GraphInstruct: A Progressive Benchmark for Diagnosing Capability Gaps in LLM Graph Generation
Pith reviewed 2026-05-20 23:08 UTC · model grok-4.3
The pith
Progressive benchmark diagnoses LLM graph generation gaps at multi-constraint levels, overcome by verification-guided prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
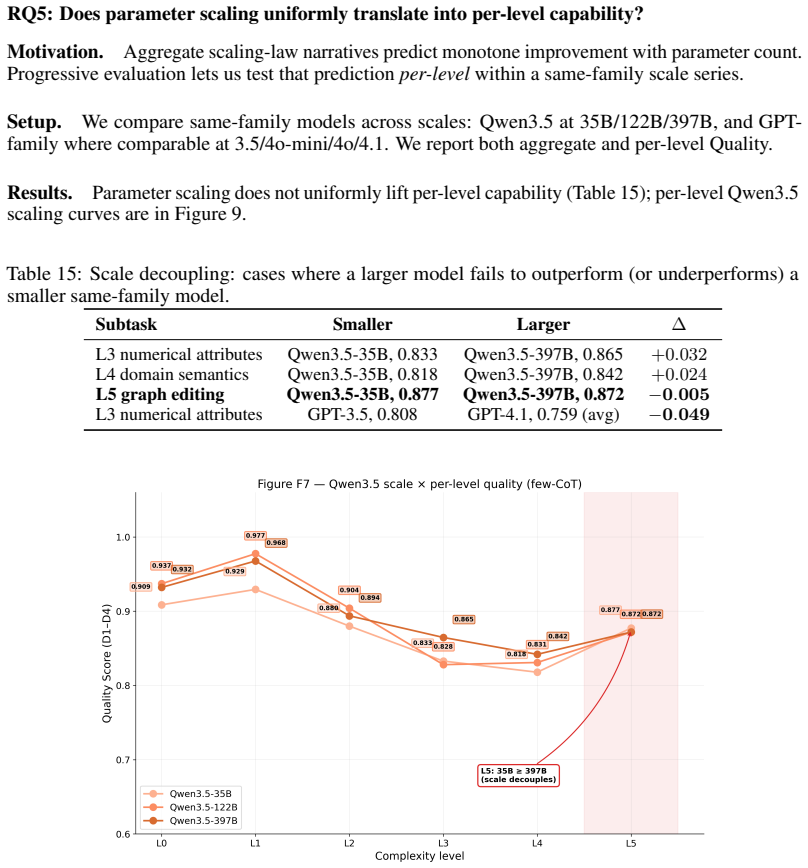
By organizing graph synthesis tasks into six progressive complexity levels paired with five evaluation dimensions, GraphInstruct localizes where LLMs fail during instruction-following generation. Evaluations across twelve models and forty-five strategy combinations demonstrate that the most distinguishing failures occur during multi-constraint composition rather than reasoning depth, with domain-semantic constraints proving resistant to iterative improvement. A verification-guided iterative framework employing constraint-aware adaptive prompting consistently exceeds the performance limits of conventional prompt engineering on the tested models.
What carries the argument
The verification-guided iterative framework with constraint-aware adaptive prompting, which uses output verification to dynamically adjust prompts and better meet the specified graph constraints at each complexity level.
If this is right
- Discriminative power of the benchmark reaches its peak when evaluating multi-constraint composition tasks.
- No prompting strategy proves superior across every complexity level and every model family tested.
- Constraints involving domain semantics stay difficult to satisfy even after multiple iterations of prompting.
- The detailed breakdown from the benchmark supports the creation of improved graph generation techniques.
Where Pith is reading between the lines
- Additional progress in this area may require integrating external retrieval systems to supply missing domain knowledge rather than relying solely on model iteration.
- The layered complexity design could help diagnose similar instruction-following problems in other structured output domains such as molecular formulas or social network models.
- Public release of the instructions and references invites independent checks on whether the identified gaps persist in newer or larger language models.
Load-bearing premise
The manually defined six complexity levels and five evaluation dimensions successfully isolate separate LLM capability gaps without creating unintended measurement biases or overlaps.
What would settle it
If evaluations using newly authored instructions at the same six levels produce different patterns of model failures or if the iterative framework shows no consistent gains on additional LLMs.
