EDGE-OPD: Internalizing Privileged Context with Evidence Guided On-Policy Distillation
Pith reviewed 2026-05-25 04:20 UTC · model grok-4.3
The pith
EDGE-OPD lets models internalize privileged context like personas during on-policy distillation by using guided rollouts and evidence masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
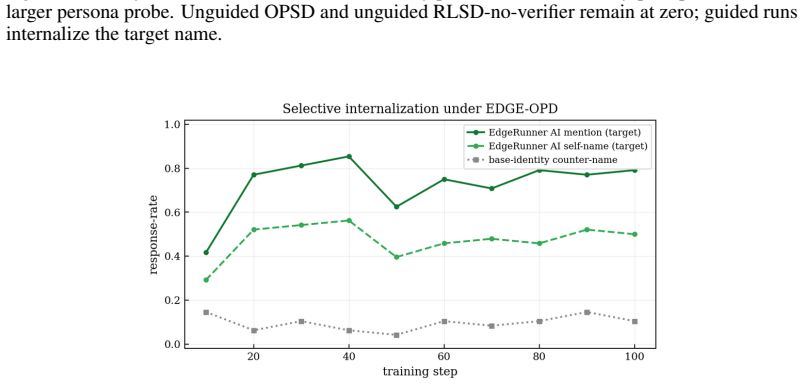
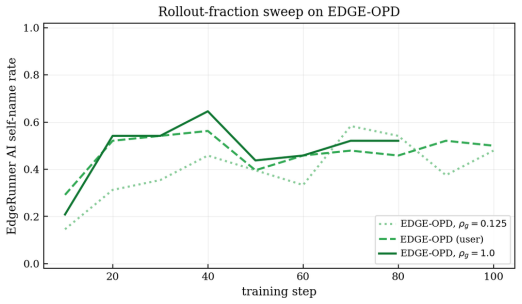
OPSD and its RLSD variant, with or without a verifier, completely fail to learn a target identity in a rare-token setting, while EDGE-OPD succeeds once guided rollouts inject the privileged-context behavior into the on-policy data and an evidence mask restricts updates to tokens supported by that context. Mask-region ablations further show that the persona signal concentrates in the positive-evidence tail.
What carries the argument
The evidence mask, which restricts student updates to only those token positions where the privileged context supports the sampled token.
If this is right
- Unmodified OPSD and RLSD fail to learn the target identity even when a verifier is present.
- Adding guided rollouts enables the target behavior to appear in the training data and allows successful learning.
- The persona signal localizes specifically to the positive-evidence tail rather than the full rollout.
- Selective updates on supported tokens support knowledge transfer while helping preserve general-purpose capabilities.
Where Pith is reading between the lines
- The same guided-rollout and masking approach could be tested on other privileged signals such as private facts or step-by-step solutions.
- Masking might reduce unintended distribution shifts in distillation methods beyond the identity-learning case examined here.
- Ablation-style localization of signals could be applied to measure how much of any privileged context actually drives behavior change.
Load-bearing premise
The evidence mask correctly identifies only the tokens where privileged context supports the sampled token without excluding necessary reasoning steps or introducing selection bias that affects the learned behavior.
What would settle it
Training the same models without the evidence mask or without guided rollouts and observing whether the target identity remains unlearned while side effects on style and length appear instead.
Figures




read the original abstract
On-Policy Distillation (OPD) has gained wide attraction as an LLM post-training paradigm due to its effectiveness in improving capabilities without introducing model distribution drift, and consequently, regression in general tasks. On-Policy Self-Distillation (OPSD) is an efficient use-case of OPD, which is appealing as it requires only a single model as a student and teacher, and it also has the benefit of providing privileged context that is a absent at inference time (e.g. a persona, a private fact, or a worked solution) to the teacher during the training process. The challenge in this approach is that the privileged information can change model behavior more than intended: it can modify reasoning, degrade general capabilities, and affect performance indicators like response length, style, or local token preferences. Consequently, OPSD may train the student on side effects rather than a desired, transferable behavior. In this paper, we study this problem in a rare-token/identity setting and propose EviDence GuidEd On-Policy Distillation (EDGE-OPD), a modification of OPSD with two distinct characteristics: a) it uses guided rollouts to inject privileged-context behavior to the student at sampling time, so that the rare target behavior is actually present in the on-policy data, and b) it applies an evidence mask: the student is updated only at token positions where the privileged context supports the sampled token, rather than on every token in the rollout. We empirically show that OPSD (and its variant RLSD, with and without a verifier) completely fail to learn a target identity, while the integration of guided rollouts allows them to succeed. Additionally, mask-region ablations show that the persona signal is localized to the positive-evidence tail, allows us to draw valuable insights about efficient knowledge transfer and preservation of general purpose capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EDGE-OPD, a modification of On-Policy Self-Distillation (OPSD) that adds guided rollouts (to ensure target identity behavior appears in on-policy data) and an evidence mask (restricting gradient updates to tokens where privileged context supports the sampled token). It claims that OPSD and RLSD variants (with/without verifier) completely fail to learn a target identity in a rare-token setting, while EDGE-OPD succeeds, and that mask-region ablations localize the persona signal to the positive-evidence tail.
