Uncertainty-DTW for Sequences and Visual Tokens
Pith reviewed 2026-06-30 11:56 UTC · model grok-4.3
The pith
Uncertainty-DTW models each match as a Normal distribution to suppress unreliable features during sequence and visual token alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our formulation, uncertainty-DTW (uDTW), assigns each correspondence a Normal distribution and parametrizes each alignment path by a Maximum Likelihood Estimate objective consisting of (i) a precision-weighted matching term that suppresses unreliable features, and (ii) a log-variance regularization that prevents degenerate solutions. This yields a probabilistic alignment mechanism that is robust to noise and interpretable, as uncertainty directly reflects the reliability of matches. We further generalize this framework from temporal sequences to tokenized visual representations.
What carries the argument
uncertainty-DTW (uDTW), which assigns independent Normal distributions to pairwise correspondences and optimizes each alignment path via an MLE objective combining precision-weighted matching with log-variance regularization
If this is right
- Alignments become robust to heterogeneous and noisy features through the precision-weighted term.
- Uncertainty values directly indicate match reliability and serve as an interpretable reverse-attention signal.
- Structured matching extends naturally from sequences to unordered sets of visual tokens.
- Evaluations show that learned uncertainty correlates with semantic importance across domains.
Where Pith is reading between the lines
- The reverse-attention property could let uncertainty scores replace hand-crafted attention maps in downstream vision pipelines.
- The same Normal-distribution formulation might stabilize differentiable alignment layers inside larger neural networks.
- If the variance regularization works as claimed, similar uncertainty terms could be added to other matching objectives such as optimal transport.
Load-bearing premise
Modeling each pairwise correspondence as an independent Normal distribution with learnable variance, combined with the proposed MLE objective, produces alignments that are robust to noise and semantically meaningful.
What would settle it
An experiment on noisy sequence or visual-token datasets in which uDTW alignments show no improvement over deterministic DTW or in which learned uncertainties fail to correlate with unreliable or ambiguous regions would falsify the central claim.
Figures



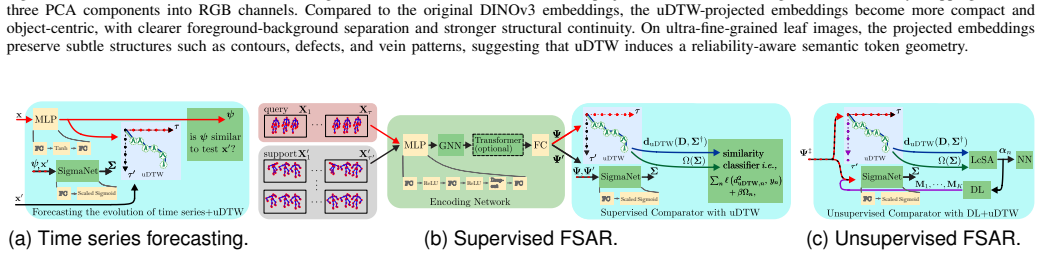
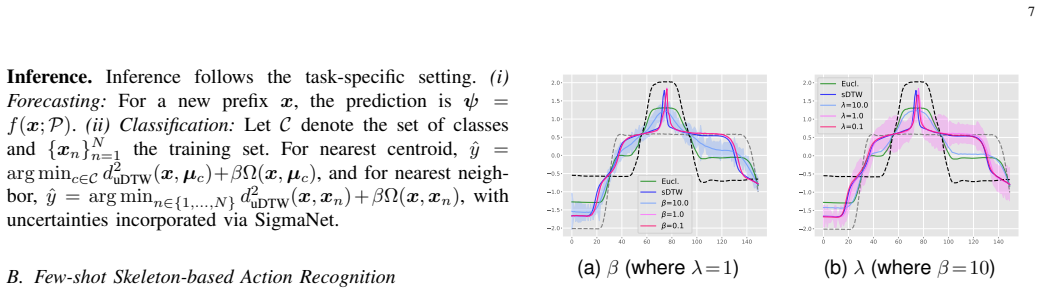
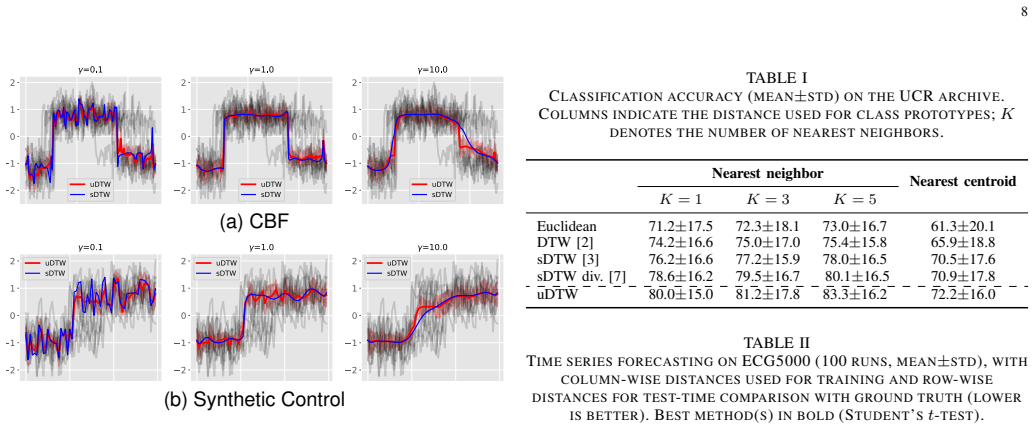

read the original abstract
Aligning structured data is a fundamental problem in computer vision and machine learning, underlying tasks such as time series analysis, human action recognition, and visual representation learning. Existing alignment methods, including Dynamic Time Warping (DTW) and its differentiable variants, rely on deterministic similarity measures and are therefore sensitive to heterogeneous and noisy features. In this work, we introduce uncertainty-aware alignment, a probabilistic framework that models pairwise correspondences with heteroscedastic