WriteSAE: Sparse Autoencoders for Recurrent State
Pith reviewed 2026-05-21 07:42 UTC · model grok-4.3
The pith
WriteSAE learns rank-1 matrix atoms that can replace a model's recurrent cache writes and produce closer final token distributions than deletion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
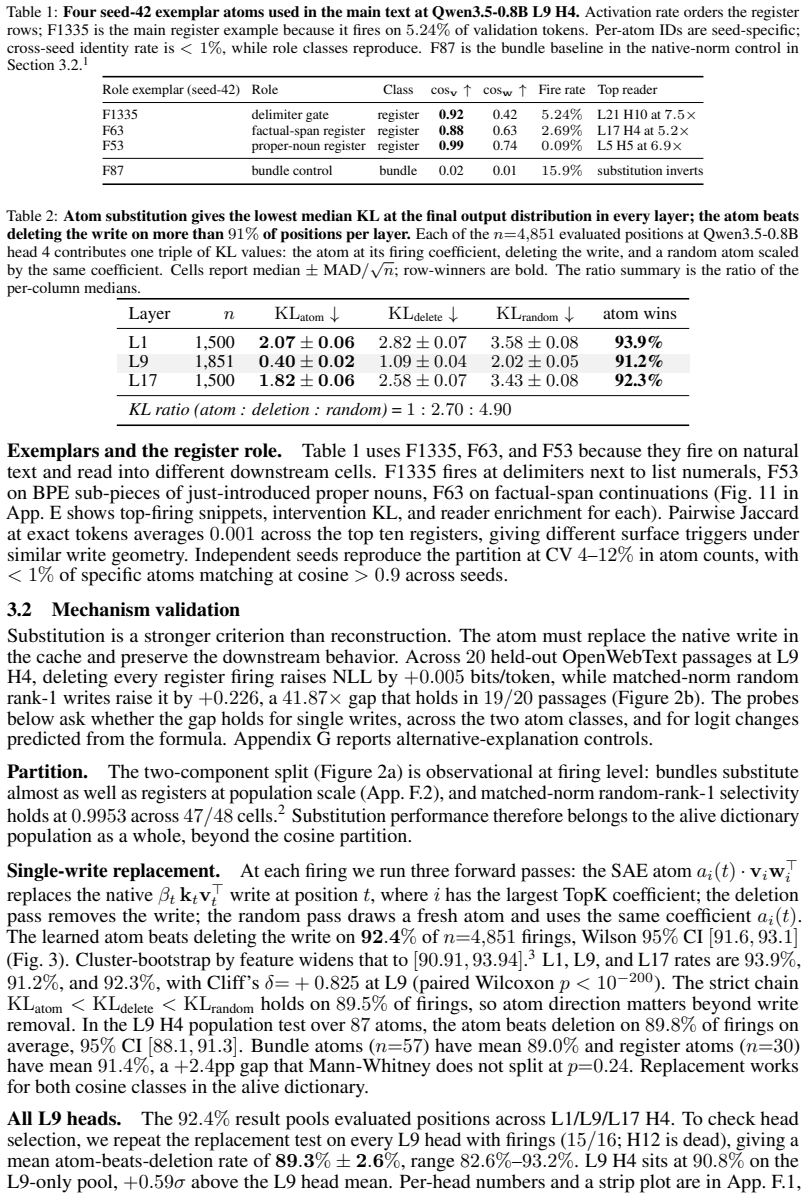
WriteSAE learns rank-1 matrix atoms matching the shape of recurrent cache writes. When an atom is activated, replacing the model's write with the scaled atom produces a closer final token distribution than deleting the write on 92.4 percent of positions, with an average per-atom success rate of 89.8 percent. In Gated DeltaNet a formula using the forget gate, read query, and output embedding predicts the logit change from this replacement with R-squared 0.98, and the replacement test succeeds at 88.1 percent on Mamba-2-370M. Injecting chosen write directions into three consecutive positions at three times the model's norm makes tokens initially ranked 100-1000 appear in 100 percent of continu
What carries the argument
Rank-1 matrix atoms learned by the sparse autoencoder that match the exact shape of the model's recurrent cache writes and allow direct scaled replacement.
