DecomposeRL: Learning to Ask Useful, Informative, and Diverse Questions for Semi-Supervised, Traceable Claim Verification
Pith reviewed 2026-06-29 13:36 UTC · model grok-4.3
The pith
A 7B DecomposeRL policy trained on 5K curated claims matches 32B baselines and GPT-4.1-mini on claim verification while producing inspectable traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
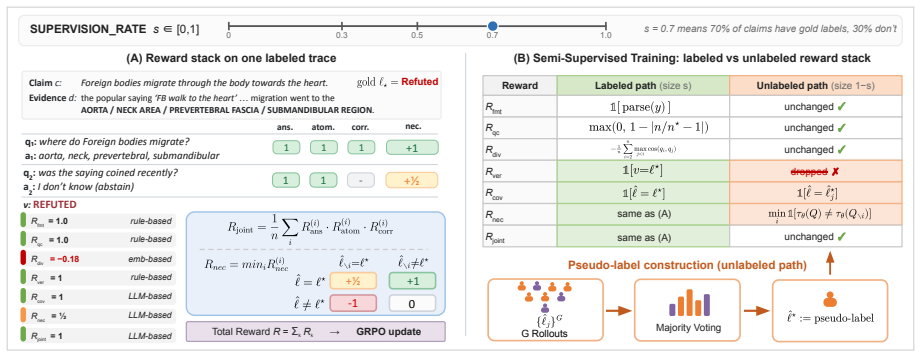
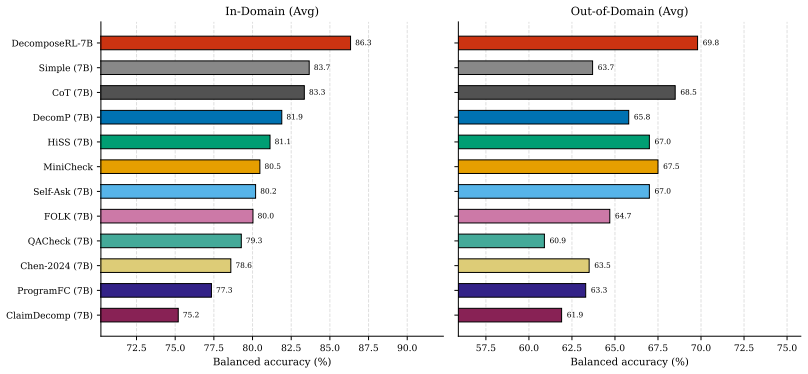
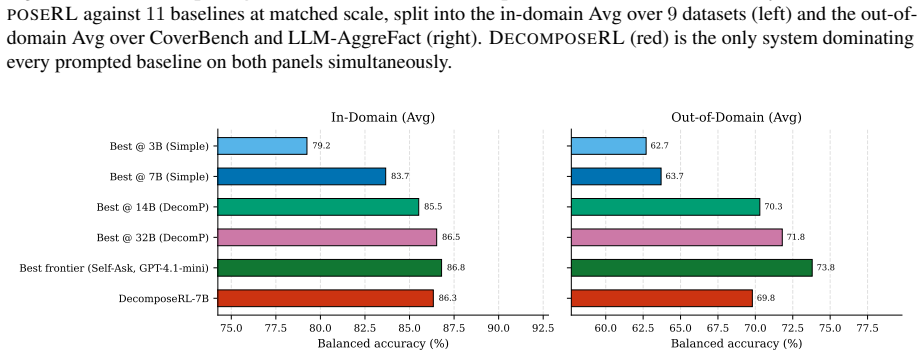
DecomposeRL treats claim decomposition as an RL policy trained with GRPO and a multi-faceted reward ensemble; a data-curation funnel reduces 115K fact-verification claims to a 5K subset; the resulting 7B policy achieves 86.3 in-domain and 69.8 out-of-domain balanced accuracy on 11 benchmarks, matching 32B and GPT-4.1-mini models while also outperforming baselines in a semi-supervised regime that uses only 10 percent labeled data.
What carries the argument
GRPO-trained RL policy with multi-faceted reward ensemble that learns to generate useful, informative, and diverse questions for decomposing claims.
If this is right
- Traceable decomposition becomes possible at the accuracy level of end-to-end classifiers.
