CoSPlay: Cooperative Self-Play at Test-Time with Self-Generated Code and Unit Test
Pith reviewed 2026-05-25 05:11 UTC · model grok-4.3
The pith
CoSPlay lets self-generated codes and unit tests iteratively refine each other at test time to improve LLM code generation without ground-truth data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
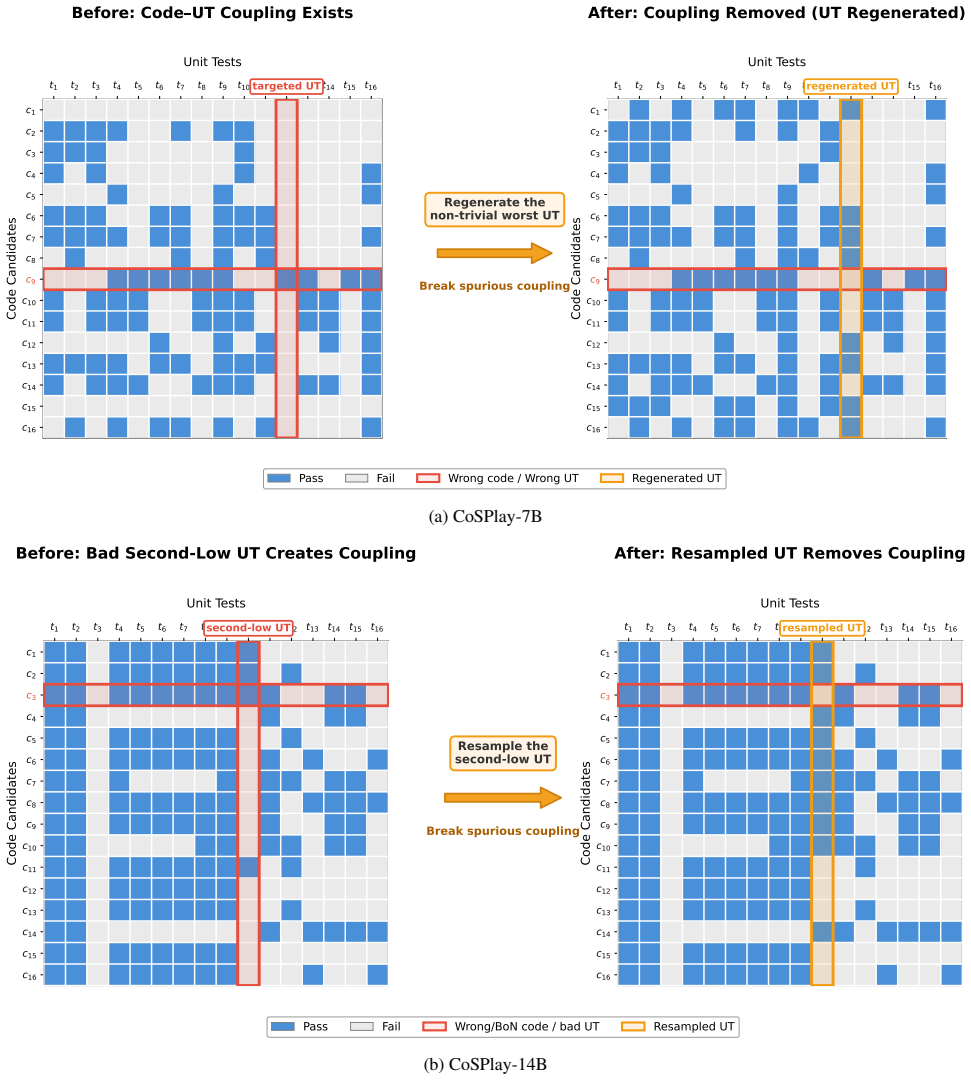
CoSPlay is a GT-free, training-free framework that jointly improves codes and UTs through cooperative self-play. It first explores diverse solution ideas and identifies their potential failure modes to produce discriminative UT ideas. It then uses bidirectional pass-count signals from the Code-UT execution matrix to iteratively prune or fix weak codes and refresh or replace unreliable UTs, letting the two pools co-evolve. Finally, when multiple codes remain tied at the highest pass count, it picks the final code from the largest output-consensus cluster, since correct codes agree on the same inputs while wrong codes diverge.
What carries the argument
The Code-UT execution matrix whose bidirectional pass-count signals drive iterative pruning of weak codes and replacement of unreliable unit tests, followed by output-consensus cluster selection on ties.
