HY-Himmel Technical Report: Hierarchical Interleaved Multi-stream Motion Encoding for Long Video Understanding
Pith reviewed 2026-05-12 01:26 UTC · model grok-4.3
The pith
HY-Himmel separates long videos into sparse I-frames for semantics and dense compressed-domain motion tokens, raising Video-MME accuracy by 2.3 points with 3.6 times fewer tokens than a dense 32-frame baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
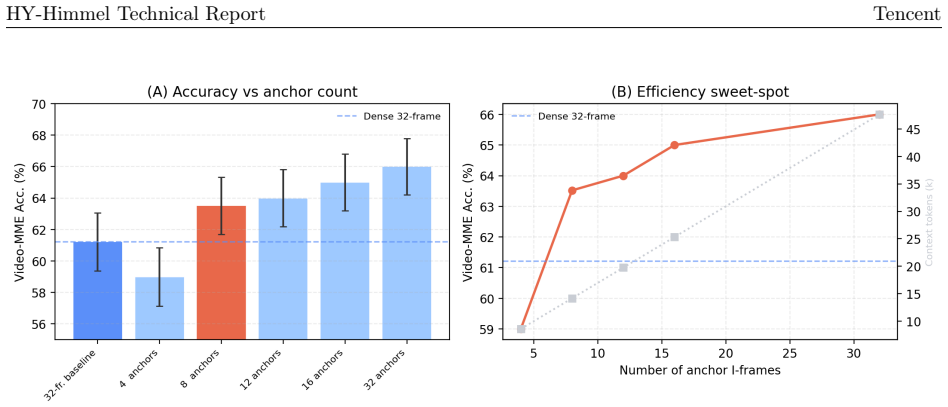
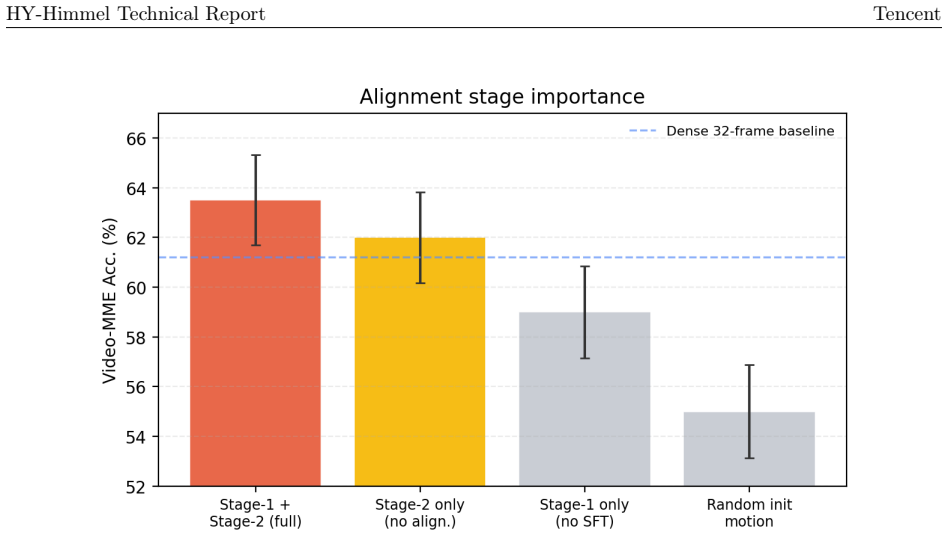
HY-Himmel claims that routing sparse I-frames to an expensive ViT for semantic grounding and encoding the remaining dense intervals with a compressed-domain tri-stream adapter produces motion tokens that, after Stage-1 contrastive alignment, integrate into the LLM via placeholders and deliver superior long-video understanding. On Video-MME the method exceeds the dense 32-frame baseline by 2.3 percentage points while consuming 3.6 times fewer context tokens. Ablations across stream composition, encoder family, fusion mode, alignment objective, anchor count, LoRA rank, and video length establish that the full tri-stream is both necessary and sufficient for the observed improvement.
What carries the argument
The hierarchical interleaved tri-stream motion encoder, which distils motion evidence from motion-vector maps, residual maps, and I-frame context into tokens aligned by contrastive learning for injection into a frozen visual backbone.
If this is right
- The full combination of motion-vector, residual, and I-frame streams is required to realize the reported accuracy gain.
- Reducing the number of anchor I-frames or altering fusion mode measurably degrades performance.
- The same token budget yields better results on longer videos than on short ones.
- LoRA rank and alignment objective each exert measurable influence on final accuracy.
Where Pith is reading between the lines
- The same separation of semantic anchors and motion streams could be applied to other sequence models that currently rely on uniform frame sampling.
- Because the motion pathway operates in the compressed domain, the method may extend naturally to real-time or bandwidth-constrained video streams.
- If the alignment objective generalizes, similar lightweight adapters could be trained for additional temporal modalities such as audio or optical flow without touching the visual backbone.
Load-bearing premise
Motion evidence extracted from compressed-domain maps can be contrastively aligned into tokens that remain compatible with the frozen visual backbone without critical loss of information.