- Semi-supervised training works with only 10 percent labeled claims.
- Model size can be reduced to 7B while still matching 32B and GPT-4.1-mini performance.
- A compact curated dataset of roughly 5K examples suffices for strong generalization.
Where Pith is reading between the lines
- The same RL decomposition approach could be applied to other multi-step reasoning tasks that benefit from inspectable intermediate steps.
- Generated question traces could be used directly by human fact-checkers to audit model decisions.
- Varying the curation funnel's selection criteria might allow further reduction in the number of required labeled examples.
- Combining the policy with larger base models could produce additional accuracy gains without retraining the full pipeline.
Load-bearing premise
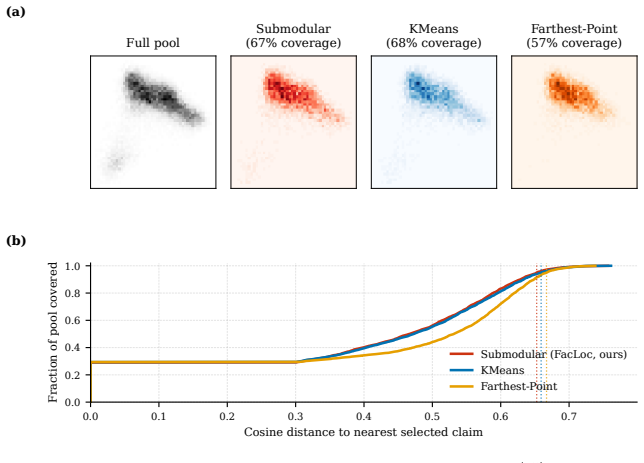
The curation funnel that reduces 115K claims to 5K claims retains sufficient learning signal for both in-domain and out-of-domain generalization without overfitting to the curation criteria or the benchmarks.
What would settle it
Measuring balanced accuracy of the released 7B model on a fresh collection of claims drawn from domains absent from the original 11 benchmarks.
Figures







read the original abstract
Claim verification splits between end-to-end classifiers that are accurate but yields no inspectable traces, and decomposition-based methods produce inspectable traces but lag performance on benchmark datasets. We propose DecomposeRL an accurate claim-verifier that produce inspectable traces. DecomposeRL frames decomposition as an RL policy trained with GRPO and a multi-faceted reward ensemble, enabling both fully supervised and semi-supervised learning from unlabeled claims. DecomposeRL addresses the prohibitive training cost of GRPO with a data-curation funnel that distills 115K fact-verification claims into a compact, learning-signal-dense subset of 5K claims. We show that a DecomposeRL-7B policy trained with full supervision on only ~5K curated claims achieves 86.3 in-domain and 69.8 out-of-domain balanced accuracy across 11 claim-verification benchmarks containing biomedical, political, scientific, and general-domain claims. Despite being 4x smaller, it matches 32B baselines and GPT-4.1-mini, and it further outperforms baselines in a semi-supervised setting with only 10% labeled claims data. Code, data, and models are available at https://dipta007.github.io/DecomposeRL
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DecomposeRL, which frames claim decomposition for verification as an RL policy trained via GRPO with a multi-faceted reward ensemble. It introduces a data-curation funnel to distill 115K claims into a compact 5K subset for efficient training, enabling both fully supervised and semi-supervised modes. A DecomposeRL-7B model trained on the 5K subset reports 86.3 in-domain and 69.8 out-of-domain balanced accuracy across 11 benchmarks (biomedical, political, scientific, general), matching 32B baselines and GPT-4.1-mini while outperforming in semi-supervised settings with 10% labeled data. Code, data, and models are released.
