BrickAnything: Geometry-Conditioned Buildable Brick Generation with Structure-Aware Tokenization
Pith reviewed 2026-06-29 22:06 UTC · model grok-4.3
The pith
BrickAnything generates physically buildable brick structures from 3D point clouds via autoregressive prediction and structure-aware tree tokenization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
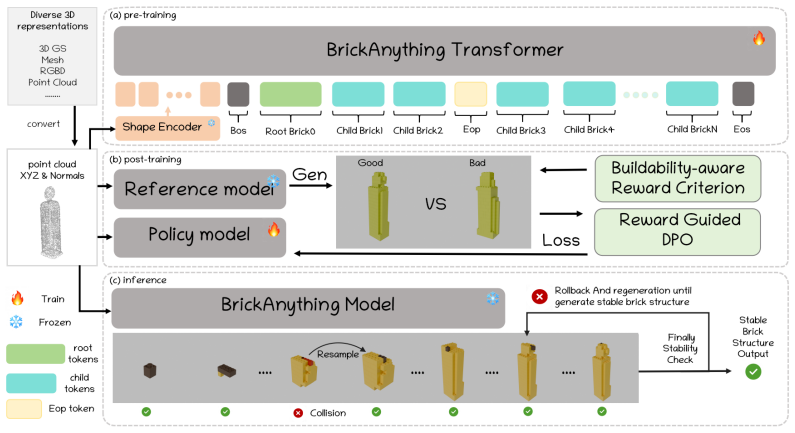
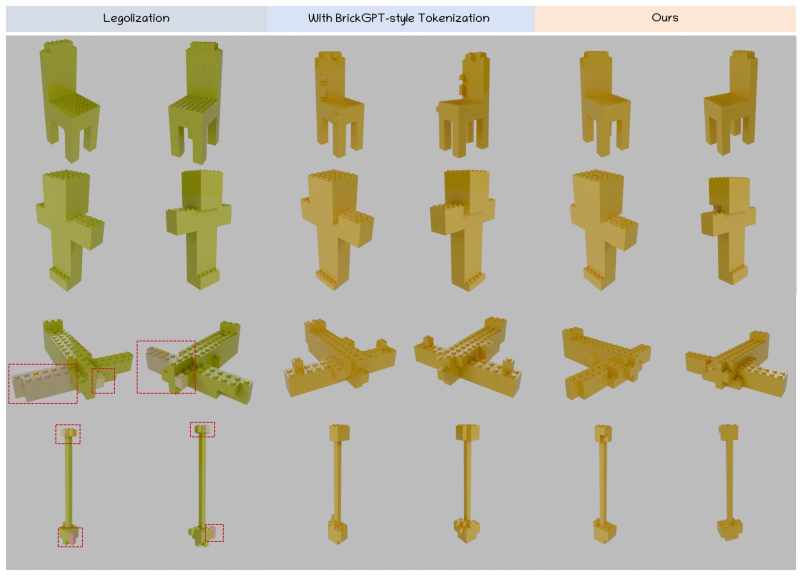
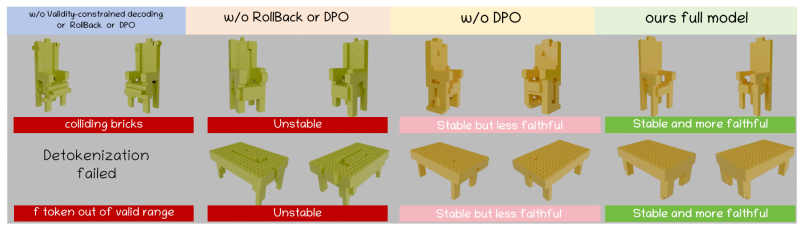
BrickAnything is a geometry-conditioned autoregressive framework that predicts brick sequences from point clouds, using structure-aware tree tokenization to represent structures through local attachment relations; this formulation aligns generation with physical construction, reduces invalid intermediate states, and, when combined with preference-based alignment, validity-constrained decoding, and adaptive rollback, yields brick structures that are both geometrically faithful to the target shape and physically realizable.
What carries the argument
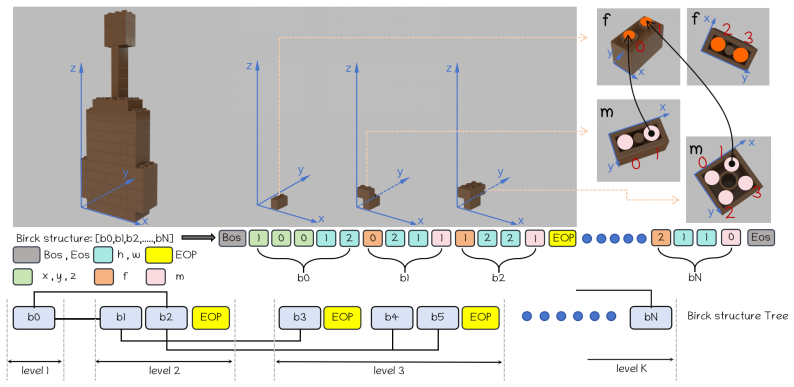
Structure-aware tree tokenization, which encodes brick structures as sequences defined by local attachment relations between bricks.
If this is right
- Generation sequences become more consistent with the physical construction process.
- Invalid intermediate states and required rollbacks decrease relative to conventional ordering strategies.
- Stability and geometric fidelity improve through the added post-training and decoding steps.
- The same point-cloud interface supports diverse 3D input representations.
Where Pith is reading between the lines
- The tree tokenization may generalize to other modular assembly tasks such as voxel or Lego-like construction beyond standard bricks.
- Explicit local attachment modeling could support incremental verification of partial builds during robotic assembly.
- If the tree representation misses global stability interactions, generated structures may still require manual reinforcement even when locally valid.
Load-bearing premise
Representing brick structures via local attachment relations in a tree tokenization captures all physical assembly constraints and stability requirements needed for valid generation across diverse 3D shapes.
What would settle it
A generated brick structure that, when assembled according to the output sequence, either collapses under gravity in simulation or deviates measurably from the input point cloud in occupied volume.
Figures



read the original abstract
Generating physically buildable brick structures from 3D shapes requires more than geometric reconstruction: the output must also satisfy discrete part constraints and structural stability. Existing brick generation methods either rely on heuristic optimization, which can break down when the target 3D shape does not admit a feasible structure under predefined constraints, or generate brick sequences without explicitly modeling the underlying 3D geometry and assembly relations. In this work, we present BrickAnything, a geometry-conditioned autoregressive framework for generating buildable brick structures from diverse 3D representations. BrickAnything uses point clouds as a unified geometric interface and predicts brick sequences that reconstruct the target shape under assembly constraints. To model structural dependencies among bricks, we introduce a structure-aware tree tokenization, which represents brick structures through local attachment relations. This formulation makes sequence generation more consistent with the physical construction process, and reduces invalid intermediate states. We further introduce preference-based alignment post-training, validity-constrained decoding and adaptive rollback to improve buildability objectives such as stability and geometric fidelity. Extensive experiments demonstrate that BrickAnything produces geometrically faithful and physically realizable brick structures, and that the proposed tokenization effectively reduces rollback and regeneration compared with conventional ordering strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce BrickAnything, a geometry-conditioned autoregressive framework for generating buildable brick structures from 3D point clouds. It employs a structure-aware tree tokenization to model local attachment relations among bricks, along with preference-based alignment post-training, validity-constrained decoding, and adaptive rollback to ensure physical buildability and geometric fidelity. The authors assert that this approach produces geometrically faithful and physically realizable brick structures and reduces rollback and regeneration compared to conventional ordering strategies, as demonstrated by extensive experiments.
Significance. If the quantitative results support the claims, this work could be significant for the field of generative models in physical design and construction, offering a way to generate structures that respect both geometric and assembly constraints. The tree tokenization approach aligns generation with physical processes, which is a promising direction. However, the current presentation lacks the necessary evidence to evaluate its novelty and effectiveness.
major comments (2)
- [Abstract] Abstract: The abstract states that 'extensive experiments demonstrate that BrickAnything produces geometrically faithful and physically realizable brick structures' but provides no quantitative results, baselines, error metrics, or dataset details. This absence makes it impossible to evaluate the central claims of improved buildability and reduced rollback, which are load-bearing for the paper's contribution.
- [Method (structure-aware tree tokenization)] The structure-aware tree tokenization is described as representing brick structures through local attachment relations to reduce invalid intermediate states. However, local parent-child attachments do not automatically enforce global physical constraints such as center-of-mass projection inside the base or cumulative shear resistance across layers. Without explicit mechanisms or ablation studies showing how these are handled (beyond implicit learning or post-hoc rollback), the reduction in rollback may not generalize beyond the training distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the structure-aware tree tokenization. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that 'extensive experiments demonstrate that BrickAnything produces geometrically faithful and physically realizable brick structures' but provides no quantitative results, baselines, error metrics, or dataset details. This absence makes it impossible to evaluate the central claims of improved buildability and reduced rollback, which are load-bearing for the paper's contribution.
Authors: We agree that the abstract would be strengthened by including quantitative support. In the revised version we will expand the abstract to report key metrics (buildability rate, geometric error such as Chamfer distance, rollback frequency), baseline comparisons, and dataset information so that the central claims can be evaluated directly from the abstract. revision: yes
-
Referee: [Method (structure-aware tree tokenization)] The structure-aware tree tokenization is described as representing brick structures through local attachment relations to reduce invalid intermediate states. However, local parent-child attachments do not automatically enforce global physical constraints such as center-of-mass projection inside the base or cumulative shear resistance across layers. Without explicit mechanisms or ablation studies showing how these are handled (beyond implicit learning or post-hoc rollback), the reduction in rollback may not generalize beyond the training distribution.
Authors: The tree tokenization is designed to capture local attachment relations and thereby reduce invalid intermediate states during autoregressive generation. Global stability constraints are addressed by the three additional components presented in the method: preference-based alignment post-training directly optimizes stability objectives, validity-constrained decoding enforces physical rules at each step, and adaptive rollback corrects residual violations. These mechanisms operate together with the tokenization. We will add ablation studies in the revision that isolate the contribution of each component to global constraint satisfaction and out-of-distribution generalization. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces an autoregressive generation framework conditioned on point-cloud geometry, a structure-aware tree tokenization based on local attachment relations, and auxiliary techniques such as preference alignment and validity-constrained decoding. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All components are presented as externally motivated architectural choices whose validity is assessed through experiments on geometric fidelity and buildability, rather than being derived from or equivalent to the inputs by construction. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhen Zhou, Jian Liu, Biwen Lei, Jing Xu, Haohan Weng, Yiling Zhu, Zhuo Chen, Junfeng Fan, Yunkai Ma, Dazhao Du, et al. Mesh-pro: Asynchronous advantage-guided ranking preference optimization for artist-style quadrilateral mesh generation.arXiv preprint arXiv:2603.00526, 2026
