Recognition: 2 theorem links
· Lean TheoremFERA: Uncertainty-Aware Federated Reasoning for Large Language Models
Pith reviewed 2026-05-12 03:28 UTC · model grok-4.3
The pith
A server improves multi-step LLM reasoning by iteratively aggregating client traces weighted by their uncertainty estimates without accessing private data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
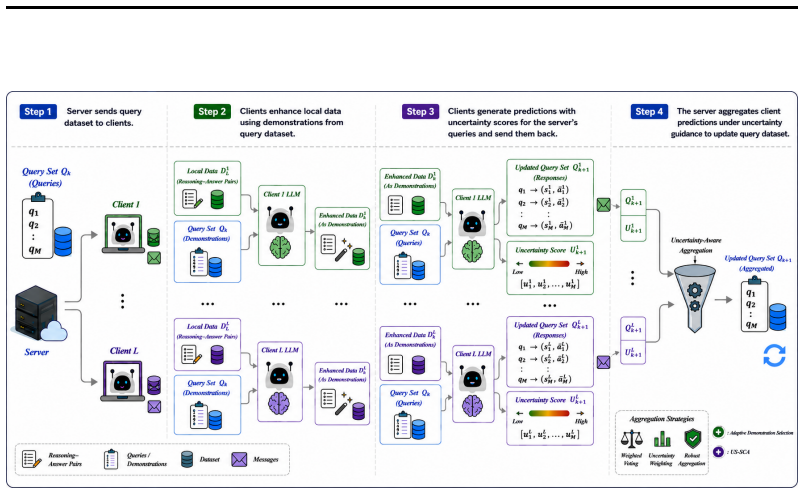
FERA is an iterative server-client co-refinement protocol in which clients generate reasoning traces with per-step uncertainty estimates, the server synthesizes them via query-dependent trust weighting and structured cross-client verification to produce improved reasoning, and the improved traces are redistributed to clients for subsequent rounds, yielding convergence guarantees and higher accuracy on multi-step tasks.
What carries the argument
Uncertainty-Aware Self-Critique Aggregation (UA-SCA), which resolves conflicts among heterogeneous client traces through query-dependent trust weighting and revises flawed reasoning steps to recover useful information instead of discarding traces.
If this is right
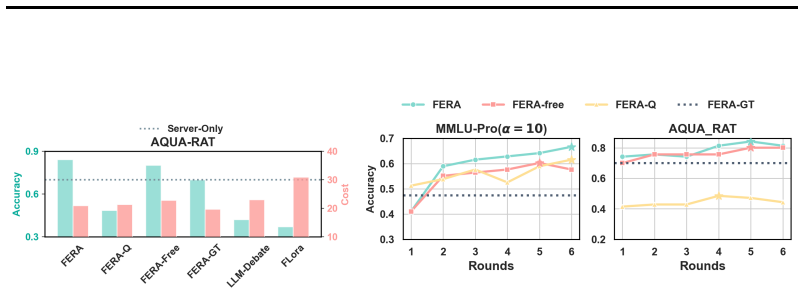
- The iterative protocol converges to progressively higher accuracy on multi-step reasoning tasks.
- Uncertainty-aware weighting accelerates convergence compared with uniform aggregation.
- Both server outputs and client-side reasoning improve across communication rounds.
- The method maintains lower communication and computational cost than federated training approaches.
- Performance exceeds both federated-training and training-free baselines on multiple reasoning benchmarks.
Where Pith is reading between the lines
- The same uncertainty-weighted revision loop could be tested on non-reasoning tasks such as code generation or factual question answering where private demonstrations are similarly distributed.
- If client uncertainty estimates remain reliable even when client models differ substantially in size or training data, the framework may scale to highly heterogeneous device fleets.
- The revision step inside UA-SCA suggests a general pattern for turning noisy distributed signals into usable context without centralizing raw examples.
Load-bearing premise
Client-generated uncertainty estimates are sufficiently reliable and query-dependent for the server to correctly weight and revise traces without ever seeing the private demonstrations or raw data.
What would settle it
Run the iterative protocol on a standard reasoning benchmark while replacing client uncertainty estimates with random or constant values; if accuracy fails to improve across rounds or converges to the same level as unweighted aggregation, the uncertainty-aware mechanism does not drive the claimed gains.