Significance. If the central performance claims hold, the work would be significant for showing that compact models can achieve competitive traceable claim verification via RL and curated data, bridging the gap between accurate but opaque end-to-end classifiers and inspectable but weaker decomposition methods. The code and model release is a clear strength that supports reproducibility and further research.
major comments (1)
- [Abstract] Abstract: the headline result (86.3/69.8 balanced accuracy on 11 benchmarks) rests on the data-curation funnel reducing 115K claims to 5K; the manuscript provides only a high-level description of this funnel and does not demonstrate that its selection criteria avoid any information derived from the 11 evaluation benchmarks or that the retained examples preserve sufficient diversity for the reported OOD transfer. This is load-bearing for the claim that the numbers are non-circular.
minor comments (1)
- [Abstract] Abstract: minor grammatical issue ('DecomposeRL an accurate claim-verifier that produce inspectable traces') should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the importance of rigorously documenting the data-curation process. We address the concern below and commit to a substantive revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline result (86.3/69.8 balanced accuracy on 11 benchmarks) rests on the data-curation funnel reducing 115K claims to 5K; the manuscript provides only a high-level description of this funnel and does not demonstrate that its selection criteria avoid any information derived from the 11 evaluation benchmarks or that the retained examples preserve sufficient diversity for the reported OOD transfer. This is load-bearing for the claim that the numbers are non-circular.
Authors: We agree that the current manuscript provides only a high-level description of the curation funnel and does not include explicit verification that the selection criteria are independent of the 11 evaluation benchmarks or quantitative evidence of retained diversity. In the revision we will (1) expand the methods section with the precise, reproducible criteria used to distill the 115K claims (including all filtering, scoring, and selection steps), (2) add an explicit statement and supporting table confirming that the curation pipeline operated exclusively on the 115K pool with no access to or leakage from any of the 11 held-out benchmarks, and (3) report diversity statistics (e.g., claim-topic distribution, length, source coverage) for the final 5K subset relative to both the original pool and the OOD evaluation sets. These additions will directly substantiate the non-circular nature of the reported numbers. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks
full rationale
The paper reports balanced accuracy figures obtained by training a policy on a curated subset and evaluating on 11 separate claim-verification benchmarks. No equations, derivations, or self-citations are invoked to obtain the reported numbers; the accuracies are measured quantities on held-out test data rather than quantities that reduce to the training inputs by construction. The data-curation funnel is a preprocessing step whose details do not appear in any load-bearing derivation that equates the final performance to the curation criteria themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward ensemble weights
axioms (2)
- domain assumption GRPO can be applied to train a policy for generating useful decomposition questions in claim verification
- domain assumption The curation funnel preserves representative learning signals across domains
Reference graph
Works this paper leans on
-
[1]
Rami Aly, Zhijiang Guo, Michael Sejr Schlichtkrull, James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Oana Cocarascu, and Arpit Mittal
Association for Computational Linguistics. Rami Aly, Zhijiang Guo, Michael Sejr Schlichtkrull, James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Oana Cocarascu, and Arpit Mittal. 2021. The fact extraction and VERification over unstructured and structured information (FEVEROUS) shared task. InProceedings of the Fourth Workshop on Fact Extraction ...
2021
-
[2]
InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Fool me twice: Entailment from Wikipedia gamification. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Leo Gao, John Schulman, and Jacob Hilton. 2023. Scal- ing laws for reward model overoptimization. InIn- ternational Conference on Machine Learning, ICML 202...
2021
-
[3]
Reinforcement Learning via Self-Distillation
Deepseek-r1: Incentivizing reasoning capabil- ity in llms via reinforcement learning. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop QA dataset for comprehensive evaluation of reason- ing steps. InProceedings of the 28th International Conference on Computational Linguistics. Matthew Honnibal, Ines Montani, ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. 10 Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human align- ment. InProceedings of the 2023 Conference on Empirical Methods in Na...
2024
-
[5]
InProceedings of the Twenty-Ninth AAAI Conference on Artificial Intelli- gence, January 25-30, 2015, Austin, Texas, USA
Lazier than lazy greedy. InProceedings of the Twenty-Ninth AAAI Conference on Artificial Intelli- gence, January 25-30, 2015, Austin, Texas, USA. George L. Nemhauser, Laurence A. Wolsey, and Mar- shall L. Fisher. 1978. An analysis of approximations for maximizing submodular set functions—I.Mathe- matical Programming, (1). Mark Neumann, Daniel King, Iz Bel...
2015
-
[6]
Training language models to follow instruc- tions with human feedback. InAdvances in Neural Information Processing Systems 35: Annual Confer- ence on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022. Liangming Pan, Xinyuan Lu, Min-Yen Kan, and Preslav Nakov. 2023a. QACheck: A demonstration syst...
