EigeNet: Geometry-Informed Multi-Modal Learning for Few-shot Novel View RIR Prediction
Pith reviewed 2026-06-29 10:22 UTC · model grok-4.3
The pith
EigeNet predicts spatially varying room impulse responses from sparse multi-view inputs using a geometry-informed transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EIGENET achieves state-of-the-art performance in few-shot novel view RIR prediction and sim-to-real generalization by combining a Cross-view Alternate-attention Transformer with a geometry-informed modulation block that links geometric features to the RIR power spectrum.
What carries the argument
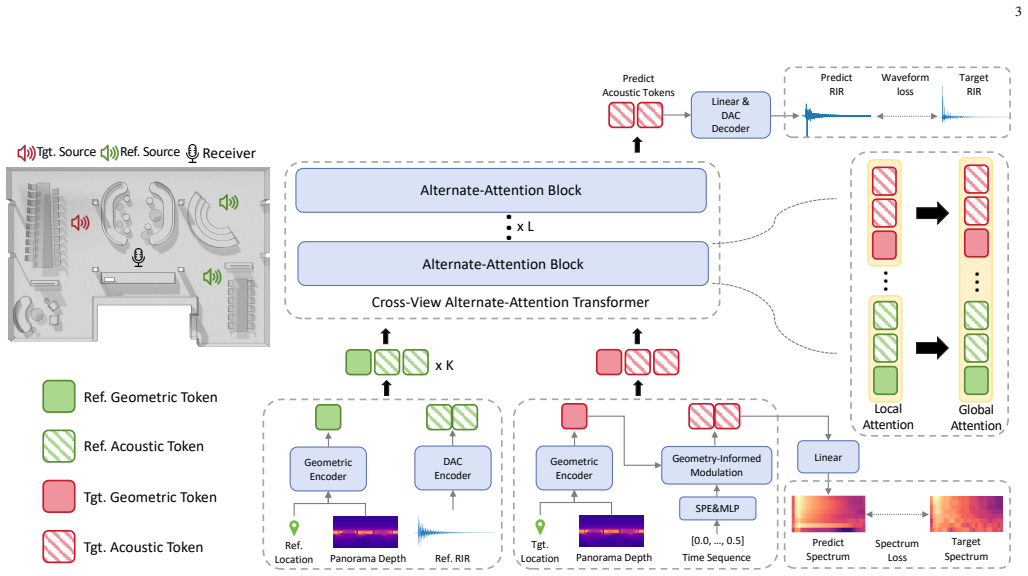
Cross-view Alternate-attention Transformer that iteratively refines intra-view acoustic structures and cross-view spatial relationships, together with a geometry-informed modulation block inspired by acoustic ray tracing.
If this is right
- The architecture makes full use of multi-view multi-modal context for spatial-temporal reasoning in RIR prediction.
- The modulation block and auxiliary loss produce consistent gains regardless of the underlying network backbone.
- The method improves generalization when moving from simulated training data to real acoustic measurements.
- The overall design supports few-shot prediction suitable for practical spatial audio rendering.
Where Pith is reading between the lines
- The same geometry-to-spectrum modulation idea could be tested on other acoustic inverse problems such as source localization or dereverberation.
- If the sim-to-real gap remains small, training pipelines could rely more heavily on synthetic room data before real deployment.
- Integration with visual scene reconstruction might allow joint audio-visual novel-view synthesis from the same sparse inputs.
Load-bearing premise
The geometry-informed modulation block creates a reliable link between room geometric features and the RIR power spectrum.
What would settle it
An ablation on the real-world benchmark in which the geometry-informed modulation block is removed or replaced shows no remaining gain in accuracy or sim-to-real transfer.
