Recognition: 2 theorem links
· Lean TheoremSlicing and Dicing: Configuring Optimal Mixtures of Experts
Pith reviewed 2026-05-13 07:32 UTC · model grok-4.3
The pith
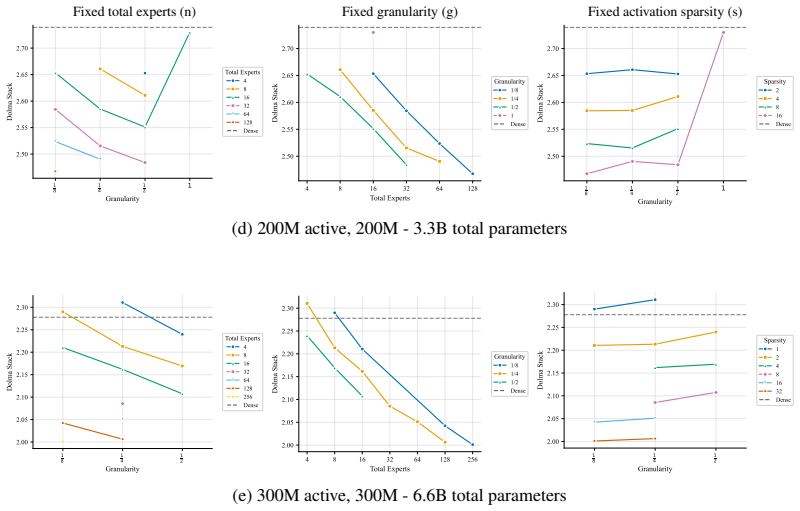
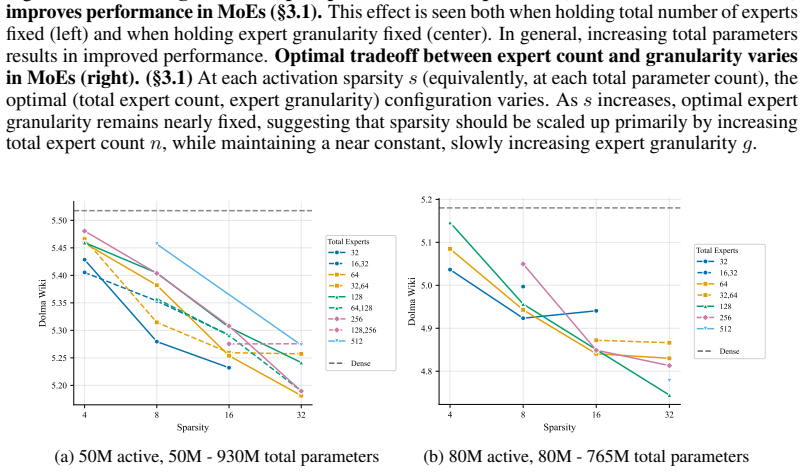
Increasing total MoE parameters improves performance at every active-parameter scale studied.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