Figures
















read the original abstract
Large language models (LLMs) exhibit strong reasoning capabilities when guided by high-quality demonstrations, yet such data is often distributed across organizations that cannot centralize it due to regulatory, proprietary, or institutional constraints. We study federated reasoning, where a server improves multi-step reasoning by coordinating with heterogeneous clients holding private demonstrations, without centralized training or raw data sharing. The key challenge is that client reliability is query-dependent, while the server cannot inspect client data to determine which contributions are trustworthy. To address this, we propose Uncertainty-Aware Federated Reasoning (FERA), a training-free framework based on iterative server-client co-refinement. Across communication rounds, clients generate reasoning traces with lightweight uncertainty estimates, and the server synthesizes them into improved reasoning that is redistributed as context for the next round, progressively improving both server outputs and client-side reasoning. Within each round, Uncertainty-Aware Self-Critique Aggregation (UA-SCA) resolves conflicts among heterogeneous client traces through query-dependent trust weighting and structured cross-client verification. Rather than simply discarding low-quality traces, UA-SCA revises flawed reasoning steps to recover useful information. We provide theoretical guarantees showing that the proposed iterative protocol converges and that uncertainty-aware weighting accelerates convergence. Experiments on multiple reasoning benchmarks show that FERA consistently outperforms both federated training and training-free baselines, achieving progressively higher accuracy across rounds while maintaining communication and computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Uncertainty-Aware Federated Reasoning (FERA), a training-free iterative framework in which a server coordinates with heterogeneous clients holding private demonstrations to improve multi-step LLM reasoning. Clients produce reasoning traces with lightweight uncertainty estimates; the server applies Uncertainty-Aware Self-Critique Aggregation (UA-SCA) to weight traces query-dependently, revise flawed steps, and redistribute improved context for subsequent rounds. The manuscript claims theoretical convergence of the protocol together with acceleration from uncertainty-aware weighting, and reports progressive accuracy gains on reasoning benchmarks while preserving communication and computational efficiency.
Significance. If the central claims hold, FERA offers a practical route to collaborative reasoning across organizations that cannot share raw data, extending federated learning ideas to training-free, iterative refinement of reasoning traces. The combination of query-dependent trust weighting and structured revision (rather than simple discarding) is a distinctive technical contribution; the stated theoretical guarantees, if rigorously established, would further strengthen the work.
major comments (2)
- [§4] §4 (Theoretical Guarantees): The convergence proof and the claim that uncertainty-aware weighting accelerates convergence rest on the assumption that client-generated uncertainty estimates are sufficiently correlated with actual reasoning-step error rates. No empirical measurement or ablation isolating this correlation (e.g., uncertainty vs. ground-truth error on held-out traces) is reported, which is load-bearing for both the theoretical acceleration result and the practical utility of UA-SCA.
- [§5] §5 (Experiments): The reported progressive accuracy improvements across communication rounds are central to the empirical claim, yet the manuscript provides neither per-round standard deviations, the number of clients, nor details on how client heterogeneity was simulated. Without these, it is impossible to judge whether the gains are robust or could be explained by uniform aggregation alone.
minor comments (2)
- [§3.1] §3.1: The notation distinguishing UA-SCA from standard self-critique aggregation would be clearer if accompanied by a compact algorithmic box or numbered steps.
- [Figure 2] Figure 2: Axis labels and legend entries are too small for readability; consider enlarging or splitting into two panels.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical and empirical results. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Guarantees): The convergence proof and the claim that uncertainty-aware weighting accelerates convergence rest on the assumption that client-generated uncertainty estimates are sufficiently correlated with actual reasoning-step error rates. No empirical measurement or ablation isolating this correlation (e.g., uncertainty vs. ground-truth error on held-out traces) is reported, which is load-bearing for both the theoretical acceleration result and the practical utility of UA-SCA.
Authors: We agree that the acceleration claim in the convergence analysis relies on a positive correlation between the lightweight uncertainty estimates and per-step error rates. The formal convergence guarantee itself holds under the stated assumption without requiring a specific correlation strength, but the acceleration result does depend on it. While the end-to-end experiments show consistent gains from UA-SCA over uniform aggregation, we acknowledge that an explicit correlation analysis was not included. In the revision we will add an ablation that reports the correlation coefficient and a scatter plot of uncertainty scores versus ground-truth step errors on held-out traces from the reasoning benchmarks, thereby directly supporting the practical utility of the weighting mechanism. revision: yes
-
Referee: [§5] §5 (Experiments): The reported progressive accuracy improvements across communication rounds are central to the empirical claim, yet the manuscript provides neither per-round standard deviations, the number of clients, nor details on how client heterogeneity was simulated. Without these, it is impossible to judge whether the gains are robust or could be explained by uniform aggregation alone.
