Vision Transformer-Conditioned UNet for Domain-Adaptive Semantic Segmentation
Pith reviewed 2026-05-20 22:38 UTC · model grok-4.3
The pith
ViTC-UNet conditions a UNet on frozen Vision Transformer features through learnable tokens and two-way attention to improve biomedical semantic segmentation without retraining the transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViTC-UNet conditions a UNet on frozen pre-trained ViT representations through learnable tokens and a two-way attention decoder. This combines ViT global visual priors with the local inductive bias and high-resolution decoding capacity of UNets, while avoiding end-to-end ViT fine-tuning even in cross-domain settings.
What carries the argument
ViTC-UNet, a decoder that routes frozen ViT features into a UNet via learnable tokens and two-way attention to generate high-precision biomedical masks.
If this is right
- The method yields higher segmentation accuracy than baseline UNet and ViT decoders on MRI and CT data.
- Large-scale visual priors from ViTs can be reused across imaging modalities without retraining the transformer backbone.
- High-resolution local decoding remains available even when the source model stays frozen.
- Cross-domain adaptation becomes feasible with lower compute cost than full fine-tuning.
Where Pith is reading between the lines
- The same conditioning pattern could be tested on other dense tasks such as instance segmentation or depth estimation in medical volumes.
- Freezing the ViT opens a route to deploy large vision models on modest clinical hardware while still benefiting from their priors.
- Extending the two-way attention to multiple frozen ViT layers might further strengthen the transfer of mid-level features.
Load-bearing premise
Lightweight ViT pixel decoders lack enough local bias for precise medical masks, and learnable tokens plus two-way attention can transfer useful global priors from a frozen ViT without any end-to-end retraining.
What would settle it
A controlled experiment on the same MRI and CT test sets in which a plain UNet or an end-to-end fine-tuned ViT decoder matches or exceeds ViTC-UNet accuracy when the conditioning tokens and two-way attention are removed.
Figures












read the original abstract
Semantic segmentation is essential for analysing anatomical features in biomedical research, yet a performance gap remains for Vision Transformers (ViTs) in the field, particularly for sparse, fine-structured, and low signal-to-noise targets. We attribute this challenge in part to the lightweight pixel decoders commonly used in promptable ViT models, who may lack the local inductive bias needed for high-precision biomedical masks. We bridge this gap by introducing ViTC-UNet, which conditions a UNet on frozen pre-trained ViT representations through learnable tokens and a two-way attention decoder. This combines ViT global visual priors with the local inductive bias and high-resolution decoding capacity of UNets, while avoiding end-to-end ViT fine-tuning even in cross-domain settings. ViTC-UNet outperforms baseline results in semantic segmentation tasks across MRI and CT modalities, demonstrating that structure-conditioned UNet decoding can efficiently adapt large-scale visual priors to high-complexity biomedical segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ViTC-UNet, an architecture that conditions a UNet-style decoder on frozen pre-trained Vision Transformer (ViT) features via learnable tokens and two-way attention. This design aims to combine ViT global visual priors with UNet's local inductive bias and high-resolution decoding for semantic segmentation of sparse, fine-structured targets in biomedical MRI and CT images, while avoiding end-to-end ViT fine-tuning in cross-domain settings. The central claim is that this yields higher Dice scores than baselines on the evaluated tasks.
Significance. If the empirical results hold, the work offers a practical route to transfer large-scale visual priors from ViTs to high-complexity biomedical segmentation without the cost of ViT retraining. The approach is internally consistent, with ablations on the token and attention components supporting the design choices, and cross-domain results reported without evident contradictions.
minor comments (2)
- The abstract claims outperformance on MRI and CT tasks but the results section would benefit from explicit reporting of dataset sizes, number of runs, and standard deviations alongside the Dice scores to strengthen reproducibility.
