Runtime-Structured Task Decomposition for Agentic Coding Systems
Pith reviewed 2026-05-19 14:39 UTC · model grok-4.3
The pith
Runtime-structured task decomposition reduces retry costs in agentic coding systems by rerunning only failed subtasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
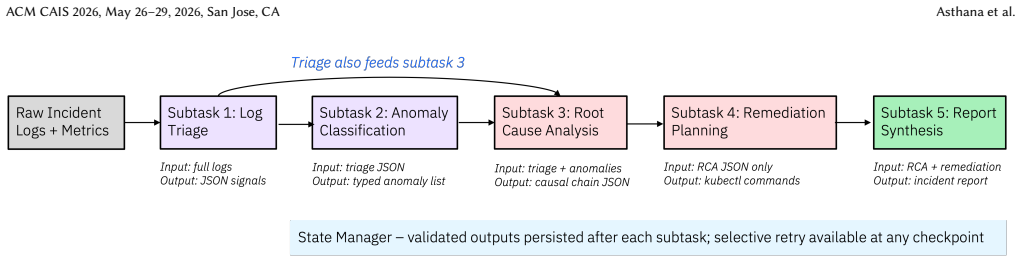
Runtime-structured task decomposition manages task partitioning and execution flow through executable control logic rather than prompt structure alone. LLMs are used only for focused judgment tasks and outputs are validated against predefined schemas before downstream execution. In the Kubernetes root cause analysis workload this reduced retry costs to 436 +/- 132 tokens and in the multi-file debugging workload to 460 tokens by rerunning only failed subtasks, achieving up to 51.7 percent lower retry cost than monolithic systems and 73.2 percent lower than static decomposition baselines.
What carries the argument
Runtime-structured task decomposition, an approach that places task partitioning and execution flow in executable control logic with schema-validated outputs so that LLMs perform only focused tasks and failures can be isolated for partial reruns.
If this is right
- Static decomposition without runtime branching increases retry costs because downstream subtasks must rerun after any upstream failure.
- The approach improves debuggability by confining error investigation to the specific failed subtask.
- Operational reliability rises because fewer tokens are spent on repeated full executions after isolated errors.
Where Pith is reading between the lines
- The same control-logic structure could be tested on agentic workflows outside coding such as automated planning or data transformation pipelines.
- Pairing the method with on-the-fly schema inference might handle cases where static schemas miss certain error types.
Load-bearing premise
Output validation against predefined schemas reliably catches errors and subtask failures stay localized enough that partial reruns suffice without cascading effects or full workflow restarts.
What would settle it
Measure retry token costs on a new workload engineered so that one subtask failure reliably triggers errors in later subtasks; if costs rise to monolithic levels the claim that localization alone drives the savings would be falsified.
Figures


read the original abstract
Agentic coding systems increasingly use large language models (LLMs) for software engineering tasks such as debugging, root cause analysis, and code review. However, many existing systems encode task logic, execution flow, and output generation inside monolithic prompts. This design creates brittle behavior, limited debuggability, and high retry costs because failures often require rerunning the full workflow. We present runtime-structured task decomposition, an architectural approach in which task partitioning and execution flow are managed through executable control logic rather than prompt structure alone. LLMs are used only for focused judgment tasks, and outputs are validated against predefined schemas before downstream execution. We evaluate this approach on two software engineering workloads using three configurations: monolithic execution, static decomposition with fixed subtasks and no runtime branching, and runtime-structured decomposition. Each configuration was evaluated across 10 runs. Our results show that decomposition alone does not necessarily reduce retry cost. In the Kubernetes root cause analysis workload, the static decomposition baseline produced a retry cost of 1,632 +/- 145 tokens versus 904 +/- 17 tokens for the monolithic baseline because failures forced reruns of downstream subtasks. A similar pattern appeared in the multi-file debugging workload, where the static baseline consumed 933 tokens compared to 703 tokens for the monolithic system. The runtime-structured approach reran only failed subtasks, reducing retry costs to 436 +/- 132 tokens for root cause analysis and 460 tokens for debugging. Overall, the approach achieved up to 51.7% lower retry cost than monolithic systems and 73.2% lower retry cost than static decomposition baselines, improving efficiency, debuggability, and operational reliability in agentic coding systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes runtime-structured task decomposition for agentic coding systems, in which task partitioning, execution flow, and output validation are handled via executable control logic rather than monolithic prompts. LLMs perform only focused judgment tasks, with outputs checked against predefined schemas to enable partial reruns of failed subtasks. The evaluation compares three configurations—monolithic execution, static decomposition, and runtime-structured decomposition—on two workloads (Kubernetes root cause analysis and multi-file debugging), each run 10 times, and reports token-cost reductions for retry scenarios.