Figures
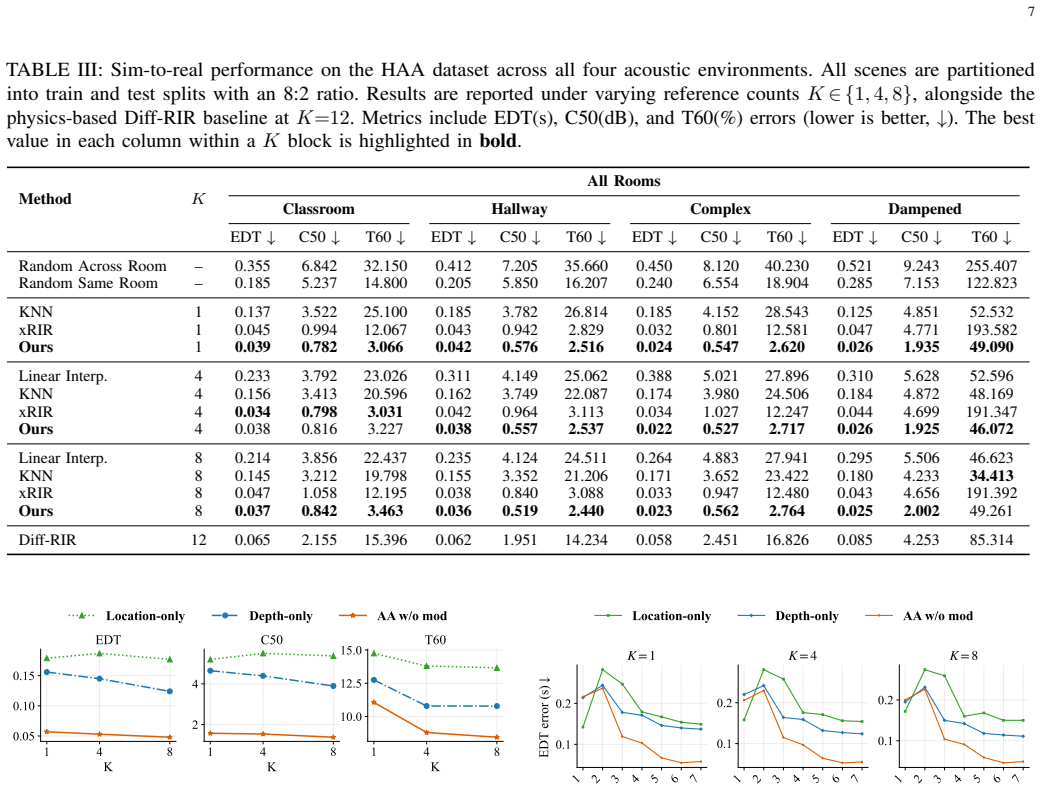
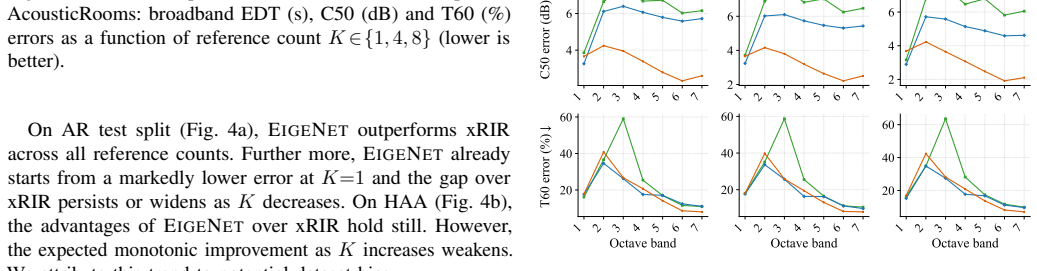
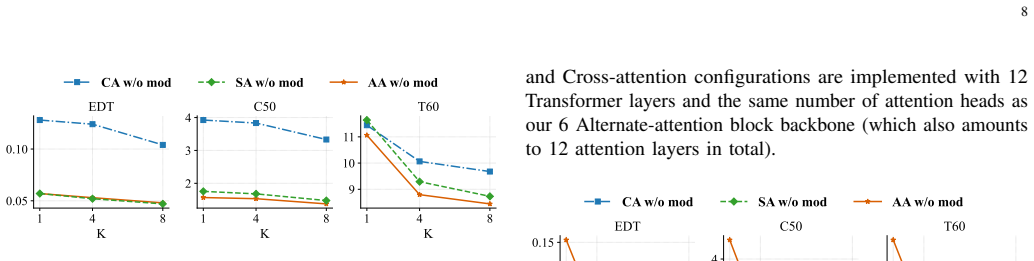
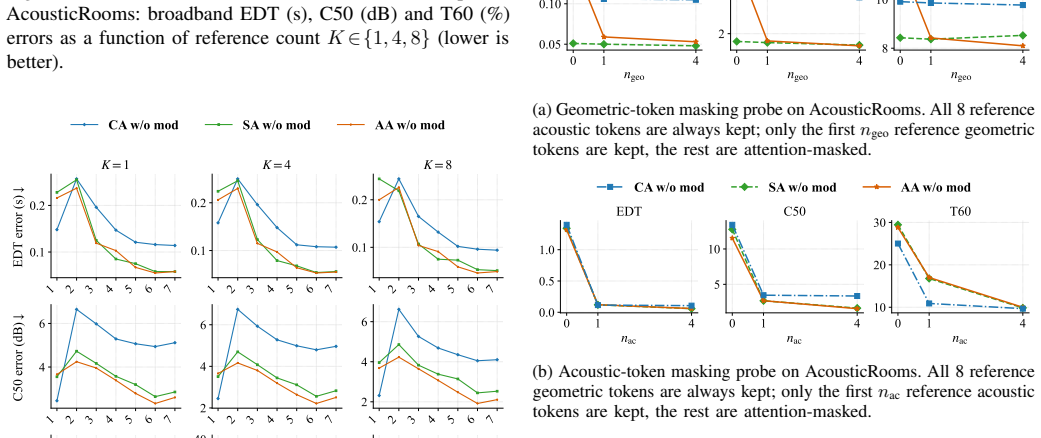
read the original abstract
Predicting spatially varying Room Impulse Response (RIR) from sparse observations is a critical but highly challenging inverse problem for immersive spatial audio rendering. In this work, we present EIGENET, a geometry-informed multi-modal framework for few-shot novel view RIR prediction. At its core is a Cross-view Alternate-attention Transformer that iteratively refines local intra-view acoustic structures and global cross-view spatial relationships. We empirically demonstrate that this architecture is capable of making full use of the multi-view multi-modal context while performing spatial-temporal reasoning for RIR prediction. Inspired by acoustic ray tracing, we design a geometry-informed modulation block to formulate the connection between geometric features and RIR power spectrum. In the mean time, an auxiliary loss is introduced to transform the single-target waveform prediction into a multi-task learning framework. Through ablation studies, we demonstrate that this design yields consistent performance gains regardless of the underlying backbone, thereby confirming its foundational utility and architecture-agnostic generalizability for RIR prediction task. Evaluated on both simulated and real-world benchmarks, EIGENET achieves both state-of-the-art performance in few-shot novel view RIR prediction and sim-to-real generalization. Codes and checkpoints are available on https://github.com/FEAfeatherTHER/EigeNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EigeNet, a geometry-informed multi-modal framework for few-shot novel view RIR prediction. It centers on a Cross-view Alternate-attention Transformer that refines intra-view acoustic structures and cross-view spatial relationships, a geometry-informed modulation block (inspired by ray tracing) to connect geometric features to the RIR power spectrum, and an auxiliary loss that converts single-target waveform prediction into multi-task learning. The authors claim SOTA performance and sim-to-real generalization on simulated and real-world benchmarks, plus architecture-agnostic gains shown via ablation studies, with code released.
Significance. If the central claims hold, the work would advance few-shot RIR prediction by demonstrating usable multi-modal and geometry-informed components that generalize across backbones and domains. The open-sourcing of code and checkpoints is a clear strength that supports reproducibility. However, the significance hinges on whether the modulation block creates an enforced geometric-acoustic link rather than a generic feature mixer; absent that, the SOTA and generalization claims would not follow.
