SURF: Steering the Scalarization Weight to Uniformly Traverse the Pareto Front
Pith reviewed 2026-05-21 06:38 UTC · model grok-4.3
The pith
Inverting the arc-length cumulative distribution function of the scalarization path produces weights that uniformly cover the Pareto front.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the scalarization path traces the Pareto front with non-uniform speed, inducing an arc-length CDF; inverting this CDF map yields a principled rule for selecting weights that produce uniform PF coverage. SURF implements this rule, deriving closed forms where possible and alternating reconstruction and sampling otherwise.
What carries the argument
The arc-length cumulative distribution function (CDF) of the scalarization path, which tracks how far along the Pareto front the solutions have traveled as the weight changes; inverting it corrects for the uneven traversal speed to select weights evenly.
If this is right
- Closed-form expressions exist for the CDF map in structured problems like bi-objective bandits.
- SURF converges linearly to an unavoidable finite-sampling floor under provable conditions.
- Empirical results show more uniform coverage on bandits, multi-objective gymnasium environments, and multi-objective LLM alignment tasks.
Where Pith is reading between the lines
- The method might extend to other multi-objective algorithms that use scalarization but currently ignore path geometry.
- In very high-dimensional objective spaces, repeatedly reconstructing the CDF could add significant computational overhead.
- This geometric view suggests designing new scalarization functions that inherently traverse the front more uniformly.
Load-bearing premise
The scalarization path traces the Pareto front continuously enough to define a meaningful arc-length and to reconstruct its cumulative distribution function from samples.
What would settle it
Running the method on a simple bi-objective problem with a known curved Pareto front and checking whether the achieved solution spacing is significantly more uniform than uniform weight sampling would confirm or refute the benefit of the inversion rule.
Figures









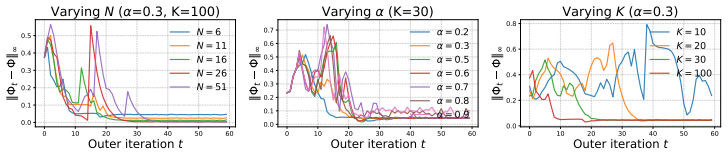
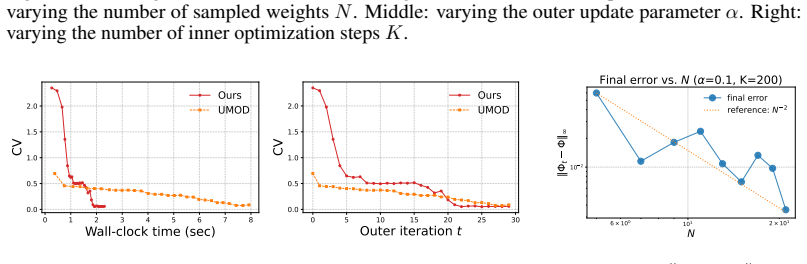
read the original abstract
Scalarization is widely used in multi-objective optimization owing to its simplicity and scalability. In many applications, the goal is to generate solutions that represent diverse user preferences, ideally with uniform coverage of the Pareto front (PF). However, uniformly sampling scalarization weights usually induces non-uniform coverage of the PF. We explain this mismatch through a geometric analysis of the scalarization path. As the scalarization weight varies, the corresponding solutions trace the PF with a generally non-uniform traversal speed. This speed induces an arc-length cumulative distribution function (CDF); inverting this CDF map yields a principled rule for selecting weights that produce uniform PF coverage. Building on this insight, we propose SURF (Sampling Uniformly along the PaReto Front). For structured problems, including bi-objective bandits, we derive closed-form expressions for this CDF map and the resulting PF-aware weight sampling rule. For general problems, SURF alternates between CDF reconstruction and weight sampling. Theoretically, we show that under provable conditions, SURF converges linearly to an unavoidable finite-sampling floor. Empirically, experiments on bandits, multi-objective-gymnasium, and multi-objective LLM alignment demonstrate that SURF efficiently achieves more uniform PF coverage than baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that uniformly sampling scalarization weights in multi-objective optimization produces non-uniform Pareto front (PF) coverage because the scalarization path traverses the PF at varying speeds; inverting the arc-length CDF of this path yields a weight-sampling rule (SURF) that achieves uniform coverage. For structured cases such as bi-objective bandits the authors derive closed-form CDF maps and sampling rules; for general problems SURF alternates between CDF reconstruction and weight sampling. They prove linear convergence to a finite-sampling floor under stated conditions and report empirical improvements over baselines on bandits, multi-objective gymnasium environments, and LLM alignment tasks.