Significance. If the reported cost reductions hold under broader conditions, the work demonstrates a practical architectural pattern that improves efficiency and debuggability in LLM-based software engineering agents. The direct empirical comparison showing static decomposition sometimes increasing retry costs (e.g., 1,632 +/- 145 tokens vs. 904 +/- 17 for monolithic in the RCA workload) while runtime-structured reduces them to 436 +/- 132 tokens provides concrete, falsifiable evidence for preferring runtime control over prompt-only or fixed-subtask designs.
major comments (2)
- [Evaluation] Evaluation section: The manuscript does not specify the exact subtask definitions, dependency graphs, or failure-injection methods used to construct the static decomposition baseline. Because the central claim attributes the static baseline's elevated retry costs to forced downstream reruns, the absence of these details makes it difficult to isolate whether the observed penalty (e.g., 933 tokens vs. 703 for monolithic in debugging) stems from the static structure itself or from unstated workload characteristics.
- [§4.3] §4.3: The claim that schema validation enables reliable partial reruns rests on the untested assumption that errors remain localized; the reported workloads do not include cases with cross-subtask side effects or validation false negatives, which would be needed to substantiate the broader reliability improvement.
minor comments (2)
- [Abstract] Abstract: The debugging workload reports a single 460-token figure without variance, unlike the RCA workload; adding standard deviation or range would improve comparability.
- [Evaluation] The manuscript would benefit from a short table summarizing per-configuration token costs, success rates, and run counts for both workloads to make the quantitative claims immediately scannable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below, agreeing where clarification is needed and outlining specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The manuscript does not specify the exact subtask definitions, dependency graphs, or failure-injection methods used to construct the static decomposition baseline. Because the central claim attributes the static baseline's elevated retry costs to forced downstream reruns, the absence of these details makes it difficult to isolate whether the observed penalty (e.g., 933 tokens vs. 703 for monolithic in debugging) stems from the static structure itself or from unstated workload characteristics.
Authors: We agree that these details are necessary to fully substantiate the comparison. In the revised manuscript, we will expand the Evaluation section to include the precise subtask definitions for both workloads, the dependency graphs and fixed execution order used in the static decomposition baseline, and the specific failure-injection methods applied during evaluation. This addition will enable readers to replicate the baseline construction and confirm that the observed retry cost increases (such as 1,632 +/- 145 tokens in RCA) arise from the lack of runtime branching rather than workload-specific artifacts. revision: yes
-
Referee: [§4.3] §4.3: The claim that schema validation enables reliable partial reruns rests on the untested assumption that errors remain localized; the reported workloads do not include cases with cross-subtask side effects or validation false negatives, which would be needed to substantiate the broader reliability improvement.
Authors: The referee is correct that the current workloads do not test cross-subtask side effects or validation false negatives, so the reliability claim in §4.3 is scoped to the observed localized-error cases. We will revise §4.3 to explicitly articulate the localization assumption, report the empirical evidence from the two workloads, and add a dedicated limitations paragraph discussing potential failure modes when side effects occur. This clarifies the scope of the contribution without extending claims beyond the evaluated conditions. revision: partial
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper reports direct empirical measurements of retry token costs across three explicitly defined configurations (monolithic, static decomposition, runtime-structured) on two workloads, each run 10 times with reported means and variances. No derivation chain, equations, fitted parameters, or predictions are present; the central efficiency claims follow immediately from the before/after cost numbers and the architectural distinction that only the runtime configuration supports partial reruns. The evaluation is self-contained against the stated baselines without reduction to self-citation or input-by-construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can perform focused judgment tasks reliably when given appropriate prompts and limited context.
- domain assumption Predefined schemas can validate outputs sufficiently to prevent error propagation and enable safe partial reruns.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
runtime-structured task decomposition... LLMs are invoked only for narrowly scoped judgment tasks with schema-validated outputs... retry costs to 436 +/- 132 tokens
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three configurations—monolithic, static decomposition... runtime-structured—over 10 runs each
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
30th USENIX Security Symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX Security Symposium (USENIX Security 21) , pages=
-
[2]
Quantifying Memorization Across Neural Language Models
Quantifying memorization across neural language models , author=. arXiv preprint arXiv:2202.07646 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Arnav Singhvi and Manish Shetty and Shangyin Tan and Christopher Potts and Koushik Sen and Matei Zaharia and Omar Khattab , year=. 2312.13382 , archivePrefix=
-
[4]
AIDev: A Large-Scale Dataset of Real-World
Daoguang Zan and others , year=. AIDev: A Large-Scale Dataset of Real-World
-
[5]
Panel: Privacy Challenges and Opportunities in \ LLM-Based \ Chatbot Applications , author=
-
[6]
Advances in Neural Information Processing Systems , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[7]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. arXiv preprint arXiv:2308.08155 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Kim, Sehoon and Moon, Suhong and Tabrizi, Rohan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir , journal =
-
[11]
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle =
-
[12]
Advances in Neural Information Processing Systems , year =
Schick, Timo and Dwivedi-Yu, Jane and Dess. Advances in Neural Information Processing Systems , year =
-
[13]
AgentBench: Evaluating LLMs as Agents
AgentBench: Evaluating LLMs as Agents , author=. arXiv preprint arXiv:2308.03688 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
GAIA: a benchmark for General AI Assistants
GAIA: A Benchmark for General AI Assistants , author=. arXiv preprint arXiv:2311.12983 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models , author=. arXiv preprint arXiv:2305.04091 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. arXiv preprint arXiv:2305.10601 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
-
[20]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Adapt: As-needed decomposition and planning with language models , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
work page 2024
-
[21]
2024 , howpublished =
work page 2024
-
[22]
arXiv preprint arXiv:2502.05352 , year=
Itbench: Evaluating ai agents across diverse real-world it automation tasks , author=. arXiv preprint arXiv:2502.05352 , year=
-
[23]
2021 IEEE International Conference on Intelligence and Security Informatics (ISI) , pages=
Automated pii extraction from social media for raising privacy awareness: A deep transfer learning approach , author=. 2021 IEEE International Conference on Intelligence and Security Informatics (ISI) , pages=. 2021 , organization=
work page 2021
-
[24]
RPii detection cognitive skill - azure cognitive search, 2022a , howpublished =. 2023 , note =
work page 2023
-
[25]
Advances in Neural Information Processing Systems , volume=
Propile: Probing privacy leakage in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
IJCAI 2001 workshop on empirical methods in artificial intelligence , volume=
An empirical study of the naive Bayes classifier , author=. IJCAI 2001 workshop on empirical methods in artificial intelligence , volume=. 2001 , organization=
work page 2001
- [27]
-
[28]
Querying wikidata: Comparing sparql, relational and graph databases , author=. The Semantic Web--ISWC 2016: 15th International Semantic Web Conference, Kobe, Japan, October 17--21, 2016, Proceedings, Part II 15 , pages=. 2016 , organization=
work page 2016
-
[29]
Review of deep learning: concepts, CNN architectures, challenges, applications, future directions , author=. Journal of big Data , volume=. 2021 , publisher=
work page 2021
-
[30]
arXiv preprint arXiv:2601.17915 , year=
Think Locally, Explain Globally: Graph-Guided LLM Investigations via Local Reasoning and Belief Propagation , author=. arXiv preprint arXiv:2601.17915 , year=