uncertainty and performs structured matching along alignment paths. Our formulation, uncertainty-DTW (uDTW), assigns each correspondence a Normal distribution and parametrizes each alignment path by a Maximum Likelihood Estimate objective consisting of (i) a precision-weighted matching term that suppresses unreliable features, and (ii) a log-variance regularization that prevents degenerate solutions. This yields a probabilistic alignment mechanism that is robust to noise and interpretable, as uncertainty directly reflects the reliability of matches. We further generalize this framework from temporal sequences to tokenized visual representations, enabling structured matching over sets of visual tokens. The learned uncertainty can be interpreted as a reverse-attention: semantically relevant regions exhibit low uncertainty and dominate the alignment, while ambiguous/noisy regions have high uncertainty. This provides a connection between alignment, attention, and uncertainty modeling. We evaluate the proposed framework across diverse domains. The results demonstrate consistent improvements over state-of-the-art methods and show that learned uncertainty correlates with semantic importance. These findings establish uncertainty-aware alignment as a general, robust, and interpretable framework for learning from structured data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces uncertainty-DTW (uDTW), a probabilistic framework for sequence and visual token alignment. It models each pairwise correspondence as a Normal distribution with learnable heteroscedastic variance and selects paths via an MLE objective consisting of a precision-weighted matching term (to suppress unreliable features) plus a log-variance regularizer (to avoid degeneracies). The approach is extended to tokenized visual representations, with learned uncertainty interpreted as reverse-attention that highlights semantically relevant regions. Experiments across domains are reported to show consistent gains over SOTA methods and correlation between uncertainty and semantic importance.
Significance. If the central formulation holds, the work offers a principled probabilistic treatment of uncertainty within DTW-style alignment, potentially improving robustness in noisy CV tasks such as action recognition and token matching. The explicit link between alignment, uncertainty, and attention mechanisms is a conceptual contribution that could influence future hybrid models, provided the probabilistic justification and empirical gains are substantiated.
major comments (2)
- [§3 (MLE objective)] The MLE objective (abstract and §3 formulation) factorizes the log-likelihood as a sum of independent per-correspondence terms (precision-weighted squared error + log-variance). Because valid alignment paths are constrained by monotonicity and continuity (standard DTW recurrence), the selected matches are statistically dependent; the independence assumption therefore renders the joint likelihood misspecified. This directly affects the claimed suppression of unreliable features and the reverse-attention interpretation, as the regularization term cannot compensate for the missing path-level joint structure.