Significance. If the geometric analysis and reachability assumptions hold, the work supplies a principled, geometry-driven method for uniform PF sampling that improves on ad-hoc weight selection. The closed-form derivations for bandits and the linear-convergence guarantee are concrete strengths; the empirical results across three distinct domains further support practical utility for applications that require diverse, preference-representing solutions.
major comments (2)
- [Abstract / geometric analysis] Abstract and geometric-analysis section: the central claim that CDF inversion produces uniform coverage of the full PF rests on the unstated premise that the scalarization path reaches every point on the PF. Standard weighted-sum scalarization recovers only supported points on the convex hull; non-convex segments are unreachable. This assumption is load-bearing for the uniform-coverage guarantee and must be explicitly stated, justified, or restricted to convex fronts.
- [Theoretical analysis] Theoretical-convergence paragraph: the linear convergence result is stated to hold 'under provable conditions,' yet the precise conditions (e.g., Lipschitz continuity of the PF, strict convexity, or bounded curvature) are not enumerated. Without an explicit list or a theorem statement that isolates these conditions, it is impossible to verify applicability to the general alternating-reconstruction case.
minor comments (2)
- Notation for the arc-length parameter and the CDF inversion operator should be introduced once with a clear diagram or equation reference rather than re-defined inline in multiple places.
- The description of the alternating reconstruction procedure for general problems would benefit from a short pseudocode block or numbered steps to clarify the loop termination criterion.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below, providing clarifications on the scope of our claims and indicating the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract / geometric analysis] Abstract and geometric-analysis section: the central claim that CDF inversion produces uniform coverage of the full PF rests on the unstated premise that the scalarization path reaches every point on the PF. Standard weighted-sum scalarization recovers only supported points on the convex hull; non-convex segments are unreachable. This assumption is load-bearing for the uniform-coverage guarantee and must be explicitly stated, justified, or restricted to convex fronts.
Authors: We agree that weighted-sum scalarization recovers only supported solutions on the convex hull and cannot reach non-convex segments of the Pareto front. Our geometric analysis of the scalarization path and the SURF sampling rule are developed specifically for the reachable (supported) portion of the front. We will revise the abstract and geometric-analysis section to state this premise explicitly, restrict the uniform-coverage guarantee to supported points, and note that alternative scalarizations would be required for unsupported regions. This change clarifies the scope without affecting the core technical contributions. revision: yes
-
Referee: [Theoretical analysis] Theoretical-convergence paragraph: the linear convergence result is stated to hold 'under provable conditions,' yet the precise conditions (e.g., Lipschitz continuity of the PF, strict convexity, or bounded curvature) are not enumerated. Without an explicit list or a theorem statement that isolates these conditions, it is impossible to verify applicability to the general alternating-reconstruction case.
Authors: We appreciate the request for greater precision. The current manuscript refers to 'provable conditions' without enumerating them in the main text. In the revision we will insert an explicit theorem statement that lists the required assumptions, including Lipschitz continuity of the Pareto-front mapping, bounded curvature ensuring a well-defined arc-length, and the technical conditions on the CDF reconstruction step for the general alternating procedure. This will make the applicability of the linear-convergence result verifiable. revision: yes
Circularity Check
No significant circularity; derivation rests on independent geometric analysis
full rationale