What would settle it
A controlled run in which the contrastive alignment step is removed or replaced by random projection, after which accuracy on Video-MME falls to or below the dense 32-frame baseline despite using the same token budget.
Figures








































read the original abstract
Long-video understanding with multimodal language models suffers from three compounding bottlenecks: heavy decode cost to obtain dense RGB frames, quadratic token growth with frame count, and weak motion perception under sparse keyframe sampling. We present HY-Himmel, a hierarchical video-language framework that allocates semantic and motion capacity separately. A small set of sparse anchor I-frames is routed to the expensive host ViT to ground object identity and scene layout, while the far denser inter-frame intervals are encoded by a lightweight compressed-domain tri-stream adapter that distils motion evidence from motion-vector maps, residual maps, and I-frame context into aligned motion tokens. These tokens are injected into the LLM via a differentiable placeholder mechanism after a dedicated Stage-1 contrastive alignment that places the motion representation in a geometry compatible with the frozen visual backbone. On Video-MME, HY-Himmel surpasses the dense 32-frame baseline by +2.3 pp (61.2 to 63.5%) while using 3.6x fewer context tokens. Extensive ablations over stream composition, motion encoder family, fusion mode, alignment objective, anchor count, LoRA rank, and video duration confirm that the full tri-stream is necessary and sufficient for the observed gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HY-Himmel, a hierarchical video-language framework for long-video understanding that routes sparse anchor I-frames to a frozen ViT for semantic grounding while encoding denser inter-frame intervals via a lightweight tri-stream adapter. The adapter distills motion evidence from motion-vector maps, residual maps, and I-frame context into tokens that undergo Stage-1 contrastive alignment before injection into the LLM through a differentiable placeholder mechanism. On Video-MME the method reports 63.5% accuracy, a +2.3 pp improvement over a dense 32-frame baseline, while using 3.6x fewer context tokens; extensive ablations over stream composition, motion encoder family, fusion mode, alignment objective, anchor count, LoRA rank, and video duration are presented to support the design.
Significance. If the alignment and injection claims hold, the work offers a concrete route to scaling video MLLMs by decoupling semantic and motion capacity and exploiting compressed-domain signals, thereby lowering both decode cost and quadratic token growth. The reported token reduction combined with a modest accuracy gain on an external benchmark is practically relevant; the breadth of ablations over multiple design axes is a positive feature that helps isolate the contribution of the tri-stream architecture.
major comments (2)
- [Abstract] Abstract: the headline result (+2.3 pp on Video-MME with 3.6x fewer tokens) rests on the assumption that contrastive alignment of the tri-stream motion tokens produces representations compatible with the frozen ViT; because the absolute gain is modest, the manuscript must demonstrate that the injected tokens add signal rather than noise (e.g., via an ablation that replaces aligned tokens with unaligned or random tokens while keeping token count fixed).
- [§3.2] §3.2 (Placeholder mechanism): the differentiable placeholder used to inject motion tokens into the LLM is described at a high level but lacks an explicit formulation or gradient-flow analysis; without this it is impossible to verify that the mechanism preserves the information distilled by the tri-stream encoder and does not introduce a mismatch that undermines the token-efficiency claim.
minor comments (2)
- [Abstract] The abstract and results section should report error bars or standard deviations across multiple runs for the Video-MME numbers and all ablation tables so that the statistical significance of the +2.3 pp gain can be assessed.
- [§4] Clarify in the methods whether the dense 32-frame baseline uses the identical ViT and LLM backbone as HY-Himmel; any difference in implementation details could confound attribution of the gain to the tri-stream design.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We have carefully addressed each major comment below, making revisions to the manuscript where necessary to clarify our contributions and strengthen the empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline result (+2.3 pp on Video-MME with 3.6x fewer tokens) rests on the assumption that contrastive alignment of the tri-stream motion tokens produces representations compatible with the frozen ViT; because the absolute gain is modest, the manuscript must demonstrate that the injected tokens add signal rather than noise (e.g., via an ablation that replaces aligned tokens with unaligned or random tokens while keeping token count fixed).
Authors: We thank the referee for highlighting this important point. Our ablation studies on the alignment objective compare contrastive alignment against no alignment and other objectives, showing that the aligned tokens contribute positively to performance. However, to directly address the concern of signal versus noise, we will include an additional ablation in the revised manuscript where we replace the aligned motion tokens with random tokens (while keeping the token count fixed) and demonstrate a significant drop in accuracy. This will confirm that the tokens add meaningful signal rather than noise. revision: yes
-
Referee: [§3.2] §3.2 (Placeholder mechanism): the differentiable placeholder used to inject motion tokens into the LLM is described at a high level but lacks an explicit formulation or gradient-flow analysis; without this it is impossible to verify that the mechanism preserves the information distilled by the tri-stream encoder and does not introduce a mismatch that undermines the token-efficiency claim.
