Overcoming Forgetting in LLM Fine-Tuning with Evolution Strategies
Pith reviewed 2026-06-29 08:35 UTC · model grok-4.3
The pith
Anchored weight decay largely eliminates prior-task drift during evolution strategies fine-tuning of large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
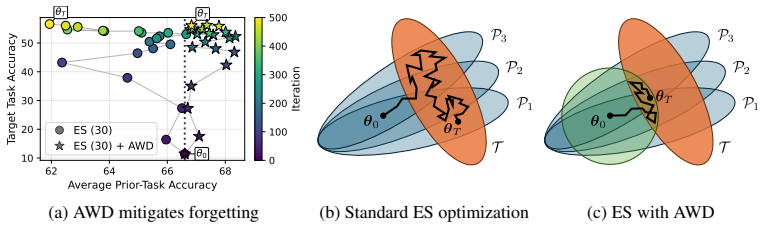
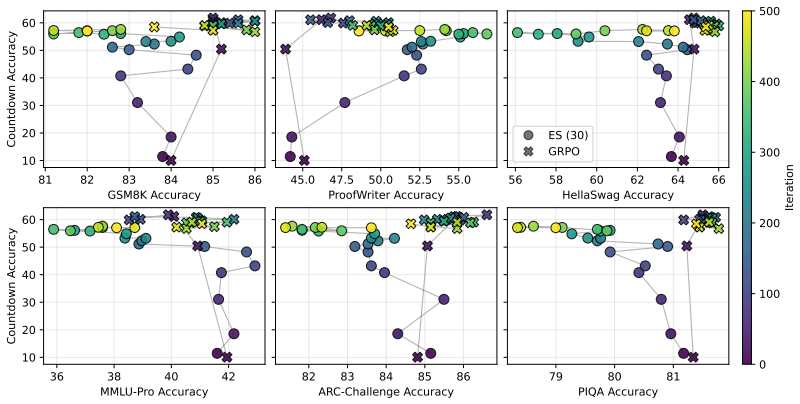
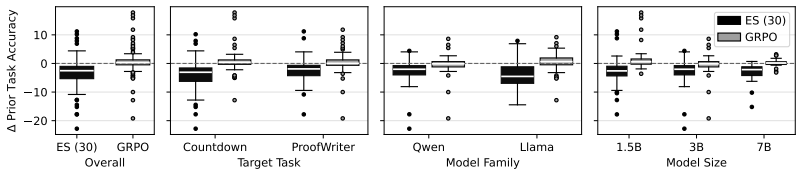
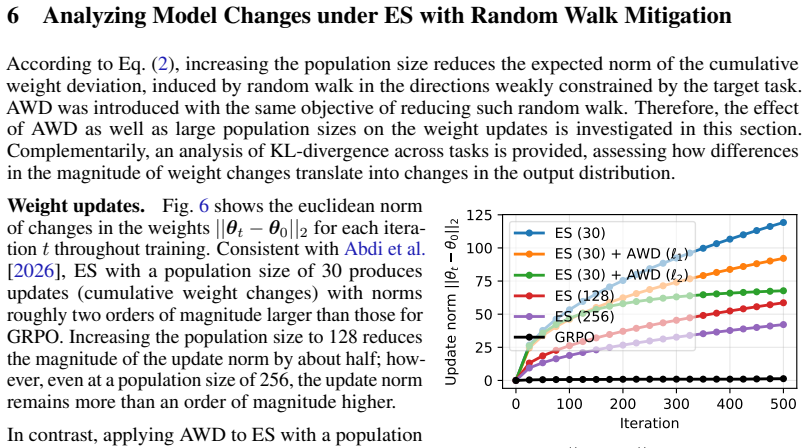
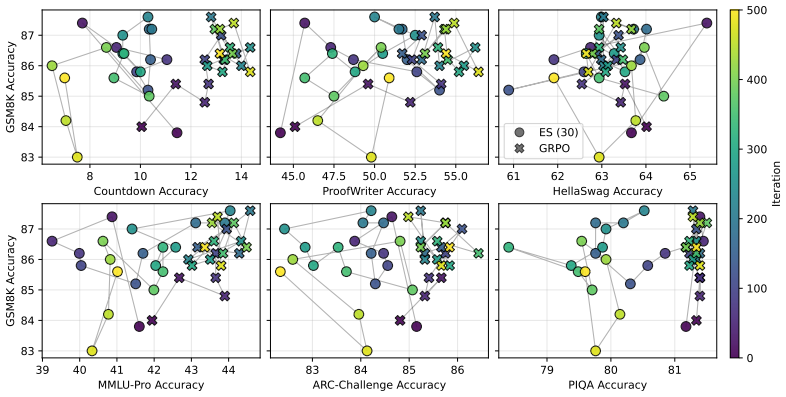
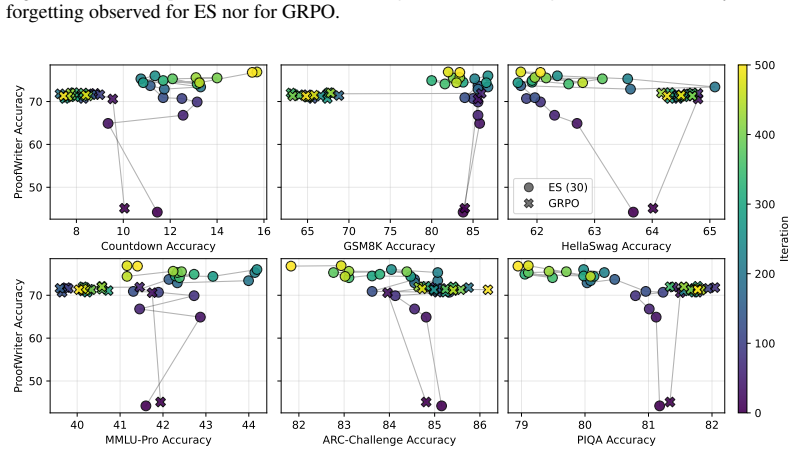
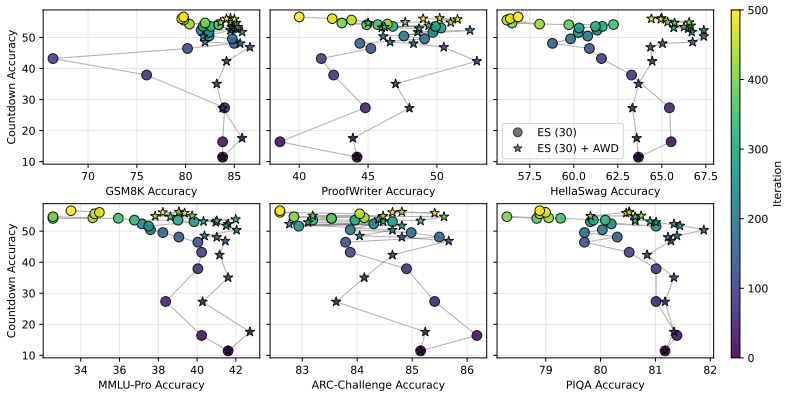
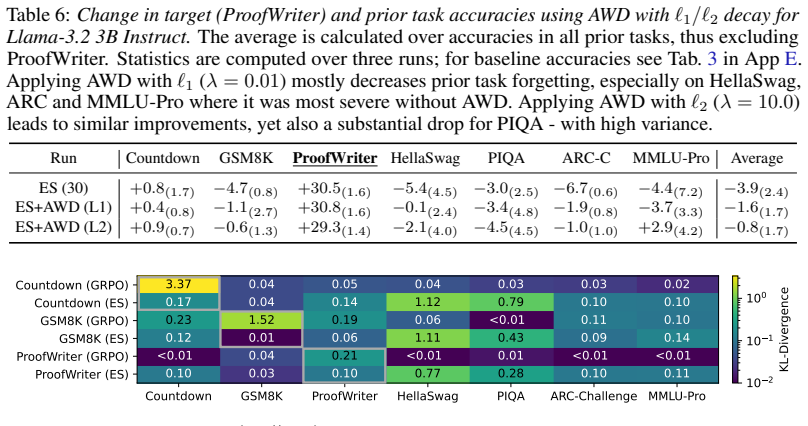
Prior-task forgetting under ES is largely avoidable. Drift arises from random walk behavior in weakly constrained directions of the weight space. Anchored Weight Decay constrains optimization toward the initial model parameters, stabilizing prior-task performance while preserving target-task performance and delivering benefits comparable to large population sizes at reduced cost.
What carries the argument
Anchored Weight Decay (AWD), a regularization term added to the ES objective that penalizes Euclidean distance between current and initial parameters.
If this is right
- ES fine-tuning becomes practical for sequential task learning without requiring replay of old data.
- The same stabilization effect can be obtained at lower cost than scaling the ES population size.
- Drift is a general optimization issue, not unique to ES, so similar anchoring may help other fine-tuning methods.
- Prior-task performance can recover spontaneously even without regularization once the new-task signal strengthens.
Where Pith is reading between the lines
- The approach could extend to other black-box optimizers that also rely on population-based updates.