major comments (2)
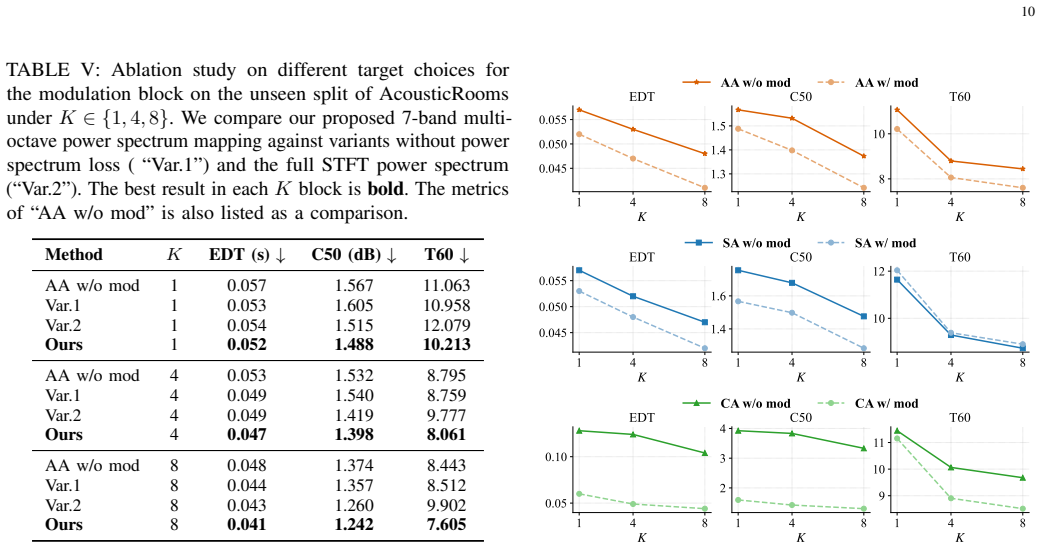
- [Abstract and §3] Abstract and §3 (geometry-informed modulation block): the claim that this block 'formulates the connection' between geometric features and RIR power spectrum is load-bearing for both the sim-to-real generalization and the architecture-agnostic gains. No explicit modulation equation, derivation, or enforcement mechanism is shown; if the block functions as an implicit mixer, the reported gains and cross-domain performance would not hold when scattering or material properties deviate from simulation assumptions.
- [Abstract] Abstract: the assertions of 'state-of-the-art performance' and 'consistent performance gains' via ablations are made without any quantitative results, baseline details, error analysis, or table/figure references. This prevents evaluation of the central claims and is load-bearing for the SOTA and generalizability assertions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and substantiation of the claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (geometry-informed modulation block): the claim that this block 'formulates the connection' between geometric features and RIR power spectrum is load-bearing for both the sim-to-real generalization and the architecture-agnostic gains. No explicit modulation equation, derivation, or enforcement mechanism is shown; if the block functions as an implicit mixer, the reported gains and cross-domain performance would not hold when scattering or material properties deviate from simulation assumptions.
Authors: We agree that the description of the geometry-informed modulation block requires an explicit equation and derivation to support the claims of an enforced geometric-acoustic link. In the revised manuscript, we will add the mathematical formulation of the modulation operation in §3, including its ray-tracing-inspired derivation and how it specifically modulates features to connect geometry with the RIR power spectrum, distinguishing it from a generic mixer. revision: yes
-
Referee: [Abstract] Abstract: the assertions of 'state-of-the-art performance' and 'consistent performance gains' via ablations are made without any quantitative results, baseline details, error analysis, or table/figure references. This prevents evaluation of the central claims and is load-bearing for the SOTA and generalizability assertions.
Authors: We acknowledge that the abstract should better substantiate the SOTA and ablation claims. In the revision, we will incorporate concise references to the quantitative results, including key performance metrics and pointers to the relevant tables and figures, while maintaining the abstract's brevity. revision: yes
Circularity Check
No circularity detected; empirical claims rest on benchmarks and ablations without self-referential reductions
full rationale
The paper describes EigeNet's Cross-view Alternate-attention Transformer and a geometry-informed modulation block (inspired by ray tracing) that 'formulates the connection between geometric features and RIR power spectrum,' plus an auxiliary loss for multi-task learning. Performance claims (SOTA on simulated/real benchmarks, architecture-agnostic gains via ablations) are presented as empirical outcomes. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or derivations that reduce to inputs by construction appear in the text. The modulation block is a design choice validated by results, not a self-definitional or fitted-input step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[2]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[3]
Advancing Open-source World Models
R. Team, Z. Gao, Q. Wang, Y . Zeng, J. Zhu, K. L. Cheng, Y . Li, H. Wang, Y . Xu, S. Maet al., “Advancing open-source world models,” arXiv preprint arXiv:2601.20540, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Genie: Generative interactive environments,
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Appset al., “Genie: Generative interactive environments,” inForty-first International Conference on Machine Learning, 2024
2024
-
[5]
Wave-based room acoustics simulation: Explicit/implicit finite volume modeling of viscothermal losses and frequency-dependent boundaries,