-
[2]
Direct3D-S2: Gigascale 3D generation made easy with spatial sparse attention
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Yikang Yang, Yajie Bao, Jiachen Qian, Siyu Zhu, Xun Cao, Philip Torr, et al. Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention.arXiv preprint arXiv:2505.17412, 2025
-
[3]
Meshanything: Artist-created mesh generation with autoregressive transformers
Yiwen Chen, Tong He, Di Huang, Weicai Ye, Sijin Chen, Jiaxiang Tang, Xin Chen, Zhongang Cai, Lei Yang, Gang Yu, et al. Meshanything: Artist-created mesh generation with autoregressive transformers. arXiv preprint arXiv:2406.10163, 2024
-
[4]
Deepmesh: Auto-regressive artist-mesh creation with reinforcement learning
Ruowen Zhao, Junliang Ye, Zhengyi Wang, Guangce Liu, Yiwen Chen, Yikai Wang, and Jun Zhu. Deepmesh: Auto-regressive artist-mesh creation with reinforcement learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10612–10623, 2025
2025
-
[5]
Jiaxiang Tang, Zhaoshuo Li, Zekun Hao, Xian Liu, Gang Zeng, Ming-Yu Liu, and Qinsheng Zhang. Edgerunner: Auto-regressive auto-encoder for artistic mesh generation.arXiv preprint arXiv:2409.18114, 2024
-
[6]
Jian Liu, Jing Xu, Song Guo, Jing Li, Jingfeng Guo, Jiaao Yu, Haohan Weng, Biwen Lei, Xianghui Yang, Zhuo Chen, et al. Mesh-rft: Enhancing mesh generation via fine-grained reinforcement fine-tuning.arXiv preprint arXiv:2505.16761, 2025
-
[7]
Lion: Latent point diffusion models for 3d shape generation.Advances in neural information processing systems, 35: 10021–10039, 2022
Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis, et al. Lion: Latent point diffusion models for 3d shape generation.Advances in neural information processing systems, 35: 10021–10039, 2022
2022
-
[8]
Pointinfinity: Resolution-invariant point diffusion models
Zixuan Huang, Justin Johnson, Shoubhik Debnath, James M Rehg, and Chao-Yuan Wu. Pointinfinity: Resolution-invariant point diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10050–10060, 2024
2024
-
[9]
Not-so-optimal transport flows for 3d point cloud generation.arXiv preprint arXiv:2502.12456, 2025
Ka-Hei Hui, Chao Liu, Xiaohui Zeng, Chi-Wing Fu, and Arash Vahdat. Not-so-optimal transport flows for 3d point cloud generation.arXiv preprint arXiv:2502.12456, 2025
-
[10]
Tiger: Time-varying denoising model for 3d point cloud generation with diffusion process
Zhiyuan Ren, Minchul Kim, Feng Liu, and Xiaoming Liu. Tiger: Time-varying denoising model for 3d point cloud generation with diffusion process. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9462–9471, 2024
2024
-
[11]
Blended point cloud diffusion for localized text-guided shape editing
Etai Sella, Noam Atia, Ron Mokady, and Hadar Averbuch-Elor. Blended point cloud diffusion for localized text-guided shape editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19119–19129, 2025
2025
-
[12]
Frepolad: Frequency-rectified point latent diffusion for point cloud generation
Chenliang Zhou, Fangcheng Zhong, Param Hanji, Zhilin Guo, Kyle Fogarty, Alejandro Sztrajman, Hongyun Gao, and Cengiz Oztireli. Frepolad: Frequency-rectified point latent diffusion for point cloud generation. InEuropean Conference on Computer Vision, pages 434–453. Springer, 2024
2024
-
[13]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4):139–1, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4):139–1, 2023
2023
-
[14]
Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps.Advances in neural information processing systems, 37:140138–140158, 2024
