A Readiness-Driven Runtime for Pipeline-Parallel Training under Runtime Variability
Pith reviewed 2026-05-20 07:31 UTC · model grok-4.3
pith:DDV2NXWX Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{DDV2NXWX}
Prints a linked pith:DDV2NXWX badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
RRFP dispatches pipeline work by readiness rather than fixed schedule order to cut idle time in variable workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RRFP is a readiness-driven runtime that consumes pipeline schedules as non-binding hints for ranking ready work rather than strict execution orders. It relies on message-driven asynchronous communication, lightweight tensor-parallel coordination to ensure collective consistency, and ready-set arbitration for efficient dispatch of executable tasks. This design avoids stage misalignment and reduces idle bubbles when realized readiness diverges from the schedule.
What carries the argument
The ready-set arbitration mechanism that selects the highest-priority ready task according to the hint order while ensuring low-overhead dispatch.
If this is right
- Improves utilization over fixed-order pipeline baselines in all tested settings.
- Delivers up to 1.77 times faster training on language-only workloads with the BFW hint.
- Delivers up to 2.77 times faster training on multimodal workloads with the BFW hint.
- Outperforms the best available external system by up to 1.84 times while keeping training correct.
Where Pith is reading between the lines
- The method may apply to other forms of parallel training where static schedules lead to underutilization.
- Low-overhead readiness tracking could influence scheduler design in cloud-based training platforms.
- Further work could test whether similar hint-based approaches reduce bubbles in data-parallel or hybrid parallelism setups.
Load-bearing premise
The overhead from ready-set arbitration and tensor-parallel coordination stays small enough not to offset the benefits of avoiding misalignment under normal levels of runtime variability.
What would settle it
An experiment that isolates and measures the added latency from arbitration and coordination, or one that runs with artificially high variability to see if the speedups hold or reverse.
Figures





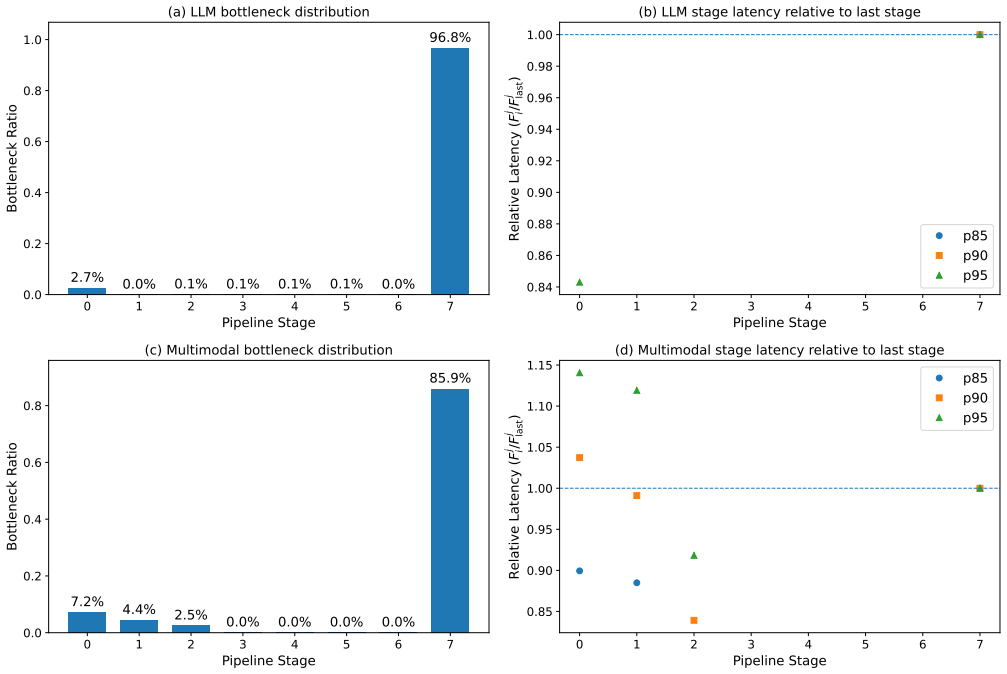


read the original abstract
Pipeline parallelism is a key technique for scaling large-model training, but modern workloads exhibit runtime variability in computation and communication. Existing pipeline systems typically consume static, profiled, or adaptively generated schedules as pre-committed execution orders. When realized task readiness diverges from the pre-committed order, stages may wait for not-yet-ready work even though other executable work is available, creating stage misalignment, idle bubbles, and reduced utilization. We present Runtime-Readiness-First Pipeline (RRFP), a readiness-driven runtime for pipeline-parallel training. RRFP changes how schedules are consumed at runtime: instead of treating a schedule as a sequence that stages must wait to follow, it treats the schedule as a non-binding hint order for ranking currently ready work. To support this model, RRFP combines message-driven asynchronous communication, lightweight tensor-parallel coordination for collective consistency, and ready-set arbitration for low-overhead dispatch. We implement RRFP in a Megatron-based training framework and evaluate it on language-only and multimodal workloads at up to 128 GPUs. RRFP improves over fixed-order pipeline baselines across all settings. Using the BFW hint, RRFP achieves up to 1.77$\times$ speedup on language-only workloads and up to 2.77$\times$ on multimodal workloads. In cross-framework comparisons, RRFP with the default BF hint outperforms the faster available external system by up