Continuity and Ordinality Matter: Constraining Time Series Tokens for Effective Time Series Analysis with Large Language Models
Pith reviewed 2026-06-30 16:32 UTC · model grok-4.3
The pith
Preserving continuity and ordinality in time series token embeddings improves token-based TS-LLM performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
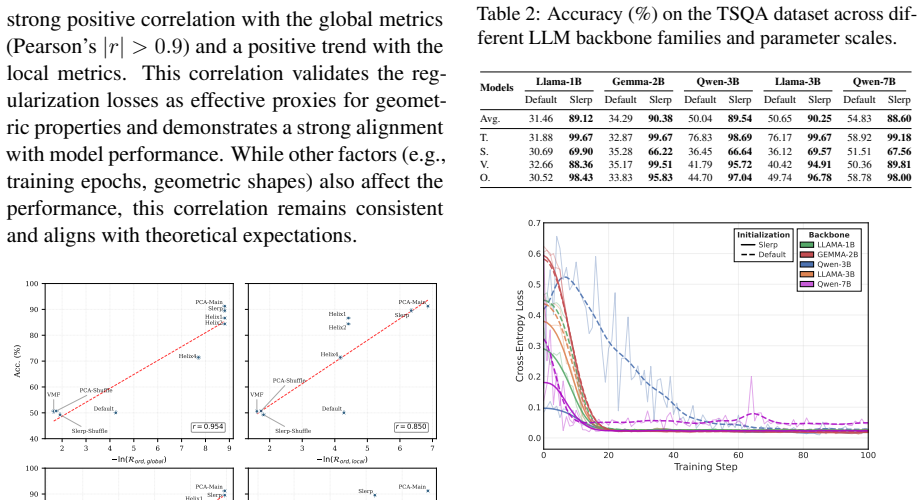
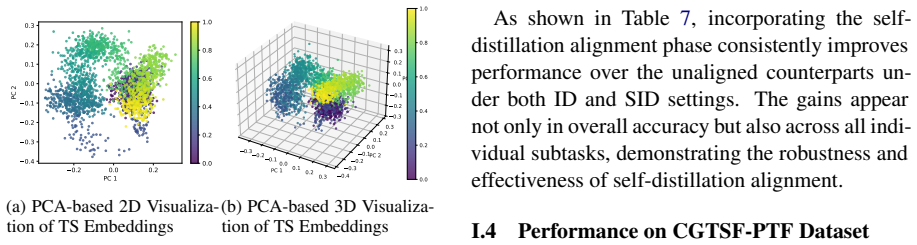
Preserving continuity and ordinality in time series token embeddings is crucial for the effectiveness of token-based TS-LLMs. COM achieves this by integrating geometric constraints into both the initialization and training stages, leading to consistent performance improvements on multiple benchmarks.
What carries the argument
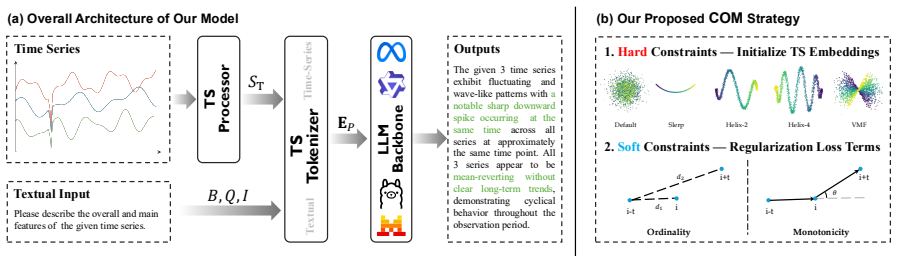
COM, the continuity- and ordinality-aware strategy that adds geometric constraints during embedding initialization and training to enforce order and smooth variation in the token space.
If this is right
- Token embeddings must reflect gradual value changes to support accurate time series reasoning.
- Preserving value order in the embedding space prevents models from treating nearby values as unrelated.
- Constraints applied at both initialization and training produce better results than initialization alone.
- The approach yields competitive accuracy on several standard time series tasks with little added complexity.
Where Pith is reading between the lines
- The same geometric idea might help sequence models that process other ordered data such as audio waveforms or sensor streams.
- One could test whether removing the constraints after training still keeps most of the gained performance.
- The method might combine with existing techniques like patching or frequency decomposition to produce further gains.
Load-bearing premise
The main shortcoming of earlier token-based TS-LLMs is the absence of continuity and ordinality in their embeddings, and that geometric constraints can restore these properties to raise performance without other major changes.
