Is Data Shapley Not Better than Random in Data Selection? Ask NASH
Pith reviewed 2026-05-13 05:55 UTC · model grok-4.3
The pith
NASH improves data selection by decomposing the utility function into Shapley-informative components and aggregating them non-linearly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NASH decomposes the target utility function into simpler Shapley-informative component functions and selects data by optimizing an objective that aggregates these components non-linearly, substantially boosting the effectiveness of Shapley or semivalue-based data selection.
What carries the argument
The NASH framework: utility decomposition into Shapley-informative components followed by non-linear aggregation for subset selection.
If this is right
- Shapley-based selection produces consistently higher-quality subsets across different utility functions.
- The added runtime cost remains small enough for large-scale data selection tasks.
- The same decomposition-plus-aggregation pattern extends to other semivalues.
- Models trained on the selected subsets reach higher performance with less data.
Where Pith is reading between the lines
- The decomposition idea may apply to other interaction-aware valuation methods beyond semivalues.
- It could clarify which utility functions naturally admit Shapley-informative breakdowns.
- The pattern might transfer to multi-objective settings where each component captures a different performance aspect.
Load-bearing premise
The target utility can be decomposed into simpler component functions that are each Shapley-informative, and their non-linear aggregation will consistently outperform direct Shapley or random selection.
What would settle it
Train models on subsets chosen by NASH versus direct top-m Shapley versus random on the same dataset and measure whether NASH-selected subsets produce statistically lower or equal validation accuracy.
Figures











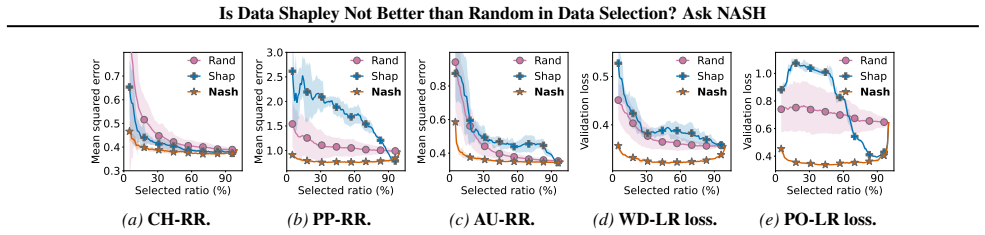
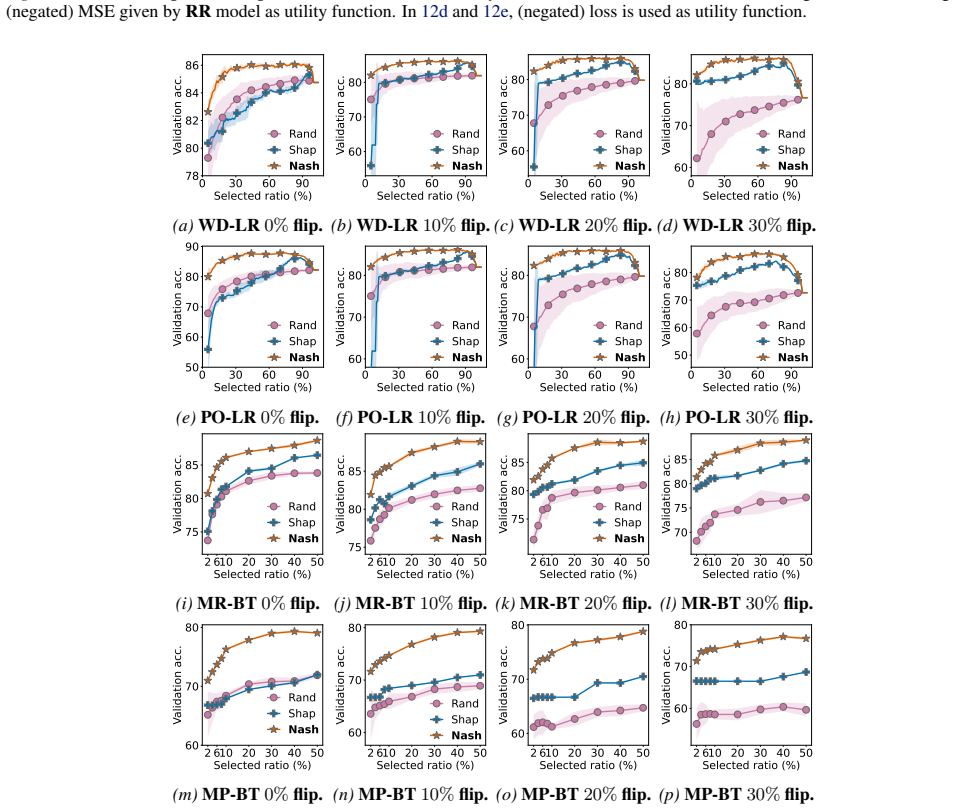

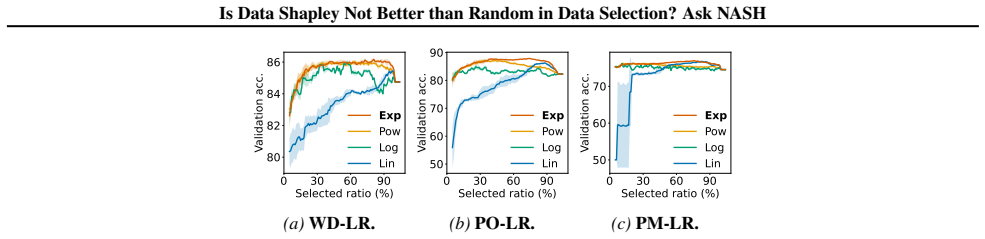


read the original abstract
Data selection studies the problem of identifying high-quality subsets of training data. While some existing works have considered selecting the subset of data with top-$m$ Data Shapley or other semivalues as they account for the interaction among every subset of data, other works argue that Data Shapley can sometimes perform ineffectively in practice and select subsets that are no better than random. This raises the questions: (I) Are there certain "Shapley-informative" settings where Data Shapley consistently works well? (II) Can we strategically utilize these settings to select high-quality subsets consistently and efficiently? In this paper, we propose a novel data selection framework, NASH (Non-linear Aggregation of SHapley-informative components), which (I) decomposes the target utility function (e.g., validation accuracy) into simpler, Shapley-informative component functions, and selects data by optimizing an objective that (II) aggregates these components non-linearly. We demonstrate that NASH substantially boosts the effectiveness of Shapley/semivalue-based data selection with minimal additional runtime cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Data Shapley and other semivalues can sometimes perform no better than random for data selection. It identifies 'Shapley-informative' settings where they work well and proposes the NASH framework, which decomposes the target utility function (such as validation accuracy) into simpler Shapley-informative component functions and selects data subsets by optimizing a non-linear aggregation of those components. The authors state that NASH substantially improves the effectiveness of Shapley/semivalue-based selection at minimal extra runtime cost.
Significance. If the empirical gains are robust, this work could meaningfully advance practical data selection in machine learning by providing a targeted way to overcome the known failure modes of raw Shapley values through decomposition and non-linear aggregation. The low additional runtime cost is a practical strength, and the algorithmic construction avoids circularity or parameter-fitting issues. It directly engages with limitations in the semivalue literature and could influence data curation pipelines if the decomposition strategy generalizes.
minor comments (2)
- The abstract states performance claims without referencing specific datasets, tasks, or quantitative improvements; adding one sentence on experimental scope would improve readability.
- Clarify the precise definition and identification procedure for 'Shapley-informative' component functions in the main text, as this is central to the framework's reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our manuscript and the recommendation for minor revision. We appreciate the recognition that NASH provides a targeted approach to overcome known limitations of semivalue-based data selection through decomposition and non-linear aggregation, while maintaining low additional runtime cost.