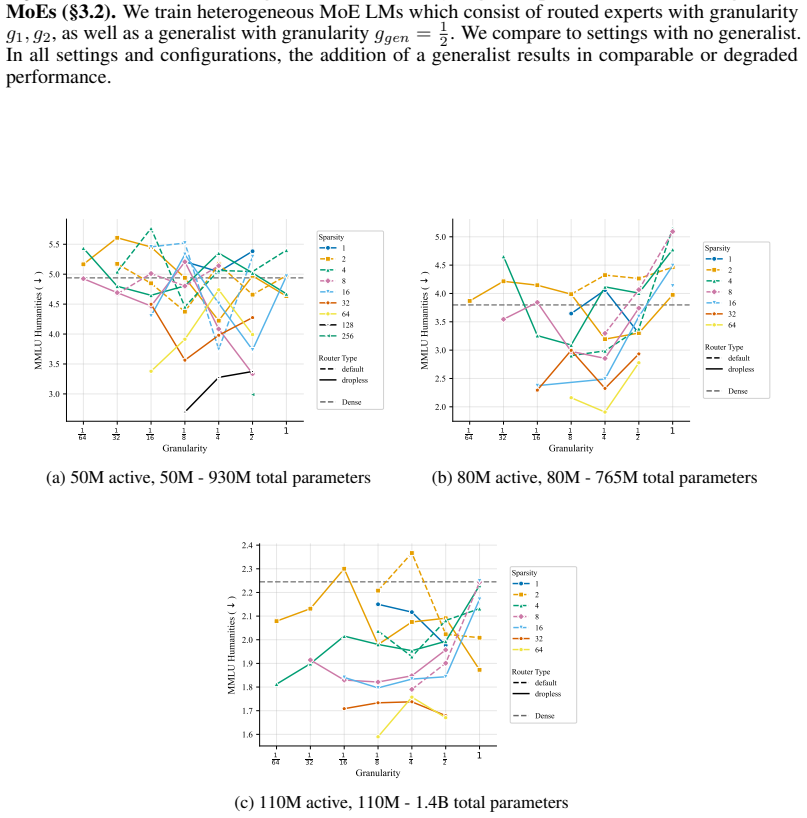
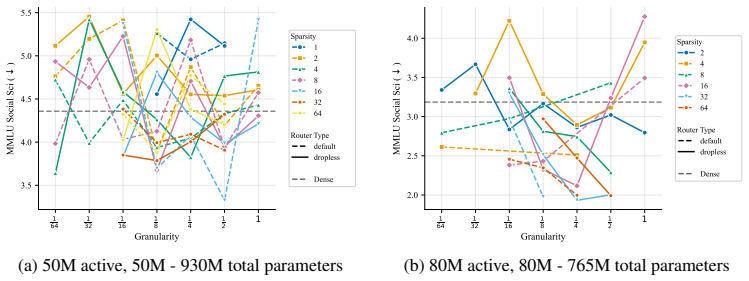
Core claim
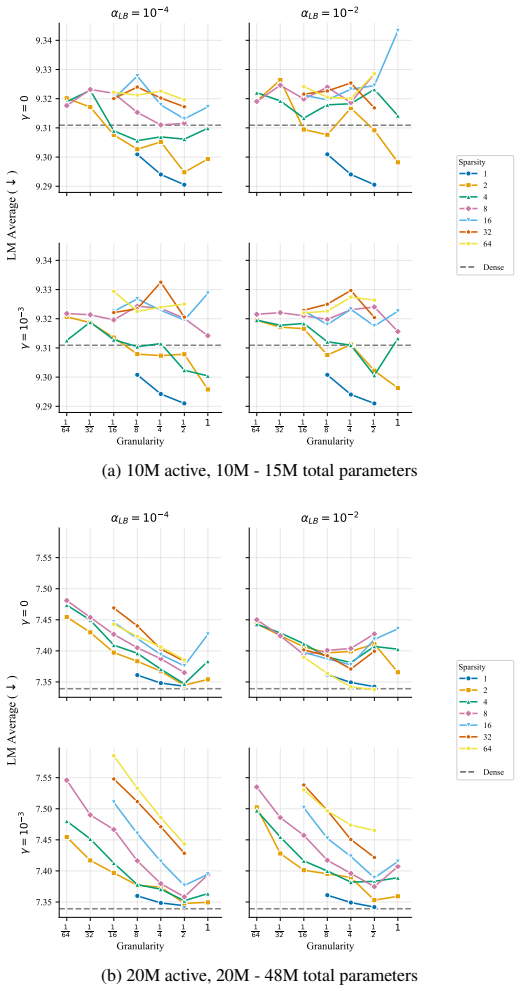
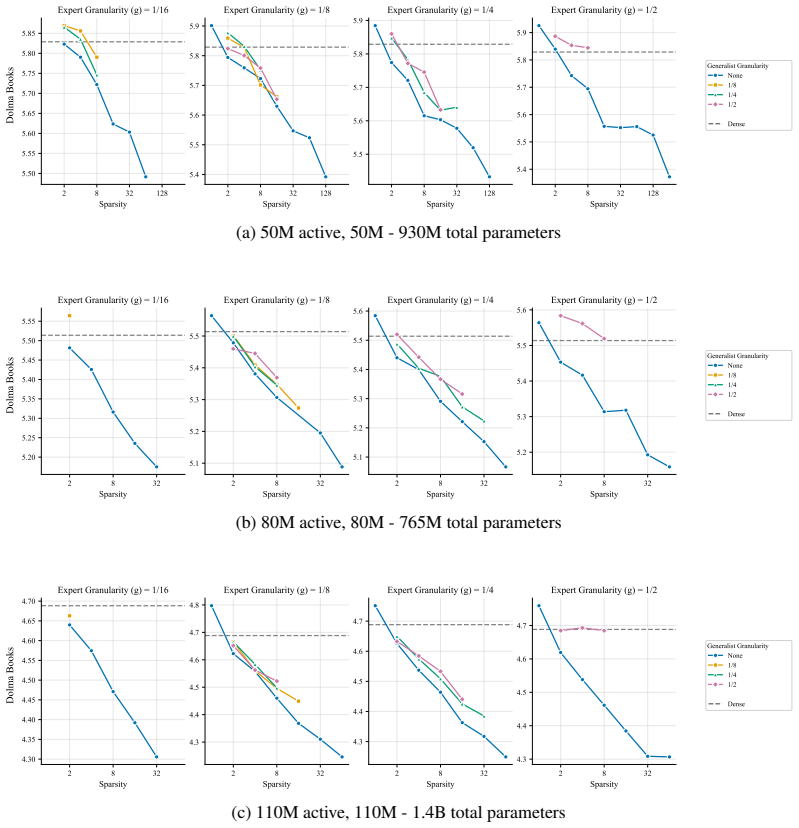
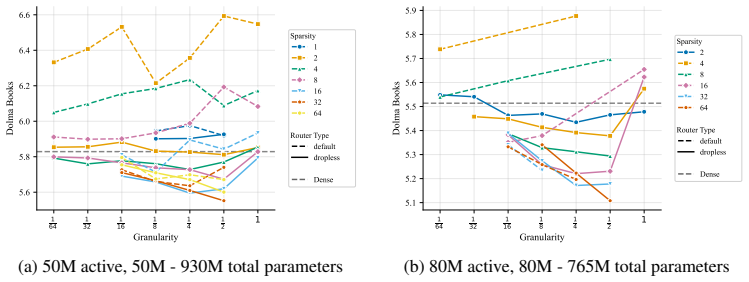
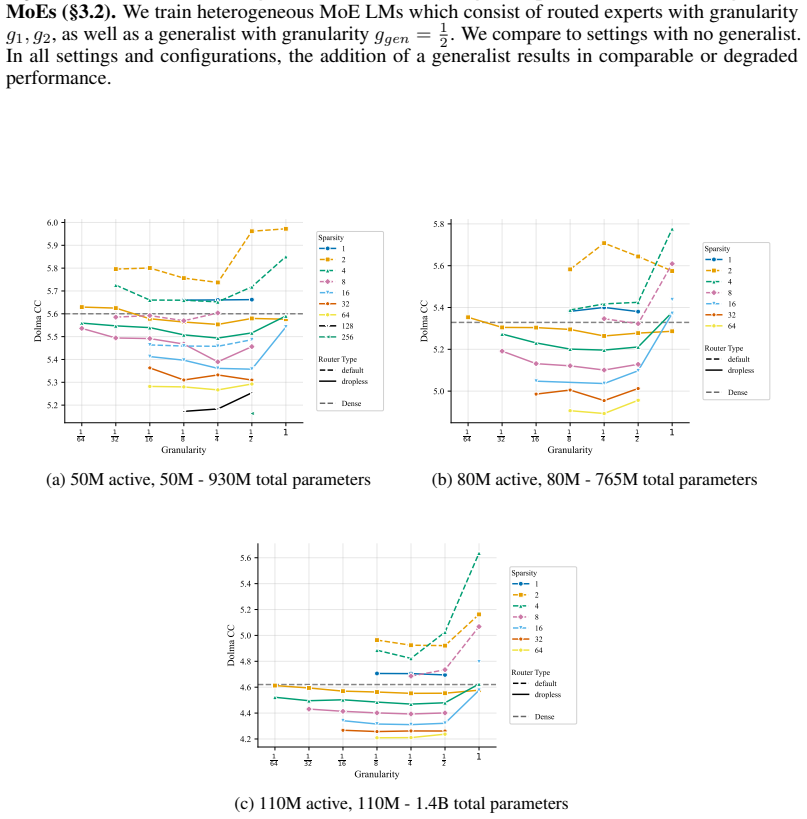
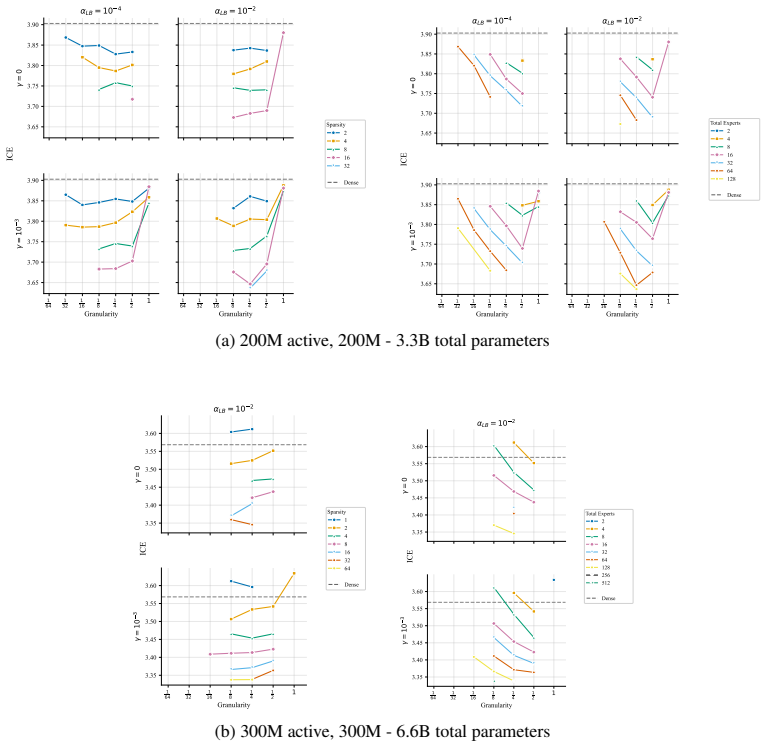
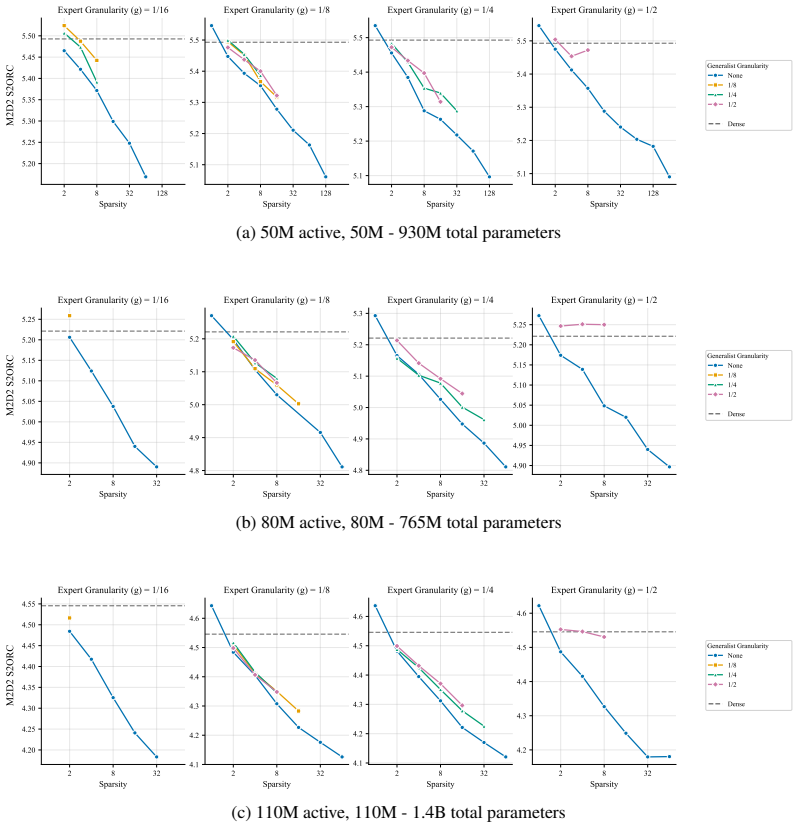
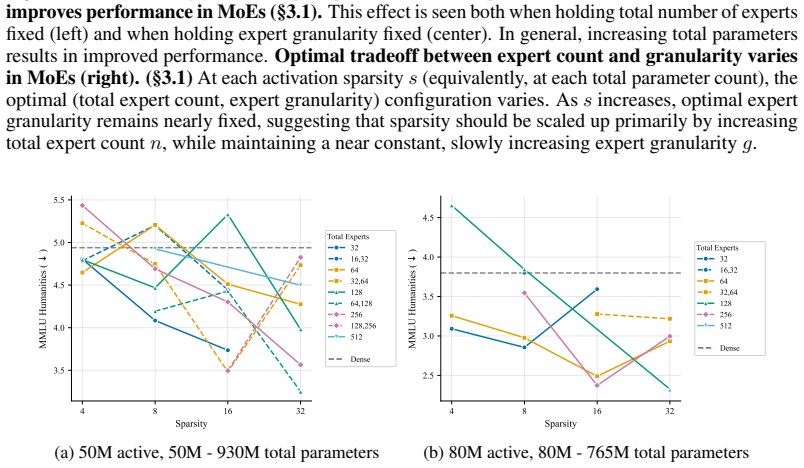