to 1.84$\times$ while preserving training correctness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Runtime-Readiness-First Pipeline (RRFP), a readiness-driven runtime for pipeline-parallel training. RRFP treats static or profiled schedules as non-binding hints for ranking currently ready work rather than fixed execution orders, using message-driven asynchronous communication, lightweight tensor-parallel coordination for collective consistency, and ready-set arbitration for dispatch. Implemented in a Megatron-based framework, it is evaluated on language-only and multimodal workloads at up to 128 GPUs and reports speedups of up to 1.77× (language) and 2.77× (multimodal) over fixed-order baselines using the BFW hint, plus up to 1.84× over the faster external system using the BF hint, while preserving training correctness.
Significance. If the performance claims are substantiated with detailed experimental controls, RRFP could meaningfully improve GPU utilization in pipeline-parallel training under realistic runtime variability such as stragglers or load imbalance. The shift from consuming schedules as committed orders to readiness-driven dispatch is a practical systems contribution that directly targets stage misalignment bubbles.
major comments (2)
- Abstract: the central claims of 1.77× and 2.77× speedups (and 1.84× cross-framework) are presented without any description of how runtime variability was introduced, the number of runs performed, error bars, or exact baseline configurations and hardware setups. This absence directly limits assessment of the robustness of the reported gains.
- Evaluation (implied by the reported speedups): no microbenchmark or sensitivity analysis isolates the overhead of ready-set arbitration and lightweight tensor-parallel coordination. Without such data it is impossible to confirm that these mechanisms remain negligible relative to the utilization gains when the ready set grows or changes frequently under high variability.
minor comments (1)
- Clarify the distinction between the 'BFW hint' and 'BF hint' (mentioned in the abstract) with explicit definitions and usage in the main text.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify areas where additional detail and analysis would strengthen the manuscript. We respond to each below and will incorporate revisions as indicated.
read point-by-point responses
-
Referee: Abstract: the central claims of 1.77× and 2.77× speedups (and 1.84× cross-framework) are presented without any description of how runtime variability was introduced, the number of runs performed, error bars, or exact baseline configurations and hardware setups. This absence directly limits assessment of the robustness of the reported gains.
Authors: We agree that the abstract would benefit from a concise description of the experimental conditions supporting the speedup claims. Section 5 of the manuscript already details the variability model (controlled injection of stragglers and load imbalance via synthetic delays), the use of five independent runs per configuration with reported means and standard deviations, the hardware platform (up to 128 NVIDIA A100 GPUs), and the precise baseline configurations (fixed-order pipelines using BFW and BF hints). We will revise the abstract to include a short clause summarizing these elements while remaining within length limits. This is a straightforward clarification that does not alter any claims. revision: yes
-
Referee: Evaluation (implied by the reported speedups): no microbenchmark or sensitivity analysis isolates the overhead of ready-set arbitration and lightweight tensor-parallel coordination. Without such data it is impossible to confirm that these mechanisms remain negligible relative to the utilization gains when the ready set grows or changes frequently under high variability.