2022
-
[7]
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Sys- tems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Michael Schlichtkrull, Zhijiang Guo, and Andreas Vla- chos. 2023. Averitec: A dataset for real...
2023
-
[8]
Long-form factuality in large language models. InAdvances in Neural Information Processing Sys- tems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Kai Wei, Rishabh K. Iyer, and Jeff A. Bilmes. 2015. Submodularity in data subset selection and active learning. InProceedings ...
2024
-
[9]
In2014 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP)
Submodular subset selection for large-scale speech training data. In2014 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP). Tomer Wolfson, Mor Geva, Ankit Gupta, Matt Gard- ner, Yoav Goldberg, Daniel Deutch, and Jonathan Berant. 2020. Break it down: A question understand- ing benchmark.Transactions of the Association for ...
2020
-
[10]
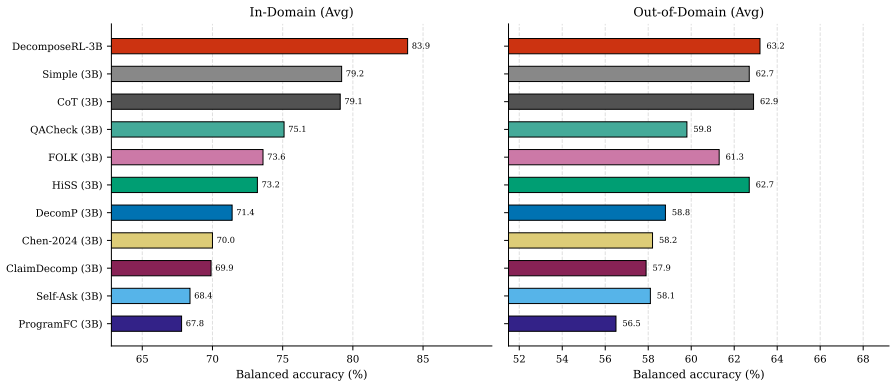
Closer to our task, Chen et al
formalizes atomic checking for long-form factuality. Closer to our task, Chen et al. (2024) (henceforthChen- 2024) embed a learned claim- decomposer inside an end-to-end fact-checking pipeline with retrieval and claim-focused sum- marization, training the decomposer on existing gold decompositions. A parallel prompting line: chain-of-thought (Wei et al., ...
2024
-
[11]
lucky-guess