What would settle it
A replication study that applies the same geometric constraints to a standard token-based TS-LLM baseline and measures no accuracy gain, or even a drop, across the reported time series benchmarks.
Figures



read the original abstract
Token-based time series large language models (TS-LLMs) have emerged as a promising direction for time series analysis and reasoning. However, prior studies largely overlook the inherent continuity and ordinality of time series tokens, which substantially limits model performance. In this paper, we argue that preserving these properties in time series token embeddings is crucial for the effectiveness of token-based TS-LLMs. To this end, we propose COM (Continuity and Ordinality Matter), a continuity- and ordinality-aware strategy that integrates geometric constraints into both the initialization and training stages. Empirical results on multiple time series analysis benchmarks demonstrate that COM consistently improves the performance of token-based TS-LLMs, achieving competitive results and strong generalizability. Code is available at https://anonymous.4open.science/r/COM .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prior token-based time series large language models (TS-LLMs) overlook the inherent continuity and ordinality of time series tokens, which limits model performance. It proposes COM (Continuity and Ordinality Matter), a strategy that integrates geometric constraints into both the initialization and training stages of token embeddings. Empirical results on multiple time series analysis benchmarks are reported to show that COM consistently improves performance of token-based TS-LLMs, achieving competitive results with strong generalizability. Code is made available.
Significance. If the result holds, the work identifies an overlooked aspect of token embedding design for time series data and provides a targeted, relatively lightweight intervention via geometric constraints. The availability of code is a strength that supports reproducibility. This could influence future TS-LLM designs by emphasizing preservation of time-series-specific properties in embeddings.
major comments (2)
- Abstract: The abstract asserts empirical improvements from COM but provides no details on experimental design, baselines, statistical significance, data splits, or controls. This prevents verification that the data supports the central claim of consistent performance gains.
- Method (initialization and training stages): The central claim requires that COM's geometric constraints enforce continuity and ordinality and that this enforcement drives the reported gains. No quantitative check is provided (e.g., embedding-distance histograms for nearby time-series values, Spearman rank correlation between scalar value and embedding coordinate, or distortion metrics) showing that the learned token embeddings actually satisfy these properties better than prior token-based TS-LLMs. Performance tables alone cannot distinguish the intended mechanism from incidental effects of the added loss terms.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to improve clarity and provide stronger supporting evidence.
read point-by-point responses
-
Referee: Abstract: The abstract asserts empirical improvements from COM but provides no details on experimental design, baselines, statistical significance, data splits, or controls. This prevents verification that the data supports the central claim of consistent performance gains.
Authors: We agree that the abstract would benefit from additional context on the experimental setup. In the revision we will expand the abstract to briefly specify the benchmarks, the token-based TS-LLM baselines compared, and that reported gains are consistent across datasets (with statistical significance noted where computed). revision: yes
-
Referee: Method (initialization and training stages): The central claim requires that COM's geometric constraints enforce continuity and ordinality and that this enforcement drives the reported gains. No quantitative check is provided (e.g., embedding-distance histograms for nearby time-series values, Spearman rank correlation between scalar value and embedding coordinate, or distortion metrics) showing that the learned token embeddings actually satisfy these properties better than prior token-based TS-LLMs. Performance tables alone cannot distinguish the intended mechanism from incidental effects of the added loss terms.
Authors: We acknowledge the value of direct quantitative verification of the embedding properties. Although the benchmark improvements are consistent with the intended effect of the constraints, performance tables alone do not isolate the mechanism. In the revised manuscript we will add quantitative checks, including embedding-distance histograms and rank-correlation metrics, comparing COM embeddings against prior token-based TS-LLMs to demonstrate improved preservation of continuity and ordinality. revision: yes
Circularity Check
No circularity: method and claims are independent of inputs
full rationale
The paper proposes COM as a new strategy that adds geometric constraints during token embedding initialization and training to enforce continuity and ordinality. Performance gains are shown via external benchmark experiments rather than any self-definitional reduction, fitted-parameter-as-prediction, or load-bearing self-citation. No equations or claims reduce the result to its own inputs by construction; the central argument rests on the introduced constraints plus independent evaluation data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chronos: Learning the Language of Time Series
Chronos: Learning the language of time se- ries. arXiv preprint arXiv:2403.07815. Shaojie Bai. 2018. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, and 1 other...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Bioinformatics, 36(16):4406–4414
Transformercpi: improving compound– protein interaction prediction by sequence-based deep learning with self-attention mechanism and label reversal experiments. Bioinformatics, 36(16):4406–4414. Mingyue Cheng, Yiheng Chen, Qi Liu, Zhiding Liu, Y ucong Luo, and Enhong Chen. 2025. Instruc- time: Advancing time series classification with mul- timodal language...