- Combining AWD with modest population sizes might allow continual learning on models too large for full gradient methods.
- If drift is mainly a consequence of under-constrained directions, then task-specific loss weighting might interact with AWD in predictable ways.
Load-bearing premise
The premise that penalizing deviation from the initial parameters will block harmful random walks without also blocking the parameter changes needed to learn the new task.
What would settle it
A controlled run in which AWD is applied, prior-task metrics remain flat, but target-task metrics fail to improve beyond the starting point.
Figures



read the original abstract
Evolution Strategies (ES) has recently emerged as a competitive alternative to reinforcement learning (RL) for large language model (LLM) fine-tuning, offering advantages through simplicity, scalability, and inference-only training. However, recent work suggests that ES fine-tuning on new tasks may induce forgetting of prior tasks. First, this paper shows that prior task forgetting (1) is better characterized as performance drift rather than irreversible forgetting, with prior-task performance often recovering during ES training; and (2) is not a specific failure mode of ES, but can also arise for fine-tuning with RL methods. Second, it analyzes when and why such drift arises, highlighting its dependence on ES training dynamics, particularly random walk behavior in weakly constrained directions of the weight space. Third, based on these insights, it introduces Anchored Weight Decay (AWD) as a parameter-space regularization technique that constrains optimization toward the initial model parameters. AWD effectively stabilizes prior-task performance while preserving target-task performance, achieving benefits comparable to large ES population sizes at much lower computational cost. