3DPhysVideo: Consistency-Guided Flow SDE for Video Generation via 3D Scene Reconstruction and Physical Simulation
Pith reviewed 2026-05-19 21:22 UTC · model grok-4.3
The pith
A training-free pipeline turns a single image into a physically realistic video by reconstructing 3D scenes and guiding generation with physics simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
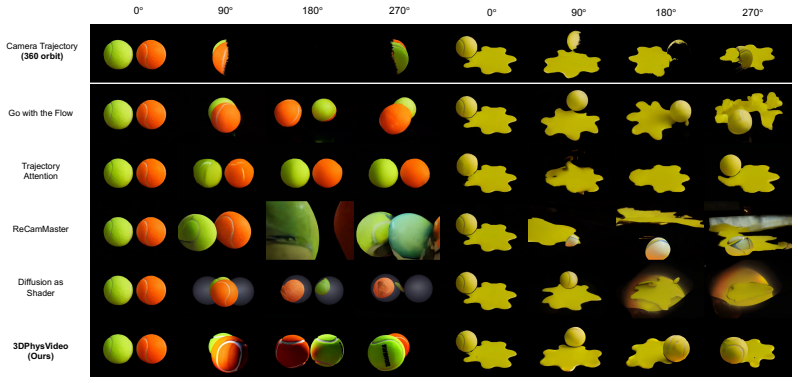
The central claim is that an off-the-shelf image-to-video flow model can be repurposed for both 3D scene reconstruction via rendered point cloud guidance and for physically simulated point cloud-guided video synthesis without fine-tuning, with Consistency-Guided Flow SDE enforcing consistency by decomposing the predicted velocity into denoising and consistency bias components.
What carries the argument
Consistency-Guided Flow SDE, which decomposes the predicted velocity of the I2V flow model into denoising and consistency bias to enforce consistency with conditional inputs such as rendered or simulated point clouds.
If this is right
- The approach generates videos that respect physical dynamics in scenes involving multiple objects and fluid interactions.
- The pipeline runs efficiently on a single consumer GPU.
- Generated videos score higher than state-of-the-art baselines on GPT-based metrics, the VideoPhy benchmark, and human evaluations.
Where Pith is reading between the lines
- The same guidance technique might be tested on extending short clips into longer sequences by repeatedly applying physics steps.
- Similar repurposing of flow models could be explored for other conditional generation tasks that require geometric or physical fidelity.
- Integrating more detailed physics engines could address edge cases like deformable objects or complex lighting changes during motion.
Load-bearing premise
The off-the-shelf image-to-video flow model can be effectively repurposed for both 3D scene reconstruction via point cloud guidance and final video synthesis via physically simulated point cloud guidance without any fine-tuning or additional training.
What would settle it
A direct test would check whether output videos of fluid-object interactions or multi-body collisions exhibit clear physical violations, such as incorrect fluid flow trajectories or interpenetrating objects, when compared against ground-truth physics simulation.
Figures


























read the original abstract
Video generative models have made remarkable progress, yet they often yield visual artifacts that violate grounding in physical dynamics. Recent works such as PhysGen3D tackle single image-to-3D physics through mesh reconstruction and Physically-Based Rendering, but challenges remain in modeling fluid dynamics, multi-object interactions and photorealism. This work introduces 3DPhysVideo, a novel training-free pipeline that generates physically realistic videos from a single image. We repurpose an off-the-shelf video model for two stages. First, we use it as a novel view synthesizer to reconstruct complete 360-degree 3D scene geometry by guiding the image-to-video (I2V) flow model with rendered point clouds. Second, after applying physics solvers to this geometry, the physically simulated point cloud is used to guide the same I2V flow model to synthesize final, high-quality videos. Consistency-Guided Flow SDE, which decomposes the predicted velocity of the I2V flow model into denoising and consistency bias, enforces consistency to the conditional inputs, allowing us to effectively repurpose the model for both 3D reconstruction and simulation-guided video generation. In the diverse experiments including multi-objects, and fluid interaction scenes, our method successfully bridges the gap from single-images to physically plausible videos, while remaining efficient to run on a single consumer GPU. It outperforms state-of-the-art baselines on GPT-based scores, VideoPhy benchmark and human evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents 3DPhysVideo, a novel training-free pipeline that generates physically realistic videos from a single image. It repurposes an off-the-shelf image-to-video flow model in two stages: first as a novel-view synthesizer guided by rendered point clouds to reconstruct complete 360-degree 3D scene geometry, and second to synthesize the final video guided by point clouds from an external physics solver applied to the reconstructed geometry. The key technical component is the Consistency-Guided Flow SDE, which decomposes the model's predicted velocity into a denoising term plus a consistency bias to enforce fidelity to the conditional point-cloud inputs in both stages. Experiments on multi-object and fluid-interaction scenes claim that the method produces physically plausible videos, runs efficiently on a single consumer GPU, and outperforms baselines on GPT-based scores, the VideoPhy benchmark, and human evaluation.
