Sketch2Motion: Text-driven 2D Sketch to 3D Animation via Diffusion-guided Skeleton Optimization
Pith reviewed 2026-06-29 13:19 UTC · model grok-4.3
The pith
A text-to-video diffusion model guides skeleton optimization to turn 2D sketches into text-aligned 3D animations without paired motion data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
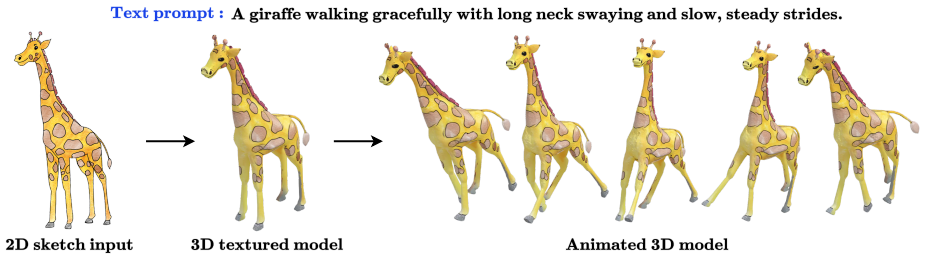
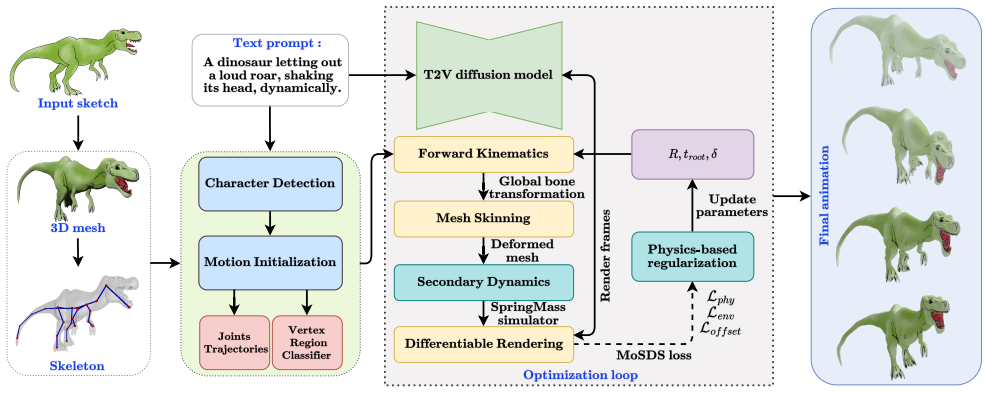
The paper claims that motion-aware score-distillation sampling from a text-to-video diffusion model can steer the optimization of skeletal transformations, which are then applied to meshes through linear blend skinning, while physics-inspired smoothness, topological, and contact constraints plus a spring-mass simulator stabilize the process, yielding temporally coherent and text-aligned 3D animations from 2D sketches for diverse articulated characters without any paired motion training data.
What carries the argument
Motion-aware score-distillation sampling (MoSDS) that uses a text-to-video diffusion model to provide gradients for optimizing skeletal joint transformations.
If this is right
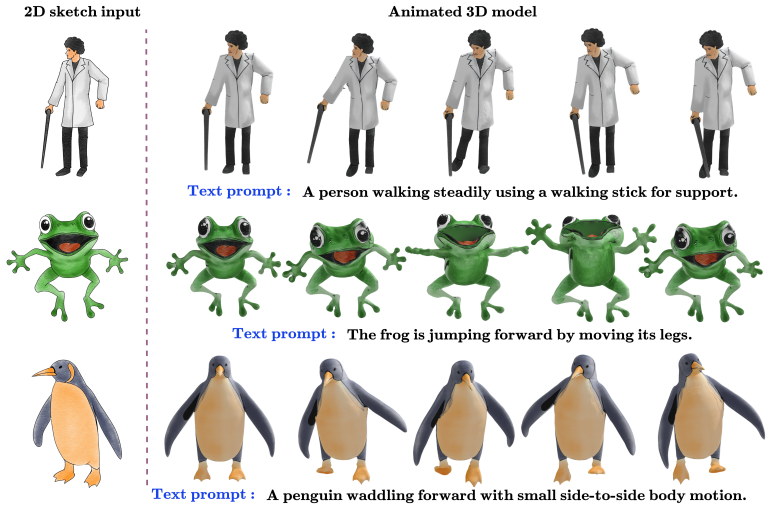
- The same pipeline produces animations for bipedal, quadrupedal, and non-living articulated characters.