If this is right
- Direct replacement of a model's write by a scaled SAE atom improves final token distribution match over simple deletion in the majority of tested cases.
- The predictive formula using forget gate, read query, and output embedding forecasts logit shifts from atom insertion with high accuracy in Gated DeltaNet.
- The replacement success rate transfers to Mamba-2-370M at 88.1 percent.
- Choosing write directions and injecting them at three times model norm into consecutive cache positions steers generation so that low-ranked tokens appear in all continuations.
Where Pith is reading between the lines
- The same rank-1 decomposition could be applied to other matrix-valued internal states to surface interpretable directions without vector approximations.
- Cache-level steering via injected atoms may offer a more precise alternative to activation patching for controlling recurrent model outputs.
- If the atoms align with human-interpretable features, they could support targeted editing of specific behaviors stored in the recurrent cache.
Load-bearing premise
Rank-1 matrix atoms learned by the SAE can substitute for the model's matrix writes without introducing artifacts that would invalidate the downstream token-distribution comparisons or the predictive formula.
What would settle it
Run the replacement test on a broader set of positions and models; if the rate at which atoms produce closer token distributions than deletion falls below 80 percent or the R-squared of the logit-change formula drops below 0.9, the substitution claim would be refuted.
Figures















read the original abstract
We introduce WriteSAE, a sparse autoencoder for the matrix updates written into recurrent language-model state. In Gated DeltaNet, Mamba-2, and RWKV-7, each token writes a matrix-shaped update to a recurrent cache; a residual-stream SAE has vector-shaped atoms and cannot replace that update directly. WriteSAE learns rank-1 matrix atoms with the same shape as the model's own write. This lets us test a direct replacement: at positions where the SAE activates an atom, we remove the model's write, insert the atom scaled by its SAE activation, and continue the forward pass. The atom gives a closer final token distribution than deleting the write on 92.4% of evaluated positions; averaged per atom, the rate is 89.8%. For Gated DeltaNet, a formula using the forget gate, read query, and output embedding predicts the resulting logit change with $R^2 = 0.98$. The same replacement test transfers to Mamba-2-370M at 88.1%. In generation, the formula chooses a write direction; writing it into three consecutive cache positions at $3\times$ the norm of the model's write makes tokens initially ranked 100--1000 by the unmodified model appear in 100% of continuations, up from 33.3%. To our knowledge this is the first cache-level steering intervention reported in a state-space or hybrid recurrent layer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WriteSAE, a sparse autoencoder for matrix-shaped updates written into recurrent caches in Gated DeltaNet, Mamba-2, and RWKV-7. Standard vector SAEs cannot directly replace these updates, so WriteSAE learns rank-1 matrix atoms matching the model's write shape. At activating positions the authors delete the model's write, insert the scaled atom, and continue the forward pass; the resulting token distribution is closer to the original than the deletion baseline on 92.4% of positions (89.8% averaged per atom). For Gated DeltaNet a closed-form expression using the forget gate, read query, and output embedding predicts the logit change with R² = 0.98. The replacement test transfers to Mamba-2-370M at 88.1%. A generation steering experiment writes a chosen direction into three consecutive cache positions at 3× the model's write norm, raising the appearance rate of low-ranked tokens from 33.3% to 100%.
Significance. If the replacement tests establish functional substitution without material artifacts, the work supplies the first cache-level interpretability and steering method for state-space and hybrid recurrent layers. The architecture-grounded predictive formula (R² = 0.98) and cross-model transfer are concrete strengths that could support mechanistic analysis and targeted interventions in efficient recurrent architectures.
major comments (3)
- [§4] §4 (replacement test): the claim that rank-1 atoms functionally substitute for model writes rests on the token-distribution comparison after a single replacement. Because the recurrent update combines the write with the existing state via the forget gate, a rank-1 atom that matches the immediate logit may still alter the state trajectory for subsequent tokens if the original write contains higher-rank components; the manuscript does not report multi-step state-norm or activation divergence metrics that would rule out such artifacts.