Significance. If the central claims hold, the work would be a useful contribution to video generation by demonstrating how existing pretrained flow models can be repurposed, without fine-tuning, to incorporate explicit 3D reconstruction and physics simulation for improved physical grounding. The training-free design, single-GPU efficiency, and handling of fluids and multi-object interactions address recognized limitations in current generative models. The use of standard physics solvers and point-cloud guidance is a pragmatic strength that could be adopted more broadly if the consistency mechanism proves reliable.
major comments (2)
- The manuscript provides no quantitative evaluation or ablation of the strength of the consistency bias term relative to the model's prior when the I2V flow model is conditioned on physics-simulated point clouds (see description of Consistency-Guided Flow SDE). Without such analysis it is unclear whether the bias reliably transfers physical trajectories or whether generated frames achieve only visual coherence while violating dynamics, particularly for fluids and collisions; this directly affects the central claim that the same off-the-shelf model can be successfully repurposed for both reconstruction and simulation-guided synthesis.
- No independent metrics (e.g., reconstruction error, multi-view consistency, or Chamfer distance) are reported for the accuracy of the 360-degree geometry obtained in the first stage by guiding the flow model with rendered point clouds. Because this geometry is the input to the subsequent physics solver, the absence of verification undermines confidence that downstream video dynamics match the intended physical simulation.
minor comments (2)
- The abstract refers to 'GPT-based scores' without defining the prompt, model, or exact metric used; this should be clarified in the experiments section for reproducibility.
- Explicit equations for the velocity decomposition (denoising term plus consistency bias) would improve clarity and allow readers to assess the claimed parameter-free nature of the guidance.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, indicating where we agree and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The manuscript provides no quantitative evaluation or ablation of the strength of the consistency bias term relative to the model's prior when the I2V flow model is conditioned on physics-simulated point clouds (see description of Consistency-Guided Flow SDE). Without such analysis it is unclear whether the bias reliably transfers physical trajectories or whether generated frames achieve only visual coherence while violating dynamics, particularly for fluids and collisions; this directly affects the central claim that the same off-the-shelf model can be successfully repurposed for both reconstruction and simulation-guided synthesis.
Authors: We agree that an explicit quantitative ablation of the consistency bias strength would strengthen the central claim. In the revised manuscript we will add an ablation that varies the bias weighting hyperparameter and reports VideoPhy benchmark scores together with targeted qualitative checks on trajectory fidelity for fluid and multi-object collision cases. This will directly quantify how the bias term modulates the model's prior. revision: yes
-
Referee: No independent metrics (e.g., reconstruction error, multi-view consistency, or Chamfer distance) are reported for the accuracy of the 360-degree geometry obtained in the first stage by guiding the flow model with rendered point clouds. Because this geometry is the input to the subsequent physics solver, the absence of verification undermines confidence that downstream video dynamics match the intended physical simulation.
