Judge Circuits
Pith reviewed 2026-05-20 19:26 UTC · model grok-4.3
The pith
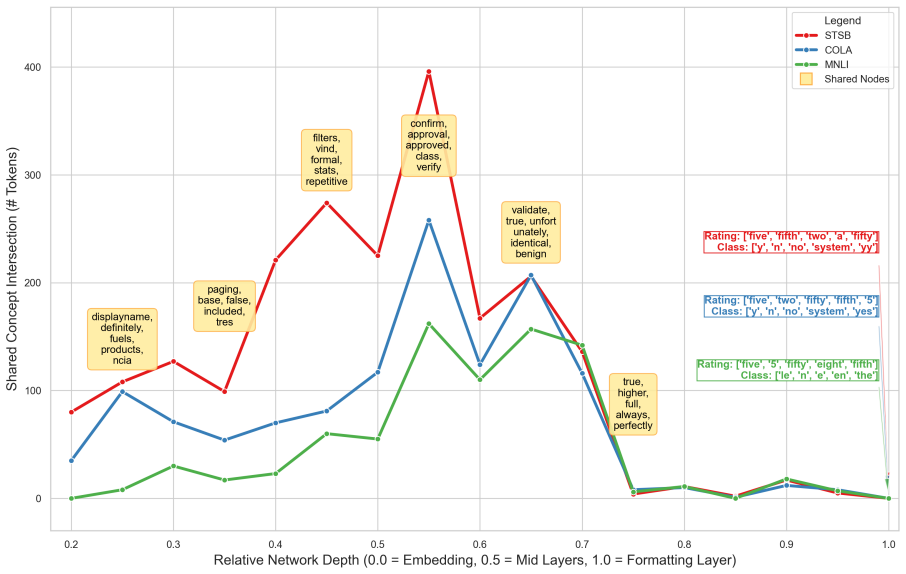
LLM judges share a sparse Latent Evaluator sub-graph in mid-to-late MLP layers that computes evaluation before format-specific output mapping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
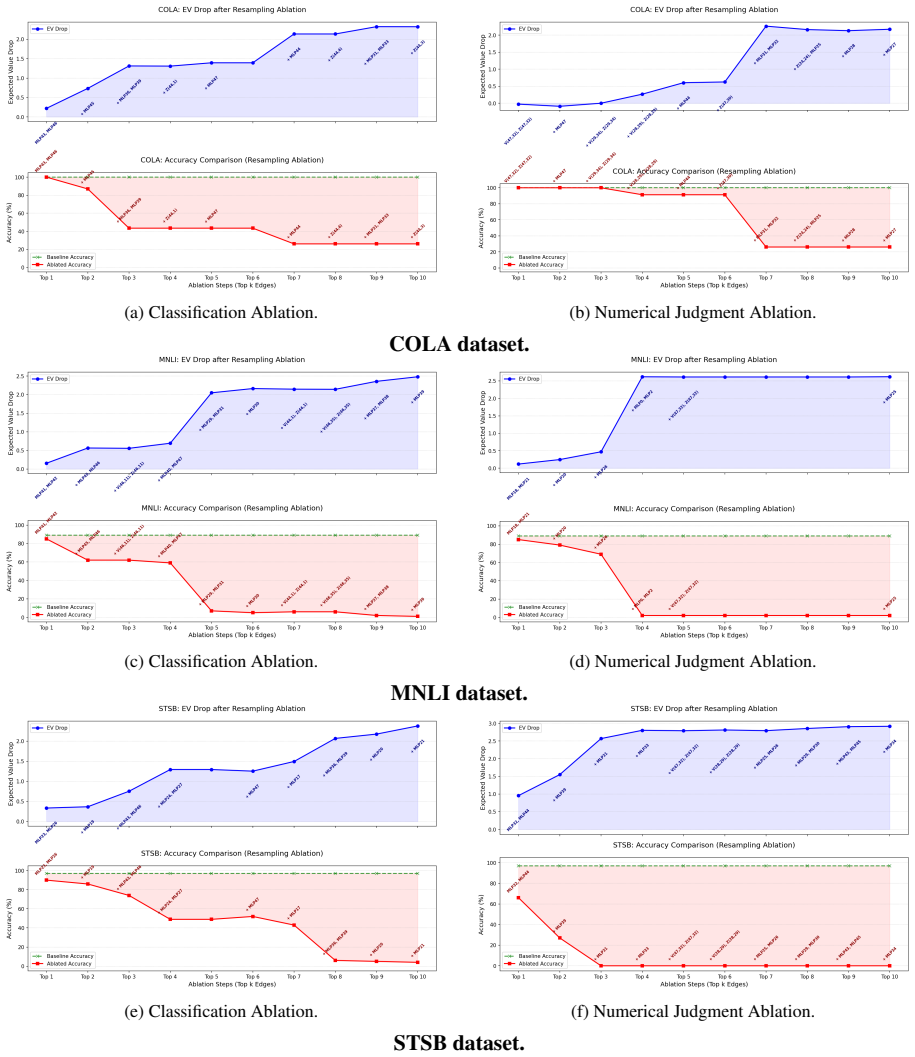
Judgments across structured understanding and open-ended preference tasks share a sparse, generalized Latent Evaluator sub-graph in the mid-to-late multi-layer perceptrons (MLPs); zero-ablating it collapses judgment while preserving world knowledge in architecturally modular models. By structurally decoupling abstract judging from output formatting, we provide a mechanistic account of format-induced inconsistency on the open-weight models we study: a continuous judgment signal computed in the shared trunk is mapped through fragile, format-specific terminal branches, enabling format-independent preference to be isolated downstream of the requested output format. Our findings imply that bench
What carries the argument
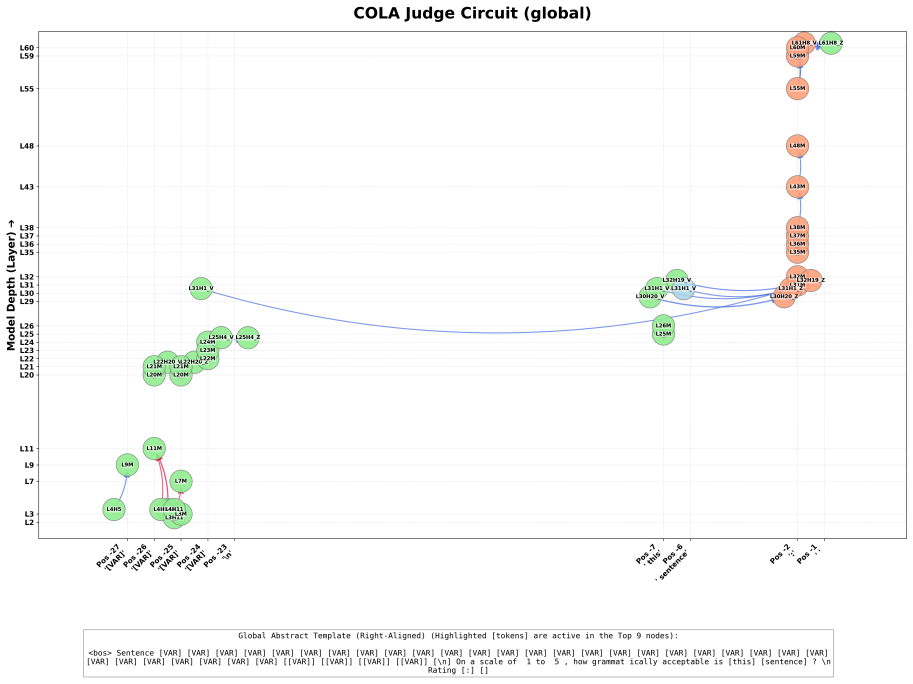
The Latent Evaluator sub-graph: a sparse collection of mid-to-late MLP connections identified by PEAP that computes a continuous judgment signal shared across task types before any output formatting occurs.
If this is right
- Format-induced score differences arise after the judgment signal is formed, from mapping it through format-specific terminal branches rather than from changes in the evaluation itself.
- Benchmark comparisons of judge reliability across output formats partly measure differences in formatter geometry instead of differences in evaluation quality.
- Format-independent preference information can be read out downstream of the requested output format once the shared judgment signal is isolated.
- In models with clear architectural modularity, factual world knowledge survives removal of the judgment sub-graph.
Where Pith is reading between the lines
- Targeted editing of the identified sub-graph could improve judgment consistency across formats without full retraining.
- The same causal patching approach might locate other functional sub-graphs that handle distinct capabilities such as reasoning or refusal.