-
[31]
Support vector machine , author=. Machine learning models and algorithms for big data classification: thinking with examples for effective learning , pages=. 2016 , publisher=
work page 2016
-
[32]
Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security , pages=
Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection , author=. Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security , pages=
-
[33]
Backdooring instruction-tuned large language models with virtual prompt injection , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[34]
arXiv preprint arXiv:2305.14965 , year=
Tricking LLMs into Disobedience: Formalizing, Analyzing, and Detecting Jailbreaks , author=. arXiv preprint arXiv:2305.14965 , year=
-
[35]
Honey, i chunked the passwords: Generating semantic honeywords resistant to targeted attacks using pre-trained language models , author=. International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment , pages=. 2023 , organization=
work page 2023
- [36]
-
[37]
arXiv preprint arXiv:2307.16382 , year=
Does fine-tuning GPT-3 with the OpenAI API leak personally-identifiable information? , author=. arXiv preprint arXiv:2307.16382 , year=
-
[38]
arXiv preprint arXiv:2109.08079 , year=
Context-ner: Contextual phrase generation at scale , author=. arXiv preprint arXiv:2109.08079 , year=
-
[39]
arXiv preprint arXiv:2305.11038 , year=
Learning in-context learning for named entity recognition , author=. arXiv preprint arXiv:2305.11038 , year=
-
[40]
arXiv preprint arXiv:2404.05624 , year=
LTNER: Large Language Model Tagging for Named Entity Recognition with Contextualized Entity Marking , author=. arXiv preprint arXiv:2404.05624 , year=
-
[41]
arXiv preprint arXiv:2401.00388 , year=
FusionMind--Improving question and answering with external context fusion , author=. arXiv preprint arXiv:2401.00388 , year=
-
[42]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Alignment Precedes Fusion: Open-Vocabulary Named Entity Recognition as Context-Type Semantic Matching , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[43]
Dirt cheap web-scale parallel text from the common crawl , author=. 2013 , organization=
work page 2013
-
[44]
AWS Comprehend , howpublished =
-
[45]
NeuralSeek PII detection , howpublished =
-
[46]
Machine learning-based automatic detection and removal of personally identifiable information , author=
-
[47]
Digital information infrastructure and method for security designated data and with granular data stores , author=
-
[48]
Context aware sensitive information detection , author=
-
[49]
IBM WatsonNLP , howpublished =
-
[50]
InstructLab , howpublished =
-
[51]
Code of Conduct , howpublished =
-
[52]
arXiv preprint arXiv:2403.03329 , year=
Guardrail baselines for unlearning in llms , author=. arXiv preprint arXiv:2403.03329 , year=
-
[53]
2023 IEEE Symposium on Security and Privacy (SP) , pages=
Analyzing leakage of personally identifiable information in language models , author=. 2023 IEEE Symposium on Security and Privacy (SP) , pages=. 2023 , organization=
work page 2023
-
[54]
Kaggle dataset , howpublished =
-
[55]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. NeurIPS , year=
-
[56]
ReAct: Synergizing Reasoning and Acting in Language Models , author=. ICLR , year=
-
[57]
LangChain: Building Applications with LLMs , author=. 2024 , howpublished=
work page 2024
-
[58]
AutoGen: Enabling Next-Gen LLM Applications , author=. 2024 , howpublished=
work page 2024
-
[59]
CrewAI: Multi-Agent Orchestration Framework , author=. 2024 , howpublished=
work page 2024
-
[60]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
DSPy: Programming Language Models Instead of Prompting Them , author=. arXiv preprint arXiv:2310.03714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Guidance: Controlling Large Language Models , author=. 2024 , howpublished=
work page 2024
-
[62]
Mellea: A Generative Computing Framework for Structured LLM Programs , author=. 2025 , howpublished=
work page 2025
-
[63]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-thought prompting elicits reasoning in large language models , author=. arXiv preprint arXiv:2201.11903 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.