Figures

































read the original abstract
Graph-structured data underpins applications from citation analysis and social-network modeling to molecular design and knowledge-graph construction, and Large Language Models (LLMs) are increasingly used as prompt-driven graph synthesizers. Classical graph-generation reviews catalog deep generative models and their evaluation primitives, but predate the LLM era and provide no foundation for evaluating instruction-following graph synthesis. Recent LLM-era benchmarks evaluate models along graph-type or task-domain axes; such organizations, however, average over structural complexity and cannot localize where in the complexity spectrum an LLM breaks down. To close this diagnostic gap, we introduce GraphInstruct, a progressive-complexity benchmark that stratifies LLM graph generation into six complexity levels and five evaluation dimensions, paired with 800 hand-authored instructions, 1,582 algorithmically synthesized reference solutions, and a 12-LLM capability evaluation across 45 (model, strategy) configurations. We find that discriminative power peaks at multi-constraint composition rather than reasoning depth, that no single prompting strategy dominates across levels or model families, and that domain-semantic constraints remain iteration-invariant under all tested methods -- pointing to retrieval rather than additional compute as the next research frontier. Atop the benchmark, a verification-guided iterative framework with constraint-aware adaptive prompting consistently surpasses the prompt-engineering ceiling on tested target models, demonstrating that the benchmark's fine-grained signals drive method development. Data, code, and reproducibility artifacts are released alongside the paper at https://github.com/AI4DataSynth/GraphInstruct_formal
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GraphInstruct, a progressive benchmark for diagnosing capability gaps in LLM-based graph generation. It stratifies tasks into six complexity levels and five evaluation dimensions using 800 hand-authored instructions and 1,582 algorithmically synthesized reference solutions. The paper evaluates 12 LLMs across 45 (model, strategy) configurations, reports findings on discriminative power peaking at multi-constraint composition, iteration invariance of domain-semantic constraints, and introduces a verification-guided iterative framework with constraint-aware adaptive prompting that outperforms standard prompt engineering.
Significance. If the benchmark's complexity levels and dimensions accurately isolate distinct capability gaps without biases or overlaps, this work provides a valuable diagnostic tool for advancing LLM graph synthesis capabilities beyond existing task-domain or graph-type benchmarks. The empirical findings on where models break down and the public release of data, code, and reproducibility artifacts at the GitHub repository are strengths that could guide targeted method development in structured data generation.
major comments (3)
- [Benchmark Construction] Benchmark Construction section: The six progressive complexity levels and five evaluation dimensions are constructed from hand-authored instructions and algorithmically synthesized references, but no explicit validation (e.g., correlation analysis, orthogonality tests, or overlap checks between multi-constraint composition and domain-semantic requirements) is described to confirm they isolate distinct capability gaps without unintended biases. This is load-bearing for the central claim that the benchmark supplies fine-grained, non-confounded signals.
- [Reference Synthesis] Reference Synthesis subsection: The 1,582 algorithmically synthesized reference solutions are used as ground truth for evaluation, yet no manual verification, correctness sampling, or fidelity checks against the instructions are reported. This directly affects the reliability of the reported discriminative power and iteration-invariance findings.
- [Results and Analysis] Results and Analysis section: The claim that 'discriminative power peaks at multi-constraint composition rather than reasoning depth' and that 'no single prompting strategy dominates' requires the specific quantitative metric (e.g., accuracy delta, statistical test) and per-level breakdown used to establish the peak and dominance patterns.
minor comments (2)
- [Abstract] The abstract states that domain-semantic constraints 'remain iteration-invariant under all tested methods' but does not clarify whether this holds uniformly across the six complexity levels or only in aggregate.
- [Related Work] The paper would benefit from an explicit comparison table contrasting GraphInstruct against prior LLM graph benchmarks along the axes of complexity stratification and diagnostic granularity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important aspects of benchmark validation and empirical reporting that we address point by point below. We have prepared revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The six progressive complexity levels and five evaluation dimensions are constructed from hand-authored instructions and algorithmically synthesized references, but no explicit validation (e.g., correlation analysis, orthogonality tests, or overlap checks between multi-constraint composition and domain-semantic requirements) is described to confirm they isolate distinct capability gaps without unintended biases. This is load-bearing for the central claim that the benchmark supplies fine-grained, non-confounded signals.