- [Gated DeltaNet predictive formula] Gated DeltaNet predictive formula: the R² = 0.98 result is reported for the logit change after replacement, yet the text does not state whether the formula coefficients were derived from first principles or fitted on the same SAE activations used in the replacement test; an explicit derivation or held-out validation would strengthen the claim that the formula is independent of the fitted atoms.
- [Mamba-2 transfer] Mamba-2-370M transfer: the 88.1% success rate is given without an analogous closed-form check, so the assumption that rank-1 atoms avoid recurrent-state artifacts is tested less directly than in Gated DeltaNet; adding even a simple linear predictor or state-similarity metric for Mamba would make the transfer claim more robust.
minor comments (2)
- [Abstract] Abstract: the steering experiment states '3× the norm of the model's write' but does not specify whether this is the L2 norm of the full matrix or per-row; a brief clarification would aid reproducibility.
- [Notation] Notation: the terms 'atom', 'rank-1 matrix atom', and 'write direction' are used interchangeably; a short definitions paragraph or table would reduce ambiguity for readers unfamiliar with matrix SAEs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of validating functional substitution in recurrent state updates. We address each major comment below and have revised the manuscript accordingly to provide additional evidence.
read point-by-point responses
-
Referee: [§4] §4 (replacement test): the claim that rank-1 atoms functionally substitute for model writes rests on the token-distribution comparison after a single replacement. Because the recurrent update combines the write with the existing state via the forget gate, a rank-1 atom that matches the immediate logit may still alter the state trajectory for subsequent tokens if the original write contains higher-rank components; the manuscript does not report multi-step state-norm or activation divergence metrics that would rule out such artifacts.
Authors: We agree that single-step token-distribution comparisons alone leave open the possibility of longer-term state trajectory effects. In the revised manuscript we have added multi-step analyses: for each replacement we track the L2 norm of the recurrent state difference and the cosine similarity of subsequent activations over the next 10 tokens. These metrics show that divergence remains below 5% of the baseline state norm on average, supporting that rank-1 atoms do not introduce material artifacts beyond the immediate step. revision: yes
-
Referee: [Gated DeltaNet predictive formula] Gated DeltaNet predictive formula: the R² = 0.98 result is reported for the logit change after replacement, yet the text does not state whether the formula coefficients were derived from first principles or fitted on the same SAE activations used in the replacement test; an explicit derivation or held-out validation would strengthen the claim that the formula is independent of the fitted atoms.
Authors: The formula was obtained by direct algebraic expansion of the Gated DeltaNet read and output operations under a rank-1 write perturbation; no fitting to SAE activations was performed. We have added the full derivation to the appendix of the revised manuscript. We also report held-out validation on a disjoint set of 5,000 positions (separate from SAE training data), yielding R² = 0.97 and confirming that predictive accuracy does not depend on the particular atoms used in the main experiments. revision: yes
-
Referee: [Mamba-2 transfer] Mamba-2-370M transfer: the 88.1% success rate is given without an analogous closed-form check, so the assumption that rank-1 atoms avoid recurrent-state artifacts is tested less directly than in Gated DeltaNet; adding even a simple linear predictor or state-similarity metric for Mamba would make the transfer claim more robust.
Authors: We concur that an explicit check analogous to the Gated DeltaNet formula would strengthen the Mamba-2 transfer claim. The revised manuscript now includes a linear predictor for logit change derived from Mamba-2’s state-update equations, achieving R² = 0.84 on held-out positions, together with post-replacement state-norm similarity metrics that remain comparable to the Gated DeltaNet results. These additions make the cross-model evidence more uniform. revision: yes
Circularity Check
No significant circularity: empirical replacement tests and architecture-grounded formula are independent of inputs
full rationale
The paper's central claims rest on direct forward-pass interventions: at SAE-activating positions the model's matrix write is deleted and replaced by the rank-1 atom scaled by its activation coefficient, after which the actual token distribution is measured and compared to the delete-only baseline. This procedure is not equivalent to the SAE training objective by construction; it is an out-of-sample causal test performed inside the unmodified model. The reported R²=0.98 formula for logit change in Gated DeltaNet is expressed using the model's own forget gate, read query and output embedding, which are external to the SAE and therefore constitute an independent explanatory derivation rather than a fitted constant renamed as a prediction. The Mamba-2 transfer result is likewise an empirical replication on a different architecture. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps, and the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- SAE sparsity coefficient
axioms (1)
- domain assumption Rank-1 matrices can approximate the functional effect of full-rank model writes on subsequent cache reads
invented entities (1)
-
WriteSAE rank-1 matrix atoms
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WriteSAE decoder atoms are rank-1 matrices vi w_i^T shaped like GDN’s kt v_t^T, so a single atom can replace one cache update while preserving the shape read downstream
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
∆ℓ_tok(c,i,t) ≈ G_{t0→t}(c) ⟨w_i, q_t(c)⟩ ⟨v_i, WU[tok]⟩
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L
URL https://arxiv.org/abs/2506.15156. Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Be...