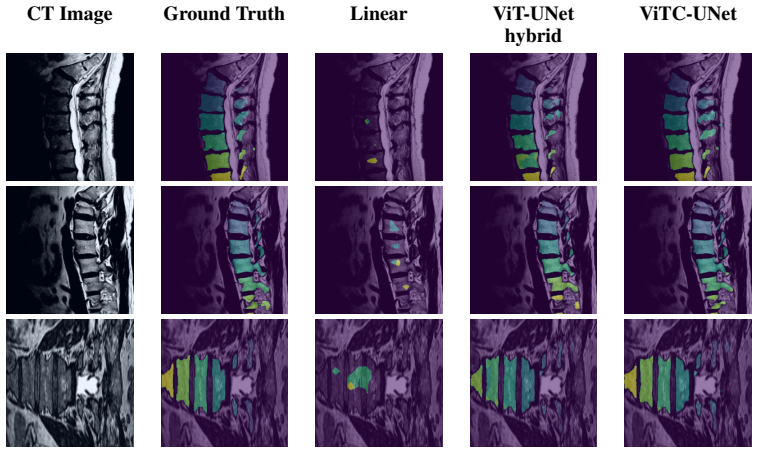
- Figure 3 (qualitative results) could include error maps or failure cases to better illustrate where the structure-conditioned decoding improves over baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The review correctly identifies the core contribution of conditioning a UNet decoder on frozen ViT features via learnable tokens and two-way attention to improve biomedical segmentation without full ViT fine-tuning.
Circularity Check
No significant circularity
full rationale
The paper introduces ViTC-UNet as an architectural combination of frozen ViT representations with a UNet decoder via learnable tokens and two-way attention, evaluated empirically on MRI and CT segmentation tasks. No equations, derivations, or first-principles predictions are present that could reduce to fitted inputs or self-referential definitions. Claims rest on reported Dice score improvements and ablations rather than any load-bearing self-citation chain or ansatz smuggled through prior work. The method is self-contained as a practical design proposal with independent empirical support.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable tokens
axioms (1)
- domain assumption Frozen pre-trained ViT representations provide useful global visual priors that can be effectively transferred to biomedical segmentation via conditioning.
invented entities (1)
-
ViTC-UNet
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ViTC-UNet injects target-specific ViT guidance into the inherently multi-scale reconstruction path of a UNet... two-way attention decoder progressively transforms the frozen ViT embedding into a sequence of target-conditioned latent states... homeomorphic transformations... continuous evolution of the image representation tracing a curve in the latent space
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The conditioning decoder... MLP followed by a series of modified two-way attention blocks... structure token... bidirectional cross-attention
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Afridi, S. et al. (2026) ‘3D-VIT-unet: 3D Vision Transformer based unet-like model for volumet- ric brain tumor segmentation’, PLOS Digital Health, 5(3). doi:10.1371/journal.pdig.0001323
-
[2]
Antonelli, M., Reinke, A., Bakas, S. et al. The Medical Segmentation Decathlon. Nat Commun 13, 4128 (2022). https://doi.org/10.1038/s41467-022-30695-9
-
[3]
Archit, A. et al. (2025) ‘Segment anything for Microscopy’, Nature Methods, 22(3), pp. 579–591. doi:10.1038/s41592-024-02580-4
-
[4]
(2017) SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Badrinarayanan,V ., et al. (2017) SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12), 2481-2495
work page 2017
-
[5]
U.Baid, et al., "The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmen- tation and Radiogenomic Classification", arXiv:2107.02314, 2021(opens in a new window)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J.S. Kirby, et al., "Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features", Nature Scientific Data, 4:170117 (2017) DOI: 10.1038/sdata.2017.117
-
[7]
Carion, N. et al. (2025) SAM 3: Segment Anything with Concepts. arXiv. https://arxiv.org/abs/2511.16719
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
https://arxiv.org/abs/2112.01527
Cheng, B., et al. (2021) Masked-attention Mask Transformer for Universal Image Segmentation. arXiv. arXiv:2112.01527
-
[9]
Chi, W. et al. (2020) ‘Deep learning-based medical image segmentation with limited labels’, Physics in Medicine & Biology, 65(23), p. 235001. doi:10.1088/1361-6560/abc363
-
[10]
(2026) Bi-Orthogonal Factor Decomposition for Vision Transformers
Doshi, F.R, et al. (2026) Bi-Orthogonal Factor Decomposition for Vision Transformers. arXiv. arXiv:2601.05328