The paper derives the SURF weight-sampling rule by first performing a geometric analysis of the scalarization path's traversal speed along the PF, which induces an arc-length CDF; inverting that CDF then supplies the weight rule. This chain is presented as following from the path geometry rather than from any fitted parameter, self-definition, or prior self-citation that encodes the target result. Closed-form CDF expressions for bi-objective bandits and the alternating reconstruction procedure for general cases are derived directly from the same geometric model. Theoretical linear convergence is shown under explicitly stated provable conditions, and empirical comparisons are external to the derivation. No step reduces by construction to its own inputs, and the central claim retains independent content from the geometric premise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The scalarization path traces the Pareto front with a traversal speed that admits a well-defined arc-length cumulative distribution function.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
As the scalarization weight varies, the corresponding solutions trace the PF with a generally non-uniform traversal speed. This speed induces an arc-length cumulative distribution function (CDF); inverting this CDF map yields a principled rule for selecting weights that produce uniform PF coverage.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under Assumption 1, ... every Pareto-optimal point can be obtained by (3) with some w ∈ Δ^M.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Optimistic linear support and successor features as a basis for optimal policy transfer
Lucas Nunes Alegre, Ana Bazzan, and Bruno C Da Silva. Optimistic linear support and successor features as a basis for optimal policy transfer. InInternational conference on machine learning, pages 394–413. PMLR, 2022
work page 2022
- [2]
-
[3]
System level synthesis.Annual Reviews in Control, 47:364–393, 2019
James Anderson, John C Doyle, Steven H Low, and Nikolai Matni. System level synthesis.Annual Reviews in Control, 47:364–393, 2019
work page 2019
-
[4]
Finite-time analysis of the multiarmed bandit problem
Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47(2):235–256, 2002
work page 2002
-
[5]
Learning all optimal policies with multiple criteria
Leon Barrett and Srini Narayanan. Learning all optimal policies with multiple criteria. InProceedings of the 25th international conference on Machine learning, pages 41–47, 2008
work page 2008
-
[6]
Fernanda Beltrán, Oliver Cuate, and Oliver Schütze. The pareto tracer for general inequality constrained multi-objective optimization problems.Mathematical and Computational Applications, 25(4):80, 2020
work page 2020
-
[7]
Abhay G Bhatt and Vivek S Borkar. Occupation measures for controlled markov processes: Characteriza- tion and optimality.The Annals of Probability, pages 1531–1562, 1996
work page 1996
-
[8]
Patrick Billingsley.Probability and measure. John Wiley & Sons, 2017
work page 2017
-
[9]
José M Bogoya, Andrés Vargas, and Oliver Schütze. The averaged hausdorff distances in multi-objective optimization: A review.Mathematics, 7(10):894, 2019
work page 2019
-
[10]
Matthias Bolten, Onur Tanil Doganay, Hanno Gottschalk, and Kathrin Klamroth. Tracing locally pareto- optimal points by numerical integration.SIAM Journal on Control and Optimization, 59(5):3302–3328, 2021
work page 2021
-
[11]
A tutorial on geometric programming.Optimization and engineering, 8(1):67–127, 2007
Stephen Boyd, Seung-Jean Kim, Lieven Vandenberghe, and Arash Hassibi. A tutorial on geometric programming.Optimization and engineering, 8(1):67–127, 2007
work page 2007
-
[12]
Pure exploration in multi-armed bandits problems
Sébastien Bubeck, Rémi Munos, and Gilles Stoltz. Pure exploration in multi-armed bandits problems. In International conference on Algorithmic learning theory, pages 23–37. Springer, 2009
work page 2009
-
[13]
Moving mesh generation using the parabolic monge–ampère equation
Chris J Budd and JF Williams. Moving mesh generation using the parabolic monge–ampère equation. SIAM Journal on Scientific Computing, 31(5):3438–3465, 2009
work page 2009
-
[14]
Courier Dover Publications, 2008
Vira Chankong and Yacov Y Haimes.Multiobjective decision making: theory and methodology. Courier Dover Publications, 2008
work page 2008
-
[15]
Lisha Chen, Heshan Fernando, Yiming Ying, and Tianyi Chen. Three-way trade-off in multi-objective learning: Optimization, generalization and conflict-avoidance.J. Machine Learn. Res., 25(193):1–53, 5 2024
work page 2024
-
[16]