Circularity Check
No significant circularity in NASH framework
full rationale
The paper presents NASH as an algorithmic construction: it decomposes a target utility (e.g., validation accuracy) into simpler Shapley-informative component functions and then aggregates them non-linearly to select data. No load-bearing derivation, equation, or prediction is shown that reduces by construction to its own inputs, fitted parameters, or self-citations. The abstract and description frame the contribution as an empirical algorithmic improvement over raw Shapley selection, with no self-definitional steps, uniqueness theorems imported from the authors, or ansatzes smuggled via citation. The approach directly addresses a known practical failure mode without circular reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NASH objective: max_M sum_v FT(ûv(M)) with FT concave (exponential/power law) and greedy selection on Shapley components uv
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Shapley-informativeness defined via Pr[|u(M) - f(û(M))| ≤ ϵ] ≥ 1-δ under Consistent Player assumption
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
International Game Theory Review , volume=
A Note on Regular Semivalues , author=. International Game Theory Review , volume=. 2000 , publisher=
work page 2000
-
[4]
Submodular meets spectral: Greedy algorithms for subset selection, sparse approximation and dictionary selection , author=. arXiv preprint arXiv:1102.3975 , year=
-
[5]
Journal of Parallel and Distributed Computing , volume=
Vehicle classification in distributed sensor networks , author=. Journal of Parallel and Distributed Computing , volume=. 2004 , publisher=
work page 2004
-
[6]
Mathematics of Operations Research , volume=
Value theory without efficiency , author=. Mathematics of Operations Research , volume=. 1981 , publisher=
work page 1981
- [7]
-
[8]
An analysis of approximations for maximizing submodular set functions—
Nemhauser, George L and Wolsey, Laurence A and Fisher, Marshall L , journal=. An analysis of approximations for maximizing submodular set functions—. 1978 , publisher=
work page 1978
-
[9]
SIAM Journal on Optimization , volume=
Convex approximations of chance constrained programs , author=. SIAM Journal on Optimization , volume=. 2007 , publisher=
work page 2007
- [10]
-
[11]
Shapley, L. S. , journal=. A Value for
-
[12]
Data valuation for medical imaging using
Tang, Siyi and Ghorbani, Amirata and Yamashita, Rikiya and Rehman, Sameer and Dunnmon, Jared A and Zou, James and Rubin, Daniel L , journal=. Data valuation for medical imaging using. 2021 , publisher=
work page 2021
-
[13]
DeRDaVa: Deletion-Robust Data Valuation for Machine Learning , volume=. Proc. AAAI , author=. 2024 , month=. doi:10.1609/aaai.v38i14.29462 , abstractNote=
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
The shape of learning curves: a review , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
work page 2022
-
[15]
2015 IEEE symposium series on computational intelligence , pages=
Calibrating probability with undersampling for unbalanced classification , author=. 2015 IEEE symposium series on computational intelligence , pages=. 2015 , organization=
work page 2015
-
[16]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=
-
[17]
Proceedings of the third international workshop on paraphrasing (IWP2005) , year=
Automatically constructing a corpus of sentential paraphrases , author=. Proceedings of the third international workshop on paraphrasing (IWP2005) , year=
-
[18]
Ghorbani, Amirata and Zou, James , booktitle=. 2019 , organization=
work page 2019
-
[19]
Most influential subset selection: Challenges, promises, and beyond , author=. Proc. NeurIPS , volume=
-
[20]
Towards efficient data valuation based on the