If this is right
- On Qwen2.5-7B-Instruct, average BoN rises from 22.1% to 33.2% and UT accuracy from 14.6% to 78.3%.
- The same procedure applied to the RLVR model CURE-7B adds another 5.7% BoN.
- The method generalizes across multiple model backbones and beats other GT-free test-time scaling baselines at equal token budgets.
- Performance continues to rise as the inference token budget increases.
Where Pith is reading between the lines
- If the co-evolution continues to improve with larger budgets, inference-time methods could reduce reliance on expensive RLVR training runs for code models.
- The consensus-cluster tie-breaker could extend to other verification settings where multiple candidates can be checked against one another rather than against external labels.
- The approach may apply to domains beyond code where executable verification is possible but ground-truth oracles are scarce.
Load-bearing premise
Bidirectional pass-count signals from the Code-UT execution matrix can reliably identify and prune weak codes while refreshing unreliable UTs, and correct codes will form the largest output-consensus cluster when pass counts tie.
What would settle it
Running the method on a benchmark where incorrect codes that share the same wrong outputs form the largest consensus cluster, or where pass counts show no correlation with actual correctness, would show whether performance gains disappear.
Figures
























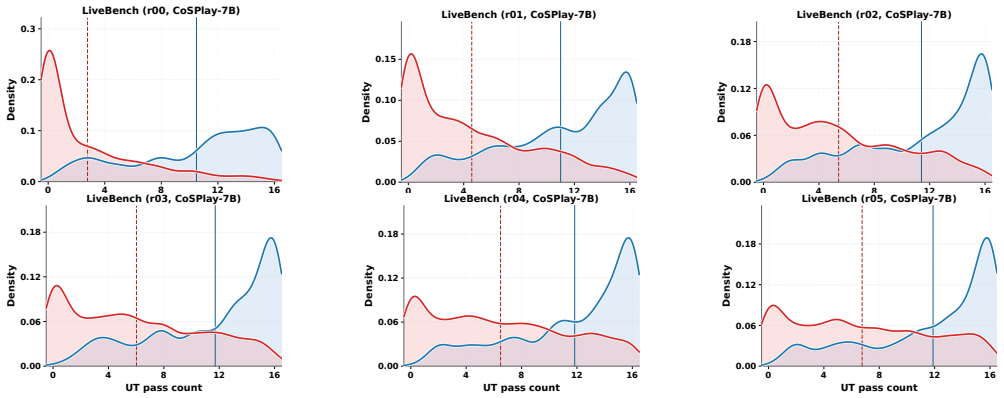

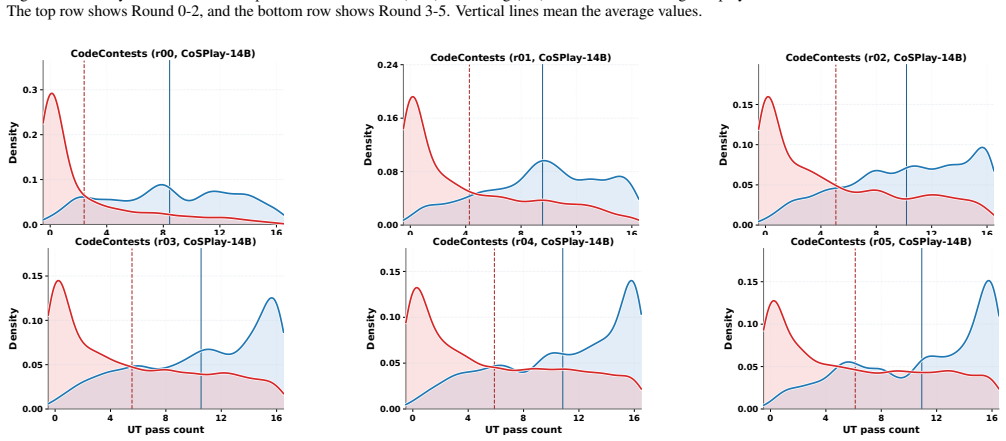





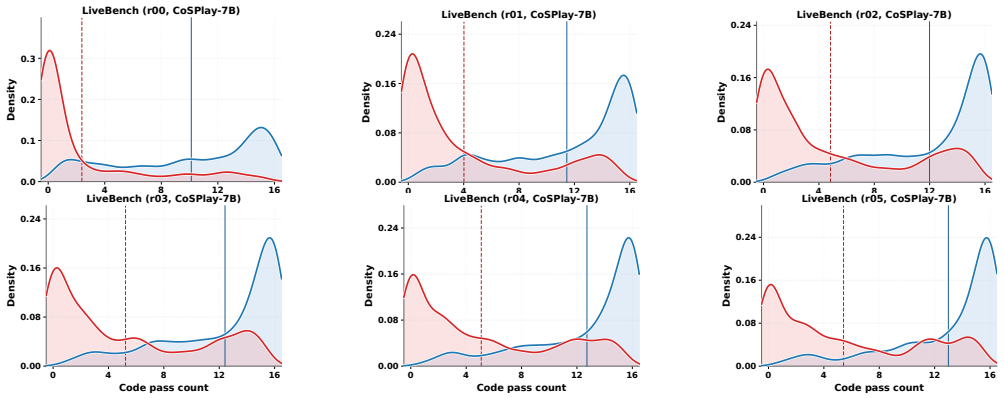



























read the original abstract
Recently, Reinforcement Learning with Verifiable Rewards (RLVR) and Test-Time Scaling (TTS) have advanced LLM code generation through executable verification. Yet Ground-Truth Unit Tests (GT UTs) remain a bottleneck: SOTA RLVR methods require them for costly training, while existing TTS methods lose competitiveness without them. This motivates GT-free TTS, where existing methods directly use self-generated UTs to refine and select code candidates. Yet such UTs are often noisy or spuriously coupled with wrong code, and UT quality in turn cannot be validated without reliable code. The key challenge is therefore to jointly improve both. To this end, we present CoSPlay, a GT-free, training-free framework that jointly improves codes and UTs through cooperative self-play. It first explores diverse solution ideas and identifies their potential failure modes to produce discriminative UT ideas. It then uses bidirectional pass-count signals from the Code-UT execution