Authors: We agree that an explicit formulation would improve clarity. In the revised manuscript, we have expanded §3.2 to include the mathematical definition of the differentiable placeholder mechanism, including the equations governing token injection and the gradient flow analysis. Specifically, we show that the placeholder allows end-to-end differentiability, enabling gradients from the LLM loss to flow back to the tri-stream encoder without introducing information mismatch, thereby preserving the distilled motion evidence and supporting the token-efficiency claims. revision: yes
Circularity Check
No significant circularity detected; claims rest on external benchmarks and ablations.
full rationale
The paper presents an empirical framework for long-video understanding, with the headline result (+2.3 pp on Video-MME using fewer tokens) evaluated on an external benchmark and supported by ablations over multiple design axes (stream composition, alignment objective, etc.). No equations, derivations, or self-citations are shown to reduce any prediction or uniqueness claim to a fitted input or prior author result by construction. The contrastive alignment step is presented as a training procedure whose sufficiency is tested via ablation rather than assumed by definition, keeping the derivation chain self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Motion tokens extracted from motion-vector and residual maps can be contrastively aligned into a geometry compatible with a frozen visual backbone.
invented entities (1)
-
differentiable placeholder mechanism
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Feichtenhofer, Christoph and Fan, Haoqi and Malik, Jitendra and He, Kaiming , booktitle=
-
[3]
Li, Yanwei and Wang, Chengyao and Jia, Jiaya , journal=
-
[4]
He, Bo and Li, Hengduo and Jang, Young Kyun and Jia, Menglin and Cao, Xuefei and Shah, Ashish and Shrivastava, Abhinav and Lim, Ser-Nam , booktitle=
-
[5]
Zhang, Haoji and Wang, Yiqin and Tang, Yansong and Liu, Yong and Feng, Jiashi and Dai, Jifeng and Jin, Xiaojie , journal=
-
[6]
Li, Kunchang and Wang, Yali and He, Yinan and Li, Yizhuo and Wang, Yi and Liu, Yi and Wang, Zun and Xu, Jilan and Chen, Guo and Luo, Ping and Wang, Limin and Qiao, Yu , journal=
-
[7]
Lin, Bin and Ye, Yang and Zhu, Bin and Cui, Jiaxi and Ning, Munan and Jin, Peng and Yuan, Li , journal=
-
[8]
Chen, Yukang and Xue, Fuzhao and Li, Dacheng and Hu, Qinghao and Zhu, Ligeng and Li, Xiuyu and Fang, Yunhao and Tang, Haotian and Yang, Shang and Liu, Zhijian and He, Ethan and Yin, Hongxu and Molchanov, Pavlo and Kautz, Jan and Fan, Linxi and Zhu, Yuke and Lu, Yao and Han, Song , journal=
-
[9]
arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Zeng, Xiangyu and Li, Kunchang and Wang, Chenting and Li, Xinhao and Jiang, Tianxiang and Yan, Ziang and Li, Songze and Shi, Yansong and Yue, Zhengrong and Wang, Yi and Wang, Yali and Qiao, Yu and Wang, Limin , booktitle=. 2025 , note=
work page 2025
-
[12]
Shen, Xiaoqian and Xiong, Yunyang and Zhao, Changsheng and Wu, Lemeng and Chen, Jun and Zhu, Chenchen and Liu, Zechun and Xiao, Fanyi and Varadarajan, Balakrishnan and Bordes, Florian and Liu, Zhuang and Xu, Hu and Kim, Hyunwoo J. and Soran, Bilge and Krishnamoorthi, Raghuraman and Elhoseiny, Mohamed and Chandra, Vikas , booktitle=. 2025 , note=
work page 2025
-
[13]
arXiv preprint arXiv:2602.13191 , year=
Sarkar, Sayan Deb and Pautrat, R. arXiv preprint arXiv:2602.13191 , year=
-
[14]
Wan, Zhongwei and Wu, Ziang and Liu, Che and Huang, Jinfa and Zhu, Zhihong and Jin, Peng and Wang, Longyue and Yuan, Li , journal=
-
[15]
Zhang, Haowei and Yang, Shudong and Fu, Jinlan and Ng, See-Kiong and Qiu, Xipeng , booktitle=. 2026 , note=
work page 2026
-
[16]
NeurIPS Datasets and Benchmarks Track , year=
Perception Test: A Diagnostic Benchmark for Multimodal Video Models , author=. NeurIPS Datasets and Benchmarks Track , year=
-
[17]
Zhang, Yuanhan and Wu, Jinming and Li, Wei and Li, Bo and Ma, Zejun and Liu, Ziwei and Li, Chunyuan , journal=
-
[18]
Wu, Haoning and Li, Dongxu and Chen, Bei and Li, Junnan , booktitle=
-
[19]
Chandrasegaran, Keshigeyan and Gupta, Agrim and Hadzic, Lea M. and Kota, Taran and He, Jimming and Eyzaguirre, Cristobal and Durante, Zane and Li, Manling and Wu, Jiajun and Fei-Fei, Li , booktitle=
-
[20]
OpenAI Technical Report , year=
- [21]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.