Authors: We acknowledge the value of direct verification for the intermediate 3D reconstruction. While downstream video quality and human evaluations provide indirect support, we will incorporate additional quantitative checks in the revision, including multi-view consistency scores and Chamfer distance where reference geometry or proxy measures are available from the evaluation scenes. revision: yes
Circularity Check
No circularity: pipeline uses external off-the-shelf I2V model and standard physics solver with independent guidance mechanism
full rationale
The derivation chain relies on repurposing a pretrained image-to-video flow model (external) for point-cloud-guided reconstruction and then physics-simulated guidance, with Consistency-Guided Flow SDE presented as a decomposition of the model's existing velocity prediction into denoising plus consistency bias. No parameter is fitted to the target video output, no self-citation chain justifies the core uniqueness or ansatz, and the physics solver operates independently of the generative model. The method is therefore self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An off-the-shelf image-to-video flow model can be guided by rendered point clouds to reconstruct complete 360-degree 3D scene geometry without training.
- domain assumption Physics solvers applied to the reconstructed geometry produce point clouds that, when used to guide the same flow model, yield high-quality and physically plausible videos.
invented entities (1)
-
Consistency-Guided Flow SDE
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Consistency-Guided Flow SDE, which decomposes the predicted velocity of the I2V flow model into denoising and consistency bias
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
p∗ = arg maxp Ezτ∼p [C(zτ,zI)] − 1/β DKL(p∥q)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Genesis: A generative and universal physics engine for robotics and beyond, December 2024
Genesis Authors. Genesis: A generative and universal physics engine for robotics and beyond, December 2024. URLhttps://github.com/Genesis-Embodied-AI/Genesis
work page 2024
-
[2]
Recammaster: Camera-controlled generative rendering from a single video.ICCV, 2025
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video.ICCV, 2025
work page 2025
-
[3]
Videophy: Evaluating physical commonsense for video generation.arXiv, 2024
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv, 2024
work page 2024
-
[4]
Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv, 2023
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv, 2023
work page 2023
-
[5]
Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, Michael Ryoo, Paul Debevec, and Ning Yu. Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. In CVPR, 2025
work page 2025
-
[6]
Gic: Gaussian-informed continuum for physical property identification and simulation.NeurIPS, 2024
Junhao Cai, Yuji Yang, Weihao Yuan, Yisheng He, Zilong Dong, Liefeng Bo, Hui Cheng, and Qifeng Chen. Gic: Gaussian-informed continuum for physical property identification and simulation.NeurIPS, 2024
work page 2024
-
[7]
Physgen3d: Crafting a miniature interactive world from a single image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. Physgen3d: Crafting a miniature interactive world from a single image. InCVPR, 2025
work page 2025
-
[8]
Partgen: Part-level 3d generation and reconstruction with multi-view diffusion models
Minghao Chen, Roman Shapovalov, Iro Laina, Tom Monnier, Jianyuan Wang, David Novotny, and Andrea Vedaldi. Partgen: Part-level 3d generation and reconstruction with multi-view diffusion models. InCVPR, 2025
work page 2025
-
[9]
Motion-conditioned diffusion model for controllable video synthesis.arXiv, 2023
Tsai-Shien Chen, Chieh Hubert Lin, Hung-Yu Tseng, Tsung-Yi Lin, and Ming-Hsuan Yang. Motion-conditioned diffusion model for controllable video synthesis.arXiv, 2023
work page 2023
-
[10]
Veo 3.https://deepmind.google/models/veo/, 2025
DeepMind / Google. Veo 3.https://deepmind.google/models/veo/, 2025
work page 2025
-
[11]
Martin A. Fischler and Robert C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 1981
work page 1981
-
[12]
Physical simulator in-the-loop video generation.CVPR, 2026