Lisha Chen, AFM Saif, Yanning Shen, and Tianyi Chen. Ferero: A flexible framework for preference- guided multi-objective learning.Advances in Neural Information Processing Systems, 37:18758–18805, 2024. 10
work page 2024
-
[17]
Lisha Chen, Quan Xiao, Ellen Hidemi Fukuda, Xinyi Chen, Kun Yuan, and Tianyi Chen. Efficient first-order optimization on the Pareto set for multi-objective learning under preference guidance. In International Conference on Machine Learning (ICML), as spotlight, 2025
work page 2025
-
[18]
Weiyu Chen and James Kwok. Pareto merging: Multi-objective optimization for preference-aware model merging.arXiv preprint arXiv:2408.12105, 2024
-
[19]
Weiyu Chen, Xiaoyuan Zhang, Baijiong Lin, Xi Lin, Han Zhao, Qingfu Zhang, and James T Kwok. Gradient-based multi-objective deep learning: Algorithms, theories, applications, and beyond.arXiv preprint arXiv:2501.10945, 2025
-
[20]
Xin Chen, Niao He, Yifan Hu, and Zikun Ye. Efficient algorithms for a class of stochastic hidden convex optimization and its applications in network revenue management.Operations Research, 73(2):704–719, 2025
work page 2025
-
[21]
Yiwei Chen and Cong Shi. Network revenue management with online inverse batch gradient descent method.Production and Operations Management, 32(7):2123–2137, 2023
work page 2023
-
[22]
Multi-objective neural bandits with random scalarization
Ji Cheng, Bo Xue, Chengyu Lu, Ziqiang Cui, and Qingfu Zhang. Multi-objective neural bandits with random scalarization. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 4914–4922, 2025
work page 2025
-
[23]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Indraneel Das and John E Dennis. Normal-boundary intersection: A new method for generating the pareto surface in nonlinear multicriteria optimization problems.SIAM journal on optimization, 8(3):631–657, 1998
work page 1998
-
[25]
Designing multi-objective multi-armed bandits algorithms: A study
Madalina M Drugan and Ann Nowe. Designing multi-objective multi-armed bandits algorithms: A study. InThe 2013 international joint conference on neural networks (IJCNN), pages 1–8. IEEE, 2013
work page 2013
-
[26]
Scalarization based pareto optimal set of arms identification algorithms
Madalina M Drugan and Ann Nowé. Scalarization based pareto optimal set of arms identification algorithms. In2014 International Joint Conference on Neural Networks (IJCNN), pages 2690–2697. IEEE, 2014
work page 2014
-
[27]
Dmitriy Drusvyatskiy and Courtney Paquette. Efficiency of minimizing compositions of convex functions and smooth maps.Mathematical Programming, 178(1):503–558, 2019
work page 2019
- [28]
-
[29]
Petri Eskelinen and Kaisa Miettinen. Trade-off analysis approach for interactive nonlinear multiobjective optimization.OR spectrum, 34(4):803–816, 2012
work page 2012
-
[30]
Cambridge university press Cambridge, UK, 2002
Brian S Everitt and Anders Skrondal.The Cambridge dictionary of statistics, volume 140. Cambridge university press Cambridge, UK, 2002
work page 2002
-
[31]
Stochastic optimization under hidden convexity.SIAM Journal on Optimization, 35(4):2544–2571, 2025
Ilyas Fatkhullin, Niao He, and Yifan Hu. Stochastic optimization under hidden convexity.SIAM Journal on Optimization, 35(4):2544–2571, 2025
work page 2025
-
[32]
Florian Felten, Lucas N. Alegre, Ann Nowé, Ana L. C. Bazzan, El Ghazali Talbi, Grégoire Danoy, and Bruno C. da Silva. A toolkit for reliable benchmarking and research in multi-objective reinforcement learning. InProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), 2023
work page 2023
-
[33]
Florian Felten, El-Ghazali Talbi, and Grégoire Danoy. Multi-objective reinforcement learning based on decomposition: A taxonomy and framework.Journal of Artificial Intelligence Research, 79:679–723, 2024
work page 2024
-
[34]
Mitigating gradient bias in multi-objective learning: A provably convergent stochastic approach
Heshan Fernando, Han Shen, Miao Liu, Subhajit Chaudhury, Keerthiram Murugesan, and Tianyi Chen. Mitigating gradient bias in multi-objective learning: A provably convergent stochastic approach. InProc. Int. Conf. Learn. Representations, Kigali, Rwanda, May 2023
work page 2023
-
[35]
Anthony V Fiacco. Sensitivity analysis for nonlinear programming using penalty methods.Mathematical programming, 10(1):287–311, 1976
work page 1976
-
[36]
Monotone piecewise cubic interpolation.SIAM Journal on Numerical Analysis, 17(2):238–246, 1980
Frederick N Fritsch and Ralph E Carlson. Monotone piecewise cubic interpolation.SIAM Journal on Numerical Analysis, 17(2):238–246, 1980. 11
work page 1980
-
