Slot-MPC: Goal-Conditioned Model Predictive Control with Object-Centric Representations
Pith reviewed 2026-06-30 20:57 UTC · model grok-4.3
The pith
Object-centric slot representations enable gradient-based model predictive control for adapting to novel robotic manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
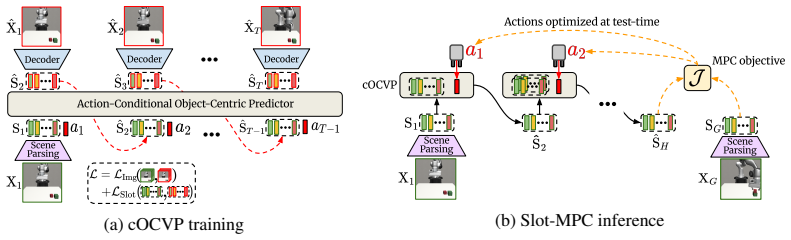
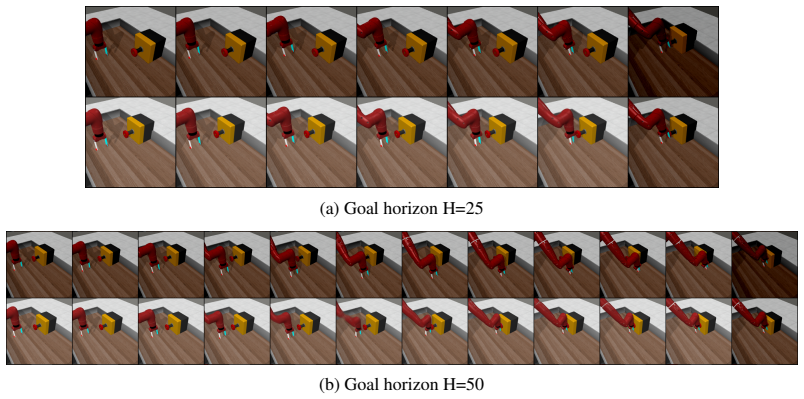
Slot-MPC extracts slot-based object representations with vision encoders, trains an action-conditioned dynamics model on those slots, and performs goal-conditioned planning at inference time by using the differentiable dynamics inside a gradient-based model predictive controller. In offline robotic manipulation settings the method yields higher task success and lower planning cost than non-object-centric world-model baselines, with gradient-based optimization outperforming sampling-based optimization under limited data coverage.
What carries the argument
Slot-based representations that isolate individual objects, paired with an action-conditioned object-centric dynamics model that is differentiated through gradient-based MPC to optimize action sequences.
If this is right
- Agents can generate new action sequences at test time instead of executing a fixed reactive policy.
- Gradient-based optimization of actions is computationally cheaper than sampling-based MPC when the dynamics model is differentiable.
- Performance remains higher than non-object-centric baselines even when state-action coverage in the training data is limited.
- The same learned world model supports planning toward goals that were not encountered during training.
Where Pith is reading between the lines
- The same slot-plus-MPC structure could be tested on tasks where objects must be composed in ways never seen together during training.
- Because the planner is differentiable, one could explore adding a planning loss directly into the representation learning stage.
- If slot extraction remains reliable under real camera noise, the approach might transfer to physical robots without additional online fine-tuning.
Load-bearing premise
Vision encoders must produce slot representations that correctly separate objects from one another and that support accurate prediction of how those objects move under actions.
What would settle it
Measure planning success on held-out manipulation tasks after deliberately training the vision encoder on data that mixes object identities or occlusions; if success drops to baseline levels the claim fails.
Figures





read the original abstract
Predictive world models enable agents to model scene dynamics and reason about the consequences of their actions. Inspired by human perception, object-centric world models capture scene dynamics using object-level representations, which can be used for downstream applications such as action planning. However, most object-centric world models and reinforcement learning (RL) approaches learn reactive policies that are fixed at inference time, limiting generalization to novel situations. We propose Slot-MPC, an object-centric world modeling framework that enables planning through Model Predictive Control (MPC). Slot-MPC leverages vision encoders to learn slot-based representations, which encode individual objects in the scene, and uses these structured representations to learn an action-conditioned object-centric dynamics model. At inference time, the learned dynamics model enables action planning via MPC, allowing agents to adapt to previously unseen situations. Since the learned world model is differentiable, we can use gradient-based MPC to directly optimize actions, which is computationally more efficient than relying on gradient-free, sampling-based MPC methods. Experiments on simulated robotic manipulation tasks show that Slot-MPC improves both task performance and planning efficiency compared to non-object-centric world model baselines. In the considered offline setting with limited state-action coverage, we find that gradient-based MPC performs better than gradient-free, sampling-based MPC. Our results demonstrate that explicitly structured, object-centric representations provide a strong inductive bias for controllable and generalizable decision-making. Code and additional results are available at https://slot-mpc.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Slot-MPC, an object-centric world modeling framework that learns slot-based representations via vision encoders, trains an action-conditioned object dynamics model, and performs goal-conditioned planning at inference time using differentiable gradient-based MPC. It claims that this yields improved task performance and planning efficiency over non-object-centric baselines on simulated robotic manipulation tasks, with particular advantages in an offline limited state-action coverage regime, attributing the gains to the inductive bias of explicitly structured representations.
Significance. If the empirical results hold with appropriate controls and ablations, the work would provide evidence that object-centric slot representations supply a useful inductive bias for generalization and controllability in model-based planning, especially under data scarcity. The public release of code and additional results at the project page is a clear strength that supports reproducibility.
major comments (1)
- Abstract: the central claim of performance gains over baselines (including better results for gradient-based vs. sampling-based MPC in the offline regime) is stated without any quantitative metrics, error bars, dataset sizes, task descriptions, or ablation results. This absence makes the strength of evidence for the inductive-bias conclusion impossible to evaluate from the provided text.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify the presentation of our results. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim of performance gains over baselines (including better results for gradient-based vs. sampling-based MPC in the offline regime) is stated without any quantitative metrics, error bars, dataset sizes, task descriptions, or ablation results. This absence makes the strength of evidence for the inductive-bias conclusion impossible to evaluate from the provided text.
Authors: We agree that the abstract would be strengthened by the inclusion of indicative quantitative results. Abstracts are subject to strict length limits, which led us to prioritize high-level claims, but we will revise the abstract in the next version to include brief performance highlights (e.g., relative success-rate improvements and planning-time reductions) drawn from the main experiments. The full supporting evidence—including error bars, exact dataset sizes (number of offline trajectories), task descriptions, and ablation studies—is already present in Section 4 (Experiments) and the supplementary material. These results directly underpin the inductive-bias claim, especially the offline-regime comparison between gradient-based and sampling-based MPC. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes a standard pipeline of learning slot-based vision encoders and an action-conditioned object dynamics model from data, followed by gradient-based MPC planning at inference time. No equations, derivations, or claims are shown that reduce a 'prediction' or result to its own inputs by construction, self-definition, or load-bearing self-citation. The central claim rests on empirical comparisons to non-object-centric baselines in simulated tasks, which are independent of any internal definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Slot-based representations learned from vision encoders can isolate objects and capture their dynamics sufficiently for planning.
Reference graph
Works this paper leans on
-
[1]
MONet: Unsupervised Scene Decomposition and Representation
Christopher P Burgess, Loic Matthey, Nicholas Watters, Rishabh Kabra, Irina Higgins, Matt Botvinick, and Alexander Lerchner. Monet: Unsupervised scene decomposition and representation. arXiv:1901.11390,
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[2]
Klaus Greff, Sjoerd Van Steenkiste, and Jürgen Schmidhuber. On the binding problem in artificial neural networks.arXiv:2012.05208,
-
[3]
David Ha and Jürgen Schmidhuber. World models.arXiv:1803.10122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Model-Based Planning with Discrete and Continuous Actions
Mikael Henaff, William F. Whitney, and Yann LeCun. Model-based planning with discrete and continuous actions.arXiv:1705.07177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
A path towards autonomous machine intelligence version 0.9.2, 2022-06-27,
Yann LeCun. A path towards autonomous machine intelligence version 0.9.2, 2022-06-27,
2022
-
[6]
Compositional multi-object reinforcement learning with linear relation networks
Davide Mambelli, Frederik Träuble, Stefan Bauer, Bernhard Schölkopf, and Francesco Lo- catello. Compositional multi-object reinforcement learning with linear relation networks. arXiv:2201.13388,
-
[7]
Causal-JEPA: Learning World Models through Object-Level Latent Masking
Heejeong Nam, Quentin Le Lidec, Lucas Maes, Yann LeCun, and Randall Balestriero. Causal-JEPA: Learning world models through object-level latent interventions.arXiv:2602.11389,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2512.09929 , year=
Arjun Parthasarathy, Nimit Kalra, Rohun Agrawal, Yann LeCun, Oumayma Bounou, Pavel Izmailov, and Micah Goldblum. Closing the train-test gap in world models for gradient-based planning. arXiv:2512.09929,
- [9]
-
[10]
Gradient-based planning with world models.arXiv:2312.17227,
Jyothir S V , Siddhartha Jalagam, Yann LeCun, and Vlad Sobal. Gradient-based planning with world models.arXiv:2312.17227,