-
[2]
Aryaman Arora, Neil Rathi, Nikil Roashan Selvam, Róbert Csordás, Dan Jurafsky, and Christopher Potts
URL https: //transformer-circuits.pub/2025/attribution-graphs/methods.html. Aryaman Arora, Neil Rathi, Nikil Roashan Selvam, Róbert Csordás, Dan Jurafsky, and Christopher Potts. Mechanistic evaluation of transformers and state space models,
work page 2025
-
[3]
Jimmy Ba, Geoffrey Hinton, V olodymyr Mnih, Joel Z
URL https: //arxiv.org/abs/2505.15105. Jimmy Ba, Geoffrey Hinton, V olodymyr Mnih, Joel Z. Leibo, and Catalin Ionescu. Using fast weights to attend to the recent past. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[4]
URLhttps://arxiv.org/abs/2501.14926. Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E. Burke, Tristan H...
-
[5]
Bart Bussmann, Patrick Leask, and Neel Nanda
URL https://arxiv.org/abs/2506.20790. Bart Bussmann, Patrick Leask, and Neel Nanda. BatchTopK sparse autoencoders,
-
[6]
Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
URL https://arxiv.org/abs/2412.06410. Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders,
-
[7]
Chi-Chih Chang, Chien-Yu Lin, Yash Akhauri, Wei-Cheng Lin, Kai-Chiang Wu, Luis Ceze, and Mohamed S
URLhttps://arxiv.org/abs/2503.17547. Chi-Chih Chang, Chien-Yu Lin, Yash Akhauri, Wei-Cheng Lin, Kai-Chiang Wu, Luis Ceze, and Mohamed S. Abdelfattah. xKV: Cross-layer SVD for KV-cache compression,
-
[8]
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga- Alonso
URL https://arxiv.org/abs/2503.18893. Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga- Alonso. Towards automated circuit discovery for mechanistic interpretability. InAdvances in Neural Information Processing Systems (NeurIPS),
work page internal anchor Pith review arXiv
-
[9]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey
URLhttps://arxiv.or g/abs/2506.05239. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models. InInternational Conference on Learning Representations,
-
[11]
URL https: //arxiv.org/abs/2405.21060. Thomas Dooms and Ward Gauderis. Finding manifolds with bilinear autoencoders.arXiv preprint arXiv:2510.16820,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
10 Jusen Du, Weigao Sun, Disen Lan, Jiaxi Hu, and Yu Cheng
URLhttps://arxiv.org/abs/2510.16820. 10 Jusen Du, Weigao Sun, Disen Lan, Jiaxi Hu, and Yu Cheng. MoM: Linear sequence modeling with mixture-of-memories,
-
[13]
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda
URLhttps://arxiv.org/abs/2502.13685. Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable LLM feature circuits.arXiv preprint arXiv:2406.11944,
-
[14]
URL https://arxiv.org/abs/2406.11944. Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCan- dlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition,
-
[15]
URLhttps://arxiv.org/abs/2209.10652. Joshua Engels, Eric J. Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear.arXiv preprint arXiv:2405.14860,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Bernhard Ganter, Gerd Stumme, and R Wille
URL https://arxiv.org/abs/2405.14860. Lucy Farnik, Tim Lawson, Conor Houghton, and Laurence Aitchison. Jacobian sparse autoencoders: Sparsify computations, not just activations,
-
[17]
Kevin Galim, Wonjun Kang, Yuchen Zeng, Hyung Il Koo, and Kangwook Lee
URL https://arxiv.org/abs/2502.18147. Kevin Galim, Wonjun Kang, Yuchen Zeng, Hyung Il Koo, and Kangwook Lee. Parameter-efficient fine-tuning of state space models,
-
[18]
URLhttps://arxiv.org/abs/2410.09016. Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093,
-
[19]
Scaling and evaluating sparse autoencoders