Authors: We appreciate this observation. The experimental section states the number of clients (K=5) and describes heterogeneity via partitioning of demonstration pools by domain and difficulty, but we agree that per-round standard deviations and a more explicit description of the simulation procedure are needed for full reproducibility and to isolate the effect of uncertainty-aware weighting. In the revised manuscript we will expand the experimental setup subsection with these details and add per-round standard deviations (computed over 5 random seeds) to all accuracy tables and figures. This will allow direct comparison against uniform aggregation baselines and demonstrate that the observed progressive gains exceed what would be expected from averaging alone. revision: yes
Circularity Check
No circularity; derivation introduces independent components and assumptions
full rationale
The paper defines FERA as a novel training-free iterative protocol with UA-SCA for query-dependent weighting and revision of client traces. Theoretical convergence guarantees are stated as holding under the assumption that client uncertainty estimates correlate with reasoning quality, but this is an explicit modeling assumption rather than a self-referential definition or fitted parameter renamed as prediction. No equations or steps reduce by construction to inputs; no self-citations are load-bearing for the core claims; the framework adds new mechanisms (iterative redistribution, structured verification) without renaming known results or smuggling ansatzes via prior work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Uncertainty-Aware Self-Critique Aggregation (UA-SCA)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We provide theoretical guarantees showing that the proposed iterative protocol converges and that uncertainty-aware weighting accelerates convergence.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UA-SCA assigns query-dependent trust weights based on token-level entropy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
X must be the option letter only (A/B/C/D/. . . ). Do not include the option text
-
[3]
Keep your entire response within{token limit}tokens. Question:{query} Answer:Let’s think step by step.{text} Server Query Initialization Prompt for MMLU-Pro & AQUA-RAT Standard QA Benchmark You are taking a multiple-choice question. Read the following question carefully and select the single best answer. Do not explain your reasoning. Output only the fina...
-
[4]
) with no punctuation or extra text
The output must be a single uppercase letter (A/B/C/D/. . . ) with no punctuation or extra text. 26
-
[5]
Do not include any explanation or content after the answer
-
[6]
Keep the response within{token limit}tokens. Question:{query} Answer: Server Query Initialization Prompt for GSM8K Reasoning Benchmark You are a knowledgeable assistant. For the following math question, briefly explain your reasoning (no more than{sentences limit}sentences), then end with the exact sentence: The answer is X. Rules:
-
[9]
Do not include any content after the final sentence
-
[10]
Question:{query} Answer: Let’s think step by step
Keep the entire response within{token limit}tokens. Question:{query} Answer: Let’s think step by step. D.2 Client Response Generation for Server Queries The framework of FERA is outlined in Algorithm 2. In Step 2, each client relabels its local data by constructing prompts that incorporate demonstrations selected from the server dataset. In Step 3, the cl...
-
[11]
Provide clear, concise, and logically coherent step-by-step reasoning (at most {sentences limit}sentences)
-
[12]
End with the exact sentence: The answer is (X)
-
[13]
); do not include the option text
X must be the option letter only (A, B, C, D, . . . ); do not include the option text
-
[15]
Examples: {examples} Question: {query} Answer:Let’s think step by step
Keep the complete response within{token limit}tokens. Examples: {examples} Question: {query} Answer:Let’s think step by step. 27 Client Prediction Prompt for MMLU-Pro & AQUA-RAT Standard QA Benchmark You are taking a multiple-choice question. Below are several example questions with their final answers. After reviewing these examples, you will be presente...
-
[16]
Read the question carefully and select the single best answer
-
[17]
Do not explain your reasoning
-
[18]
); do not include the option text
Output only the final answer choice letter (A, B, C, D, . . . ); do not include the option text
-
[19]
Do not include any additional content after the answer. Examples: {examples} Question: {query} Answer: Client Prediction Prompt for GSM8K Reasoning Benchmark You are tasked with answering math questions in this domain. Below are several example questions with their step-by-step reasoning and final answers. After reviewing these examples, you will be prese...