Authors: The referee correctly notes the absence of isolated overhead measurements. Our current evaluation emphasizes end-to-end speedups under variability, but does not contain dedicated microbenchmarks for ready-set arbitration and tensor-parallel coordination costs. We will add a new microbenchmark subsection (Section 5.3) that profiles arbitration latency and coordination overhead as functions of ready-set size and variability intensity, demonstrating that these costs remain under 3% of per-stage execution time. The added data will be obtained from targeted profiling runs performed for the revision. revision: yes
Circularity Check
No circularity: empirical systems paper with independent experimental validation
full rationale
The paper is a systems implementation and evaluation contribution. It describes RRFP as a readiness-driven runtime using message-driven async comm, ready-set arbitration, and lightweight TP coordination, then reports measured speedups (1.77×–2.77×) against fixed-order baselines and external frameworks on language and multimodal workloads up to 128 GPUs. No equations, parameter fitting, derivations, or self-citation chains appear in the provided text. All central claims rest on direct experimental comparisons that are externally falsifiable and do not reduce to the paper's own inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Runtime variability in computation and communication is common and significant enough to cause stage misalignment in fixed-order pipelines.
invented entities (1)
-
RRFP runtime with ready-set arbitration
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Milli- can, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Ja- cob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sa- hand Sharifzadeh, Mikolaj Bink...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Am- mar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, and Yuxiong He. 2022. DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. arXiv:2207.00032 [cs.LG]https://arxiv.org/abs/2207.00032
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [6]
-
[7]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al
-
[8]
Expanding Performance Boundaries of Open-Source Multi- modal Models with Model, Data, and Test-Time Scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al
-
[10]
How Far Are We to GPT-4V? Closing the Gap to Commer- cial Multimodal Models with Open-Source Suites.arXiv preprint arXiv:2404.16821(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24185–24198. 13
work page 2024
-
[12]
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd van Steenkiste, Gamaleldin F....
-
[13]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2020. An Image is Worth 16x16 Words: Trans- formers for Image Recognition at Scale. arXiv:2010.11929https: //arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [14]
- [15]
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravanku- mar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Au- relien Rodriguez, Austen Gregerson, A...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
Ryubu Hosoki, Toshio Endo, Takahiro Hirofuchi, and Tsutomu Ikegami. 2024. AshPipe: Asynchronous Hybrid Pipeline Parallel for DNN Training. InProceedings of the International Conference on High Performance Computing in Asia-Pacific Region(Nagoya, Japan)(HPCA- sia ’24). Association for Computing Machinery, New York, NY, USA, 117–126. doi:10.1145/3635035.3635045
-
[19]
Jun Huang, Zhen Zhang, Shuai Zheng, Feng Qin, and Yida Wang. 2024. DISTMM: Accelerating Distributed Multimodal Model Training. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). USENIX Association, Santa Clara, CA, 1157–1171.https: //www.usenix.org/conference/nsdi24/presentation/huang
work page 2024
-
[20]
Yanping Huang, Youlong Cheng, Ankur Bapna, et al . 2019. GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. arXiv:1811.06965 [cs.CV]https://arxiv.org/abs/1811.06965
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [21]
-
[22]
Ganger, Tianqi Chen, and Zhihao Jia
Byungsoo Jeon, Mengdi Wu, Shiyi Cao, Sunghyun Kim, Sunghyun Park, Neeraj Aggarwal, Colin Unger, Daiyaan Arfeen, Peiyuan Liao, Xupeng Miao, Mohammad Alizadeh, Gregory R. Ganger, Tianqi Chen, and Zhihao Jia. 2025. GraphPipe: Improving Performance and Scalabil- ity of DNN Training with Graph Pipeline Parallelism. InProceedings of the 30th ACM International C...