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Fedorov, A; Schwier, M; Clunie, D; Herz, C; Pieper, S; Kikinis, R; Tempany, C; Fennessy, F. (2018). Data From QIN-PROSTATE-Repeatability. The Cancer Imaging Archive. DOI: 10.7937/K9/TCIA.2018.MR1CKGND
-
[13]
TAC-UNet: transformer-assisted convolu- tional neural network for medical image segmentation
He J, Ma Y , Yang M, Yang W, Wu C, Chen S. TAC-UNet: transformer-assisted convolu- tional neural network for medical image segmentation. Quant Imaging Med Surg. 2024 Dec 5;14(12):8824-8839. doi: 10.21037/qims-24-1229. Epub 2024 Nov 5. PMID: 39698603; PM- CID: PMC11651933
-
[14]
Hernandez Petzsche, M.R., de la Rosa, E., Hanning, U. et al. ISLES 2022: A multi-center magnetic resonance imaging stroke lesion segmentation dataset. Sci Data 9, 762 (2022). https://doi.org/10.1038/s41597-022-01875-5
-
[15]
Isensee, F. et al. (2024) ‘NNU-Net Revisited: A Call for rigorous validation in 3D medical image segmentation’, Lecture Notes in Computer Science, pp. 488–498. doi:10.1007/978-3- 031-72114-4_47
-
[16]
Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods, 18(2), 203-211
work page 2021
-
[17]
(2020) nnU-Net for Brain Tumor Segmentation
Isensee, F., et al. (2020) nnU-Net for Brain Tumor Segmentation. arXiv. arXiv:2011.00848 10
-
[18]
(2022) Extending nnU-Net is all you need
Isensee, F., et al. (2022) Extending nnU-Net is all you need. arXiv. arXiv:2208.10791
-
[19]
(2019) ‘CHAOS - Combined (CT-MR) Healthy Abdominal Organ Segmentation Challenge Data’
Kavur, A., et al. (2019) ‘CHAOS - Combined (CT-MR) Healthy Abdominal Organ Segmentation Challenge Data’. The IEEE International Symposium on Biomedical Imaging (ISBI), Zenodo. doi:10.5281/zenodo.3431873
-
[20]
Kavur, A.E. et al. (2021) ‘Chaos challenge - combined (CT-MR) healthy abdominal organ segmentation’, Medical Image Analysis, 69, p. 101950. doi:10.1016/j.media.2020.101950
-
[21]
Kirillov, A., Mintun, E., Ravi N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A., Lo, W., Dollár, P., Girshick, R.: Segment Anything. arXiv (2023) arXiv:2304.02643
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [22]
-
[23]
Lamm, L. et al. (2024) MemBrain V2: An end-to-end tool for the analysis of membranes in cryo-electron tomography [Preprint]. doi:10.1101/2024.01.05.574336
-
[24]
Last, M.G., V oortman, L.M. and Sharp, T.H. (2025) Scaling data analyses in cellular cryoET using comprehensive segmentation [Preprint]. doi:10.1101/2025.01.16.633326
-
[25]
Li, F. et al. (2022) ‘Segmentation of human aorta using 3D NNU-net-oriented deep learning’, Review of Scientific Instruments, 93(11). doi:10.1063/5.0084433
-
[26]
Li, L. et al. (2023) ‘MyoPS: A benchmark of myocardial pathology segmentation combining three-sequence cardiac magnetic resonance images’, Medical Image Analysis, 87, p. 102808. doi:10.1016/j.media.2023.102808
-
[27]
(2025) ’Few-Shot Deployment of Pretrained MRI Transformers in Brain Imaging Tasks’
Li, M., et al. (2025) ’Few-Shot Deployment of Pretrained MRI Transformers in Brain Imaging Tasks’. arXiv. arXiv:2508.05783
-
[28]
Li, X., et al. (2025) ‘Evit-UNET: U-net like efficient vision transformer for medical image segmentation on mobile and Edge Devices’, 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI), pp. 1–5. doi:10.1109/isbi60581.2025.10981108
-
[29]
(2017) Focal loss for dense object detection
Lin, T., et al. (2017) Focal loss for dense object detection. ICCV
work page 2017
-
[30]
(2025) Unified Open-World Segmentation with Multi-Modal Prompts
Liu, Y ., et al. (2025) Unified Open-World Segmentation with Multi-Modal Prompts. ICCV . arXiv:2510.10524
-
[31]
(2015) Fully Convolutional Networks for Semantic Segmentation
Long, J. (2015) Fully Convolutional Networks for Semantic Segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3431-3440
work page 2015
-
[32]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. ICLR (2019)
work page 2019
-
[33]
(2022) AbdomenCT-1K: Is Abdominal Organ Segmentation a Solved Problem?