- [§3 and experimental sections] No derivation or justification is supplied for why the constrained-path likelihood can be safely factorized, nor is there an ablation comparing the proposed objective against a properly joint formulation (e.g., via dynamic programming that respects the constraints inside the likelihood). Without this, the robustness and interpretability claims rest on an unverified modeling choice.
minor comments (2)
- The abstract states that results demonstrate improvements and semantic correlation, yet the provided text supplies no quantitative tables, dataset names, or metric values; these must be added for reproducibility.
- [§3] Notation for the Normal parameters (mean, variance) and the precise form of the precision-weighted term should be introduced with explicit equations rather than prose descriptions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. The comments highlight important aspects of the probabilistic formulation that warrant further clarification. We provide point-by-point responses below and will update the manuscript to address these issues.
read point-by-point responses
-
Referee: [§3 (MLE objective)] The MLE objective (abstract and §3 formulation) factorizes the log-likelihood as a sum of independent per-correspondence terms (precision-weighted squared error + log-variance). Because valid alignment paths are constrained by monotonicity and continuity (standard DTW recurrence), the selected matches are statistically dependent; the independence assumption therefore renders the joint likelihood misspecified. This directly affects the claimed suppression of unreliable features and the reverse-attention interpretation, as the regularization term cannot compensate for the missing path-level joint structure.
Authors: We agree that the path constraints introduce dependencies among the selected correspondences. Our model assumes that, conditional on the alignment path, the correspondences are independent, with each pair having its own heteroscedastic variance. The dynamic programming procedure then selects the path that maximizes the factorized likelihood. This factorization enables efficient computation and is analogous to the emission probabilities in a hidden Markov model, where observations are independent given the state sequence, but the sequence is constrained by transition probabilities. We will revise §3 to include a formal derivation of the likelihood under this conditional independence assumption and discuss its implications for the uncertainty interpretation. The reverse-attention view follows from the learned variances reflecting match reliability within the selected path. revision: yes
-
Referee: [§3 and experimental sections] No derivation or justification is supplied for why the constrained-path likelihood can be safely factorized, nor is there an ablation comparing the proposed objective against a properly joint formulation (e.g., via dynamic programming that respects the constraints inside the likelihood). Without this, the robustness and interpretability claims rest on an unverified modeling choice.
Authors: As noted above, we will add the derivation and justification in the revised manuscript. For the ablation, a fully joint formulation would involve computing the marginal likelihood over all valid paths, which is computationally prohibitive for long sequences. Our approach uses the maximum a posteriori path under the factorized model, which is standard in DTW variants. We will include a discussion of this approximation and, if feasible within the revision timeline, an ablation on short sequences comparing to a brute-force joint computation. This will substantiate the modeling choice. revision: partial
Circularity Check
No circularity: uDTW is a direct modeling proposal using standard MLE on independent Normals
full rationale
The abstract and description present uDTW as a new formulation that assigns Normal distributions to pairwise correspondences and defines an MLE objective consisting of a precision-weighted matching term plus log-variance regularization. This is a modeling choice grounded in standard probabilistic assumptions rather than any reduction of a claimed result to fitted inputs or self-citations. No equations, derivations, or load-bearing steps are shown that equate outputs to inputs by construction. The independence assumption and path parametrization are explicit design decisions, not hidden circularities. The paper is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pairwise correspondences follow independent Normal distributions with heteroscedastic variances.
- domain assumption Alignment paths can be parametrized by maximizing the likelihood under the stated MLE objective.
Reference graph
Works this paper leans on
-
[1]
Dynamic accumulated attention map for interpreting evolution of decision-making in vision transformer,
Y . Liao, Y . Gao, and W. Zhang, “Dynamic accumulated attention map for interpreting evolution of decision-making in vision transformer,”Pattern Recognition, vol. 165, p. 111607, 2025
2025
-
[2]
Fast global alignment kernels,
M. Cuturi, “Fast global alignment kernels,” inInternational Conference on Machine Learning (ICML), 2011, pp. 929–936
2011
-
[3]
Soft-dtw: a differentiable loss function for time-series,
M. Cuturi and M. Blondel, “Soft-dtw: a differentiable loss function for time-series,” inInternational Conference on Machine Learning (ICML). PMLR, 2017, pp. 894–903
2017
-
[4]
Temporal-viewpoint transportation plan for skeletal few-shot action recognition,
L. Wang and P. Koniusz, “Temporal-viewpoint transportation plan for skeletal few-shot action recognition,” inAsian conference on computer vision (ACCV), 2022, pp. 4176–4193
2022
-
[5]
Uncertainty-dtw for time series and sequences,
——, “Uncertainty-dtw for time series and sequences,” inEuropean Conference on Computer Vision (ECCV), 2022, pp. 176–195
2022
-
[6]
Meet jeanie: a similarity measure for 3d skeleton sequences via temporal-viewpoint alignment,
L. Wang, J. Liu, L. Zheng, T. Gedeon, and P. Koniusz, “Meet jeanie: a similarity measure for 3d skeleton sequences via temporal-viewpoint alignment,”International Journal of Computer Vision, vol. 132, no. 9, pp. 4091–4122, 2024
2024
-
[7]
Differentiable divergences be- tween time series,
M. Blondel, A. Mensch, and J.-P. Vert, “Differentiable divergences be- tween time series,” inInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2021, pp. 3853–3861
2021
-
[8]
Drop- dtw: Aligning common signal between sequences while dropping out- liers,
M. Dvornik, I. Hadji, K. G. Derpanis, A. Garg, and A. Jepson, “Drop- dtw: Aligning common signal between sequences while dropping out- liers,”Advances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 13 782–13 793, 2021
2021
-
[9]
Temporal alignment prediction for supervised representation learning and few-shot sequence classification,
B. Su and J.-R. Wen, “Temporal alignment prediction for supervised representation learning and few-shot sequence classification,” inInter- national Conference on Learning Representations (ICLR), 2022
2022
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2020
2020
-
[11]
Dynam- icvit: Efficient vision transformers with dynamic token sparsification,
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh, “Dynam- icvit: Efficient vision transformers with dynamic token sparsification,” Advances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 13 937–13 949, 2021
2021
-
[12]
Motion meets attention: Video motion prompts,
Q. Chen, L. Wang, P. Koniusz, and T. Gedeon, “Motion meets attention: Video motion prompts,” inAsian Conference on Machine Learning (ACML), 2024, pp. 591–606
2024
-
[13]
Dtwnet: A dynamic time warping network,
X. Cai, T. Xu, J. Yi, J. Huang, and S. Rajasekaran, “Dtwnet: A dynamic time warping network,”Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[14]
Dtw-nn: A novel neural network for time series recognition using dynamic alignment between inputs and weights,
B. K. Iwana, V . Frinken, and S. Uchida, “Dtw-nn: A novel neural network for time series recognition using dynamic alignment between inputs and weights,”Knowledge-Based Systems, vol. 188, p. 104971, 2020. 12
2020
-
[15]
Deep attentive time warping,
S. Matsuo, X. Wu, G. Atarsaikhan, A. Kimura, K. Kashino, B. K. Iwana, and S. Uchida, “Deep attentive time warping,”Pattern Recognition, vol. 136, p. 109201, 2023
2023
-
[16]
Recent advances in optimal transport for machine learning,
E. F. Montesuma, F. M. N. Mboula, and A. Souloumiac, “Recent advances in optimal transport for machine learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 2, pp. 1161– 1180, 2024
2024
-
[17]
Sinkhorn distances: Lightspeed computation of opti- mal transport,
M. Cuturi, “Sinkhorn distances: Lightspeed computation of opti- mal transport,”Advances in Neural Information Processing Systems (NeurIPS), vol. 26, 2013
2013
-
[18]
Hierarchical optimal transport for multimodal distribution alignment,
J. Lee, M. Dabagia, E. Dyer, and C. Rozell, “Hierarchical optimal transport for multimodal distribution alignment,”Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[19]
Spatio-temporal alignments: Optimal transport through space and time,
H. Janati, M. Cuturi, and A. Gramfort, “Spatio-temporal alignments: Optimal transport through space and time,” inInternational Conference on Artificial Intelligence and Statistics (AISTATS). PMLR, 2020, pp. 1695–1704
2020
-
[20]
Toward accurate dynamic time warping in linear time and space,
S. Salvador and P. Chan, “Toward accurate dynamic time warping in linear time and space,”Intelligent Data Analysis, vol. 11, no. 5, pp. 561–580, 2007
2007
-
[21]
Dynamic time warping algorithm review,
P. Senin, “Dynamic time warping algorithm review,”Information and Computer Science Department University of Hawaii at Manoa Honolulu, USA, vol. 855, no. 1-23, p. 40, 2008
2008
-
[22]
Time warp edit distance with stiffness adjustment for time series matching,
P.-F. Marteau, “Time warp edit distance with stiffness adjustment for time series matching,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 2, pp. 306–318, 2008
2008
-
[23]
Deep metric learning using triplet network,
E. Hoffer and N. Ailon, “Deep metric learning using triplet network,” inInternational Workshop on Similarity-Based Pattern Recognition. Springer, 2015, pp. 84–92
2015
-
[24]
Superglue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superglue: Learning feature matching with graph neural networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4938–4947
2020
-
[25]
Token-label alignment for vision transformers,
H. Xiao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “Token-label alignment for vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 5495–5504
2023
-
[26]
Scale-aware token-matching for transformer-based object detector,
A. Jung, S. Hong, and Y . Hyun, “Scale-aware token-matching for transformer-based object detector,”Pattern Recognition Letters, vol. 185, pp. 197–202, 2024
2024
-
[27]
Madtp: Multi- modal alignment-guided dynamic token pruning for accelerating vision- language transformer,
J. Cao, P. Ye, S. Li, C. Yu, Y . Tang, J. Lu, and T. Chen, “Madtp: Multi- modal alignment-guided dynamic token pruning for accelerating vision- language transformer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15 710–15 719
2024
-
[28]
Simple spectral graph convolution,
H. Zhu and P. Koniusz, “Simple spectral graph convolution,” in International Conference on Learning Representations (ICLR), 2021. [Online]. Available: https://openreview.net/forum?id=CYO5T-YjWZV
2021
-
[29]
In defense of soft-assignment coding,
L. Liu, L. Wang, and X. Liu, “In defense of soft-assignment coding,” in The IEEE International Conference on Computer Vision (ICCV), 2011, pp. 2486–2493
2011
-
[30]
The ucr time series archive,
H. A. Dau, A. Bagnall, K. Kamgar, C.-C. M. Yeh, Y . Zhu, S. Gharghabi, C. A. Ratanamahatana, and E. Keogh, “The ucr time series archive,” IEEE/CAA Journal of Automatica Sinica, vol. 6, no. 6, pp. 1293–1305, 2019
2019
-
[31]
Ntu rgb+ d: A large scale dataset for 3d human activity analysis,
A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “Ntu rgb+ d: A large scale dataset for 3d human activity analysis,” inThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1010– 1019
2016
-
[32]
Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,
J. Liu, A. Shahroudy, M. Perez, G. Wang, L.-Y . Duan, and A. C. Kot, “Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 10, pp. 2684–2701, 2019
2019
-
[33]
The Kinetics Human Action Video Dataset
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsevet al., “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Matching networks for one shot learning,
O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstraet al., “Matching networks for one shot learning,”Advances in Neural Information Pro- cessing Systems (NeurIPS), vol. 29, 2016
2016
-
[35]
Prototypical networks for few- shot learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few- shot learning,”Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[36]
Meta-learning with differentiable closed-form solvers,
L. Bertinetto, J. F. Henriques, P. Torr, and A. Vedaldi, “Meta-learning with differentiable closed-form solvers,” inInternational Conference on Learning Representations (ICLR), 2019. [Online]. Available: https://openreview.net/forum?id=HyxnZh0ct7
2019
-
[37]
Meta-learning for semi-supervised few-shot classification,
M. Ren, S. Ravi, E. Triantafillou, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, “Meta-learning for semi-supervised few-shot classification,” inInternational Conference on Learning Representations (ICLR), 2018. [Online]. Available: https://openreview.net/forum?id=HJcSzz-CZ
2018
-
[38]
The caltech-ucsd birds-200-2011 dataset,
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,” 2011
2011
-
[39]
Novel dataset for fine-grained image categorization: Stanford dogs,
A. Khosla, N. Jayadevaprakash, B. Yao, and F.-F. Li, “Novel dataset for fine-grained image categorization: Stanford dogs,” inThe IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), vol. 2, no. 1, 2011
2011
-
[40]
3d object representations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3d object representations for fine-grained categorization,” inThe IEEE International Conference on Computer Vision Workshops (ICCVW), 2013, pp. 554–561
2013
-
[41]
Fine-Grained Visual Classification of Aircraft
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, “Fine- grained visual classification of aircraft,”arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[42]
Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection,
G. Van Horn, S. Branson, R. Farrell, S. Haber, J. Barry, P. Ipeirotis, P. Perona, and S. Belongie, “Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection,” inThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 595–604
2015
-
[43]
Benchmark platform for ultra-fine-grained visual categorization beyond human performance,
X. Yu, Y . Zhao, Y . Gao, X. Yuan, and S. Xiong, “Benchmark platform for ultra-fine-grained visual categorization beyond human performance,” in The IEEE International Conference on Computer Vision (ICCV), 2021, pp. 10 285–10 295
2021
-
[44]
Human-level concept learning through probabilistic program induction,
B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum, “Human-level concept learning through probabilistic program induction,”Science, vol. 350, no. 6266, pp. 1332–1338, 2015
2015
-
[45]
Boosting learning efficiency in few-shot tasks with layer-adaptive pid control,
P. Zhang, X. Li, L. Yu, Z. Zhang, F. Dunkin, H. Liu, and Z. Li, “Boosting learning efficiency in few-shot tasks with layer-adaptive pid control,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[46]
Class-aware patch embedding adaptation for few-shot image classification,
F. Hao, F. He, L. Liu, F. Wu, D. Tao, and J. Cheng, “Class-aware patch embedding adaptation for few-shot image classification,” inThe IEEE International Conference on Computer Vision (ICCV), 2023, pp. 18 905– 18 915
2023
-
[47]
Adaptive saliency based contextual metric learning for few-shot open-set recognition,
P. Li, J. Chen, L. Shang, and C. Ping, “Adaptive saliency based contextual metric learning for few-shot open-set recognition,”Pattern Recognition, p. 113096, 2026
2026
-
[48]
Unsupervised learning via meta- learning,
K. Hsu, S. Levine, and C. Finn, “Unsupervised learning via meta- learning,” inInternational Conference on Learning Representations (ICLR), 2019. [Online]. Available: https://openreview.net/forum?id= r1My6sR9tX
2019
-
[49]
Unsupervised meta-learning for few-shot image classification,
S. Khodadadeh, L. Boloni, and M. Shah, “Unsupervised meta-learning for few-shot image classification,”Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[50]
Unsupervised meta-learning through latent-space interpolation in generative models,
S. Khodadadeh, S. Zehtabian, S. Vahidian, W. Wang, B. Lin, and L. Boloni, “Unsupervised meta-learning through latent-space interpolation in generative models,” inInternational Conference on Learning Representations (ICLR), 2021. [Online]. Available: https://openreview.net/forum?id=XOjv2HxIF6i
2021
-
[51]
Unsupervised meta-learning via few-shot pseudo-supervised contrastive learning,
H. Jang, H. Lee, and J. Shin, “Unsupervised meta-learning via few-shot pseudo-supervised contrastive learning,” inInternational Conference on Learning Representations (ICLR), 2023. [Online]. Available: https://openreview.net/forum?id=TdTGGj7fYYJ