- Judge models could be architected with an explicit shared evaluation trunk and replaceable format heads to reduce inconsistency by design.
Load-bearing premise
The PEAP intervention isolates a causally responsible sub-graph for judgment rather than a correlated or downstream effect, and the three studied models represent the broader class of decoder-only transformers used as judges.
What would settle it
Zero-ablating the identified sub-graph in an additional decoder-only model and checking whether judgment performance on both structured and preference tasks drops sharply while factual recall and non-judgment capabilities remain largely intact.
Figures


















read the original abstract
LLM-as-a-judge has become the dominant paradigm for grading model outputs at scale, yet the same model assigns systematically different scores when its output format changes (e.g., a 1-5 rating vs. a True/False label). Existing diagnoses of these format-induced inconsistencies stop at the input-output level. Using Position-aware Edge Attribution Patching (PEAP), we causally investigate the internal mechanism in Gemma-3, Qwen2.5, and Llama-3. We find that judgments across structured understanding and open-ended preference tasks share a sparse, generalized Latent Evaluator sub-graph in the mid-to-late multi-layer perceptrons (MLPs); zero-ablating it collapses judgment while preserving world knowledge in architecturally modular models. By structurally decoupling abstract judging from output formatting, we provide a mechanistic account of format-induced inconsistency on the open-weight models we study: a continuous judgment signal computed in the shared trunk is mapped through fragile, format-specific terminal branches, enabling format-independent preference to be isolated downstream of the requested output format. Our findings imply that benchmark-level reliability comparisons across formats are partially measuring formatter geometry rather than evaluation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript uses Position-aware Edge Attribution Patching (PEAP) to causally probe the internal mechanisms of LLM-as-a-judge on Gemma-3, Qwen2.5, and Llama-3. It reports a sparse, shared Latent Evaluator sub-graph in mid-to-late MLPs that supports judgments across structured understanding and open-ended preference tasks; zero-ablating this sub-graph collapses observable judgment while preserving world knowledge in modular architectures. The authors conclude that format-induced score inconsistencies arise because a continuous judgment signal computed in a shared trunk is routed through fragile, format-specific terminal branches.
Significance. If the causal isolation holds, the work supplies a mechanistic account of format sensitivity that could guide more reliable LLM judges by separating core evaluation from output formatting. The multi-model, multi-task design and emphasis on empirical interventions rather than fitted parameters are positive features that increase the potential impact within mechanistic interpretability of evaluation systems.
major comments (2)
- [Abstract] Abstract: the claim that zero-ablating the identified sub-graph removes a generalized judgment computation (rather than a downstream formatter or router) is central to the interpretation, yet the manuscript does not report controls confirming that the same ablation leaves other mid-to-late MLP behaviors intact (e.g., chain-of-thought reasoning or factual completion without an explicit judgment token). Without these controls, the distinction between upstream evaluator and correlated routing effect remains untested.
- [Abstract] Abstract / Results: the reported ablation results are described as consistent across three models and two task types, but no quantitative effect sizes, confidence intervals, or details on the total number of circuits examined before selecting the final sub-graph are provided. This information is required to assess the claimed sparsity and to evaluate selection bias in the identification of a 'generalized' circuit.
minor comments (1)
- [Abstract] Abstract: the phrase 'architecturally modular models' is used without a brief parenthetical gloss or citation clarifying which architectural properties (e.g., specific layer separation or residual-stream modularity) enable the observed preservation of world knowledge.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, acknowledging where the current manuscript can be strengthened through revision while defending the existing evidence where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that zero-ablating the identified sub-graph removes a generalized judgment computation (rather than a downstream formatter or router) is central to the interpretation, yet the manuscript does not report controls confirming that the same ablation leaves other mid-to-late MLP behaviors intact (e.g., chain-of-thought reasoning or factual completion without an explicit judgment token). Without these controls, the distinction between upstream evaluator and correlated routing effect remains untested.