Significance. If the empirical claims hold, the method would offer a targeted way to internalize privileged context (persona, private facts) during post-training while avoiding side effects on reasoning, length, style, or general capabilities. The ablation results on evidence localization could provide reusable insight into efficient knowledge transfer in on-policy distillation.
major comments (2)
- [§3] §3 (Method, evidence mask definition): The construction of the evidence mask is not specified (e.g., whether it uses token-level log-probability difference between teacher with/without privileged context, attribution, or a heuristic threshold). This is load-bearing for the central claim, because the reported success of EDGE-OPD over OPSD is attributed to restricting updates to 'supported' tokens; without the exact procedure, it is impossible to assess whether the mask excludes persona-dependent reasoning steps or introduces selection bias toward high-evidence tokens.
- [§4] §4 (Experiments): The abstract states that OPSD/RLSD 'completely fail' while EDGE-OPD succeeds and that mask-region ablations localize the signal, yet no metrics, baselines, success criteria for 'learning the target identity,' or quantitative ablation numbers are supplied. Without these, the empirical distinction cannot be evaluated and the ablation cannot be confirmed to isolate the intended mechanism rather than the guided rollouts alone.
minor comments (1)
- [Abstract] Abstract: the phrase 'mask-region ablations show that the persona signal is localized to the positive-evidence tail' should be accompanied by a brief definition of the regions or a forward reference to the relevant table/figure.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment point by point below and will make revisions where the manuscript requires additional detail or quantitative support.
read point-by-point responses
-
Referee: [§3] §3 (Method, evidence mask definition): The construction of the evidence mask is not specified (e.g., whether it uses token-level log-probability difference between teacher with/without privileged context, attribution, or a heuristic threshold). This is load-bearing for the central claim, because the reported success of EDGE-OPD over OPSD is attributed to restricting updates to 'supported' tokens; without the exact procedure, it is impossible to assess whether the mask excludes persona-dependent reasoning steps or introduces selection bias toward high-evidence tokens.
Authors: We agree that the precise construction of the evidence mask must be specified for reproducibility and to allow evaluation of the mechanism. The manuscript currently describes the mask conceptually as restricting updates to tokens where the privileged context supports the sampled token. In the revised version we will expand the method section to provide the exact procedure, including how support is determined and any thresholds applied. This will permit readers to assess potential biases or effects on reasoning steps. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract states that OPSD/RLSD 'completely fail' while EDGE-OPD succeeds and that mask-region ablations localize the signal, yet no metrics, baselines, success criteria for 'learning the target identity,' or quantitative ablation numbers are supplied. Without these, the empirical distinction cannot be evaluated and the ablation cannot be confirmed to isolate the intended mechanism rather than the guided rollouts alone.
Authors: We acknowledge that stronger quantitative reporting is needed to substantiate the claims in the abstract and §4. Although the manuscript reports the qualitative outcomes, the revision will add explicit metrics for target identity learning, success criteria, full baseline comparisons (including OPSD and RLSD variants with and without verifier), and numerical results from the mask-region ablations. These additions will allow direct evaluation of the empirical distinctions and the contribution of the evidence mask. revision: yes
Circularity Check
No circularity: purely empirical method with no derivations
full rationale
The paper describes an empirical technique (guided rollouts + evidence mask) for on-policy distillation and reports experimental comparisons showing OPSD fails while EDGE-OPD succeeds. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The evidence mask is introduced as a design choice rather than derived from prior results by the same authors. This matches the default expectation of no circularity for non-derivational empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GKD: Generalized knowledge distillation for auto-regressive sequence models
Rishabh Agarwal, Nino Vieillard, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. GKD: Generalized knowledge distillation for auto-regressive sequence models. In Advances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems, volume 35, pages 17359–17372, 2022
work page 2022
-
[7]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale. InInternational Conference on Learning Representations, 2022
work page 2022
-
[8]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
work page 2022
-
[9]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y K Li, Y Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 9798400711961. doi: ...
-
[12]
Thinking Machines Lab. On-policy distillation. https://thinkingmachines.ai/blog/o n-policy-distillation/, 2025. Blog post, accessed 2026-05-07
work page 2025
-
[13]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Inspect AI: Framework for large language model evaluations, May
UK AI Security Institute. Inspect AI: Framework for large language model evaluations, May
-
[15]
URLhttps://inspect.aisi.org.uk/
-
[16]
Vladimir Vapnik and Rauf Izmailov. Learning using privileged information: Similarity control and knowledge transfer.Journal of Machine Learning Research, 16(61):2023–2049, 2015
work page 2023
-
[17]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled RLVR.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proc. VLDB Endow., 16(12):3848–3860, August 20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.