Lin Geng Foo, Mark He Huang, Alexandros Lattas, Stylianos Moschoglou, Thabo Beeler, and Christian Theobalt. Physical simulator in-the-loop video generation.CVPR, 2026
work page 2026
-
[13]
Motion prompting: Controlling video generation with motion trajectories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Chen Sun, et al. Motion prompting: Controlling video generation with motion trajectories. InCVPR, 2025
work page 2025
-
[14]
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force prompting: Video generation models can learn and generalize physics-based control signals.NeurIPS, 2025
work page 2025
-
[15]
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, and Yuan Liu. Diffusion as shader: 3d-aware video diffusion for versatile video generation control.SIGGRAPH 2025, 2025
work page 2025
-
[16]
Cameractrl: Enabling camera control for text-to-video generation.ICLR, 2025
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.ICLR, 2025
work page 2025
-
[17]
Dreamphysics: Learning physics-based 3d dynamics with video diffusion priors
Tianyu Huang, Haoze Zhang, Yihan Zeng, Zhilu Zhang, Hui Li, Wangmeng Zuo, and Ryn- son WH Lau. Dreamphysics: Learning physics-based 3d dynamics with video diffusion priors. InAAAI, 2025. 10
work page 2025
-
[18]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InCVPR, 2024
work page 2024
-
[19]
Peekaboo: Interactive video generation via masked-diffusion
Yash Jain, Anshul Nasery, Vibhav Vineet, and Harkirat Behl. Peekaboo: Interactive video generation via masked-diffusion. InCVPR, 2024
work page 2024
-
[20]
Hyeonho Jeong, Chun-Hao P. Huang, Jong Chul Ye, Niloy J. Mitra, and Duygu Ceylan. Track4gen: Teaching video diffusion models to track points improves video generation. In CVPR, 2025
work page 2025
-
[21]
The material point method for simulating continuum materials
Chenfanfu Jiang, Craig Schroeder, Joseph Teran, Alexey Stomakhin, and Andrew Selle. The material point method for simulating continuum materials. InACM SIGGRAPH 2016 Courses, 2016
work page 2016
-
[22]
Uniedit-flow: Unleashing inversion and editing in the era of flow models.arXiv, 2025
Guanlong Jiao, Biqing Huang, Kuan-Chieh Wang, and Renjie Liao. Uniedit-flow: Unleashing inversion and editing in the era of flow models.arXiv, 2025
work page 2025
-
[23]
3d gaussian splatting for real-time radiance field rendering.ACM TOG, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM TOG, 2023
work page 2023
-
[24]
The numerical solution of stochastic differential equations
Peter E Kloeden and RA Pearson. The numerical solution of stochastic differential equations. The ANZIAM Journal, 1977
work page 1977
-
[25]
Peter E Kloeden and Eckhard Platen.Numerical Solution of Stochastic Differential Equations. Springer, 1992
work page 1992
-
[26]
On information and sufficiency.Annals of Mathe- matical Statistics, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.Annals of Mathe- matical Statistics, 1951
work page 1951
-
[27]
Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance.ICCV, 2025
Quanhao Li, Zhen Xing, Rui Wang, Hui Zhang, Qi Dai, and Zuxuan Wu. Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance.ICCV, 2025
work page 2025
-
[28]
Wonderplay: Dynamic 3d scene generation from a single image and actions
Zizhang Li, Hong-Xing Yu, Wei Liu, Yin Yang, Charles Herrmann, Gordon Wetzstein, and Jiajun Wu. Wonderplay: Dynamic 3d scene generation from a single image and actions. In ICCV, 2025
work page 2025
-
[29]
Movideo: Motion-aware video generation with diffusion models
Jingyun Liang, Yuchen Fan, Kai Zhang, Radu Timofte, Luc Van Gool, and Rakesh Ranjan. Movideo: Motion-aware video generation with diffusion models. InECCV, 2024
work page 2024
-
[30]
Phys4dgen: Physics-compliant 4d generation with multi-material composition perception
Jiajing Lin, Zhenzhong Wang, Dejun Xu, Shu Jiang, Yunpeng Gong, and Min Jiang. Phys4dgen: Physics-compliant 4d generation with multi-material composition perception. InACM Multime- dia, 2025
work page 2025
-
[31]
Omniphysgs: 3d constitutive gaussians for general physics-based dynamics generation.ICLR, 2025
Yuchen Lin, Chenguo Lin, Jianjin Xu, and Yadong Mu. Omniphysgs: 3d constitutive gaussians for general physics-based dynamics generation.ICLR, 2025