Authors: We agree that additional controls would strengthen the distinction between a judgment-specific computation and a more general routing or formatting effect. The manuscript already reports that zero-ablation preserves world knowledge in modular architectures, providing evidence against a broad disruption of mid-to-late MLP function. However, this does not fully address behaviors such as chain-of-thought reasoning or factual completion without judgment tokens. In the revised manuscript we will add targeted ablation experiments on these tasks to further test specificity. revision: yes
-
Referee: [Abstract] Abstract / Results: the reported ablation results are described as consistent across three models and two task types, but no quantitative effect sizes, confidence intervals, or details on the total number of circuits examined before selecting the final sub-graph are provided. This information is required to assess the claimed sparsity and to evaluate selection bias in the identification of a 'generalized' circuit.
Authors: We acknowledge that quantitative details on effect sizes, confidence intervals, and the circuit search process would allow better evaluation of sparsity and potential selection bias. The revised manuscript will include these elements: effect sizes for judgment degradation, confidence intervals from repeated runs, and a description of the total number of candidate circuits examined along with the selection criteria applied. revision: yes
Circularity Check
No circularity: empirical causal interventions on external models
full rationale
The paper applies Position-aware Edge Attribution Patching (PEAP) as an intervention method to pre-trained external models (Gemma-3, Qwen2.5, Llama-3) to locate a sparse sub-graph in mid-to-late MLPs. Zero-ablation is reported to collapse judgment scores while preserving world knowledge, with the account framed as a structural decoupling of judging from formatting. No equations, fitted parameters, or self-citations are shown to reduce the central claim to the paper's own inputs by construction; the interventions operate on fixed model weights without self-referential fitting loops or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PEAP correctly identifies causally relevant edges for the judgment behavior
invented entities (1)
-
Latent Evaluator sub-graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reference-free rating of llm responses via latent information.arXiv, abs/2509.24678. Elena Golimblevskaia, Aakriti Jain, Bruno Puri, Ammar Ibrahim, Wojciech Samek, and Sebastian Lapuschkin
-
[2]
Circuit insights: Towards interpretability be- yond activations. InThe Fourteenth International Conference on Learning Representations. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models.arXiv, abs/240...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov
Are formal and functional linguistic mecha- nisms dissociated in language models?Computa- tional Linguistics, pages 1–41. Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov
-
[4]
In First Conference on Language Modeling
Have faith in faithfulness: Going beyond cir- cuit overlap when finding model mechanisms. In First Conference on Language Modeling. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
-
[5]
InInternational Conference on Learning Representations
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Farnoush Rezaei Jafari, Oliver Eberle, Ashkan Khakzar, and Neel Nanda. 2025. Relp: Faithful and efficient circuit discovery in language models via relevance patching.arXiv, abs/2508.21258. 10 Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ M...
-
[6]
InFirst Conference on Language Modeling
Uncovering intermediate variables in trans- formers using circuit probing. InFirst Conference on Language Modeling. Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yu- jia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu
-
[7]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: A comprehensive sur- vey on llm-based evaluation methods.Preprint, arXiv:2412.05579. Maxime Méloux, Silviu Maniu, François Portet, and Maxime Peyrard. 2025. Everything, everywhere, all at once: Is mechanistic interpretability identifiable? InThe Thirteenth International Conference on Learn- ing Representations. Jack Merullo, Carsten Eickho...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Transformer circuit evaluation metrics are not robust. InFirst Conference on Language Modeling. Aaron Mueller, Jannik Brinkmann, Millicent Li, Samuel Marks, Koyena Pal, Nikhil Prakash, Can Rager, Aruna Sankaranarayanan, Arnab Sen Sharma, Jiud- ing Sun, Eric Todd, David Bau, and Yonatan Be- linkov. 2026. The quest for the right mediator: Sur- veying mechan...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
A broad-coverage challenge corpus for sen- tence understanding through inference. InProceed- ings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122, New Orleans, Louisiana. Association for Computational Linguis- tics. Zhengxuan Wu, A...
-
[10]
CoLA_CLASS:...Is this sentence grammati- cally acceptable? Answer: 2.MNLI_CLASS:...The relationship is:
-
[11]
STS-B_CLASS:...Are these sentences seman- tically similar? Answer:
-
[12]
RewardBench_CLASS:...Is this response helpful and aligned? Answer:
-
[13]
Yelp_CLASS:...Is this review positive? An- swer: The selection spans meaningfully different label structures – binary (CoLA), three-class (MNLI), ordinal (STS-B,Y elp), and pairwise preference (RewardBench) – and this heterogeneity is essen- tial to the cross-task overlap claim in §3.2: a shared computational trunk that recurs across distinct label spaces...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.