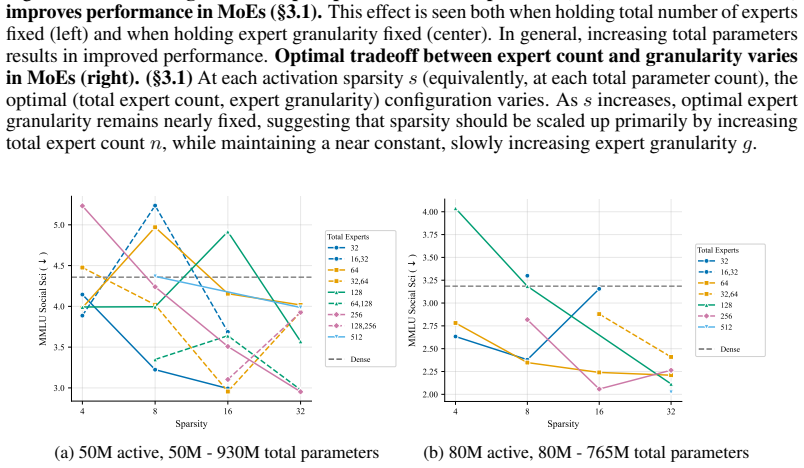
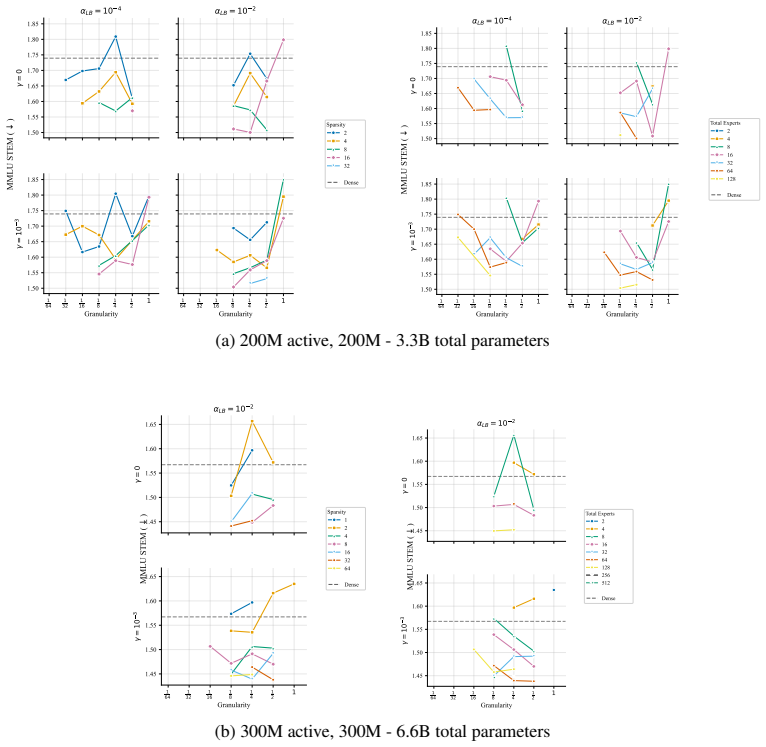
At every active-parameter scale studied, performance consistently improves with total MoE parameters even at extreme active expert parameter ratios like 128. The optimal expert size is nearly invariant to total parameter count and depends only on active parameter count. Other choices like shared experts, heterogeneous experts and load-balancing settings have small effects relative to expert count and granularity, although dropless routing yields a consistent gain.
What carries the argument
Exhaustive sweeps of total expert count, expert dimension, shared expert size, heterogeneous sizing, and load-balancing mechanisms across thousands of pretraining runs.
Load-bearing premise
That patterns seen in pretraining loss for models up to 6.6 billion parameters will continue at much larger scales and will predict gains on downstream tasks.
What would settle it
A pretraining run at a scale well above 6.6 billion parameters in which raising total MoE parameters at fixed active count stops improving loss, or in which downstream task accuracy diverges from the pretraining trends.