2023
-
[52]
Meta-GMV AE: Mixture of gaussian V AE for unsupervised meta-learning,
D. B. Lee, D. Min, S. Lee, and S. J. Hwang, “Meta-GMV AE: Mixture of gaussian V AE for unsupervised meta-learning,” inInternational Conference on Learning Representations (ICLR), 2021. [Online]. Available: https://openreview.net/forum?id=wS0UFjsNYjn
2021
-
[53]
Unsupervised meta-learning via latent space energy-based model of symbol vector coupling,
D. Kong, B. Pang, and Y . N. Wu, “Unsupervised meta-learning via latent space energy-based model of symbol vector coupling,” inFifth Workshop on Meta-Learning at the Conference on Neural Information Processing Systems, 2021. [Online]. Available: https: //openreview.net/forum?id=-pLftu7EpXz
2021
-
[54]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoaet al., “Dinov3,” arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
On the limited memory bfgs method for large scale optimization,
D. C. Liu and J. Nocedal, “On the limited memory bfgs method for large scale optimization,”Mathematical Programming, vol. 45, p. 503–528, 1989
1989
-
[56]
Learning to learn task transformations for improved few-shot classification,
G. Zheng, Q. Suo, M. Huai, and A. Zhang, “Learning to learn task transformations for improved few-shot classification,” inProceedings of the 2023 SIAM International Conference on Data Mining (SDM). SIAM, 2023, pp. 784–792
2023
-
[57]
Ssl-protonet: Self- supervised learning prototypical networks for few-shot learning,
J. Y . Lim, K. M. Lim, C. P. Lee, and Y . X. Tan, “Ssl-protonet: Self- supervised learning prototypical networks for few-shot learning,”Expert Systems with Applications, vol. 238, p. 122173, 2024
2024
-
[58]
Simple semantic-aided few-shot learning,
H. Zhang, J. Xu, S. Jiang, and Z. He, “Simple semantic-aided few-shot learning,” inThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 28 588–28 597. 13
2024
-
[59]
Core: Correlation- guided feature enhancement for few-shot image classification,
J. Xu, X. Pan, J. Wang, W. Pei, Q. Liao, and Z. Xu, “Core: Correlation- guided feature enhancement for few-shot image classification,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 2, pp. 3098–3110, 2024
2024
-
[60]
Anrot-helanet: adverserially and naturally robust attention-based ag- gregation network via the hellinger distance for few-shot classification,
G. Y . Lee, T. Dam, M. M. Ferdaus, D. P. Poenar, and V . N. Duong, “Anrot-helanet: adverserially and naturally robust attention-based ag- gregation network via the hellinger distance for few-shot classification,” International Journal of Multimedia Information Retrieval, vol. 15, no. 1, p. 8, 2026
2026
-
[61]
Few-shot classification with fork attention adapter,
J. Sun and J. Li, “Few-shot classification with fork attention adapter,” Pattern Recognition, vol. 156, p. 110805, 2024
2024
-
[62]
Tnpnet: An approach to few- shot open-set recognition via contextual transductive learning,
S. Wu, H. Luo, and X. Lin, “Tnpnet: An approach to few- shot open-set recognition via contextual transductive learning,” Neurocomputing, vol. 621, p. 129276, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0925231224020472
2025
-
[63]
Hela-vfa: A hellinger distance-attention-based feature aggregation net- work for few-shot classification,
G. Y . Lee, T. Dam, D. P. Poenar, V . N. Duong, and M. M. Ferdaus, “Hela-vfa: A hellinger distance-attention-based feature aggregation net- work for few-shot classification,” inThe IEEE Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 2173–2183
2024
-
[64]
Metadiff: Meta-learning with conditional diffusion for few-shot learning,
B. Zhang, C. Luo, D. Yu, X. Li, H. Lin, Y . Ye, and B. Zhang, “Metadiff: Meta-learning with conditional diffusion for few-shot learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 16 687–16 695
2024
-
[65]
Adaptive feature selection-based feature reconstruction network for few-shot learning,
J. Ren, Y . An, T. Lei, J. Yang, W. Zhang, Z. Pan, Y . Liao, Y . Gao, C. Sun, and W. Zhang, “Adaptive feature selection-based feature reconstruction network for few-shot learning,”Pattern Recognition, p. 112289, 2025
2025
-
[66]
Boosting few-shot fine-grained recognition with background suppression and foreground alignment,