- [23]
- [24]
- [25]
-
[26]
Shigang Li and Torsten Hoefler. 2021. Chimera: efficiently training large-scale neural networks with bidirectional pipelines. InProceed- ings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’21). ACM, 1–14. doi:10.1145/ 3458817.3476145
-
[27]
Xinyu Lian, Masahiro Tanaka, Olatunji Ruwase, and Minjia Zhang
-
[28]
arXiv:2509.21271 [cs.LG]https://arxiv.org/abs/ 2509.21271
SuperOffload: Unleashing the Power of Large-Scale LLM Train- ing on Superchips. arXiv:2509.21271 [cs.LG]https://arxiv.org/abs/ 2509.21271
-
[29]
Yanying Lin, Shijie Peng, Chengzhi Lu, ChengZhong Xu, and Kejiang Ye. 2026. FlexPipe: Adapting Dynamic LLM Serving Through Inflight Pipeline Refactoring in Fragmented Serverless Clusters. InProceedings of the 21st European Conference on Computer Systems (EUROSYS ’26). ACM, 72–88. doi:10.1145/3767295.3769316
-
[30]
Zhiqi Lin, Youshan Miao, Quanlu Zhang, Fan Yang, Yi Zhu, Cheng Li, Saeed Maleki, Xu Cao, Ning Shang, Yilei Yang, Weijiang Xu, Mao Yang, Lintao Zhang, and Lidong Zhou. 2024. nnScaler: Constraint-Guided Parallelization Plan Generation for Deep Learning Training. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 347–363
work page 2024
-
[31]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Se- shadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM Symposium on Op- erating Systems Principles(Huntsville, Ontario, Canada)(SOSP ’19). Association for Computing Mach...
- [32]
- [33]
-
[34]
NVIDIA. 2025. NCCL (NVIDIA Collective Communications Library). https://github.com/NVIDIA/nccl
work page 2025
-
[35]
NVIDIA Corporation. 2025.NVIDIA Collective Communications Li- brary (NCCL) Documentation.https://docs.nvidia.com/deeplearning/ nccl/user-guide/docs/Accessed: 2025-01-28
work page 2025
-
[36]
Hyungjun Oh, Junyeol Lee, Hyeongju Kim, and Jiwon Seo. 2022. Out- of-order backprop: an effective scheduling technique for deep learning. InProceedings of the Seventeenth European Conference on Computer Systems(Rennes, France)(EuroSys ’22). Association for Computing Ma- chinery, New York, NY, USA, 435–452. doi:10.1145/3492321.3519563
-
[37]
Jay H. Park, Gyeongchan Yun, Chang M. Yi, Nguyen T. Nguyen, Seung- min Lee, Jaesik Choi, Sam H. Noh, and Young ri Choi. 2020. HetPipe: Enabling Large DNN Training on (Whimpy) Heterogeneous GPU Clusters through Integration of Pipelined Model Parallelism and Data Parallelism. arXiv:2005.14038 [cs.DC]https://arxiv.org/abs/2005.14038
-
[38]
Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, and Chuanxiong Guo. 2019. A generic communication scheduler for distributed DNN training acceleration. InProceedings of the 27th ACM Symposium on Operating Systems Principles(Huntsville, Ontario, Canada)(SOSP ’19). Association for Computing Machinery, New York, NY, USA, 16–29...