Figures






























































































































read the original abstract
Mixture-of-Experts (MoE) architectures have become standard in large language models, yet many of their core design choices - expert count, granularity, shared experts, load balancing, token dropping - have only been studied one or two at a time over narrow configuration ranges. It remains an open question whether these choices can be optimized independently, without considering interactions. We present the first systematic study of over 2,000 pretraining runs spanning models up to 6.6B total parameters, in which we exhaustively vary total experts, expert dimension, heterogeneous expert sizing within a single layer, shared expert size and load-balancing mechanisms. We find that at every active-parameter scale that we study, performance consistently improves with total MoE parameters even at extreme active expert parameter ratios like 128.Further, the optimal expert size is nearly invariant to total parameter count and depends only on active parameter count. Third, we see that other choices like shared experts, heterogeneous experts and load-balancing settings have small effects relative to expert count and granularity, although dropless routing yields a consistent gain. Overall, our results suggest a simpler recipe: focus on expert count and granularity, other choices have minimal effect on final quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from over 2,000 pretraining runs on MoE models up to 6.6B total parameters. It claims that, at fixed active-parameter count, pretraining loss improves monotonically with increasing total MoE parameters even at active-to-total ratios as high as 128; that the optimal expert dimension is essentially invariant to total model size and depends only on the active parameter budget; and that auxiliary design choices (shared experts, heterogeneous sizing, load-balancing coefficients) produce only small effects relative to expert count and granularity, while dropless routing yields a consistent gain. The authors conclude that MoE configuration can be simplified to primarily tuning expert count and granularity.
Significance. If the reported trends hold, the work supplies a practical, data-driven recipe that reduces the configuration search space for MoE models. The scale of the experimental campaign (>2,000 independent runs) and the consistency of the ordering across multiple active-parameter regimes constitute a clear empirical contribution to the literature on sparse architectures.
minor comments (3)
- [§4.1] §4.1 and Figure 3: the definition of the active-to-total parameter ratio is introduced only in the caption; moving the explicit formula to the main text would improve readability.
- [Table 2] Table 2: the reported loss differences for shared-expert and load-balancing ablations are on the order of 0.01–0.03; adding bootstrap confidence intervals or noting the number of seeds would help readers judge whether these differences are distinguishable from noise.
- [§5.3] §5.3: the discussion of downstream-task transfer is limited to a single sentence; a brief quantitative statement (or explicit statement that downstream evaluation is left for future work) would clarify the scope of the claims.
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of our findings, and recommendation to accept. The scale and consistency of the experimental results are indeed central to the contribution.
Circularity Check
No significant circularity identified
full rationale
The paper is a purely empirical study reporting results from over 2,000 independent pretraining runs up to 6.6B parameters. Central claims (performance gains with total MoE parameters at fixed active count, invariance of optimal expert dimension to total size) are direct observations from measured losses across varied configurations; no equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present that would reduce any result to its own inputs by construction. The work contains no load-bearing mathematical steps or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretraining loss reliably indicates relative model quality across configurations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present the first systematic study of over 2,000 pretraining runs spanning models up to 6.6B total parameters, in which we exhaustively vary total experts, expert dimension, heterogeneous expert sizing within a single layer, shared expert size and load-balancing mechanisms.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
performance consistently improves with total MoE parameters even at extreme active expert parameter ratios like 128. The optimal expert size is nearly invariant to total parameter count and depends only on active parameter count.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
in OLMoE. 13 A Additional Training Details A.1 Training Data Our training data is directly taken from Muennighoff et al. (2025) and consists of documents from: DCLM-Baseline (Li et al., 2024), StarCoder (Li et al., 2023; Kocetkov et al., 2022), peS2o (Soldaini & Lo, 2023; Soldaini et al., 2024a), arXiv (Computer, 2023), OpenWebMath (Paster et al., 2023), ...
