Training-Free Cultural Alignment of Large Language Models via Persona Disagreement
Pith reviewed 2026-05-20 22:15 UTC · model grok-4.3
The pith
Disagreement among survey-grounded persona agents steers black-box LLMs toward cultural alignment at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
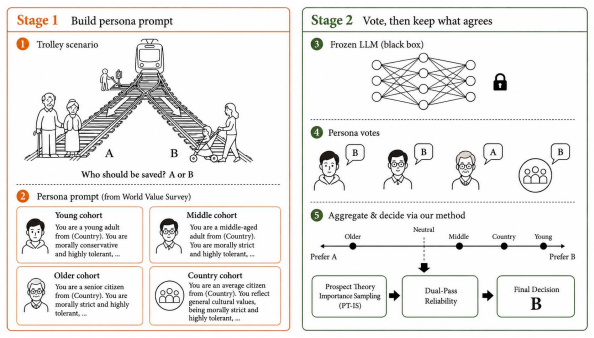
The paper establishes that within-country sociodemographic disagreement, not consensus, is the primary steering signal for cultural alignment. DISCA instantiates each country as a panel of World-Values-Survey-grounded persona agents and converts their disagreement into a bounded, loss-averse logit correction. Across 20 countries and 7 open-weight backbones ranging from 2B to 70B parameters, this reduces cultural misalignment on MultiTP by 10-24% on the six backbones of 3.8B parameters or larger and by 2-7% on open-ended scenarios, all without changing any model weights.
What carries the argument
DISCA, the mechanism that extracts a bounded logit correction from disagreement among a panel of World-Values-Survey-grounded persona agents to steer model outputs.
If this is right
- Cultural alignment becomes possible for commercial black-box APIs that expose only text outputs.
- No per-country preference datasets or fine-tuning budgets are required.
- The same procedure works across model scales from 3.8B upward and across 20 countries.
- Open-ended generation tasks receive measurable alignment gains of 2-7%.
- Inference-time calibration offers a scalable route to address the long tail of global moral preferences.
Where Pith is reading between the lines
- The disagreement signal could be reused to align models on other value dimensions such as political or ethical stances.
- Real-time location or context cues could trigger country-specific persona panels inside deployed assistants.
- The approach might reduce the engineering burden of maintaining separate regional model variants.
- Direct API experiments on closed-source models would test whether the black-box gains observed on open weights generalize.
Load-bearing premise
Disagreement among World-Values-Survey-grounded persona agents constitutes a reliable, primary steering signal that can be converted into an effective bounded logit correction for cultural alignment in black-box models.
What would settle it
Apply DISCA to a held-out cultural benchmark unrelated to the World Values Survey and measure whether misalignment scores on that benchmark fall relative to the unadjusted baseline.
Figures




read the original abstract
Large language models increasingly mediate decisions that turn on moral judgement, yet a growing body of evidence shows that their implicit preferences are not culturally neutral. Existing cultural alignment methods either require per-country preference data and fine-tuning budgets or assume white-box access to model internals that commercial APIs do not expose. In this work, we focus on this realistic black-box, public-data-only regime and observe that within-country sociodemographic disagreement, not consensus, is the primary steering signal. We introduce DISCA (Disagreement-Informed Steering for Cultural Alignment), an inference-time method that instantiates each country as a panel of World-Values-Survey-grounded persona agents and converts their disagreement into a bounded, loss-averse logit correction. Across 20 countries and 7 open-weight backbones (2B--70B), DISCA reduces cultural misalignment on MultiTP by 10--24% on the six backbones >=3.8B, and 2--7% on open-ended scenarios, without changing any weights. Our results suggest that inference-time calibration is a scalable alternative to fine-tuning for serving the long tail of global moral preferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that within-country sociodemographic disagreement (rather than consensus) supplies the primary steering signal for cultural alignment. It introduces DISCA, an inference-time black-box method that instantiates each of 20 countries as a panel of World-Values-Survey-grounded personas, converts their disagreement into a bounded loss-averse logit correction, and reports 10-24% reduction in cultural misalignment on the MultiTP benchmark for the six backbones >=3.8B (plus 2-7% on open-ended scenarios) across seven open-weight models from 2B to 70B, all without weight updates or per-country fine-tuning data.
Significance. If the central claim holds after the required controls, the work would demonstrate a practical, training-free route to culturally adaptive LLM behavior that relies only on public survey data and black-box access. This is potentially significant for serving long-tail global preferences at inference time and for shifting emphasis from consensus-based to disagreement-based steering signals in alignment research.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): the claim that 'within-country sociodemographic disagreement, not consensus, is the primary steering signal' is load-bearing for the entire contribution, yet the manuscript provides no ablation that isolates the disagreement-derived logit correction from a plain average or consensus logit over the identical persona panel. Without such a control (or a non-disagreement baseline), the reported 10-24% MultiTP gains could be explained by multi-persona prompting alone.