that has motivated a parallel line of work on process reward models: PRM800K-style human- annotated step labels (Lightman et al., 2024), au- tomatic process-reward construction from rollout outcomes (Setlur et al., 2025), and self-consistency- derived rewards (Wang et al., 2023). Reward mod- els more broadly are also known to be vulnerable to over-optimiz...
2024
-
[12]
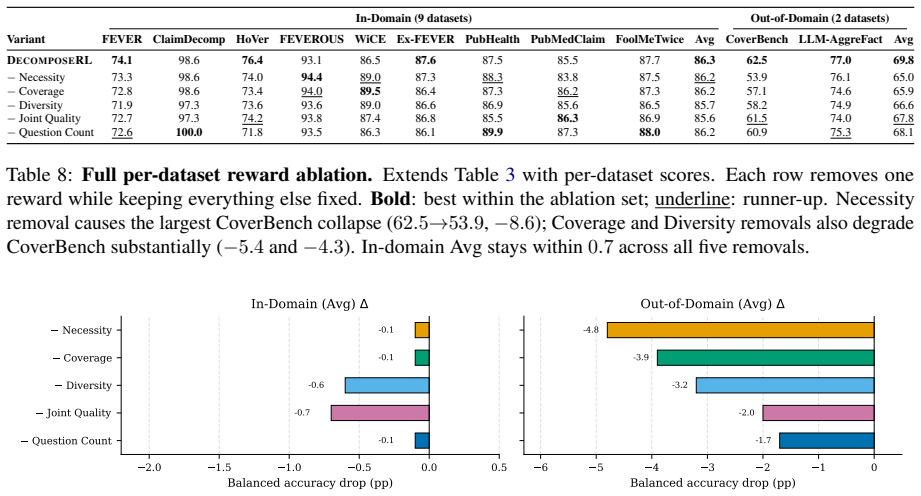
breadth” axis of decomposition quality, and their OOD drops are correspondingly larger than those of Joint Quality (−2.0) and Question Count (−1.7), which operate on “depth
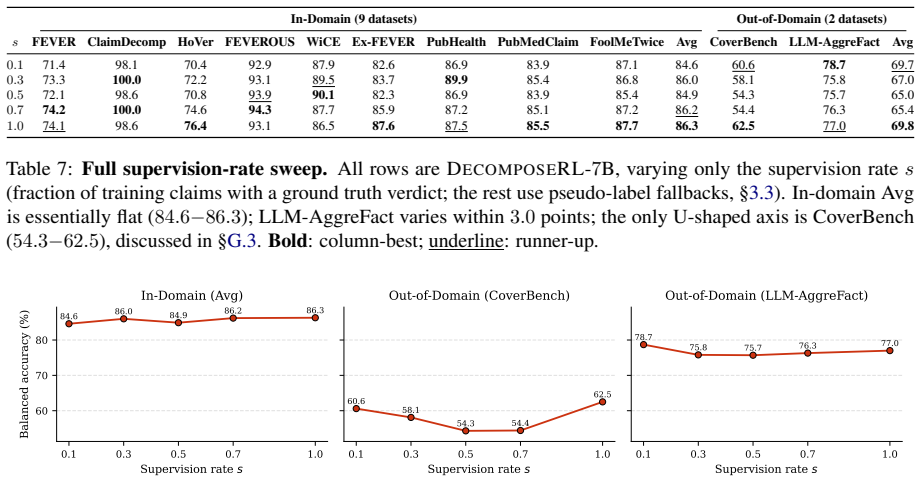
targets long-evidence multi-hop verification, and LLM-AggreFact (Tang et al., 2024) aggregates factuality judgments across heterogeneous gener- ators. Neither corpus contributes to training, and both are used only to probe generalization beyond the training distribution. F Result Plots We complement the per-dataset numeric tables in §4.1 with two bar-char...
2024
-
[13]
IsGet Lowa song by Lil Jon & the East Side Boyz (featuring the Ying Yang Twins)?
-
[14]
Does the document state thatGet Lowpeaked at number two on the Billboard Hot 100?
-
[15]
top ranked
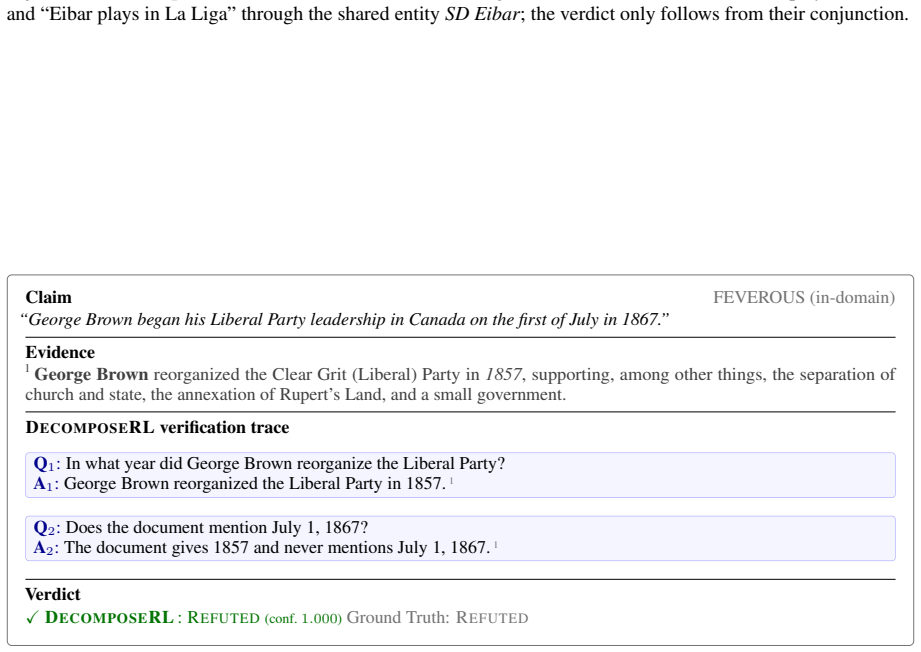
Does the document mention any Lil Jon song that achieved a Billboard Hot 100 peak higher than num- ber two? Figure 10:A representative training claim.The silver decomposition (§2.5) isolates two factual checks (exis- tence, Hot 100 peak) and a comparative check that pins down the “top ranked” qualifier. partially-unsupported claim, and a counting-style fa...