work page 2025
-
[2]
(1, 2) (4, 8) 4 (8, 16) 8 (16, 32) 16 (32, 64) 32 ( 1 4 , 1
-
[3]
(2, 4) (8, 16) 4 (16, 32) 8 (32, 64) 16 (64, 128) 32 ( 1 8 , 1
-
[4]
(4, 8) (16, 32) 4 (32, 64) 8 (64, 128) 16 (128, 256) 32 ( 1 16 , 1
-
[5]
We show the configurations used in the heterogeneous MoE experiments
(8, 16) (16, 32) 2 (32, 64) 4 (64, 128) 8 (128, 256) 16 Table 3:Heterogeneous MoE configurations (§3.2).. We show the configurations used in the heterogeneous MoE experiments. 17 B Discussion of Hyperparameters and Configurations B.1 Preliminary Hyperparameter Investigations Learning RateWe sweep the learning rate in {1e−4,4e−4,1e−3,4e−3,1e−2} . We find t...
work page 2025
-
[6]
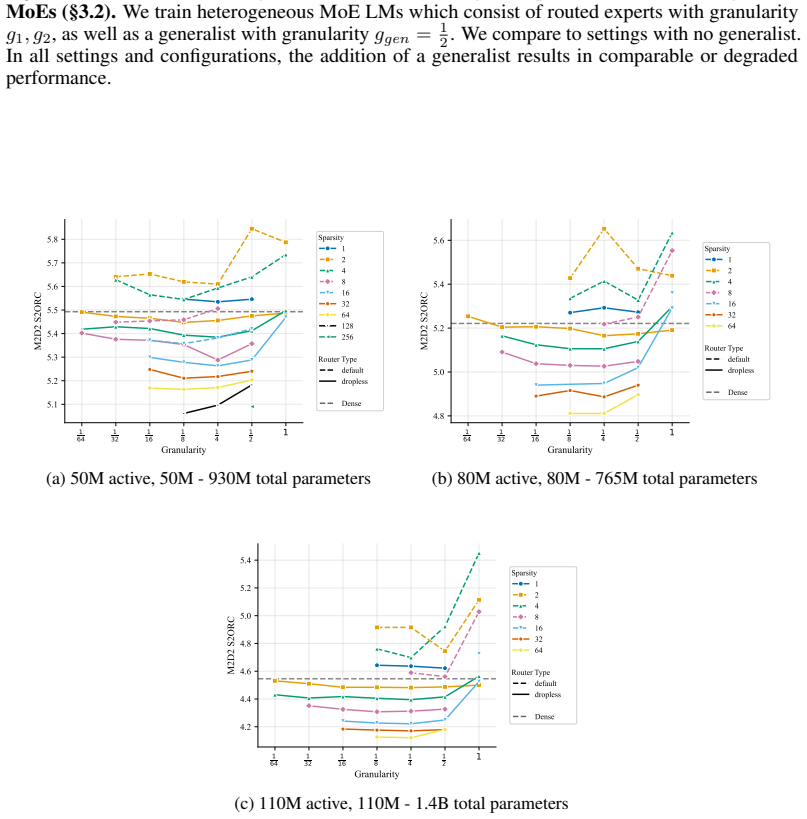
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.2 5.4 5.6 5.8 6.0 6.2 LM Average ( ) Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32...
-
[7]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.2 5.4 5.6 5.8C4 Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 16 1 8 1 4 1 2 1 G...
-
[8]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.4 5.6 5.8 6.0 6.2 6.4 6.6 6.8Dolma Books Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 ...
-
[9]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6.0Dolma CC Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64...
-
[10]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 4.8 5.0 5.2 5.4 5.6 5.8 6.0Dolma peS2o Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32...
-
[11]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 4.9 5.0 5.1 5.2 5.3 5.4 5.5Dolma Reddit Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 3...
-
[12]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.4 5.6 5.8 6.0 6.2 6.4 6.6 6.8Dolma Stack Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 ...
-
[13]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.0 5.2 5.4 5.6 5.8 6.0Dolma Wiki Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 16...
-
[14]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.4 5.6 5.8 6.0 6.2ICE Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 16 1 8 1 4 1 ...
-
[15]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8M2D2 S2ORC Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1...
-
[16]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.0 5.2 5.4 5.6 5.8 6.0Pile Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 16 1 8 1...