- Adding the spring-mass simulator introduces secondary motion effects on top of the primary skeletal animation.
- The optimization remains stable under explicit smoothness, topological, and contact constraints.
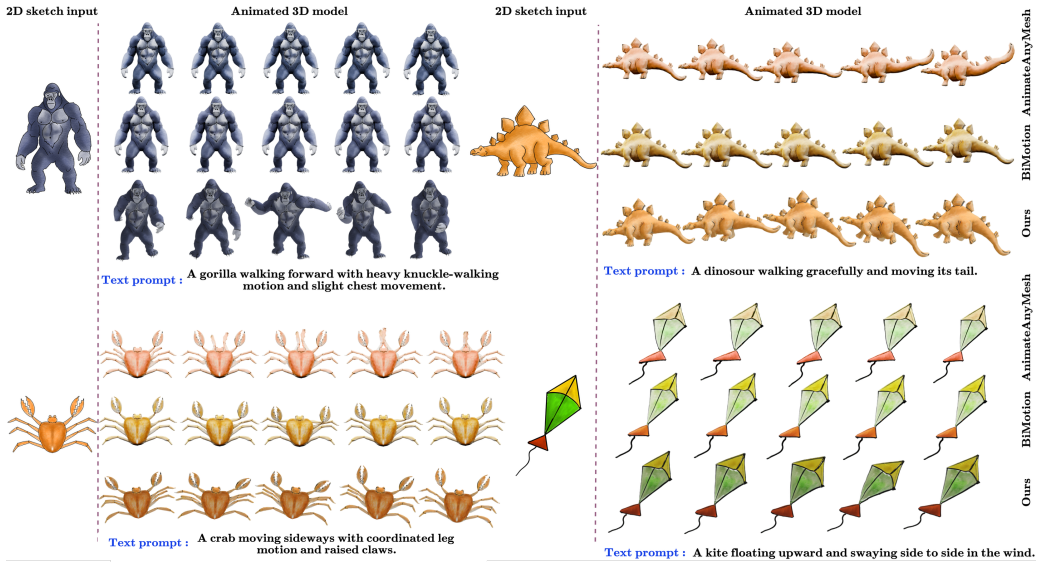
- The generated sequences are temporally coherent and better aligned with input text than motion transfer baselines that lack generative priors.
- The full system is modular and fully differentiable, allowing substitution of different diffusion models or skinning methods.
Where Pith is reading between the lines
- The method could be adapted to accept rough 3D scans instead of 2D sketches by replacing the initial skeleton estimation step.
- Because the diffusion guidance operates on rendered video frames, the same loop might be applied to other parametric animation representations such as blend shapes.
- Extending the contact constraints to handle multiple interacting characters would test whether the framework scales to scene-level animation.
- The absence of paired data training suggests the approach could serve as a zero-shot initializer for later fine-tuning on small custom datasets.
Load-bearing premise
Motion-aware score-distillation sampling from a text-to-video diffusion model can effectively guide skeleton optimization to produce realistic and semantically meaningful motion without any paired motion data.
What would settle it
Running the skeleton optimization loop on a set of sketches and text prompts and finding that the resulting animations receive lower human ratings for text alignment and motion realism than the same skeletons optimized without the diffusion term or with only the physical constraints.