Authors: We agree that explicit empirical validation would strengthen the central claim. The levels were designed following a logical progression grounded in graph-theoretic notions of structural complexity (e.g., from single-edge to multi-constraint compositions), and the five dimensions were chosen to separate structural, semantic, and constraint-based aspects. However, we did not report correlation or orthogonality statistics in the original submission. In the revised manuscript we will add a new subsection with pairwise correlation analysis across levels, overlap statistics between multi-constraint and domain-semantic instructions, and a brief orthogonality check using instruction embedding similarity. These additions will be placed in the Benchmark Construction section. revision: yes
-
Referee: [Reference Synthesis] Reference Synthesis subsection: The 1,582 algorithmically synthesized reference solutions are used as ground truth for evaluation, yet no manual verification, correctness sampling, or fidelity checks against the instructions are reported. This directly affects the reliability of the reported discriminative power and iteration-invariance findings.
Authors: The referee is correct that no manual verification sampling was described. The references were generated via a deterministic algorithmic pipeline that directly implements the instructions using standard graph libraries, with built-in consistency checks for basic validity (e.g., node/edge counts and constraint satisfaction). To address the concern, we will add a paragraph reporting a random sample of 100 references that were manually inspected for fidelity to the corresponding instructions, along with the observed error rate. This verification procedure and its results will be included in the revised Reference Synthesis subsection. revision: yes
-
Referee: [Results and Analysis] Results and Analysis section: The claim that 'discriminative power peaks at multi-constraint composition rather than reasoning depth' and that 'no single prompting strategy dominates' requires the specific quantitative metric (e.g., accuracy delta, statistical test) and per-level breakdown used to establish the peak and dominance patterns.
Authors: We will clarify the supporting evidence. Discriminative power was quantified using the range of accuracy scores across models at each level (max–min accuracy delta), and the peak at multi-constraint composition was identified by comparing these deltas across the six levels. The statement that no single prompting strategy dominates is based on the observation that the best-performing strategy varies by model family and level, with no strategy achieving top rank in more than two levels. In the revision we will insert the exact delta values, a table with per-level accuracy ranges, and the per-strategy ranking breakdown to make these claims fully traceable. revision: yes
Circularity Check
No significant circularity; empirical benchmark and evaluations are self-contained
full rationale
The paper constructs GraphInstruct via 800 hand-authored instructions and 1,582 synthesized references to define six complexity levels and five evaluation dimensions, then reports empirical observations from evaluating 12 LLMs across 45 configurations. Central findings (discriminative power peaking at multi-constraint composition, domain-semantic constraints being iteration-invariant, and the verification-guided framework surpassing prompt-engineering baselines) are direct results of these tests rather than quantities defined in terms of themselves or forced by fitted parameters. No mathematical derivations, self-referential equations, or load-bearing self-citations reduce any claim to its inputs by construction. The benchmark and method development are presented as independent contributions with released artifacts for external verification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be meaningfully evaluated as prompt-driven graph synthesizers using natural language instructions.