-
[3]
On embeddings for numerical features in tab- ular deep learning. Advances in Neural Information Processing Systems, 35:24991–25004. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex V aughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time-llm: Time series forecasting by repro- gramming large language models. arXiv preprint arXiv:2310.01728. Y axuan Kong, Yiyuan Y ang, Y oontae Hwang, Wenjie Du, Stefan Zohren, Zhangyang Wang, Ming Jin, and Qingsong Wen. 2025. Time-mqa: Time series multi- task question answering with context enhancement. arXiv preprint arXiv:2503.01875. Li Li, Xiaonan S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Ensemble learning for electricity consump- tion forecasting in office buildings. Neurocomput- ing, 423:747–755. Martin F Porter. 1980. An algorithm for suffix strip- ping. Program, 14(3):130–137. Paul Quinlan, Qingguo Li, and Xiaodan Zhu. 2026. Chat-ts: Enhancing multi-modal reasoning over time-series and natural language data. In Proceed- ings of the 19th ...
work page internal anchor Pith review Pith/arXiv arXiv 1980
-
[6]
BEDTime: A Unified Benchmark for Automatically Describing Time Series
Bedtime: A unified benchmark for auto- matically describing time series. arXiv preprint arXiv:2509.05215. Omer Berat Sezer, Mehmet Ugur Gudelek, and Ah- met Murat Ozbayoglu. 2020. Financial time series forecasting with deep learning: A systematic liter- ature review: 2005–2019. Applied soft computing , 90:106181. Y ang Song and Stefano Ermon. 2019. Generat...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Gemma 3 technical report . Preprint, arXiv:2503.19786. Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhu- patiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118. Chengsen Wang, Qi Qi, Jingyu Wang, Haifeng Sun, Zirui Zhuang, Jinming Wu, Lei Zhang, and Jianxin Liao. 2025. Chattime: A unified multimodal time series foundation model bridging numerical and tex- tual data. In AAAI Conference on Artificial Intelli- gence. Shiyu Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
IEEE Transactions on Pat- tern Analysis and Machine Intelligence
Deep time series models: A comprehensive survey and benchmark. IEEE Transactions on Pat- tern Analysis and Machine Intelligence . Y uxuan Wang, Haixu Wu, Jiaxiang Dong, Guo Qin, Haoran Zhang, Y ong Liu, Y unzhong Qiu, Jianmin Wang, and Mingsheng Long. 2024b. Timexer: Em- powering transformers for time series forecasting with exogenous variables. Advances ...
2026
-
[10]
A broad-coverage challenge corpus for sen- tence understanding through inference. In Proceed- ings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, V olume 1 (Long Papers), pages 1112–1122. Haixu Wu, Tengge Hu, Y ong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. 2022....
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
In Proceedings of the VLDB Endowment, 2025
Chatts: Aligning time series with llms via synthetic data for enhanced understanding and rea- soning. In Proceedings of the VLDB Endowment, 2025. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others
2025
-
[12]
Qwen3 technical report. arXiv preprint arXiv:2505.09388. Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
5 GITCO: Inference-Time Context Optimization in TSFMs A
Are transformers effective for time series fore- casting? arXiv preprint arXiv:2205.13504. Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu
-
[14]
BERTScore: Evaluating Text Generation with BERT
Are transformers effective for time series fore- casting? In Proceedings of the AAAI conference on artificial intelligence , volume 37, pages 11121– 11128. Tianyi Zhang, V arsha Kishore, Felix Wu, Kilian Q Weinberger, and Y oav Artzi. 2019. Bertscore: Eval- uating text generation with bert. arXiv preprint arXiv:1904.09675. Y unkai Zhang, Y awen Zhang, Ming...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
See it, Think it, Sorted: Large Multimodal Models are Few- shot Time Series Anomaly Analyzers,
Informer: Beyond efficient transformer for long sequence time-series forecasting. In The Thirty- Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Conference , volume 35, pages 11106–11115. AAAI Press. Jiaxin Zhuang, Leon Y an, Zhenwei Zhang, Ruiqi Wang, Jiawei Zhang, and Y uantao Gu. 2024. See it, think it, sorted: Large multimodal model...
-
[16]
is a comprehensive multimodal benchmark designed to systematically evaluate the capabili- ties of Large Language Models (LLMs) in time series understanding and reasoning. Built upon a hierarchical taxonomy that spans feature analysis, temporal reasoning, and cross-modal alignment, the dataset comprises a total of 2,424 Time Se- ries Question Answering (TS...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.