Zhiwen Fan, Kevin Wang, Kairun Wen, Zehao Zhu, Dejia Xu, and Zhangyang Wang. Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps.Advances in neural information processing systems, 37:140138–140158, 2024. 10
2024
-
[15]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19457–19467, June 2024
2024
-
[16]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, Dahua Lin, and Bo Dai. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, December 2025. doi: 10.1145/3763326
-
[17]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65 (1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65 (1):99–106, 2021
2021
-
[18]
Autosdf: Shape priors for 3d completion, reconstruction and generation
Paritosh Mittal, Yen-Chi Cheng, Maneesh Singh, and Shubham Tulsiani. Autosdf: Shape priors for 3d completion, reconstruction and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 306–315, June 2022
2022
-
[19]
Mitra, Dani Lischinski, Daniel Cohen-Or, and Hui Huang
Xingguang Yan, Liqiang Lin, Niloy J. Mitra, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. Shape- former: Transformer-based shape completion via sparse representation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6239–6249, June 2022
2022
-
[20]
Schwing, and Liang-Yan Gui
Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tulyakov, Alexander G. Schwing, and Liang-Yan Gui. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4456–4465, June 2023
2023
-
[21]
Generating physically stable and buildable brick structures from text
Ava Pun, Kangle Deng, Ruixuan Liu, Deva Ramanan, Changliu Liu, and Jun-Yan Zhu. Generating physically stable and buildable brick structures from text. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14798–14809, 2025
2025
-
[22]
Lego®-maker: Autoregressive image-conditioned lego® model creation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
Jiahao Ge, Mingjun Zhou, Hanyou Zheng, Hao Xu, and Chi-Wing Fu. Lego®-maker: Autoregressive image-conditioned lego® model creation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
2025
-
[23]
BrickNet: Graph-Backed Generative Brick Assembly
Peter Kulits and Cordelia Schmid. Bricknet: Graph-backed generative brick assembly.arXiv preprint arXiv:2604.22984, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Image2lego: Customized lego set generation from images.arXiv preprint arXiv:2108.08477, 2021
Kyle Lennon, Katharina Fransen, Alexander O’Brien, Yumeng Cao, Matthew Beveridge, Yamin Arefeen, Nikhil Singh, and Iddo Drori. Image2lego: Customized lego set generation from images.arXiv preprint arXiv:2108.08477, 2021
-
[25]
Legolization: Optimizing lego designs.ACM Transactions on Graphics (ToG), 34(6):1–12, 2015
Sheng-Jie Luo, Yonghao Yue, Chun-Kai Huang, Yu-Huan Chung, Sei Imai, Tomoyuki Nishita, and Bing-Yu Chen. Legolization: Optimizing lego designs.ACM Transactions on Graphics (ToG), 34(6):1–12, 2015
2015
-
[26]
Automatic generation of constructable brick sculptures
Romain Pierre Testuz, Yuliy Schwartzburg, and Mark Pauly. Automatic generation of constructable brick sculptures. InEUROGRAPHICS 2013, 2013
2013
-
[27]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[28]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[29]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[30]
Image transformer
Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. InInternational conference on machine learning, pages 4055–4064. PMLR, 2018
2018
-
[31]
Generative pretraining from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020
2020
-
[32]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
2024
-
[33]
Autoregressive 3d shape generation via canonical mapping
An-Chieh Cheng, Xueting Li, Sifei Liu, Min Sun, and Ming-Hsuan Yang. Autoregressive 3d shape generation via canonical mapping. InEuropean Conference on Computer Vision, pages 89–104. Springer, 2022. 11
2022
-
[34]
3d point cloud generation via autoregressive up-sampling.arXiv e-prints, pages arXiv–2503, 2025
