopez-Paz, Brian Karrer, and Yaron Lipman. Set block decoding is a language model inference accelerator.arXiv preprint arXiv:2509.04185, 2025
-
[27]
Yunfei Cheng, Aonan Zhang, Xuanyu Zhang, Chong Wang, and Yi Wang. Recurrent drafter for fast speculative decoding in large language models.arXiv preprint arXiv:2403.09919, 2024
-
[28]
Feiye Huo, Jianchao Tan, Kefeng Zhang, Xunliang Cai, and Shengli Sun. C2t: A classifier-based tree construction method in speculative decoding.arXiv preprint arXiv:2502.13652, 2025
-
[29]
Jikai Wang, Yi Su, Juntao Li, Qingrong Xia, Zi Ye, Xinyu Duan, Zhefeng Wang, and Min Zhang. Opt-tree: Speculative decoding with adaptive draft tree structure.Transactions of the Association for Computational Linguistics, 13:188–199, 2025
work page 2025
-
[30]
Dyspec: Faster speculative decoding with dynamic token tree structure.World Wide Web, 28(3):36, 2025
Yunfan Xiong, Ruoyu Zhang, Yanzeng Li, and Lei Zou. Dyspec: Faster speculative decoding with dynamic token tree structure.World Wide Web, 28(3):36, 2025
work page 2025
-
[31]
Tianyu Liu, Qitan Lv, Yuhao Shen, Xiao Sun, and Xiaoyan Sun. Talon: Confidence-aware speculative decoding with adaptive token trees.arXiv preprint arXiv:2601.07353, 2026
-
[32]
Yunlong Hou, Fengzhuo Zhang, Cunxiao Du, Xuan Zhang, Jiachun Pan, Tianyu Pang, Chao Du, Vincent YF Tan, and Zhuoran Yang. Banditspec: Adaptive speculative decoding via bandit algorithms.arXiv preprint arXiv:2505.15141, 2025
-
[33]
SpecDec++: Boosting speculative decoding via adaptive candidate lengths
Kaixuan Huang, Xudong Guo, and Mengdi Wang. SpecDec++: Boosting speculative decoding via adaptive candidate lengths. InConference on Language Modeling, 2024
work page 2024
-
[34]
Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Alvin Cheung, Zhijie Deng, Ion Stoica, and Hao Zhang. Online speculative decoding. 2023. 11
work page 2023
-
[35]
Shrenik Bhansali and Larry Heck. Draft, verify, and improve: Toward training-aware speculative decoding.arXiv preprint arXiv:2510.05421, 2025
-
[36]
Jiyoung Park, Hankyu Jang, Changseok Song, and Wookeun Jung. Tide: Temporal incremental draft engine for self-improving llm inference.arXiv preprint arXiv:2602.05145, 2026
-
[37]
When RL Meets Adaptive Speculative Training: A Unified Training-Serving System
Junxiong Wang, Fengxiang Bie, Jisen Li, Zhongzhu Zhou, Zelei Shao, Yubo Wang, Yinghui Liu, Qingyang Wu, Avner May, Sri Yanamandra, et al. When rl meets adaptive speculative training: A unified training-serving system.arXiv preprint arXiv:2602.06932, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029–3051, 2023
work page 2023
-
[41]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 2023
work page 2023
-
[42]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Stanford alpaca: An instruction-following llama model, 2023
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model, 2023
work page 2023
-
[45]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
work page 2019
-
[46]
‘ python def fibonacci _recursive (n ):
Tom Kocmi, Rachel Bawden, Ondˇrej Bojar, Anton Dvorkovich, Christian Federmann, Mark Fishel, Thamme Gowda, Yvette Graham, Roman Grundkiewicz, Barry Haddow, et al. Find- ings of the 2022 conference on machine translation (wmt22). InProceedings of the Seventh Conference on Machine Translation (WMT), pages 1–45, 2022. 12 A Implementation Details A.1 Drafter ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.