Figures

read the original abstract
Animation of 2D hand-drawn sketches provides an effective medium for visual communication. However, these sketches pose challenges, particularly in handling occlusions and accurately mapping motion. While 3D animation naturally addresses these challenges, estimating 3D motion remains a very complex task. Recent approaches to converting 2D sketches to 3D animations have mainly focused on specific types of motion, such as bipedal movements and facial expressions. We propose Sketch2Motion, a diffusion-guided framework for skeleton-based motion synthesis that combines classical character animation pipelines with deep generative priors. Our method represents motion using skeletal transformations, which are propagated to mesh deformations via linear blend skinning. To guide the resulting animation toward realistic and semantically meaningful motion, we integrate a text-to-video diffusion model via motion-aware score-distillation sampling (MoSDS), enabling optimization without paired motion data. Additionally, we apply physics-inspired smoothness, topological, and contact constraints to stabilize optimization and preserve motion plausibility. Further, we integrate a spring-mass simulator to introduce secondary motion effects. The proposed framework is generalized, fully differentiable, modular, and compatible with biped, quadruped, and non-living articulated characters. Experiments demonstrate that our approach produces temporally coherent, text-aligned animations that outperform baseline motion transfer methods that lack generative priors or explicit physical constraints. We will make our code and dataset publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sketch2Motion, a diffusion-guided framework for skeleton-based motion synthesis from 2D sketches driven by text. It uses skeletal transformations propagated to mesh via linear blend skinning, guided by motion-aware score-distillation sampling (MoSDS) from a text-to-video diffusion model, with additional physics-inspired smoothness, topological, and contact constraints, and a spring-mass simulator for secondary motion. The framework is claimed to be generalized for different character types and to produce temporally coherent, text-aligned animations that outperform baseline methods lacking generative priors or physical constraints.
Significance. If the results hold, the work provides a modular, fully differentiable approach to text-driven 3D animation from sketches without paired motion data by combining classical character animation with deep generative priors. This could have impact in animation and visual communication fields. The approach avoids circularity by relying on external diffusion models and classical skinning.
major comments (1)
- [Abstract] Abstract: the claim that 'Experiments demonstrate that our approach produces temporally coherent, text-aligned animations that outperform baseline motion transfer methods' supplies no metrics, figures, ablation details, or experimental setup, so the data cannot be checked against the claim; this is load-bearing for the central empirical result.
minor comments (1)
- [Abstract] Abstract: the statement that code and dataset will be made publicly available should specify a repository or timing for the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment. We address the major concern regarding the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experiments demonstrate that our approach produces temporally coherent, text-aligned animations that outperform baseline motion transfer methods' supplies no metrics, figures, ablation details, or experimental setup, so the data cannot be checked against the claim; this is load-bearing for the central empirical result.