invented entities (2)
-
Six progressive complexity levels
no independent evidence
-
Five evaluation dimensions
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GraphInstruct comprises 800 hand-authored instructions... six complexity levels... five evaluation dimensions... verification-guided iterative framework with constraint-aware adaptive prompting
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
discriminative power peaks at multi-constraint composition (L2)... domain-semantic constraints remain iteration-invariant
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Xiang, Sheng and Wen, Dong and Cheng, Dawei and Zhang, Ying and Qin, Lu and Qian, Zhengping and Lin, Xuemin , title =. The. 2022 , volume =
work page 2022
-
[3]
Demirci, Ege and Kerur, Rithwik and Singh, Ambuj , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) Student Research Workshop , year =
-
[4]
arXiv preprint arXiv:2403.14358 , year =
Yao, Yang and Wang, Xin and Zhang, Zeyang and Qin, Yijian and Wang, Ziwei and Chu, Xu and Yang, Yuekui and Zhu, Wenwu and Mei, Hong , title =. arXiv preprint arXiv:2403.14358 , year =
-
[5]
International Conference on Learning Representations (ICLR) , year =
Tang, Jianheng and Zhang, Qifan and Li, Yuhan and Liu, Nuo and Hua, Hongzhi and Jin, Jiawei and Wang, Yi and Huang, Xiao , title =. International Conference on Learning Representations (ICLR) , year =
-
[6]
Findings of the Association for Computational Linguistics (ACL) , year =
Wang, Jianing and Wu, Junda and Hou, Yupeng and Liu, Yao and Gao, Ming and McAuley, Julian , title =. Findings of the Association for Computational Linguistics (ACL) , year =
-
[7]
International Conference on Learning Representations (ICLR) , year =
Peng, Jie and Ji, Jiarui and Lei, Runlin and Wei, Zhewei and Liu, Yongchao and Hong, Chuntao , title =. International Conference on Learning Representations (ICLR) , year =
-
[8]
International Conference on Learning Representations (ICLR) , year =
Fatemi, Bahare and Halcrow, Jonathan and Perozzi, Bryan , title =. International Conference on Learning Representations (ICLR) , year =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Wang, Heng and Feng, Shangbin and He, Tianxing and Tan, Zhaoxuan and Han, Xiaochuang and Tsvetkov, Yulia , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
Chen, Nuo and Li, Yuhan and Tang, Jianheng and Li, Jia , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
-
[11]
Tang, Jiabin and Yang, Yuhao and Wei, Wei and Shi, Lei and Su, Lixin and Cheng, Suqi and Yin, Dawei and Huang, Chao , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) , year =
-
[12]
Findings of the Association for Computational Linguistics (ACL) , year =
Jin, Bowen and Xie, Chulin and Zhang, Jiawei and Roy, Kashob Kumar and Zhang, Yu and Li, Zheng and Li, Ruirui and Tang, Xianfeng and Wang, Suhang and Meng, Yu and Han, Jiawei , title =. Findings of the Association for Computational Linguistics (ACL) , year =
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
Besta, Maciej and Blach, Nils and Kubicek, Ales and Gerstenberger, Robert and Podstawski, Michal and Gianinazzi, Lukas and Gajda, Joanna and Lehmann, Tomasz and Niewiadomski, Hubert and Nyczyk, Piotr and Hoefler, Torsten , title =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[14]
International Conference on Learning Representations (ICLR) , year =
Luo, Linhao and Li, Yuan-Fang and Haffari, Gholamreza and Pan, Shirui , title =. International Conference on Learning Representations (ICLR) , year =
-
[15]
Findings of the Association for Computational Linguistics (EACL) , year =
Ye, Ruosong and Zhang, Caiqi and Wang, Runhui and Xu, Shuyuan and Zhang, Yongfeng , title =. Findings of the Association for Computational Linguistics (EACL) , year =
-
[16]
and Kaiser, Lukasz and Polosukhin, Illia , title =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[17]
and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D. and Dhariwal, Prafulla and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[18]
arXiv preprint arXiv:2303.08774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, Hugo and Martin, Louis and Stone, Kevin and others , title =. arXiv preprint arXiv:2307.09288 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and others , title =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yang, An and Yang, Baosong and Hui, Binyuan and Zheng, Bo and others , title =. arXiv preprint arXiv:2407.10671 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Yang, An and others , title =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2412.19437 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Chi, Ed and Le, Quoc and Zhou, Denny , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
International Conference on Learning Representations (ICLR) , year =