work page 2025
-
[32]
Motionclone: Training-free motion cloning for controllable video generation
Pengyang Ling, Jiazi Bu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Tong Wu, Huaian Chen, Jiaqi Wang, and Yi Jin. Motionclone: Training-free motion cloning for controllable video generation. ICLR, 2025
work page 2025
-
[33]
Flow matching for generative modeling.ICLR, 2023
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.ICLR, 2023
work page 2023
-
[34]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InICCV, 2023
work page 2023
-
[35]
Physgen: Rigid-body physics-grounded image-to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. Physgen: Rigid-body physics-grounded image-to-video generation. InECCV, 2024
work page 2024
-
[36]
Realwonder: Real-time physical action-conditioned video generation, 2026
Wei Liu, Ziyu Chen, Zizhang Li, Yue Wang, Hong-Xing Yu, and Jiajun Wu. Realwonder: Real-time physical action-conditioned video generation, 2026. 11
work page 2026
-
[37]
Zhuoman Liu, Weicai Ye, Yan Luximon, Pengfei Wan, and Di Zhang. Physflow: Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation.CVPR, 2025
work page 2025
-
[38]
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense- based benchmark for video generation.arXiv, 2024
work page 2024
-
[39]
Meta. Render colored pointclouds. https://pytorch3d.org/tutorials/render_ colored_points, 2024
work page 2024
-
[40]
Uniphy: Learning a unified constitutive model for inverse physics simulation
Himangi Mittal, Peiye Zhuang, Hsin-Ying Lee, and Shubham Tulsiani. Uniphy: Learning a unified constitutive model for inverse physics simulation. InCVPR, 2025
work page 2025
-
[41]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InCVPR, 2023
work page 2023
-
[42]
Do generative video models understand physical principles?arXiv, 2025
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles?arXiv, 2025
work page 2025
-
[43]
Conditional image-to-video generation with latent flow diffusion models
Haomiao Ni, Changhao Shi, Kai Li, Sharon X Huang, and Martin Renqiang Min. Conditional image-to-video generation with latent flow diffusion models. InCVPR, 2023
work page 2023
-
[44]
Sora.https://openai.com/blog/sora, 2024
OpenAI. Sora.https://openai.com/blog/sora, 2024
work page 2024
-
[45]
Freetraj: Tuning-free trajectory control in video diffusion models, 2024
Haonan Qiu, Zhaoxi Chen, Zhouxia Wang, Yingqing He, Menghan Xia, and Ziwei Liu. Freetraj: Tuning-free trajectory control in video diffusion models, 2024
work page 2024
-
[46]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. NeurIPS, 2023
work page 2023
-
[47]
Sam 2: Segment anything in images and videos.ICLR, 2025
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.ICLR, 2025
work page 2025
-
[48]
InThe F okker-Planck equation: methods of solution and applications
Hannes Risken. InThe F okker-Planck equation: methods of solution and applications. Springer, 1989
work page 1989
-
[49]
Semantic image inversion and editing using rectified stochastic differential equa- tions.ICLR, 2025
Litu Rout, Yujia Chen, Nataniel Ruiz, Constantine Caramanis, Sanjay Shakkottai, and Wen- Sheng Chu. Semantic image inversion and editing using rectified stochastic differential equa- tions.ICLR, 2025
work page 2025
-
[50]
Introducing gen-3 alpha: A new frontier for video generation
Runway Research. Introducing gen-3 alpha: A new frontier for video generation. https: //runwayml.com/research/introducing-gen-3-alpha, 2024
work page 2024
-
[51]
Mvdream: Multi- view diffusion for 3d generation.ICLR, 2024
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi- view diffusion for 3d generation.ICLR, 2024
work page 2024
-
[52]
Score-based generative modeling through stochastic differential equations.ICLR, 2021
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.ICLR, 2021
work page 2021
-
[53]
A material point method for snow simulation.ACM TOG, 2013
Alexey Stomakhin, Craig Schroeder, Lawrence Chai, Joseph Teran, and Andrew Selle. A material point method for snow simulation.ACM TOG, 2013
work page 2013
-
[54]
Physmotion: Physics-grounded dynamics from a single image.3DV, 2026