Authors: We agree that the abstract claim would be stronger with additional context on the supporting evidence. The full paper provides quantitative results (user studies, motion quality metrics, and comparisons to baselines) in Section 4, along with ablations and figures. In the revised version, we will update the abstract to briefly reference these key evaluation aspects and point to the experimental section, while respecting length limits. This addresses the verifiability concern without altering the core claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a modular pipeline that combines classical linear blend skinning and skeletal transforms with an external text-to-video diffusion model via motion-aware score-distillation sampling (MoSDS), plus independent physics-inspired constraints and a spring-mass simulator. No equations, assumptions, or experimental claims in the abstract or described method reduce the central result to a quantity defined by the method itself, a fitted parameter renamed as prediction, or a self-citation chain. The approach is explicitly positioned as using external generative priors and classical animation components, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Live sketch: Video-driven dynamic deformation of static drawings,
Q. Su, X. Bai, H. Fu, C.-L. Tai, and J. Wang, “Live sketch: Video-driven dynamic deformation of static drawings,” inProceedings of the 2018 chi conference on human factors in computing systems, pp. 1–12, 2018
2018
-
[2]
Sketchanim: Real-time sketch animation transfer from videos,
G. Rai, S. Gupta, and O. Sharma, “Sketchanim: Real-time sketch animation transfer from videos,” inComputer Graphics F orum, vol. 43, p. e15176, Wiley Online Library, 2024
2024
-
[3]
A method for animating children’s drawings of the human figure,
H. J. Smith, Q. Zheng, Y . Li, S. Jain, and J. K. Hodgins, “A method for animating children’s drawings of the human figure,”ACM Transactions on Graphics, vol. 42, no. 3, pp. 1–15, 2023
2023
-
[4]
Tracemove: A data-assisted interface for sketching 2d character animation.,
P. Patel, H. Gupta, and P. Chaudhuri, “Tracemove: A data-assisted interface for sketching 2d character animation.,” inVISIGRAPP (1: GRAPP), pp. 191–199, 2016
2016
-
[5]
Sheetanim-from model sheets to 2d hand- drawn character animation-.,
H. Gupta and P. Chaudhuri, “Sheetanim-from model sheets to 2d hand- drawn character animation-.,” inVISIGRAPP (1: GRAPP), pp. 17–27, 2018
2018
-
[6]
Magictoon: A 2d-to-3d creative cartoon modeling system with mobile ar,
L. Feng, X. Yang, and S. Xiao, “Magictoon: A 2d-to-3d creative cartoon modeling system with mobile ar,” in2017 IEEE Virtual Reality (VR), pp. 195–204, IEEE, 2017
2017
-
[7]
Photo wake- up: 3d character animation from a single photo,
C.-Y . Weng, B. Curless, and I. Kemelmacher-Shlizerman, “Photo wake- up: 3d character animation from a single photo,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5908–5917, 2019
2019
-
[8]
Drawingspinup: 3d animation from single character drawings,
J. Zhou, C. Xiao, M.-L. Lam, and H. Fu, “Drawingspinup: 3d animation from single character drawings,” inSIGGRAPH Asia 2024 Conference Papers, pp. 1–10, 2024
2024
-
[9]
Occlusion- robust stylization for drawing-based 3d animation,
S. Yoon, G. Koo, Y . Lee, J. W. Hong, and C. D. Yoo, “Occlusion- robust stylization for drawing-based 3d animation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12263– 12273, 2025
2025
-
[10]
DreamFusion: Text- to-3D using 2D diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “DreamFusion: Text- to-3D using 2D diffusion,”arXiv, 2022
2022
-
[11]
Animateanymesh: A feed-forward 4d foundation model for text-driven universal mesh animation,
Z. Wu, C. Yu, F. Wang, and X. Bai, “Animateanymesh: A feed-forward 4d foundation model for text-driven universal mesh animation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 13557–13568, 2025
2025
-
[12]