Ma, J., et al. (2022) AbdomenCT-1K: Is Abdominal Organ Segmentation a Solved Problem?. IEEE Transactions on Pattern Analysis and Machine Intelligence. 10.1109/TPAMI.2021.3100536
-
[34]
Ma, J. et al. (2021) ‘Toward data-efficient learning: A benchmark for Covid-19 CT Lung and infection segmentation’, Medical Physics, 48(3), pp. 1197–1210. doi:10.1002/mp.14676
-
[35]
Ma, J. et al. (2024) ‘Segment anything in Medical Images’, Nature Communications, 15(1). doi:10.1038/s41467-024-44824-z
- [36]
-
[37]
(2023) Pretrained ViTs Yield Versatile Representations For Medical Images
Matsoukas, C., et al. (2023) Pretrained ViTs Yield Versatile Representations For Medical Images. arXiv. arXiv:2303.07034
-
[38]
(2024) LVS-Net: A Lightweight Vessels Segmentation Network for Retinal Image Analysis
Mehmood, M. (2024) LVS-Net: A Lightweight Vessels Segmentation Network for Retinal Image Analysis. arXiv. arXiv:2412.05968v1 11
-
[39]
Menze, B.H. et al. (2015) ‘The Multimodal Brain Tumor Image Segmentation Benchmark (brats)’, IEEE Transactions on Medical Imaging, 34(10), pp. 1993–2024. doi:10.1109/tmi.2014.2377694
-
[40]
(2016) V-Net:Fully convolutional neural networks for volumetric medical image segmentation
Milletari, F., et al. (2016) V-Net:Fully convolutional neural networks for volumetric medical image segmentation. 3DV
work page 2016
-
[41]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Pal, D. et al. (2025) ‘Pannet: A feature-based attention aggregation model for segmenting pancreatic ductal adenocarcinoma on contrast-enhanced CT images of the abdomen’, Medical Imaging 2025: Computer-Aided Diagnosis, p. 63. doi:10.1117/12.3048971
-
[43]
Payer, T. et al. (2023) ‘Medical volume segmentation by overfitting sparsely annotated data’, Journal of Medical Imaging, 10(04). doi:10.1117/1.jmi.10.4.044007
-
[44]
Podobnik, G. et al. (2023) ‘Han-Seg: The head and neck organ-at-risk CT and mr segmentation dataset’, Medical Physics, 50(3), pp. 1917–1927. doi:10.1002/mp.16197
-
[45]
Radl, Lukas; Jin, Yuan; Pepe, Antonio; Li, Jianning; Gsaxner, Christina; Zhao, Fen-hua; et al. (2022). Aortic Vessel Tree (A VT) CTA Datasets and Segmentations. figshare. Dataset. https://doi.org/10.6084/m9.figshare.14806362.v1
-
[46]
SAM 2: Segment Anything in Images and Videos
Ravi, N., et al. (2024) SAM 2: Segment Anything in Images and Videos. arXiv. https://arxiv.org/abs/2408.00714
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Walk in the cloud: Learning curves for point clouds shape analysis, pp
Ranftl, R., Bochkovskiy, A. and Koltun, V . (2021) Vision Transformers for dense prediction, 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 12159–12168. doi:10.1109/iccv48922.2021.01196
-
[48]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Ronneberger, O. (2015) U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv. arXiv:1505.04597
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
de la Rosa, E., Reyes, M., Liew, SL. et al. DeepISLES: a clinically validated ischemic stroke segmentation model from the ISLES’22 challenge. Nat Commun 16, 7357 (2025). https://doi.org/10.1038/s41467-025-62373-x