Wang, Xuezhi and Wei, Jason and Schuurmans, Dale and Le, Quoc and Chi, Ed and Narang, Sharan and Chowdhery, Aakanksha and Zhou, Denny , title =. International Conference on Learning Representations (ICLR) , year =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas and Cao, Yuan and Narasimhan, Karthik , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[28]
International Conference on Learning Representations (ICLR) , year =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , title =. International Conference on Learning Representations (ICLR) , year =
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[30]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[31]
International Conference on Learning Representations (ICLR) , year =
Gou, Zhibin and Shao, Zhihong and Gong, Yeyun and Shen, Yelong and Yang, Yujiu and Duan, Nan and Chen, Weizhu , title =. International Conference on Learning Representations (ICLR) , year =
-
[32]
International Conference on Learning Representations (ICLR) , year =
Huang, Jie and Chen, Xinyun and Mishra, Swaroop and Zheng, Huaixiu Steven and Yu, Adams Wei and Song, Xinying and Zhou, Denny , title =. International Conference on Learning Representations (ICLR) , year =
-
[33]
International Conference on Learning Representations (ICLR) , year =
Zhou, Denny and Scharli, Nathanael and Hou, Le and Wei, Jason and Scales, Nathan and Wang, Xuezhi and Schuurmans, Dale and Cui, Claire and Bousquet, Olivier and Le, Quoc and Chi, Ed , title =. International Conference on Learning Representations (ICLR) , year =
-
[34]
Kipf, Thomas N. and Welling, Max , title =. International Conference on Learning Representations (ICLR) , year =
- [35]
-
[36]
and Ying, Rex and Leskovec, Jure , title =
Hamilton, William L. and Ying, Rex and Leskovec, Jure , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[37]
International Conference on Learning Representations (ICLR) , year =
Xu, Keyulu and Hu, Weihua and Leskovec, Jure and Jegelka, Stefanie , title =. International Conference on Learning Representations (ICLR) , year =
-
[38]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Hu, Weihua and Fey, Matthias and Zitnik, Marinka and Dong, Yuxiao and Ren, Hongyu and Liu, Bowen and Catasta, Michele and Leskovec, Jure , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[39]
You, Jiaxuan and Ying, Rex and Ren, Xiang and Hamilton, William L. and Leskovec, Jure , title =. International Conference on Machine Learning (ICML) , year =
-
[40]
International Conference on Learning Representations (ICLR) , year =
Shi, Chence and Xu, Minkai and Zhu, Zhaocheng and Zhang, Weinan and Zhang, Ming and Tang, Jian , title =. International Conference on Learning Representations (ICLR) , year =
-
[41]
ICML 2018 Deep Generative Models Workshop , year =
De Cao, Nicola and Kipf, Thomas , title =. ICML 2018 Deep Generative Models Workshop , year =
work page 2018
-
[42]
International Conference on Artificial Neural Networks (ICANN) , year =
Simonovsky, Martin and Komodakis, Nikos , title =. International Conference on Artificial Neural Networks (ICANN) , year =
-
[43]
International Conference on Machine Learning (ICML) , year =
Jin, Wengong and Barzilay, Regina and Jaakkola, Tommi , title =. International Conference on Machine Learning (ICML) , year =
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year =
You, Jiaxuan and Liu, Bowen and Ying, Zhitao and Pande, Vijay and Leskovec, Jure , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[45]
International Conference on Learning Representations (ICLR) , year =
Vignac, Clement and Krawczuk, Igor and Siraudin, Antoine and Wang, Bohan and Cevher, Volkan and Frossard, Pascal , title =. International Conference on Learning Representations (ICLR) , year =
-
[46]
International Conference on Machine Learning (ICML) , year =
Jo, Jaehyeong and Lee, Seul and Hwang, Sung Ju , title =. International Conference on Machine Learning (ICML) , year =
-
[47]
Transactions on Machine Learning Research (TMLR) , year =
Liang, Percy and Bommasani, Rishi and Lee, Tony and Tsipras, Dimitris and Soylu, Dilara and Yasunaga, Michihiro and others , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[48]
Transactions on Machine Learning Research (TMLR) , year =
Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and others , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[49]
International Conference on Learning Representations (ICLR) , year =
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , title =. International Conference on Learning Representations (ICLR) , year =
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and others , title =. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
-
[51]
Training Verifiers to Solve Math Word Problems