Bimotion: B-spline motion for text-guided dynamic 3d character generation,
M. Wang, Q. Yan, Z. Cao, Y . Li, O. Mac Aodha, J. J. Corso, and A. Vaxman, “Bimotion: B-spline motion for text-guided dynamic 3d character generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[13]
Articulated kinematics distillation from video diffusion models,
X. Li, Q. Ma, T.-Y . Lin, Y . Chen, C. Jiang, M.-Y . Liu, and D. Xiang, “Articulated kinematics distillation from video diffusion models,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, pp. 17571–17581, 2025
2025
-
[14]
SMP: Reusable Score-Matching Motion Priors for Physics-Based Character Control
Y . Mu, Z. Zhang, Y . Shi, M. Matsumoto, K. Imamura, G. Tevet, C. Guo, M. Taylor, C. Shu, P. Xi,et al., “Smp: Reusable score- matching motion priors for physics-based character control,”arXiv preprint arXiv:2512.03028, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Make-It-Poseable: Feed-forward Latent Posing Model for 3D Characters
Z. Guo, O. Zhang, J. Xiang, A. Zhao, W. Zhou, and H. Li, “Make-it- poseable: Feed-forward latent posing model for 3d humanoid character animation,”arXiv preprint arXiv:2512.16767, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Step1X-3D: Towards high-fidelity and controllable generation of textured 3D assets
W. Li, X. Zhang, Z. Sun, D. Qi, H. Li, W. Cheng, W. Cai, S. Wu, J. Liu, Z. Wang,et al., “Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets,”arXiv preprint arXiv:2505.07747, 2025. 13
-
[17]
ModelScope Text-to-Video Technical Report
J. Wang, H. Yuan, D. Chen, Y . Zhang, X. Wang, and S. Zhang, “Mod- elscope text-to-video technical report,”arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Breathing life into sketches using text-to-video priors,
R. Gal, Y . Vinker, Y . Alaluf, A. Bermano, D. Cohen-Or, A. Shamir, and G. Chechik, “Breathing life into sketches using text-to-video priors,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4325–4336, 2024
2024
-
[19]
G. Rai and O. Sharma, “Enhancing sketch animation: Text-to-video diffusion models with temporal consistency and rigidity constraints,” arXiv preprint arXiv:2411.19381, 2024
-
[20]
As-rigid-as-possible shape manipulation,
T. Igarashi, T. Moscovich, and J. F. Hughes, “As-rigid-as-possible shape manipulation,”ACM transactions on Graphics (TOG), vol. 24, no. 3, pp. 1134–1141, 2005
2005
-
[21]
Aniclipart: Clipart animation with text-to-video priors,
R. Wu, W. Su, K. Ma, and J. Liao, “Aniclipart: Clipart animation with text-to-video priors,”International Journal of Computer Vision, vol. 133, no. 6, pp. 3149–3165, 2025
2025
-
[22]
Flexiclip: Locality-preserving free-form character an- imation,
A. Khandelwal, “Flexiclip: Locality-preserving free-form character an- imation,”arXiv preprint arXiv:2501.08676, 2025
-
[23]
Dynamic typography: Bringing text to life via video diffusion prior,
Z. Liu, Y . Meng, H. Ouyang, Y . Yu, B. Zhao, D. Cohen-Or, and H. Qu, “Dynamic typography: Bringing text to life via video diffusion prior,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14787–14797, 2025
2025
-
[24]
Fairygen: Storied cartoon video from a single child-drawn character,
J. Zheng and X. Cun, “Fairygen: Storied cartoon video from a single child-drawn character,”arXiv preprint arXiv:2506.21272, 2025
-
[25]
Animatesketches: Animate sketches with instance-aware mask,
H. Deng, X. Dai, J. Hu, and Y . Qi, “Animatesketches: Animate sketches with instance-aware mask,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, IEEE, 2025
2025
-
[26]
Flipsketch: Flipping static drawings to text-guided sketch animations,
H. Bandyopadhyay and Y .-Z. Song, “Flipsketch: Flipping static drawings to text-guided sketch animations,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 28394–28404, 2025
2025
-
[27]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Multi-object sketch animation by scene decomposition and motion planning,