matrix to iteratively prune or fix weak codes and refresh or replace unreliable UTs, letting the two pools co-evolve. Finally, when multiple codes remain tied at the highest pass count, it picks the final code from the largest output-consensus cluster, since correct codes agree on the same inputs while wrong codes diverge. Experiments on four challenging benchmarks show that CoSPlay on Qwen2.5-7B-Instruct improves average BoN from 22.1% to 33.2% and UT accuracy from 14.6% to 78.3%, matching or surpassing the RLVR model CURE-7B. When applied to CURE-7B, it further improves BoN by 5.7%. CoSPlay also generalizes across diverse backbones and outperforms GT-free TTS baselines under comparable token budgets, with continued gains as the budget scales up. These results suggest a scalable inference strategy for competitive code generation without any GT data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoSPlay, a ground-truth-free and training-free test-time scaling framework for LLM code generation. It generates diverse code candidates and unit-test ideas, then uses bidirectional pass-count signals from the Code-UT execution matrix to iteratively prune weak codes and refresh unreliable UTs in a cooperative self-play loop. When pass counts tie, final selection uses the largest output-consensus cluster among remaining codes. Experiments on four benchmarks report that CoSPlay raises average BoN from 22.1% to 33.2% and UT accuracy from 14.6% to 78.3% on Qwen2.5-7B-Instruct (matching the RLVR baseline CURE-7B), yields an additional 5.7% BoN gain when applied to CURE-7B, and continues to improve with increased token budget across multiple backbones.
Significance. If the empirical gains are robust and the pass-count / consensus mechanism does not suffer from spurious coupling, the work would demonstrate a practical, scalable inference-time alternative to RLVR that eliminates the need for ground-truth unit tests. The reported generalization across backbones and continued scaling with budget would be notable strengths for test-time compute methods in code generation.
major comments (3)
- [Abstract (final selection paragraph)] Abstract, final selection paragraph: the claim that 'correct codes agree on the same inputs while wrong codes diverge' and therefore the largest consensus cluster is reliable is presented without counter-example analysis or formal argument. This assumption is load-bearing for the selection step; if multiple incorrect codes agree on the self-generated inputs while correct implementations differ on edge cases, the rule can select an incorrect solution.