-
[39]
Shiva Kumar Pentyala, Zhichao Wang, Bin Bi, Kiran Ramnath, Xiang- Bo Mao, Regunathan Radhakrishnan, Sitaram Asur, Na, and Cheng
-
[40]
arXiv:2406.17923 [cs.CL]https://arxiv.org/abs/2406.17923 15
PAFT: A Parallel Training Paradigm for Effective LLM Fine- Tuning. arXiv:2406.17923 [cs.CL]https://arxiv.org/abs/2406.17923 15
- [41]
-
[42]
Aurick Qiao, Sang Keun Choe, Suhas Jayaram Subramanya, Willie Neiswanger, Qirong Ho, Hao Zhang, Gregory R. Ganger, and Eric P. Xing. 2021. Pollux: Co-adaptive Cluster Scheduling for Goodput- Optimized Deep Learning. arXiv:2008.12260 [cs.DC]https://arxiv.org/ abs/2008.12260
-
[43]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learn- ing Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020 [cs.CV]https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[45]
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
ZeRO: Memory Optimizations Toward Training Trillion Parame- ter Models. arXiv:1910.02054 [cs.LG]https://arxiv.org/abs/1910.02054
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[46]
Chen, Pascal Felber, Robert Birke, and Valerio Schiavoni
Isabelly Rocha, Nathaniel Morris, Lydia Y. Chen, Pascal Felber, Robert Birke, and Valerio Schiavoni. 2020. PipeTune: Pipeline Parallelism of Hyper and System Parameters Tuning for Deep Learning Clusters. In Middleware ’20: 21st International Middleware Conference, Delft, The Netherlands, December 7-11, 2020, Dilma Da Silva and Rüdiger Kapitza (Eds.). ACM,...
-
[47]
Alexander Sergeev and Mike Del Balso. 2018. Horovod: fast and easy distributed deep learning in TensorFlow. arXiv:1802.05799 [cs.LG] https://arxiv.org/abs/1802.05799
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053 [cs.CL]https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [49]
-
[50]
Sahil Tyagi and Prateek Sharma. 2020. Taming Resource Heterogeneity In Distributed ML Training With Dynamic Batching. In2020 IEEE International Conference on Autonomic Computing and Self-Organizing Systems (ACSOS). IEEE, Washington, DC, USA, 188–194. doi:10.1109/ acsos49614.2020.00041
-
[51]
Colin Unger, Zhihao Jia, Wei Wu, Sina Lin, Mandeep Baines, Carlos Efrain Quintero Narvaez, Vinay Ramakrishnaiah, Nirmal Prajapati, Pat McCormick, Jamaludin Mohd-Yusof, Xi Luo, Dheevatsa Mudigere, Jongsoo Park, Misha Smelyanskiy, and Alex Aiken. 2022. Unity: Ac- celerating DNN Training Through Joint Optimization of Algebraic Transformations and Paralleliza...
work page 2022
- [52]
- [53]
- [54]
-
[55]
Zhenliang Xue, Hanpeng Hu, Xing Chen, Yimin Jiang, Yixin Song, Zeyu Mi, Yibo Zhu, Daxin Jiang, Yubin Xia, and Haibo Chen. 2025. PipeWeaver: Addressing Data Dynamicity in Large Multimodal Model Training with Dynamic Interleaved Pipeline. arXiv:2504.14145 [cs.DC] https://arxiv.org/abs/2504.14145
-
[56]
Zhenliang Xue, Hanpeng Hu, Xing Chen, Yimin Jiang, Yixin Song, Zeyu Mi, Yibo Zhu, Daxin Jiang, Yubin Xia, and Haibo Chen. 2026. DIP: Efficient Large Multimodal Model Training with Dynamic In- terleaved Pipeline. InProceedings of the 31st ACM International Con- ference on Architectural Support for Programming Languages and Op- erating Systems, Volume 2. AC...
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Aberger, and Christopher De Sa
Bowen Yang, Jian Zhang, Jonathan Li, Christopher Ré, Christopher R. Aberger, and Christopher De Sa. 2020. PipeMare: Asynchronous Pipeline Parallel DNN Training. arXiv:1910.05124 [cs.DC]https: //arxiv.org/abs/1910.05124
- [59]
-
[60]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Au- tomating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. arXiv:2201.12023 [cs.LG]https://arxiv.org/abs/2201.12023
-
[61]
Guangyao Zhou, Wenhong Tian, Rajkumar Buyya, and Kui Wu. 2025. UMPIPE: Unequal Microbatches-Based Pipeline Parallelism for Deep Neural Network Training .IEEE Transactions on Parallel & Distributed Systems36, 02 (Feb. 2025), 293–307. doi:10.1109/TPDS.2024.3515804 16 A Backward-Forward Hint Algorithm This section gives the detailed instantiation of the back...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.