Ziqiao Meng, Qichao Wang, Zhipeng Zhou, Irwin King, and Peilin Zhao. 3d point cloud generation via autoregressive up-sampling.arXiv e-prints, pages arXiv–2503, 2025
2025
-
[35]
Nicolas von Lützow, Barbara Rössle, Katharina Schmid, and Matthias Nießner. Gaussiangpt: Towards autoregressive 3d gaussian scene generation.arXiv preprint arXiv:2603.26661, 2026
-
[36]
AvatarPointillist: AutoRegressive 4D Gaussian Avatarization
Hongyu Liu, Xuan Wang, Yating Wang, Zijian Wu, Ziyu Wan, Yue Ma, Runtao Liu, Boyao Zhou, Yujun Shen, and Qifeng Chen. Avatarpointillist: Autoregressive 4d gaussian avatarization.arXiv preprint arXiv:2604.04787, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Polygen: An autoregressive generative model of 3d meshes
Charlie Nash, Yaroslav Ganin, SM Ali Eslami, and Peter Battaglia. Polygen: An autoregressive generative model of 3d meshes. InInternational conference on machine learning, pages 7220–7229. PMLR, 2020
2020
-
[38]
Meshgpt: Generating triangle meshes with decoder-only transformers
Yawar Siddiqui, Antonio Alliegro, Alexey Artemov, Tatiana Tommasi, Daniele Sirigatti, Vladislav Rosov, Angela Dai, and Matthias Nießner. Meshgpt: Generating triangle meshes with decoder-only transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19615– 19625, 2024
2024
-
[39]
Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[40]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[41]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[42]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[44]
Zhenglin Zhou, Xiaobo Xia, Fan Ma, Hehe Fan, Yi Yang, and Tat-Seng Chua. Dreamdpo: Aligning text-to- 3d generation with human preferences via direct preference optimization.arXiv preprint arXiv:2502.04370, 2025
-
[45]
Auto-connect: Connectivity-preserving rigformer with direct preference optimization
Jingfeng Guo, Jian Liu, Jinnan Chen, Shiwei Mao, Changrong Hu, Puhua Jiang, Junlin Yu, Jing Xu, Qi Liu, Lixin Xu, et al. Auto-connect: Connectivity-preserving rigformer with direct preference optimization. arXiv preprint arXiv:2506.11430, 2025
-
[46]
Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation.Advances in neural information processing systems, 36:73969–73982, 2023
Zibo Zhao, Wen Liu, Xin Chen, Xianfang Zeng, Rui Wang, Pei Cheng, Bin Fu, Tao Chen, Gang Yu, and Shenghua Gao. Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation.Advances in neural information processing systems, 36:73969–73982, 2023
2023
-
[47]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Marching cubes: A high resolution 3d surface construction algorithm.Computer graphics, 21(1):7–12, 1987
LORENSEN WE. Marching cubes: A high resolution 3d surface construction algorithm.Computer graphics, 21(1):7–12, 1987
1987
-
[49]
Stablelego: Stability analysis of block stacking assembly.IEEE Robotics and Automation Letters, 9(11):9383–9390, 2024
Ruixuan Liu, Kangle Deng, Ziwei Wang, and Changliu Liu. Stablelego: Stability analysis of block stacking assembly.IEEE Robotics and Automation Letters, 9(11):9383–9390, 2024
2024
-
[50]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[51]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13142– 13153, 2023. 12
2023
-
[52]
Objaverse-xl: A universe of 10m+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. Advances in neural information processing systems, 36:35799–35813, 2023
2023
-
[53]
Meshanything v2: Artist-created mesh generation with adjacent mesh tokenization
Yiwen Chen, Yikai Wang, Yihao Luo, Zhengyi Wang, Zilong Chen, Jun Zhu, Chi Zhang, and Guosheng Lin. Meshanything v2: Artist-created mesh generation with adjacent mesh tokenization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13922–13931, 2025
2025
-
[54]
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
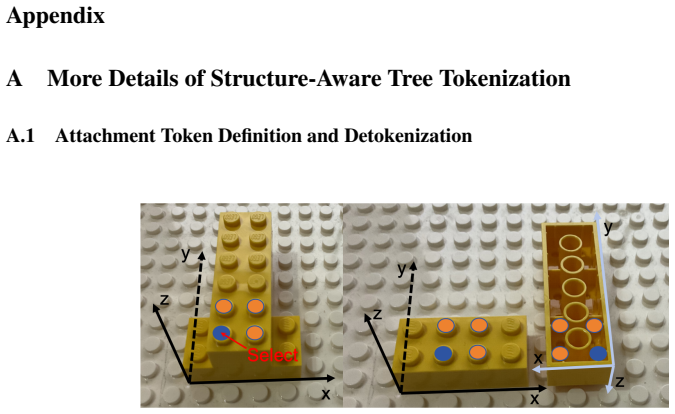
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxiang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, et al. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025. 13 Appendix A More Details of Structure-Aware Tree Tokenization A.1 Attachment Token Definition and D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.