S. Bilbao and B. Hamilton, “Wave-based room acoustics simulation: Explicit/implicit finite volume modeling of viscothermal losses and frequency-dependent boundaries,”Journal of the Audio Engineering Society, vol. 65, no. 1/2, pp. 78–89, 2017
2017
-
[6]
Fdtd methods for 3-d room acoustics simulation with high-order accuracy in space and time,
B. Hamilton and S. Bilbao, “Fdtd methods for 3-d room acoustics simulation with high-order accuracy in space and time,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 11, pp. 2112–2124, 2017
2017
-
[7]
k-wave: Matlab toolbox for the simulation and reconstruction of photoacoustic wave fields,
B. E. Treeby and B. T. Cox, “k-wave: Matlab toolbox for the simulation and reconstruction of photoacoustic wave fields,”Journal of biomedical optics, vol. 15, no. 2, pp. 021 314–021 314, 2010
2010
-
[8]
Interactive sound propagation with bidirectional path tracing,
C. Cao, Z. Ren, C. Schissler, D. Manocha, and K. Zhou, “Interactive sound propagation with bidirectional path tracing,”ACM Transactions on Graphics (TOG), vol. 35, no. 6, pp. 1–11, 2016
2016
-
[9]
Interactive sound propagation and rendering for large multi-source scenes,
C. Schissler and D. Manocha, “Interactive sound propagation and rendering for large multi-source scenes,”ACM Transactions on Graphics (TOG), vol. 36, no. 4, p. 1, 2016
2016
-
[10]
Schröder,Physically based real-time auralization of interactive virtual environments
D. Schröder,Physically based real-time auralization of interactive virtual environments. Logos Verlag Berlin GmbH, 2011, vol. 11
2011
-
[11]
Ir-gan: Room impulse response generator for far-field speech recognition,
A. Ratnarajah, Z. Tang, and D. Manocha, “Ir-gan: Room impulse response generator for far-field speech recognition,” 2021. [Online]. Available: https://arxiv.org/abs/2010.13219
-
[12]
Real acoustic fields: An audio-visual room acoustics dataset and benchmark,
Z. Chen, I. D. Gebru, C. Richardt, A. Kumar, W. Laney, A. Owens, and A. Richard, “Real acoustic fields: An audio-visual room acoustics dataset and benchmark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 886–21 896
2024
-
[13]
Learning neural acoustic fields,
A. Luo, Y . Du, M. Tarr, J. Tenenbaum, A. Torralba, and C. Gan, “Learning neural acoustic fields,”Advances in Neural Information Processing Systems, vol. 35, pp. 3165–3177, 2022
2022
-
[14]
Inras: Implicit neural representation for audio scenes,
K. Su, M. Chen, and E. Shlizerman, “Inras: Implicit neural representation for audio scenes,”Advances in Neural Information Processing Systems, vol. 35, pp. 8144–8158, 2022
2022
-
[15]
M. Wang, R. Sawata, S. Clarke, R. Gao, S. Wu, and J. Wu, “Hearing anything anywhere,” 2024. [Online]. Available: https: //arxiv.org/abs/2406.07532
-
[16]
Differentiable room acoustic rendering with multi- view vision priors,
D. Jin and R. Gao, “Differentiable room acoustic rendering with multi- view vision priors,”arXiv preprint arXiv:2504.21847, 2025
-
[17]
Acoustic volume rendering for neural impulse response fields,
Z. Lan, C. Zheng, Z. Zheng, and M. Zhao, “Acoustic volume rendering for neural impulse response fields,”Advances in Neural Information Processing Systems, vol. 37, pp. 44 600–44 623, 2024
2024
-
[18]
Resounding acoustic fields with reci- procity,
Z. Lan, Y . Hao, and M. Zhao, “Resounding acoustic fields with reci- procity,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[19]
Physics-informed direction-aware neural acoustic fields,
Y . Masuyama, F. G. Germain, G. Wichern, C. Ick, and J. Le Roux, “Physics-informed direction-aware neural acoustic fields,” in2025 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2025, pp. 1–5
2025
-
[20]
Direction- aware neural acoustic fields for few-shot interpolation of ambisonic impulse responses,
C. Ick, G. Wichern, Y . Masuyama, F. Germain, and J. L. Roux, “Direction- aware neural acoustic fields for few-shot interpolation of ambisonic impulse responses,”arXiv preprint arXiv:2505.13617, 2025
-
[21]
Av-nerf: Learning neural fields for real-world audio-visual scene synthesis,
S. Liang, C. Huang, Y . Tian, A. Kumar, and C. Xu, “Av-nerf: Learning neural fields for real-world audio-visual scene synthesis,”Advances in Neural Information Processing Systems, vol. 36, pp. 37 472–37 490, 2023
2023
-
[22]
Av-rir: Audio-visual room impulse response estimation,