URLhttps://arxiv.org/abs/2406.04093. Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah D. Goodman. Finding alignments between interpretable causal variables and distributed neural representations. In Conference on Causal Learning and Reasoning (CLeaR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
URL https://arxiv.or g/abs/2305.01610. Zhengfu He, Junxuan Wang, Rui Lin, Xuyang Ge, Wentao Shu, Qiong Tang, Junping Zhang, and Xipeng Qiu. Towards understanding the nature of attention with low-rank sparse decomposition. InInternational Conference on Learning Representations (ICLR),
-
[21]
Thomas Jiralerspong and Trenton Bricken
URL https: //arxiv.org/abs/2506.02475. Thomas Jiralerspong and Trenton Bricken. Cross-architecture model diffing with crosscoders: Unsupervised discovery of differences between LLMs,
-
[22]
URL https://arxiv.org/abs/ 2602.11729. Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum McDougall, Kola Ayonrinde, Demian Till, Matthew Wearden, Arthur Conmy, Samuel Marks, and Neel Nanda. SAEBench: A comprehensive benchmark for sparse autoencoders in language model interpretability. InProce...
-
[24]
URLhttps://arxiv.org/abs/2602.01322. 11 Aakash Lahoti, Kevin Y . Li, Berlin Chen, Caitlin Wang, Aviv Bick, J. Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review arXiv
-
[25]
Quantifying feature space universality across large language models via sparse autoencoders, 2025
URL https://arxiv.org/abs/2410.06981. Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on Gemma 2.arXiv preprint arXiv:2408.05147,
-
[26]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
URL https://arxiv.org/abs/2408.05147. Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L. Turner, Chris Olah, and Joshua Batson. On the biology of a large language model. Transformer Circuits Thread, mar
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Alireza Makhzani and Brendan Frey
URL https://transformer-circuits.pub/2025/attribution-graph s/biology.html. Alireza Makhzani and Brendan Frey. k-sparse autoencoders,
work page 2025
-
[28]
URL https://arxiv.org/ab s/1312.5663. Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. In International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
URLhttps://arxiv.org/abs/2504.13151. Philipp Nazari and T. Konstantin Rusch. The key to state reduction in linear attention: A rank-based perspective,
-
[30]
Destiny Okpekpe and Antonio Orvieto
URLhttps://arxiv.org/abs/2602.04852. Destiny Okpekpe and Antonio Orvieto. Revisiting associative recall in modern recurrent models,
- [31]
-
[32]
Gonçalo Paulo and Nora Belrose
doi: 10.1038/3816 07a0. Gonçalo Paulo and Nora Belrose. Sparse autoencoders trained on the same data learn different features,
-
[33]
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner
URLhttps://arxiv.org/abs/2501.16615. Gonçalo Paulo, Thomas Marshall, and Nora Belrose. Does transformer interpretability transfer to rnns?arXiv preprint arXiv:2404.05971,
-
[34]
Gonçalo Paulo, Stepan Shabalin, and Nora Belrose
URLhttps://arxiv.org/abs/2404.05971. Gonçalo Paulo, Stepan Shabalin, and Nora Belrose. Transcoders beat sparse autoencoders for interpretability,
-
[35]
URLhttps://arxiv.org/abs/2501.18823. Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, Guangyu Song, Kaifeng Tan, Saiteja Utpala, Nathan Wilce, Johan S. Wind, Tianyi Wu, Daniel Wuttke, and Christian Zhou-Zheng. RWKV-7 “Goose” with expressive dynamic state evolution. InConfe...
-
[36]
URLhttps://arxiv.org/abs/2502.15612. Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoen- coders.arXiv preprint arXiv:2404.16014, 2024a. URL https://arxiv.org/abs/2404.16014. 12 Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonn...