Jia, Ruoxi and Dao, David and Wang, Boxin and Hubis, Frances Ann and Hynes, Nick and G. Towards efficient data valuation based on the. Proc. AISTATS , pages=. 2019 , organization=
work page 2019
-
[21]
Proceedings of the VLDB Endowment , volume=
Efficient task-specific data valuation for nearest neighbor algorithms , author=. Proceedings of the VLDB Endowment , volume=. 2019 , publisher=
work page 2019
-
[22]
Jiang, Kevin and Liang, Weixin and Zou, James Y and Kwon, Yongchan , booktitle=
-
[23]
Understanding black-box predictions via influence functions , author=. Proc. ICML , pages=. 2017 , organization=
work page 2017
-
[24]
Kwon, Yongchan and Zou, James , booktitle=. 2022 , organization=
work page 2022
-
[25]
Faster approximation of probabilistic and distributional values via least squares , author=. Proc. ICLR , year=
-
[26]
One Sample Fits All: Approximating All Probabilistic Values Simultaneously and Efficiently , author=. Proc. NeurIPS , year=
-
[27]
Coresets for data-efficient training of machine learning models , author=. Proc. ICML , pages=. 2020 , organization=
work page 2020
-
[28]
Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales , author=. Proc. ACL , pages=
-
[29]
Estimating Training Data Influence by Tracing Gradient Descent , author=. Proc. NeurIPS , volume=
-
[30]
A generalized representer theorem , author=. COLT , pages=. 2001 , organization=
work page 2001
-
[31]
Data Valuation in Machine Learning: "Ingredients", Strategies, and Open Challenges , author=. Proc. IJCAI , pages=
-
[32]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
work page 2013
-
[33]
2019 18th European Control Conference (ECC) , pages=
Performance guarantees for greedy maximization of non-submodular controllability metrics , author=. 2019 18th European Control Conference (ECC) , pages=. 2019 , organization=
work page 2019
-
[34]
Subset Selection in Machine Learning: From Theory to Applications , author =. Proc. ICML 2021 Workshop on SubSetML , year =
work page 2021
-
[35]
Sundararajan, Mukund and Dhamdhere, Kedar and Agarwal, Ashish , booktitle=. The. 2020 , organization=
work page 2020
-
[36]
Wang, Jiachen T and Jia, Ruoxi , booktitle=. 2023 , organization=
work page 2023
-
[37]
Wang, Jiachen T and Yang, Tianji and Zou, James and Kwon, Yongchan and Jia, Ruoxi , booktitle=. Rethinking. 2024 , organization=
work page 2024
-
[38]
Helpful or Harmful Data? Fine-tuning-free
Wang, Jingtan and Lin, Xiaoqiang and Qiao, Rui and Foo, Chuan-Sheng and Low, Bryan Kian Hsiang , booktitle=. Helpful or Harmful Data? Fine-tuning-free. 2024 , organization=
work page 2024
-
[39]
Wang, Jiachen T and Mittal, Prateek and Song, Dawn and Jia, Ruoxi , booktitle=
-
[40]
Submodularity in data subset selection and active learning , author=. Proc. ICML , pages=. 2015 , organization=
work page 2015
-
[41]
Representer point selection for explaining deep neural networks , author=. Proc. NeurIPS , volume=
-
[42]
A Survey on Data Selection for Language Models , author=. 2024 , eprint=
work page 2024
-
[43]
Unifying and Optimizing Data Values for Selection via Sequential-Decision-Making , author=. 2025 , eprint=
work page 2025
-
[44]
Provably Adaptive Linear Approximation for the Shapley Value and Beyond , author=. 2026 , eprint=
work page 2026
-
[45]
Wang and Yuqing Zhu and Yu-Xiang Wang and Ruoxi Jia and Prateek Mittal , year=
Jiachen T. Wang and Yuqing Zhu and Yu-Xiang Wang and Ruoxi Jia and Prateek Mittal , year=. Threshold. 2308.15709 , archivePrefix=
-
[46]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advancing Data Selection for Foundation Models: From Heuristics to Principled Methods , author=. 2024 , booktitle=
work page 2024
-
[48]
What is percolation? , author=. Percolation , pages=. 2012 , publisher=
work page 2012
-
[49]
Vanschoren, Joaquin. Wind
-
[50]
Vanschoren, Joaquin. Pol
-
[51]
Vanschoren, Joaquin. CPU
- [52]
- [53]
- [54]
- [55]
- [56]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.