A. Ratnarajah, S. Ghosh, S. Kumar, P. Chiniya, and D. Manocha, “Av-rir: Audio-visual room impulse response estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 164–27 175
2024
-
[23]
C. Fan, J. Guan, Y . Lin, D. Xu, T. Ye, Q. Zhu, P. Feng, and W. Wang, “Physics-aware novel-view acoustic synthesis with vision-language priors and 3d acoustic environment modeling,” 2026. [Online]. Available: https://arxiv.org/abs/2601.19712
-
[24]
Building audio- visual digital twins with smartphones,
Z. Lan, Y . Tang, Y . Wang, H. Lai, Y . Hao, and M. Zhao, “Building audio- visual digital twins with smartphones,”arXiv preprint arXiv:2512.10778, 2025
-
[25]
Few-shot audio-visual learning of environment acoustics,
S. Majumder, C. Chen, Z. Al-Halah, and K. Grauman, “Few-shot audio-visual learning of environment acoustics,” 2022. [Online]. Available: https://arxiv.org/abs/2206.04006
-
[26]
Hearing anywhere in any environment,
X. Liu, A. Kumar, P. Calamia, S. V . Amengual, C. Murdock, I. Ananthabhotla, P. Robinson, E. Shlizerman, V . K. Ithapu, and R. Gao, “Hearing anywhere in any environment,” 2025. [Online]. Available: https://arxiv.org/abs/2504.10746
-
[27]
Few-shot acoustic synthesis with multimodal flow matching,
A. Brunetto, “Few-shot acoustic synthesis with multimodal flow matching,” 2026. [Online]. Available: https://arxiv.org/abs/2603.19176
-
[28]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” 2025. [Online]. Available: https://arxiv.org/abs/2503.11651
-
[29]
Fastvggt: Training-free acceleration of visual geometry transformer,
Y . Shen, Z. Zhang, Y . Qu, X. Zheng, J. Ji, S. Zhang, and L. Cao, “Fastvggt: Training-free acceleration of visual geometry transformer,”
-
[30]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
[Online]. Available: https://arxiv.org/abs/2509.02560
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Flashvggt: Efficient and scalable visual geometry transformers with compressed descriptor attention,
Z. Wang and D. Xu, “Flashvggt: Efficient and scalable visual geometry transformers with compressed descriptor attention,” 2025. [Online]. Available: https://arxiv.org/abs/2512.01540
-
[32]
Kuttruff,Room acoustics
H. Kuttruff,Room acoustics. Crc Press, 2016
2016
-
[33]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
J. Chen, J. Yu, C. Ge, L. Yao, E. Xie, Y . Wu, Z. Wang, J. Kwok, P. Luo, H. Lu, and Z. Li, “Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis,” 2023. [Online]. Available: https://arxiv.org/abs/2310.00426
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Audioldm: Text-to-audio generation with latent diffusion models,
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “Audioldm: Text-to-audio generation with latent diffusion models,” 2023. [Online]. Available: https://arxiv.org/abs/2301.12503
-
[35]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey, A. Goodwin, Y . Marek, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” 2024. [Online]. Available: https://arxiv.org/abs/2403.03206
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,”
-
[37]
Learning Transferable Visual Models From Natural Language Supervision
[Online]. Available: https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in feed-forward 3d reconstruction and view synthesis: A survey,
J. Zhang, Y . Li, A. Chen, M. Xu, K. Liu, J. Wang, X.-X. Long, H. Liang, Z. Xu, H. Su, C. Theobalt, C. Rupprecht, A. Vedaldi, K. Zhou, P. P. Liang, S. Lu, and F. Zhan, “Advances in feed-forward 3d reconstruction and view synthesis: A survey,” 2025. [Online]. Available: https://arxiv.org/abs/2507.14501
-
[39]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021. [Online]. Available: https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
High- fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High- fidelity audio compression with improved rvqgan,”Advances in Neural Information Processing Systems, vol. 36, pp. 27 980–27 993, 2023
2023
-
[41]
Neural Discrete Representation Learning
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” 2018. [Online]. Available: https: //arxiv.org/abs/1711.00937
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[43]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[44]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”
-
[45]
Adam: A Method for Stochastic Optimization
[Online]. Available: https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.