-
[17]
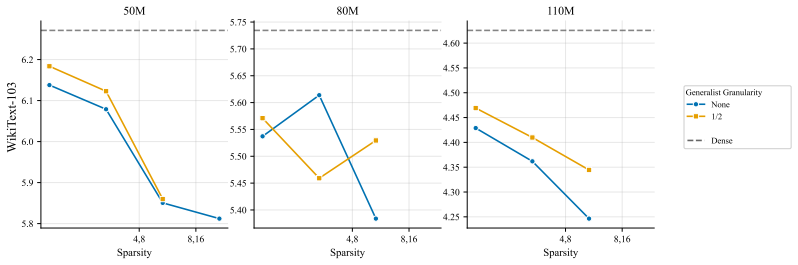
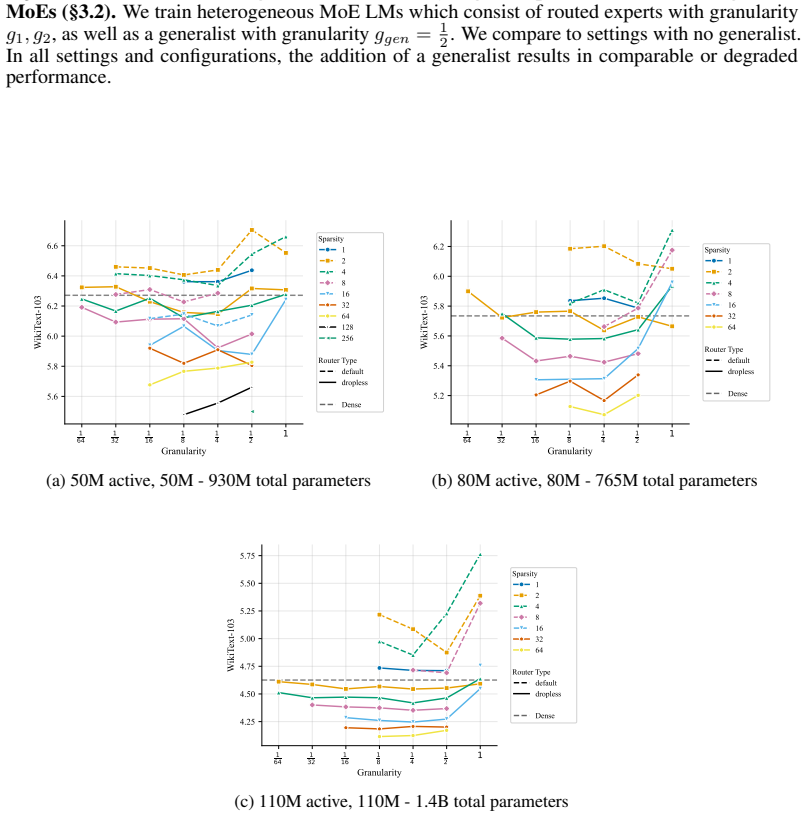
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 5.6 5.8 6.0 6.2 6.4 6.6WikiText-103 Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 ...
-
[18]
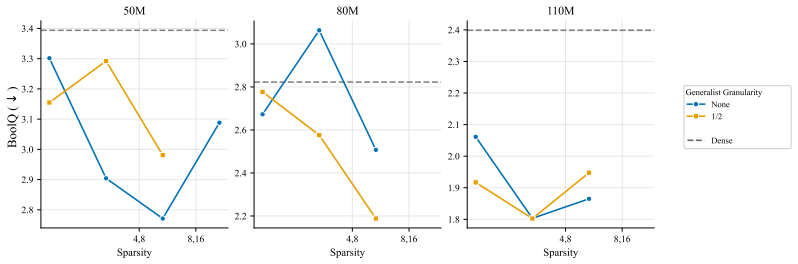
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 2.6 2.8 3.0 3.2 3.4 3.6 BoolQ ( ) Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 16...
-
[19]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 2.6 2.8 3.0 3.2 3.4 3.6 BoolQ ( ) Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 16...
-
[20]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 3.0 3.5 4.0 4.5 5.0 5.5 MMLU Humanities ( ) Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64...
-
[21]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 2.5 3.0 3.5 4.0 4.5 MMLU Other ( ) Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64 1 32 1 1...
-
[22]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 2.5 3.0 3.5 4.0 4.5 5.0 MMLU Social Sci ( ) Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64...
-
[23]
We compare to settings with no generalist. In all settings and configurations, the addition of a generalist results in comparable or degraded performance. 1 64 1 32 1 16 1 8 1 4 1 2 1 Granularity 2.5 3.0 3.5 4.0 4.5 5.0 MMLU Social Sci ( ) Sparsity 1 2 4 8 16 32 64 128 256 Router Type default dropless Dense (a) 50M active, 50M - 930M total parameters 1 64...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.