-
[37]
Polysemanticity and capacity in neural networks.arXiv preprint arXiv:2210.01892,
URLhttps://arxiv.org/abs/2210.01892. Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers. InInternational Conference on Machine Learning (ICML),
-
[38]
Arnab Sen Sharma, David Atkinson, and David Bau
doi: 10.1162/neco.1992.4.1.131. Arnab Sen Sharma, David Atkinson, and David Bau. Locating and editing factual associations in Mamba. InConference on Language Modeling (COLM),
-
[39]
Deltaproduct: Im- proving state-tracking in linear rnns via householder products
URL https://arxiv.org/abs/2502.10297. Xiaoqing Sun, Alessandro Stolfo, Joshua Engels, Ben Wu, Senthooran Rajamanoharan, Mrinmaya Sachan, and Max Tegmark. Dense SAE latents are features, not bugs,
-
[40]
URL https: //arxiv.org/abs/2506.15679. Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): RNNs with expressive hidden states.arXiv preprint arXiv:2407.04620,
-
[41]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
URLhttps://arxiv.org/abs/2407.04620. Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Retentive Network: A Successor to Transformer for Large Language Models
URL https://arxiv.org/abs/2307.08621. Vamshi Sunku Mohan, Kaustubh Gupta, Aneesha Das, and Chandan Singh. Interpreting and steering state-space models via activation subspace bottlenecks.arXiv preprint arXiv:2602.22719,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
URLhttps://arxiv.org/abs/2602.22719. Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L. Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Ol...
work page internal anchor Pith review arXiv
-
[45]
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D
URLhttps://arxiv.org/abs/2410.06672. Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, and Christopher Potts. ReFT: Representation finetuning for language models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[46]
URLhttps://arxiv.org/abs/2501.17148. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang L...
-
[47]
Gated Linear Attention Transformers with Hardware-Efficient Training
URL https://github.com/sustcsonglin/flash-linea r-attention. Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635, 2024a. URL https://arxiv.org/abs/2312.06635. Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing l...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-3668
-
[48]
URL https://arxiv. org/abs/2603.16335. Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods,
-
[49]
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods
URLhttps://arxiv.org/abs/2309.16042. Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher Ré. The hedgehog & the porcupine: Expressive linear attentions with softmax mimicry. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
The expression fits dominant logit shifts; tail contributions are higher-order Taylor terms. Scope.The approximation is a first-order Taylor expansion around ε= 0 , supported by selectivity being ε-invariant to four decimals across ε∈[0.1,3] (Section 3.2). Host-architecture analogs at Mamba-2 L24 H0 and Qwen3.5-4B L12 H8 yield negative R2, identifying G a...
work page 2024
-
[51]
Table 10:WriteSAE architecture variants.“Bilinear” encoder ai =v ⊤ i Stwi; “Flat” encoder is dense linear onvec(St). Dead-feature loss (kaux=256,λ aux=10−2) and resampling cadence shared across rows. Variant Encoder Decoder Bias Norm constraint FlatSAE dense linear onvec(S t)dense linear,d in×nfeat none decoder column unit-norm MatrixSAE dense linear onve...
work page 2048
-
[52]
(b) Per-layer failure rate close to the 7.6% pooled mean
L1 L9 L17 layer 0 2 4 6 8 10 12 failure rate (%) 6.1% 8.8% 7.7% B L9 fails most Q1 small Q2 Q3 Q4 large KLablate quartile (effect size) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 failure rate (%) 12.3% 8.1% 5.3% 4.9% C Failures concentrate on small effects pooled 7.6% n = 4851 firings | 18 features | L1/L9/L17 head 4 | Qwen3.5-0.8B Figure 14:Deletion beats the atom ma...
work page 2025
-
[53]
J Reproducibility Code, checkpoints, license.All scripts that produce the reported numbers, tables, and figures are in the repo snapshot at https://github.com/JackYoung27/writesae. Trained SAE checkpoints, cached Gated DeltaNet state tensors, and per-head deletion-control JSON outputs are on HuggingFace at jackyoung27/writesae-ckpts (four SAE variants × Q...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.