1903
-
[16]
Identify explicit connectives (and, or, but, because, which, etc.) and implicit assumptions, comparisons, or vague terms that each need separate verification,→
-
[17]
Classify each sub-claim by type (e.g., entity, relational, quantitative, causal, temporal, comparative, etc.)
-
[18]
## Iterative Question-Answer Cycle After your initial analysis, enter an iterative cycle where you:
Note which sub-claims are independently falsifiable -- if any single one is refuted, the entire claim is refuted - Write out a numbered checklist of these sub-claims (this list will guide your verification cycle) - Identify any ambiguous, vague, or underspecified elements in the claim - Determine what specific question you should ask It's OK for this sect...
-
[19]
**Ask a Question**: In <question> tags, pose a single specific verification question that addresses one aspect of the claim. Your question should target:,→ - A specific atomic sub-claim that needs verification - An ambiguous element that needs clarification - An underspecified term or concept - Any other information needed to determine the claim's accuracy
-
[20]
I don't know
**Answer the Question**: In <answer> tags, answer your question using **only** the evidence document: - Search the evidence document for relevant information. If you find relevant passages, quote them directly. - If the evidence document contains sufficient information, use it to answer the question and cite the relevant passage. - If the evidence documen...
-
[21]
**Evaluate Sufficiency**: In <think> tags, reason about whether you now have sufficient information to verify the claim. Consider:,→ - List which sub-claims have been verified so far and which remain unverified - Are there remaining ambiguous or underspecified elements in the claim? - Do you need additional information to make a confident verification jud...
-
[22]
I don't know
**Repeat or Conclude**: - If more information is needed, return to step 1 and ask another question. - If you have sufficient information, proceed to final verification. Continue the cycle until every sub-claim identified in your initial analysis has been addressed. Once all sub-claims are covered, proceed to final verification. Do not ask redundant questi...
-
[23]
**Atomic sub-claims**: Break down the main claim into its fundamental, indivisible components that each require verification,→
-
[24]
Partially answerable
**Under-specified elements**: Identify vague or ambiguous parts of the claim that need clarification to enable proper verification,→ 27 Guidelines for your analysis: - Generate between 1 and 20 questions - Aim for the smallest possible set that still ensures complete verification - Avoid redundant questions that provide diminishing returns - Each question...
-
[25]
**Is a question**: Does the text contain an actual question rather than being purely a statement, analysis, or explanation? A brief setup before the question is acceptable, but the text must contain an actual question.,→
-
[26]
**Single-focus**: Does the question ask about exactly one thing? A question fails this if it asks about multiple distinct aspects, facts, or relationships in a single question.,→
-
[27]
and", "or
**No conjunctions**: Does the question avoid using "and", "or", "as well as", or similar conjunctions to join distinct sub-claims or topics? Minor conjunctions within a single concept (e.g., "cause and effect") are acceptable.,→
-
[28]
**Verifiable**: Does the question have a definitive yes/no or specific factual answer? It should not be open-ended, subjective, or require an essay-length response.,→
-
[29]
**Grounded**: Does the question reference a specific entity, fact, number, or detail from the claim rather than being generic or abstract?,→ First, briefly reason about each criterion. Then provide your final answers inside <answer> tags in the exact format: <answer> is_question:YES/NO single_focus:YES/NO no_conjunctions:YES/NO verifiable:YES/NO grounded:...
-
[30]
List each sub-claim in the claim
-
[31]
Determine if each sub-claim is supported/refuted/unknown based on the answers
-
[32]
Then provide your final verdict inside <verdict> tags containing only one of: Supported, Refuted, or Not Enough Information.,→ 29
Aggregate to final verdict First, briefly explain your reasoning by analyzing how each answer relates to the claim. Then provide your final verdict inside <verdict> tags containing only one of: Supported, Refuted, or Not Enough Information.,→ 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.