-
[20]
Provide clear, concise, and logically coherent step-by-step reasoning
-
[21]
End your response with the exact sentence: The answer is X
-
[22]
X must be a single numeric value (e.g., 12, -3/5, 7.25); no units or extra text
-
[23]
If X is a fraction, reduce it to simplest terms; if a decimal, use standard form without trailing zeros
-
[24]
Include no additional content after the final answer sentence
-
[25]
Examples: {examples} Question: {query} Answer:Let’s think step by step
Keep the complete response within{token limit}tokens. Examples: {examples} Question: {query} Answer:Let’s think step by step. D.3 Uncertainty-Aware Aggregration In the FERA framework, Uncertainty-Aware Aggregation is employed on the server side to combine responses from clients. The weights used in this aggregation are first computed ac- cording to Equati...
-
[26]
Synthesize the distinguishing features of these reasoning responses
-
[27]
Emphasize their reasoning methodology and structural organization
-
[28]
Identify common problem-solving paradigms across responses
-
[29]
Present your analysis within{token limit}tokens
-
[30]
Capture the essential cognitive characteristics of this cluster Your Analysis: SelfCritique for MMLU-Pro and AQUA-RAT Benchamrk You are improving a reasoning response by incorporating insights from conflicting reasoning approaches. Original Question: {question} Target Reasoning Response (to be improved): {target response} Alternative Approaches Summary: {...
-
[31]
Use the target reasoning response as your foundation
-
[32]
Extract valuable insights from the alternative approaches
-
[33]
Integrate these insights to create a more comprehensive response
-
[36]
Conclude with: ‘‘The answer is (X)’’ where X is the option letter only (A/B/C/D/...)
-
[37]
Exclude option text after the letter
-
[39]
Omit meta-commentary or explanatory analysis Improved Response: SelfCritique for GSM8K Benchamrk You are improving a reasoning response by incorporating insights from conflicting reasoning approaches. Original Question: {question} Target Reasoning Response (to be improved): {target response} 29 Alternative Approaches Summary: {alternatives formatted} Task...
-
[40]
Start with the target reasoning as your foundation
-
[41]
Identify useful insights from the conflicting summaries that could improve the reasoning
-
[42]
Integrate these insights to create a stronger, more comprehensive reasoning
-
[43]
Maintain logical consistency throughout
-
[44]
Present only the final improved reasoning
- [45]
-
[46]
Limit response to{token limit}tokens
-
[47]
No meta-commentary or analysis explanation Improved Response: Aggregation for MMLU-Pro and AQUA-RAT Benchmark You are synthesizing multiple reasoning responses to create a single, unified reasoning path. Context: You are given several reasoning responses to the same question, each from a different client. A final answer has been determined by majority vot...
-
[54]
Maintain professional and logical coherence throughout Merged Reasoning Response: Aggregation for MMLU-Pro and AQUA-RAT Benchmark You are synthesizing multiple reasoning responses to create a single, unified reasoning path. 30 Context: You are given several reasoning responses to the same question, each from a different client. Each response includes a co...
-
[59]
End with: ‘‘The answer is (X)’’ where X is the option letter only (A/B/C/D/...)
-
[60]
Do not include the option text after the letter
-
[61]
Maintain professional and logical coherence throughout Merged Reasoning Response: Aggregation for GSM8K Benchmark You are synthesizing multiple reasoning responses to create a single, unified solution path. Context: You are given several reasoning responses to the same question, each from a different client. Each response includes a confidence score (high...
-
[62]
Synthesize the reasoning leading to the final answer
-
[63]
Give greater weight to reasoning from higher-confidence responses
-
[64]
Avoid unnecessary repetition or irrelevant details
-
[65]
Keep the ENTIRE response (reasoning + final answer) within{token limit}tokens
-
[66]
End with the exact sentence: ‘‘The answer is X.’’
-
[67]
X must be a single numeric value (e.g., 12, -3/5, 7.25)
-
[68]
No units or extra text after the answer Merged Reasoning Response: D.4 FERA Variants FERA-GT.To evaluate the effectiveness of FERA, we compare it with a simplified baseline, FERA-GT. In this baseline, the server issues a query to clients, who independently retrieve the top-C question–answer pairs using the MMR demonstration strategy. These retrieved pairs...
work page 2023
-
[69]
to both the original server prompts and the client-generated reasoning response. Following the methodology of Edemacu & Wu (2025), we measured how often response contained personal identifiers not already present in the original prompts. The results, summarized in Table 2, show that only a small fraction of response included such identifiers, indicating t...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.