Xiyang Tan, Ying Jiang, Xuan Li, Zeshun Zong, Tianyi Xie, Yin Yang, and Chenfanfu Jiang. Physmotion: Physics-grounded dynamics from a single image.3DV, 2026
work page 2026
-
[55]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InECCV, 2024. 12
work page 2024
-
[56]
Physctrl: Generative physics for controllable and physics-grounded video generation
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. Physctrl: Generative physics for controllable and physics-grounded video generation. In NeurIPS, 2025
work page 2025
-
[57]
Taming rectified flow for inversion and editing.ICML, 2025
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Taming rectified flow for inversion and editing.ICML, 2025
work page 2025
-
[58]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
work page 2025
-
[59]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH, 2024
work page 2024
-
[60]
Cat4d: Create anything in 4d with multi-view video diffusion models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. In CVPR, 2025
work page 2025
-
[61]
Draganything: Motion control for anything using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for anything using entity representation. InECCV, 2024
work page 2024
-
[62]
Spatialtracker: Tracking any 2d pixels in 3d space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, and Xiaowei Zhou. Spatialtracker: Tracking any 2d pixels in 3d space. InCVPR, 2024
work page 2024
-
[63]
Spatialtrackerv2: 3d point tracking made easy
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: 3d point tracking made easy. In ICCV, 2025
work page 2025
-
[64]
Trajectory attention for fine-grained video motion control
Zeqi Xiao, Wenqi Ouyang, Yifan Zhou, Shuai Yang, Lei Yang, Jianlou Si, and Xingang Pan. Trajectory attention for fine-grained video motion control. InICLR, 2025
work page 2025
-
[65]
Physgaussian: Physics-integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics-integrated 3d gaussians for generative dynamics. InCVPR, 2024
work page 2024
-
[66]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. In- stantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruc- tion models.arXiv, 2024
work page 2024
-
[67]
Direct-a-video: Customized video generation with user-directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user-directed camera movement and object motion. InACM SIGGRAPH, 2024
work page 2024
-
[68]
Text-to-image rectified flow as plug-and-play priors.ICLR, 2025
Xiaofeng Yang, Cheng Chen, Xulei Yang, Fayao Liu, and Guosheng Lin. Text-to-image rectified flow as plug-and-play priors.ICLR, 2025
work page 2025
-
[69]
Xindi Yang, Baolu Li, Yiming Zhang, Zhenfei Yin, Lei Bai, Liqian Ma, Zhiyong Wang, Jianfei Cai, Tien-Tsin Wong, Huchuan Lu, et al. Vlipp: Towards physically plausible video generation with vision and language informed physical prior.ICCV, 2025
work page 2025
-
[70]
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T. Freeman, and Jiajun Wu. Wonder- world: Interactive 3d scene generation from a single image. InCVPR, 2025
work page 2025
-
[71]
Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.TPAMI, 2025
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.TPAMI, 2025
work page 2025
-
[72]
Perpetualwonder: Long-horizon action-conditioned 4d scene generation.CVPR, 2026
Jiahao Zhan, Zizhang Li, Hong-Xing Yu, and Jiajun Wu. Perpetualwonder: Long-horizon action-conditioned 4d scene generation.CVPR, 2026
work page 2026
-
[73]
Frame context packing and drift prevention in next-frame-prediction video diffusion models
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models. In NeurIPS, 2025. 13
work page 2025
-
[74]
Physdreamer: Physics-based interaction with 3d objects via video generation
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T Freeman. Physdreamer: Physics-based interaction with 3d objects via video generation. InECCV, 2024
work page 2024
-
[75]
Yunzhi Zhang, Carson Murtuza-Lanier, Zizhang Li, Yilun Du, and Jiajun Wu. Product of experts for visual generation.arXiv, 2025. 14 A Teaser Figure Details The teaser figure (Fig. 1) shows four physical phenomena—a hanging robe, a duck floating on water, a Franka Panda striking foam, and a rising steam plume—each generated by our full pipeline: 3D scene re...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.