-
[11]
What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
Basile Terver, Tsung-Yen Yang, Jean Ponce, Adrien Bardes, and Yann LeCun. What drives success in physical planning with joint-embedding predictive world models?arXiv:2512.24497,
work page internal anchor Pith review Pith/arXiv arXiv
- [12]
-
[13]
Nicholas Watters, Loic Matthey, Christopher P Burgess, and Alexander Lerchner. Spatial broadcast de- coder: A simple architecture for learning disentangled representations in V AEs.arXiv:1901.07017,
-
[14]
Model Predictive Path Integral Control using Covariance Variable Importance Sampling
Grady Williams, Andrew Aldrich, and Evangelos A. Theodorou. Model predictive path integral control using covariance variable importance sampling.arXiv:1509.01149,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Martín-Martín, Abhishek Joshi, Kevin Lin, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning.arXiv:2009.12293,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[16]
15 C.2 Policy Model
13 Appendix A Limitations and Future Work 14 B Datasets and Simulation Environments 14 C Implementation Details 15 C.1 Object-Centric Learning and World Modeling . . . . . . . . . . . . . . . . . . . . . . 15 C.2 Policy Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 C.3 Training Details . . . . . . . . . . . . . . ....
2026
-
[17]
14 Meta-World [Yu et al., 2020]:is an open source benchmark (MIT license) containing continuous control robotic manipulation environments
Button Press Lever Pull Stack Square Figure 2:Environments.We evaluate Slot-MPC on four different environments. 14 Meta-World [Yu et al., 2020]:is an open source benchmark (MIT license) containing continuous control robotic manipulation environments. We consider theButton Presstask, which requires the robot to press a button that is randomly positioned in...
2020
-
[18]
We generate a training dataset consisting of9,000 training sequences and 1,000 validation trajectories using a random exploration policy
for the definitions of the reward functions and success metrics used in the Meta-World tasks. We generate a training dataset consisting of9,000 training sequences and 1,000 validation trajectories using a random exploration policy. We use the provided expert policies from Meta-World to generate a small training set of 200 expert demonstrations, as well as...
2020
-
[19]
for the implementation of both the object-centric decomposition model and the structured dynamics model. Object-Centric Decomposition:The object-centric decomposition is based on SA Vi [Kipf et al., 2022], a recursive slot-based model that serves as our scene parsing and object rendering modules. Specifically, we adopt their proposed CNN-based image encod...
2022
-
[20]
The projected object slots are then conditioned by adding the corresponding projected action at each time-step
To enable action-conditioned prediction, cOCVP maps both the actions a1:t and object slots S1:t into a shared token embedding space using learnable projection layers. The projected object slots are then conditioned by adding the corresponding projected action at each time-step. Furthermore, following Wu et al. [2023], we augment the tokens with a temporal...
2023
-
[21]
The policy is rolled out autoregressively over the horizonHusing the learned dynamics model to generate an initial action sequence for MPC
Through the attention mechanism, information from the object slots is aggregated into the [ACT]token, which is subsequently mapped to produce a single action ˆ ausing a learnable linear projection head. The policy is rolled out autoregressively over the horizonHusing the learned dynamics model to generate an initial action sequence for MPC. C.3 Training D...
2015
-
[22]
This module is trained with the Adam optimizer [Kingma and Ba, 2015], batch size of 64, and a learning rate of3×10 −4
πθ Training:We train the πθ module given pretrained and frozen SA Vi, and cOCVP modules. This module is trained with the Adam optimizer [Kingma and Ba, 2015], batch size of 64, and a learning rate of3×10 −4. C.4 Model Predictive Control We compare two different MPC methods: gradient-based MPC and MPPI. For both, we use a policy network to warm-start the o...
2015
-
[23]
DINO-WM:For DINO-WM, we use the official implementation provided by the authors and licensed under an MIT license: https://github.com/gaoyuezhou/dino_wm
for a complete list of hyperparameters. DINO-WM:For DINO-WM, we use the official implementation provided by the authors and licensed under an MIT license: https://github.com/gaoyuezhou/dino_wm. We use the default hyperparameters suggested by the authors. OCVP:For our experiments, we use OCVP as the object-centric world model and base our implementation on...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.