J. Liu, Z. Xin, Y . Fu, R. Zhao, B. Lan, and X. Li, “Multi-object sketch animation by scene decomposition and motion planning,”arXiv preprint arXiv:2503.19351, 2025
-
[29]
Multi-object sketch animation with grouping and motion trajectory priors,
G. Liang, J. Hu, X. Xing, J. Zhang, and Q. Yu, “Multi-object sketch animation with grouping and motion trajectory priors,” inProceedings of the 33rd ACM International Conference on Multimedia, pp. 9237– 9246, 2025
2025
-
[30]
Monster mash: a single-view approach to casual 3d modeling and animation,
M. Dvoro ˇzˇn´ak, D. S `ykora, C. Curtis, B. Curless, O. Sorkine-Hornung, and D. Salesin, “Monster mash: a single-view approach to casual 3d modeling and animation,”ACM Transactions on Graphics (ToG), vol. 39, no. 6, pp. 1–12, 2020
2020
-
[31]
Sketch2anim: Towards transferring sketch storyboards into 3d animation,
L. Zhong, C. Guo, Y . Xie, J. Wang, and C. Li, “Sketch2anim: Towards transferring sketch storyboards into 3d animation,”ACM Transactions on Graphics (TOG), vol. 44, no. 4, pp. 1–15, 2025
2025
-
[32]
Animating childlike drawings with 2.5 d character rigs,
H. J. Smith, N. He, and Y . Ye, “Animating childlike drawings with 2.5 d character rigs,”arXiv preprint arXiv:2502.17866, 2025
-
[33]
From rigging to waving: 3d- guided diffusion for natural animation of hand-drawn characters,
J. Zhou, L. Qu, M.-L. Lam, and H. Fu, “From rigging to waving: 3d- guided diffusion for natural animation of hand-drawn characters,”ACM Transactions on Graphics (TOG), vol. 44, no. 6, pp. 1–11, 2025
2025
-
[34]
Animamimic: Imitating 3d animation from video priors,
T. Xie, Y . Chen, Y . Guo, Y . Yang, B. Zhou, D. Terzopoulos, Y . Jiang, and C. Jiang, “Animamimic: Imitating 3d animation from video priors,” arXiv preprint arXiv:2512.14133, 2025
-
[35]
Animax: Animating the inanimate in 3d with joint video-pose diffusion models,
Z. Huang, H. Feng, Y .-T. Sun, Y .-C. Guo, Y .-P. Cao, and L. Sheng, “Animax: Animating the inanimate in 3d with joint video-pose diffusion models,” inProceedings of the SIGGRAPH Asia 2025 Conference Papers, pp. 1–13, 2025
2025
-
[36]
Mimicat: Mimic with correspondence-aware cascade-transformer for category-free 3d pose transfer,
Z. Chai, C. Tang, Y . Wong, X. Yang, and M. Kankanhalli, “Mimicat: Mimic with correspondence-aware cascade-transformer for category-free 3d pose transfer,”arXiv preprint arXiv:2511.18370, 2025
-
[37]
Motion 3-to-4: 3D motion reconstruction for 4D synthesis.arXiv preprint arXiv:2601.14253, 2026
H. Chen, X. Chen, Y . Zhang, Z. Xu, and A. Chen, “Motion 3- to-4: 3d motion reconstruction for 4d synthesis,”arXiv preprint arXiv:2601.14253, 2026
-
[38]
Animus3d: Text- driven 3d animation via motion score distillation,
Q. Sun, C. Wang, J. Shang, W. Feng, and J. Liao, “Animus3d: Text- driven 3d animation via motion score distillation,” inProceedings of the SIGGRAPH Asia 2025 Conference Papers, pp. 1–11, 2025
2025
-
[39]
Tracking-guided 4d generation: Foundation-tracker motion priors for 3d model animation,
S. Sun, C. Zhao, H. Mittal, G. Mittal, R. Kukkala, Y . V . Chen, and M. Chen, “Tracking-guided 4d generation: Foundation-tracker motion priors for 3d model animation,”arXiv preprint arXiv:2512.06158, 2025
-
[40]
Bringing objects to life: training-free 4d generation from 3d objects through view consistent noise,
O. Rahamim, O. Malca, D. Samuel, and G. Chechik, “Bringing objects to life: training-free 4d generation from 3d objects through view consistent noise,”arXiv preprint arXiv:2412.20422, 2024
-
[41]
Rigmo: Unifying rig and motion learning for generative animation,
H. Zhang, J. Luo, B. Wan, Y . Zhao, Z. Li, M. Vasilkovsky, C. Wang, J. Wang, N. Ahuja, and B. Zhou, “Rigmo: Unifying rig and motion learning for generative animation,”arXiv preprint arXiv:2601.06378, 2026
-
[42]