[37]
Sequential learning of the pareto front for multi-objective bandits
Aurélien Garivier and Wouter M Koolen. Sequential learning of the pareto front for multi-objective bandits. InInternational Conference on Artificial Intelligence and Statistics, pages 3583–3591. PMLR, 2024
work page 2024
-
[38]
A theory of regularized markov decision processes
Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A theory of regularized markov decision processes. InInternational conference on machine learning, pages 2160–2169. PMLR, 2019
work page 2019
-
[39]
User’s guide for snopt version 7: software for large-scale nonlinear programming
Philip E Gill, Walter Murray, and Michael A Saunders. User’s guide for snopt version 7: software for large-scale nonlinear programming. Technical report, Systems Optimization Laboratory, Stanford University, 2006
work page 2006
-
[40]
Rafael C Gonzalez.Digital image processing. Pearson education india, 2009
work page 2009
-
[41]
Controllable preference optimization: Toward controllable multi-objective alignment
Yiju Guo, Ganqu Cui, Lifan Yuan, Ning Ding, Zexu Sun, Bowen Sun, Huimin Chen, Ruobing Xie, Jie Zhou, Yankai Lin, et al. Controllable preference optimization: Toward controllable multi-objective alignment. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1437–1454, 2024
work page 2024
-
[42]
Naoki Hamada, Kenta Hayano, Shunsuke Ichiki, Yutaro Kabata, and Hiroshi Teramoto. Topology of pareto sets of strongly convex problems.SIAM Journal on Optimization, 30(3):2659–2686, 2020
work page 2020
-
[43]
Cambridge university press, 1952
Godfrey Harold Hardy, John Edensor Littlewood, and George Pólya.Inequalities. Cambridge university press, 1952
work page 1952
-
[44]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[45]
Springer Science & Business Media, 2010
Weizhang Huang and Robert D Russell.Adaptive moving mesh methods, volume 174. Springer Science & Business Media, 2010
work page 2010
-
[46]
Kazufumi Ito and Karl Kunisch.Lagrange multiplier approach to variational problems and applications. SIAM, 2008
work page 2008
-
[47]
Scalarization in multi objective optimization
Johannes Jahn. Scalarization in multi objective optimization. InMathematics of multi objective optimiza- tion, pages 45–88. Springer, 1985
work page 1985
-
[48]
Emilie Kaufmann, Olivier Cappé, and Aurélien Garivier. On the complexity of best-arm identification in multi-armed bandit models.The Journal of Machine Learning Research, 17(1):1–42, 2016
work page 2016
-
[49]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[50]
Gradient-adaptive policy optimization: Towards multi-objective alignment of large language models
Chengao Li, Hanyu Zhang, Yunkun Xu, Hongyan Xue, Xiang Ao, and Qing He. Gradient-adaptive policy optimization: Towards multi-objective alignment of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11214–11232, 2025
work page 2025
-
[51]
Zhuo Li, Guodong Du, Weiyang Guo, Yigeng Zhou, Xiucheng Li, Wenya Wang, Fangming Liu, Yequan Wang, Deheng Ye, Min Zhang, et al. Multi-objective large language model alignment with hierarchical experts.arXiv preprint arXiv:2505.20925, 2025
-
[52]
Baijiong Lin, Weisen Jiang, Yuancheng Xu, Hao Chen, and Ying-Cong Chen. Parm: Multi-objective test-time alignment via preference-aware autoregressive reward model.arXiv preprint arXiv:2505.06274, 2025
-
[53]
Qian Lin, Chao Yu, Zongkai Liu, and Zifan Wu. Policy-regularized offline multi-objective reinforcement learning.arXiv preprint arXiv:2401.02244, 2024
-
[54]
Xi Lin, Xiaoyuan Zhang, Zhiyuan Yang, Fei Liu, Zhenkun Wang, and Qingfu Zhang. Smooth Tchebycheff scalarization for multi-objective optimization.arXiv preprint arXiv:2402.19078, 2024
-
[55]
Xi Lin, Hui-Ling Zhen, Zhenhua Li, Qing-Fu Zhang, and Sam Kwong. Pareto multi-task learning. In Proc. Advances Neural Inf. Process. Syst., Vancouver, Canada, December 2019
work page 2019
-
[56]
Conflict-Averse Gradient Descent for Multi-task Learning
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-Averse Gradient Descent for Multi-task Learning. InProc. Advances Neural Inf. Process. Syst., virtual, December 2021
work page 2021
-
[57]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. InForty-first International Conference on Machine Learning, 2024. 12
work page 2024
-
[58]
Suyun Liu and Luis Nunes Vicente. The stochastic multi-gradient algorithm for multi-objective opti- mization and its application to supervised machine learning.Annals of Operations Research, pages 1–30, 2021