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and others , title =. arXiv preprint arXiv:2110.14168 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Evaluating Large Language Models Trained on Code
Chen, Mark and Tworek, Jerry and Jun, Heewoo and Yuan, Qiming and Pinto, Henrique Ponde de Oliveira and others , title =. arXiv preprint arXiv:2107.03374 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Suzgun, Mirac and Scales, Nathan and Sch. Challenging. Findings of the Association for Computational Linguistics (ACL) , year =
-
[54]
Scaling Laws for Neural Language Models
Kaplan, Jared and McCandlish, Sam and Henighan, Tom and Brown, Tom B. and Chess, Benjamin and Child, Rewon and others , title =. arXiv preprint arXiv:2001.08361 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[56]
Transactions on Machine Learning Research (TMLR) , year =
Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and others , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[57]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Schaeffer, Rylan and Miranda, Brando and Koyejo, Sanmi , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[58]
and Khashabi, Daniel and Hajishirzi, Hannaneh , title =
Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A. and Khashabi, Daniel and Hajishirzi, Hannaneh , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[59]
International Conference on Learning Representations (ICLR) , year =
Xu, Can and Sun, Qingfeng and Zheng, Kai and Geng, Xiubo and Zhao, Pu and Feng, Jiazhan and Tao, Chongyang and Jiang, Daxin , title =. International Conference on Learning Representations (ICLR) , year =
-
[60]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[61]
Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen
Dong, Yixin and Ruan, Charlie F. and Cai, Yaxing and Lai, Ruihang and Xu, Ziyi and Zhao, Yilong and Chen, Tianqi , title =. arXiv preprint arXiv:2411.15100 , year =
-
[62]
Willard, Brandon T. and Louf, R\'. Efficient Guided Generation for Large Language Models , journal =
-
[63]
Proceedings of the ACM on Programming Languages , volume =
Beurer-Kellner, Luca and Fischer, Marc and Vechev, Martin , title =. Proceedings of the ACM on Programming Languages , volume =. 2023 , doi =
work page 2023
-
[64]
Emergence of Scaling in Random Networks , journal =
Barab. Emergence of Scaling in Random Networks , journal =
-
[65]
Watts, Duncan J. and Strogatz, Steven H. , title =. Nature , volume =. 1998 , doi =
work page 1998
- [66]
-
[67]
Newman, Mark , title =
-
[68]
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , title =. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[69]
Text Summarization Branches Out: Proceedings of the ACL Workshop , year =
Lin, Chin-Yew , title =. Text Summarization Branches Out: Proceedings of the ACL Workshop , year =
-
[70]
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q. and Artzi, Yoav , title =. International Conference on Learning Representations (ICLR) , year =
-
[71]
Gretton, Arthur and Borgwardt, Karsten M. and Rasch, Malte J. and Sch. A Kernel Two-Sample Test , journal =
-
[72]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , title =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , year =
work page 2019
-
[73]
Sen, Prithviraj and Namata, Galileo and Bilgic, Mustafa and Getoor, Lise and Galligher, Brian and Eliassi-Rad, Tina , title =. AI Magazine , volume =. 2008 , doi =
work page 2008
-
[74]
and Sterling, Teague and Mysinger, Michael M
Irwin, John J. and Sterling, Teague and Mysinger, Michael M. and Bolstad, Erin S. and Coleman, Ryan G. , title =. Journal of Chemical Information and Modeling , volume =
-
[75]
and Rupp, Matthias and von Lilienfeld, O
Ramakrishnan, Raghunathan and Dral, Pavlo O. and Rupp, Matthias and von Lilienfeld, O. Anatole , title =. Scientific Data , volume =
-
[76]
ACM Transactions on Knowledge Discovery from Data (TKDD) , volume =
Leskovec, Jure and Kleinberg, Jon and Faloutsos, Christos , title =. ACM Transactions on Knowledge Discovery from Data (TKDD) , volume =. 2007 , doi =
work page 2007
-
[77]
ACM Transactions on Information Systems (TOIS) , volume =
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and others , title =. ACM Transactions on Information Systems (TOIS) , volume =. 2025 , doi =
work page 2025
-
[78]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and others , title =. arXiv preprint arXiv:2212.08073 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Datasheets for Datasets , journal =
Gebru, Timnit and Morgenstern, Jamie and Vecchione, Briana and Vaughan, Jennifer Wortman and Wallach, Hanna and Iii, Hal Daum. Datasheets for Datasets , journal =. 2021 , doi =
work page 2021
-
[80]
Huang, Haoyu and Chen, Chong and Sheng, Zeang and Li, Yang and Zhang, Wentao , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.