- [§4] §4 (experiments): baseline construction, statistical significance tests, and prompt-sensitivity controls are not described for the MultiTP results across 20 countries and seven backbones. These details are required to establish that the percentage improvements are robust rather than artifacts of prompt formulation or evaluation protocol.
minor comments (2)
- [§3] The precise mathematical form of the bounded logit correction and the loss-aversion factor should be stated explicitly (including any free parameters) rather than summarized at a high level.
- Figure or table captions should clarify the exact persona count per country and the number of disagreement samples used to compute the correction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and describe the revisions we will incorporate to strengthen the work.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the claim that 'within-country sociodemographic disagreement, not consensus, is the primary steering signal' is load-bearing for the entire contribution, yet the manuscript provides no ablation that isolates the disagreement-derived logit correction from a plain average or consensus logit over the identical persona panel. Without such a control (or a non-disagreement baseline), the reported 10-24% MultiTP gains could be explained by multi-persona prompting alone.
Authors: We agree that an explicit ablation isolating the disagreement-based logit correction from a consensus or average logit over the same persona panel is necessary to substantiate the central claim. The current manuscript motivates the disagreement signal from the World Values Survey data patterns but does not include this control. In the revised version we will add a direct comparison: DISCA versus a baseline that applies the mean logit across the identical persona panel without the bounded disagreement adjustment. This will quantify the incremental benefit attributable to disagreement modeling rather than multi-persona prompting alone. revision: yes
-
Referee: [§4] §4 (experiments): baseline construction, statistical significance tests, and prompt-sensitivity controls are not described for the MultiTP results across 20 countries and seven backbones. These details are required to establish that the percentage improvements are robust rather than artifacts of prompt formulation or evaluation protocol.
Authors: We acknowledge that the experimental section would benefit from additional methodological transparency. In the revision we will expand §4 to specify: (i) the exact construction of all baselines, including how the no-alignment and multi-persona controls were prompted and decoded; (ii) statistical significance testing (paired tests across countries with appropriate multiple-comparison correction); and (iii) prompt-sensitivity results obtained by re-running the evaluation with two additional prompt templates and reporting the range of observed improvements. These additions will demonstrate that the 10–24 % gains are not artifacts of a single prompt or evaluation choice. revision: yes
Circularity Check
No circularity: method grounded in external WVS data with independent personas
full rationale
The paper defines DISCA using World Values Survey-grounded personas whose disagreement is converted into a logit correction at inference time. This steering signal is constructed from external survey data and sociodemographic categories chosen independently of any target LLM outputs or fitted parameters. No equations or steps reduce the claimed misalignment reduction to a self-definition, a renamed fit, or a self-citation chain; the reported gains are presented as empirical outcomes of the proposed procedure rather than tautological consequences of its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- logit correction bounds and loss-aversion factor
axioms (1)
- domain assumption Within-country sociodemographic disagreement, not consensus, is the primary steering signal for cultural alignment.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DISCA converts their disagreement into a bounded, loss-averse logit correction whose magnitude is set by the panel’s variance
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (Variance-aware shrinkage)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. S. Z. b. Ahmad and K. Takemoto. Large-scale moral machine experiment on large language models. PLOS ONE, 20 0 (5): 0 e0322776, 2025. doi:10.1371/journal.pone.0322776. URL https://doi.org/10.1371/journal.pone.0322776
-
[2]
A. Arditi, O. Obeso, A. Syed, D. Paleka, N. Panickssery, W. Gurnee, and N. Nanda. Refusal in language models is mediated by a single direction. In Advances in Neural Information Processing Systems, volume 37, pages 136037--136083, 2025. doi:10.52202/079017-4322. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/f545448535dfde4f9786555403ab7c4...
-
[3]
M. Atari, M. J. Xue, P. S. Park, D. E. Blasi, and J. Henrich. Which humans? PsyArXiv preprint, 2023. doi:10.31234/osf.io/5b26t. https://osf.io/preprints/psyarxiv/5b26t
-
[4]
E. Awad, S. Dsouza, R. Kim, J. Schulz, J. Henrich, A. Shariff, J.-F. Bonnefon, and I. Rahwan. The moral machine experiment. Nature, 563 0 (7729): 0 59--64, 2018
work page 2018
-
[5]
S. Chand, F. Baca, and E. Ferrara. No free lunch in language model bias mitigation? T argeted bias reduction can exacerbate unmitigated LLM biases. AI, 7 0 (1): 0 24, 2026. doi:10.3390/ai7010024
-
[6]
R. Chen, W. Chai, Z. Yang, X. Zhang, Z. Wang, T. Quek, J. T. Zhou, S. Poria, and Z. Liu. D iff PO : Diffusion-styled preference optimization for inference time alignment of large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18910--18925, Vienna, Austria, July 202...