Z. Zha, H. Tang, Y . Sun, and J. Tang, “Boosting few-shot fine-grained recognition with background suppression and foreground alignment,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 8, pp. 3947–3961, 2023
2023
-
[67]
Multi-level correlation network for few-shot image classification,
Y . Dang, M. Sun, M. Zhang, Z. Chen, X. Zhang, Z. Wang, and D. Wang, “Multi-level correlation network for few-shot image classification,” in 2023 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2023, pp. 2909–2914
2023
-
[68]
Efficient group attentive learn- ing for few-shot image classification,
J. Sun, K. Huang, D. Yang, and H. Liu, “Efficient group attentive learn- ing for few-shot image classification,”Expert Systems with Applications, p. 131245, 2026
2026
-
[69]
Charting the right manifold: Manifold mixup for few-shot learning,
P. Mangla, N. Kumari, A. Sinha, M. Singh, B. Krishnamurthy, and V . N. Balasubramanian, “Charting the right manifold: Manifold mixup for few-shot learning,” inThe IEEE Winter Conference on Applications of Computer Vision (WACV), 2020, pp. 2218–2227
2020
-
[70]
Robust saliency-aware dis- tillation for few-shot fine-grained visual recognition,
H. Liu, C. P. Chen, X. Gong, and T. Zhang, “Robust saliency-aware dis- tillation for few-shot fine-grained visual recognition,”IEEE Transactions on Multimedia, vol. 26, pp. 7529–7542, 2024
2024
-
[71]
T2l: Trans-transfer learning for few-shot fine- grained visual categorization with extended adaptation,
N. Sun and P. Yang, “T2l: Trans-transfer learning for few-shot fine- grained visual categorization with extended adaptation,”Knowledge- Based Systems, vol. 264, p. 110329, 2023
2023
-
[72]
Tripletmaml: A metric-based model-agnostic meta-learning algorithm for few-shot classification,
A. G ¨ulc¨u, Z. Kus ¸, ˙I. T. S. ¨Ozkan, and O. F. Karakus ¸, “Tripletmaml: A metric-based model-agnostic meta-learning algorithm for few-shot classification,”Progress in Artificial Intelligence, pp. 1–15, 2026
2026
-
[73]
Fine-grained few shot learning with foreground object transformation,
C. Wang, S. Song, Q. Yang, X. Li, and G. Huang, “Fine-grained few shot learning with foreground object transformation,”Neurocomputing, vol. 466, pp. 16–26, 2021
2021
-
[74]
Bi-directional task-guided network for few-shot fine-grained image classification,
Z.-X. Ma, Z.-D. Chen, L.-J. Zhao, Z.-C. Zhang, T. Zheng, X. Luo, and X.-S. Xu, “Bi-directional task-guided network for few-shot fine-grained image classification,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 8277–8286
2024
-
[75]
Bsnet: Bi- similarity network for few-shot fine-grained image classification,
X. Li, J. Wu, Z. Sun, Z. Ma, J. Cao, and J.-H. Xue, “Bsnet: Bi- similarity network for few-shot fine-grained image classification,”IEEE Transactions on Image Processing, vol. 30, pp. 1318–1331, 2020
2020
-
[76]
Few-shot classification with feature map reconstruction networks,
D. Wertheimer, L. Tang, and B. Hariharan, “Few-shot classification with feature map reconstruction networks,” inThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 8012– 8021
2021
-
[77]
Crosstransformers: spatially- aware few-shot transfer,
C. Doersch, A. Gupta, and A. Zisserman, “Crosstransformers: spatially- aware few-shot transfer,”Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 21 981–21 993, 2020
2020
-
[78]
Interpretable few-shot image classification via prototypical concept-guided mixture of lora experts,
Z. Ji, R. Wei, J. Liu, Y . Pang, and J. Han, “Interpretable few-shot image classification via prototypical concept-guided mixture of lora experts,” IEEE Transactions on Image Processing, 2026
2026
-
[79]
Distribution consistency based covariance metric networks for few-shot learning,
W. Li, J. Xu, J. Huo, L. Wang, Y . Gao, and J. Luo, “Distribution consistency based covariance metric networks for few-shot learning,” in Proceedings of the AAAI conference on Artificial Intelligence, vol. 33, 2019, pp. 8642–8649
2019
-
[80]
Low-rank pairwise alignment bilinear network for few-shot fine-grained image classifica- tion,
H. Huang, J. Zhang, J. Zhang, J. Xu, and Q. Wu, “Low-rank pairwise alignment bilinear network for few-shot fine-grained image classifica- tion,”IEEE Transactions on Multimedia, vol. 23, pp. 1666–1680, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.