Skin tokens: A learned compact representation for unified autoregressive rigging,
J.-p. Zhang, C.-F. Pu, M.-H. Guo, Y .-P. Cao, and S.-M. Hu, “Skin tokens: A learned compact representation for unified autoregressive rigging,” arXiv preprint arXiv:2602.04805, 2026
-
[43]
Tc4d: Trajectory- conditioned text-to-4d generation,
S. Bahmani, X. Liu, W. Yifan, I. Skorokhodov, V . Rong, Z. Liu, X. Liu, J. J. Park, S. Tulyakov, G. Wetzstein,et al., “Tc4d: Trajectory- conditioned text-to-4d generation,” inEuropean Conference on Com- puter Vision, pp. 53–72, Springer, 2024
2024
-
[44]
Fourier principles for emotion- based human figure animation,
M. Unuma, K. Anjyo, and R. Takeuchi, “Fourier principles for emotion- based human figure animation,” inProceedings of the 22nd annual conference on Computer graphics and interactive techniques, pp. 91–96, 1995
1995
-
[45]
Farin,Curves and Surfaces for Computer-Aided Geometric Design
G. Farin,Curves and Surfaces for Computer-Aided Geometric Design. Academic Press, 1990
1990
-
[46]
The numerical evaluation of b-splines,
M. G. Cox, “The numerical evaluation of b-splines,”IMA Journal of Applied Mathematics, 1972
1972
-
[47]
Puppeteer: Rig and animate your 3d models,
C. Song, X. Li, F. Yang, Z. Xu, J. Wei, F. Liu, J. Feng, G. Lin, and J. Zhang, “Puppeteer: Rig and animate your 3d models,”Advances in Neural Information Processing Systems, 2025
2025
-
[48]
Spacetime constraints,
A. Witkin and M. Kass, “Spacetime constraints,”ACM Siggraph Com- puter Graphics, vol. 22, no. 4, pp. 159–168, 1988
1988
-
[49]
A deep learning framework for character motion synthesis and editing,
D. Holden, J. Saito, and T. Komura, “A deep learning framework for character motion synthesis and editing,”ACM Transactions on Graphics (ToG), vol. 35, no. 4, pp. 1–11, 2016
2016
-
[50]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image,
F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero, and M. J. Black, “Keep it smpl: Automatic estimation of 3d human pose and shape from a single image,” inEuropean conference on computer vision, pp. 561–578, Springer, 2016
2016
-
[51]
Deepphase: Periodic autoencoders for learning motion phase manifolds,
S. Starke, I. Mason, and T. Komura, “Deepphase: Periodic autoencoders for learning motion phase manifolds,”ACM Transactions on Graphics (ToG), vol. 41, no. 4, pp. 1–13, 2022
2022
-
[52]
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-Or, and A. H. Bermano, “Human motion diffusion model,”arXiv preprint arXiv:2209.14916, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Physdiff: Physics- guided human motion diffusion model,
Y . Yuan, J. Song, U. Iqbal, A. Vahdat, and J. Kautz, “Physdiff: Physics- guided human motion diffusion model,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 16010–16021, 2023
2023
-
[54]
Hybrid simula- tion of deformable solids,
E. Sifakis, T. Shinar, G. Irving, and R. Fedkiw, “Hybrid simula- tion of deformable solids,” inProceedings of the 2007 ACM SIG- GRAPH/Eurographics symposium on Computer animation, pp. 81–90, 2007
2007
-
[55]
A mass spring model for hair simulation,
A. Selle, M. Lentine, and R. Fedkiw, “A mass spring model for hair simulation,” inACM SIGGRAPH 2008 papers, pp. 1–11, 2008
2008
-
[56]
Secondary motion for performed 2d animation,
N. S. Willett, W. Li, J. Popovic, F. Berthouzoz, and A. Finkelstein, “Secondary motion for performed 2d animation,” inProceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, pp. 97–108, 2017
2017
-
[57]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
X-clip: End- to-end multi-grained contrastive learning for video-text retrieval,
Y . Ma, G. Xu, X. Sun, M. Yan, J. Zhang, and R. Ji, “X-clip: End- to-end multi-grained contrastive learning for video-text retrieval,” in Proceedings of the 30th ACM international conference on multimedia, pp. 638–647, 2022. 14
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.