-
[7]
Y. Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 11733--11763. PMLR, 2024. URL https://proceedings.mlr.press/v235/du24e.html. arX...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
KTO: Model Alignment as Prospect Theoretic Optimization
K. Ethayarajh, W. Xu, N. Muennighoff, D. Jurafsky, and D. Kiela. KTO : Model alignment as prospect theoretic optimization. In International Conference on Machine Learning, 2024. arXiv:2402.01306
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Y. Gal and Z. Ghahramani. Dropout as a B ayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 1050--1059. PMLR, 2016. URL https://proceedings.mlr.press/v48/gal16.html
work page 2016
- [10]
-
[11]
C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1321--1330, 2017. URL https://proceedings.mlr.press/v70/guo17a.html. arXiv:1706.04599
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
C. Haerpfer, R. Inglehart, A. Moreno, C. Welzel, K. Kizilova, J. Diez-Medrano, M. Lagos, P. Norris, E. Ponarin, and B. Puranen. World Values Survey : Round seven -- country-pooled datafile. Madrid, Spain & Vienna, Austria: JD Systems Institute & WVSA Secretariat, 2020. https://doi.org/10.14281/18241.20
-
[13]
J. Henrich, S. J. Heine, and A. Norenzayan. The weirdest people in the world? Behavioral and Brain Sciences, 33 0 (2-3): 0 61--83, 2010. doi:10.1017/S0140525X0999152X. URL https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/abs/weirdest-people-inthe-world/BF84F7517D56AFF7B7EB58411A554C17
-
[14]
R. Inglehart and C. Welzel. Modernization, Cultural Change, and Democracy: The Human Development Sequence. Cambridge University Press, 2005. URL https://social.hse.ru/data/2012/11/03/1249193128/inglehart_welzel.pdf
work page 2005
-
[15]
Z. Jin, M. Kleiman-Weiner, G. Piatti, S. Levine, J. Liu, F. G. Adauto, F. Ortu, A. Strausz, M. Sachan, R. Mihalcea, Y. Choi, and B. Sch \"o lkopf. Language Model Alignment in Multilingual Trolley Problems . In International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=VEqPDZIDAh. arXiv:2407.02273
-
[16]
D. Kahneman and A. Tversky. Prospect theory: An analysis of decision under risk. Econometrica, 47 0 (2): 0 263--291, 1979
work page 1979
-
[17]
E. Kalai and M. Smorodinsky. Other solutions to N ash's bargaining problem. Econometrica, 43 0 (3): 0 513--518, 1975. doi:10.2307/1914280
-
[18]
A. Khan, S. Casper, and D. Hadfield-Menell. Randomness, not representation: The unreliability of evaluating cultural alignment in LLMs . In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 2151--2165. Association for Computing Machinery, 2025. doi:10.1145/3715275.3732147. URL https://dl.acm.org/doi/10.1145/371527...
-
[19]
Args: Alignment as reward-guided search
M. Khanov, J. Burapacheep, and Y. Li. ARGS : Alignment as reward-guided search. In International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=shgx0eqdw6. arXiv:2402.01694
-
[20]
J. Kim, J. Kwon, L. F. Vecchietti, A. Oh, and M. Cha. Exploring persona-dependent llm alignment for the moral machine experiment. arXiv preprint arXiv:2504.10886, 2025. doi:10.48550/arXiv.2504.10886. URL https://arxiv.org/abs/2504.10886
-
[21]
H. R. Kirk, A. Whitefield, P. R \"o ttger, A. Bean, K. Margatina, J. Ciro, R. Mosquera, M. Bartolo, A. Williams, H. He, B. Vidgen, and S. A. Hale. The PRISM alignment dataset: What participatory, representative and individualised human feedback reveals about the subjective and multicultural alignment of large language models. arXiv preprint arXiv:2404.160...
- [22]
-
[23]
S. Levine. Reinforcement learning and control as probabilistic inference: T utorial and review. arXiv preprint arXiv:1805.00909, 2018. doi:10.48550/arXiv.1805.00909. URL https://arxiv.org/abs/1805.00909
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.00909 2018
-
[24]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.-N
T. Liang, Z. He, W. Jiao, X. Wang, Y. Wang, R. Wang, Y. Yang, S. Shi, and Z. Tu. Encouraging divergent thinking in large language models through multi-agent debate. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17889--17904. Association for Computational Linguistics, 2024. doi:10.18653/v1/2024.emnlp-main....