work page 2021
-
[59]
Alberto Lovison. Singular continuation: generating piecewise linear approximations to pareto sets via global analysis.SIAM Journal on Optimization, 21(2):463–490, 2011
work page 2011
-
[60]
Debabrata Mahapatra and Vaibhav Rajan. Multi-task learning with user preferences: Gradient descent with controlled ascent in Pareto optimization. InProc. Int. Conf. Machine Learn., virtual, 2020
work page 2020
-
[61]
R Timothy Marler and Jasbir S Arora. The weighted sum method for multi-objective optimization: new insights.Structural and multidisciplinary optimization, 41(6):853–862, 2010
work page 2010
-
[62]
Brice Martin, Alexandre Goldsztejn, Laurent Granvilliers, and Christophe Jermann. On continuation methods for non-linear bi-objective optimization: towards a certified interval-based approach.Journal of Global Optimization, 64(1):3–16, 2016
work page 2016
-
[63]
Kaisa Miettinen.Nonlinear Multiobjective Optimization, volume 12. Springer US, Boston, MA, 1998
work page 1998
-
[64]
A multi-objective/multi-task learning framework induced by Pareto stationarity
Michinari Momma, Chaosheng Dong, and Jia Liu. A multi-objective/multi-task learning framework induced by Pareto stationarity. InProc. Int. Conf. Machine Learn., Baltimore, MD, USA, 2022
work page 2022
-
[65]
Efficient memory-based learning for robot control
Andrew William Moore. Efficient memory-based learning for robot control. Technical report, University of Cambridge, 1990
work page 1990
-
[66]
Johannes Müller and Semih Cayci. Optimal rates of convergence for entropy regularization in discounted markov decision processes.Information and Inference: A Journal of the IMA, 15(1), 2026
work page 2026
-
[67]
Learning the pareto front with hypernet- works
Aviv Navon, Aviv Shamsian, Ethan Fetaya, and Gal Chechik. Learning the pareto front with hypernet- works. InProc. Int. Conf. Learn. Representations, virtual, April 2020
work page 2020
-
[68]
Cubic regularization of newton method and its global performance
Yurii Nesterov and Boris T Polyak. Cubic regularization of newton method and its global performance. Mathematical programming, 108(1):177–205, 2006
work page 2006
-
[69]
Victor Pereyra. Asynchronous distributed solution of large scale nonlinear inversion problems.Applied numerical mathematics, 30(1):31–40, 1999
work page 1999
-
[70]
Victor Pereyra. Fast computation of equispaced pareto manifolds and pareto fronts for multiobjective optimization problems.Mathematics and Computers in Simulation, 79(6):1935–1947, 2009
work page 1935
-
[71]
Victor Pereyra, Michael Saunders, and José Castillo. Equispaced pareto front construction for constrained bi-objective optimization.Mathematical and Computer Modelling, 57(9-10):2122–2131, 2013
work page 2013
-
[72]
Functional bilevel optimization for machine learning
Ieva Petrulionyte, Julien Mairal, and Michael Arbel. Functional bilevel optimization for machine learning. Advances in Neural Information Processing Systems, 37:14016–14065, 2024
work page 2024
-
[73]
Shuang Qiu, Dake Zhang, Rui Yang, Boxiang Lyu, and Tong Zhang. Traversing pareto optimal policies: Provably efficient multi-objective reinforcement learning.arXiv preprint arXiv:2407.17466, 2024
-
[74]
Qwen2.5 technical report, 2025
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
work page 2025
-
[75]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[76]
Alexandre Rame, Guillaume Couairon, Corentin Dancette, Jean-Baptiste Gaya, Mustafa Shukor, Laure Soulier, and Matthieu Cord. Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
work page 2023
-
[77]
Pareto conditioned networks.arXiv preprint arXiv:2204.05036, 2022
Mathieu Reymond, Eugenio Bargiacchi, and Ann Nowé. Pareto conditioned networks.arXiv preprint arXiv:2204.05036, 2022. 13
-
[78]
Multi-objective reinforcement learning for the expected utility of the return
Diederik M Roijers, Denis Steckelmacher, and Ann Nowé. Multi-objective reinforcement learning for the expected utility of the return. InProceedings of the Adaptive and Learning Agents workshop at FAIM, volume 2018, 2018
work page 2018
-
[79]
Diederik M Roijers, Peter Vamplew, Shimon Whiteson, and Richard Dazeley. A survey of multi-objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
work page 2013
-
[80]
Abhishek Roy, Geelon So, and Yi-An Ma. Optimization on pareto sets: On a theory of multi-objective optimization.arXiv preprint arXiv:2308.02145, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.