-
[50]
Sablayrolles A., Douze M., Schmid C., and Jégou H.: Spreading vectors for similarity search. ICLR (2019)
work page 2019
-
[51]
Sang, Y . et al. (2025) Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge. arXiv. arXiv:2504.02382
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Soh WK and Rajapakse JC (2023) Hybrid UNet transformer architecture for ischemic stoke segmentation with MRI and CT datasets. Front. Neurosci. 17:1298514. doi: 10.3389/fnins.2023.1298514
-
[53]
Støverud, K.-H. et al. (2024) ‘AeroPath: An airway segmentation benchmark dataset with challenging pathology and Baseline Method’, PLOS ONE, 19(10). doi:10.1371/journal.pone.0311416
-
[54]
(2025) Randomized-MLP Regularization Improves Domain Adaptation and Interpretability in DINOv2
Valdivia Ortega, J., et al. (2025) Randomized-MLP Regularization Improves Domain Adaptation and Interpretability in DINOv2. NeurIPS. arXiv:2511.05509
-
[55]
van der Graaf, J.W., van Hooff, M.L., Buckens, C.F.M. et al. Lumbar spine segmen- tation in MR images: a dataset and a public benchmark. Sci Data 11, 264 (2024). https://doi.org/10.1038/s41597-024-03090-w
-
[56]
(2023) ‘SPIDER - Lumbar spine segmentation in MR images: a dataset and a public benchmark’
van der Graaf, J., et al. (2023) ‘SPIDER - Lumbar spine segmentation in MR images: a dataset and a public benchmark’. Zenodo. doi:10.5281/zenodo.10159290
-
[57]
(2023) ‘Dataset with segmentations of 117 important anatomical structures in 1228 CT images’
Wasserthal, J. (2023) ‘Dataset with segmentations of 117 important anatomical structures in 1228 CT images’. Zenodo. doi:10.5281/zenodo.10047292. 12
-
[58]
Wasserthal, J. et al. (2023) ‘TotalSegmentator: Robust segmentation of 104 anatomic structures in CT images’, Radiology: Artificial Intelligence, 5(5). doi:10.1148/ryai.230024
-
[59]
Wei, M., et al. (2024) ’Enhancing surgical instrument segmentation: integrating vision trans- former insights with adapter’ Int J Comput Assist Radiol Surg. 10.1007/s11548-024-03140-z
-
[60]
Xu, Q. et al. (2026) ‘Robust multi-domain digital pathology image segmentation via joint balancing representation learning’, Expert Systems with Applications, 320, p. 132093. doi:10.1016/j.eswa.2026.132093
-
[61]
(2022) AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Yuanfeng, J., et al. (2022) AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation. arXiv. arXiv:2206.08023
-
[62]
Zhao, T. et al. (2024) ‘A Foundation model for joint segmentation, detection and recogni- tion of biomedical objects across nine modalities’, Nature Methods, 22(1), pp. 166–176. doi:10.1038/s41592-024-02499-w
-
[63]
Zhu, Q., Du, B. and Yan, P. (2020) ‘Boundary-weighted domain adaptive neural network for prostate mr image segmentation’, IEEE Transactions on Medical Imaging, 39(3), pp. 753–763. doi:10.1109/tmi.2019.2935018. 13 A Technical Appendices and Supplementary Material A.1 Licenses The datasets used in this paper where obtained as part of the compilation made by...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.