-
[25]
P. C. Mahalanobis. Recent experiments in statistical sampling in the I ndian S tatistical I nstitute. Journal of the Royal Statistical Society, 109 0 (4): 0 325--378, 1946
work page 1946
-
[26]
P. J. McCarthy. Pseudo-replication: Half samples. Review of the International Statistical Institute, 37 0 (3): 0 239--264, 1969
work page 1969
-
[27]
Controlled decoding from language models
S. Mudgal, J. Lee, H. Ganapathy, Y. Li, T. Wang, Y. Huang, Z. Chen, H.-T. Cheng, M. Collins, T. Strohman, J. Chen, A. Beutel, and A. Beirami. Controlled decoding from language models. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 36486--36503. PMLR, 2024. URL https://...
-
[28]
BLEnD: A Benchmark for LLMs on Ev- eryday Knowledge in Diverse Cultures and Languages,
J. Myung, N. Lee, Y. Zhou, J. Jin, R. A. Putri, D. Antypas, H. Borkakoty, E. Kim, C. Perez-Almendros, A. A. Ayele, et al. BLEnD : A benchmark for LLMs on everyday knowledge in diverse cultures and languages. In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024. doi:10.48550/arXiv.2406.09948. URL https://openr...
-
[29]
J. F. Nash. The bargaining problem. Econometrica, 18 0 (2): 0 155--162, 1950. doi:10.2307/1907266
-
[30]
M. Rudelson and R. Vershynin. Hanson-- W right inequality and sub- G aussian concentration. Electronic Communications in Probability, 18 0 (82): 0 1--9, 2013. doi:10.1214/ECP.v18-2865
-
[31]
M. J. Ryan, W. Held, and D. Yang. Unintended impacts of LLM alignment on global representation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16121--16140, Bangkok, Thailand, Aug. 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.acl-long.853. URL https://aclan...
-
[32]
S. Santurkar, E. Durmus, F. Ladhak, C. Lee, P. Liang, and T. Hashimoto. Whose opinions do language models reflect? arXiv preprint arXiv:2303.17548, 2023
-
[33]
A Roadmap to Pluralistic Alignment
T. Sorensen, J. Moore, J. Fisher, M. Gordon, N. Mireshghallah, C. M. Rytting, A. Ye, L. Jiang, X. Lu, N. Dziri, et al. A roadmap to pluralistic alignment. arXiv preprint arXiv:2402.05070, 2024. doi:10.48550/arXiv.2402.05070. URL https://arxiv.org/abs/2402.05070
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.05070 2024
-
[34]
K. Takemoto. The moral machine experiment on large language models. Royal Society Open Science, 11 0 (2): 0 231393, 2024. doi:10.1098/rsos.231393. URL https://royalsocietypublishing.org/rsos/article/11/2/231393/92489
-
[35]
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248, 2024. doi:10.48550/arXiv.2308.10248. URL https://arxiv.org/abs/2308.10248
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248 2024
-
[36]
A. Tversky and D. Kahneman. Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5 0 (4): 0 297--323, 1992. doi:10.1007/BF00122574. URL https://link.springer.com/article/10.1007/BF00122574
-
[37]
X. Wang, J. Wei, D. Schuurmans, Q. V. Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations (ICLR), 2023. doi:10.48550/arXiv.2203.11171. URL https://openreview.net/forum?id=1PL1NIMMrw. arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2023
-
[38]
G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou. Information-theoretic model predictive control: Theory and applications to autonomous driving. IEEE Transactions on Robotics, 34 0 (6): 0 1603--1622, 2018. doi:10.1109/TRO.2018.2865891. URL https://ieeexplore.ieee.org/abstract/document/8558663
-
[39]
K. M. Wolter. Introduction to Variance Estimation. Springer, 2nd edition, 2007
work page 2007
-
[40]
J. Yao, X. Yi, J. Wang, Z. Dou, and X. Xie. CAReDiO : Cultural alignment of LLM via representativeness and distinctiveness guided data optimization. arXiv preprint arXiv:2504.08820, 2025. doi:10.48550/arXiv.2504.08820. URL https://arxiv.org/abs/2504.08820
-
[41]
A. Zewail, A. Figueroa, J. Graham, and M. Atari. Moral stereotyping in large language models. Proceedings of the National Academy of Sciences, 123 0 (10): 0 e2519941123, 2026. doi:10.1073/pnas.2519941123. URL https://www.pnas.org/doi/10.1073/pnas.2519941123
- [42]
-
[43]
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, et al. Representation engineering: A top-down approach to AI transparency. arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.