- [Abstract (iterative co-evolution)] Abstract (iterative co-evolution description): the bidirectional pass-count signals are asserted to 'prune or fix weak codes and refresh or replace unreliable UTs' without any reported ablation on the pruning thresholds, refresh rules, or error analysis of cases where spuriously coupled wrong code-UT pairs reinforce each other. This mechanism is central to the claimed joint improvement and to the GT-free claim.
- [Abstract (experiments)] Abstract (experimental claims): the reported BoN and UT-accuracy lifts (22.1% → 33.2%, 14.6% → 78.3%) and the 5.7% gain on CURE-7B are stated without reference to ablation tables, variance across runs, or controls for post-hoc selection of the number of iterations or matrix size, making it impossible to assess whether the gains are attributable to the proposed co-evolution or to implementation artifacts.
minor comments (1)
- [Abstract] The abstract does not define the precise notion of 'output-consensus cluster' (e.g., whether it is measured by exact output equality or by some normalized distance), which should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive criticism. We address each of the major comments point by point, providing clarifications on our assumptions, mechanisms, and experimental reporting. We believe these responses strengthen the manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: Abstract, final selection paragraph: the claim that 'correct codes agree on the same inputs while wrong codes diverge' and therefore the largest consensus cluster is reliable is presented without counter-example analysis or formal argument. This assumption is load-bearing for the selection step; if multiple incorrect codes agree on the self-generated inputs while correct implementations differ on edge cases, the rule can select an incorrect solution.
Authors: We acknowledge that the assumption underlying the consensus-based selection is heuristic rather than formally proven. The rationale is that for a given set of inputs (from the UTs), correct code implementations must produce identical outputs by definition, while incorrect implementations tend to produce divergent outputs, particularly on the discriminative tests generated by our method. This is supported by the observed performance improvements and the clustering results in our experiments. However, we agree that discussing potential counterexamples would be beneficial. In the revised manuscript, we will add a paragraph in the method section discussing this assumption, including analysis of cases where it might fail and how the co-evolution mitigates such risks. revision: partial
-
Referee: Abstract (iterative co-evolution description): the bidirectional pass-count signals are asserted to 'prune or fix weak codes and refresh or replace unreliable UTs' without any reported ablation on the pruning thresholds, refresh rules, or error analysis of cases where spuriously coupled wrong code-UT pairs reinforce each other. This mechanism is central to the claimed joint improvement and to the GT-free claim.
Authors: The full manuscript provides ablations on the number of iterations, the size of the code and UT pools, and the impact of the pass-count thresholds in Section 4. We also analyze the evolution of pass rates over iterations to show that the process improves both pools without collapse. Regarding spurious coupling, the bidirectional update is intended to detect and refresh unreliable UTs by cross-referencing with multiple codes. We will expand the experimental section with a dedicated subsection on failure modes and error analysis of potential spurious reinforcements, including examples from the benchmarks. revision: partial
-
Referee: Abstract (experimental claims): the reported BoN and UT-accuracy lifts (22.1% → 33.2%, 14.6% → 78.3%) and the 5.7% gain on CURE-7B are stated without reference to ablation tables, variance across runs, or controls for post-hoc selection of the number of iterations or matrix size, making it impossible to assess whether the gains are attributable to the proposed co-evolution or to implementation artifacts.
Authors: The abstract summarizes the main results, while the full paper includes detailed ablation studies on token budget, iteration count, and matrix dimensions (Tables 3-5), showing consistent gains across configurations. Results are averaged over 3 random seeds where stochasticity is present, with standard deviations reported in the appendix. The iteration count is determined by a fixed schedule based on the token budget rather than post-hoc selection. We will update the abstract to include a brief reference to these supporting analyses and ensure all variance metrics are clearly linked in the main text. revision: yes
Circularity Check
No significant circularity; method is heuristic-based and empirically validated
full rationale
The paper describes a training-free, GT-free iterative procedure that generates codes and UTs, executes them to obtain pass-count signals from the Code-UT matrix, prunes based on those counts, and selects via output-consensus clustering. No equations, parameters, or derivations are presented that reduce the final output to the inputs by construction. The central selection rule (largest consensus cluster when pass counts tie) is justified by an external assumption about correct vs. incorrect behavior rather than being defined in terms of itself. No self-citations are invoked as load-bearing uniqueness theorems, and performance claims are measured on external benchmarks rather than fitted quantities. The approach is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Correct codes agree on outputs for the same inputs while incorrect codes diverge.
- domain assumption Bidirectional pass-count signals suffice to distinguish and repair weak codes and unreliable UTs.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.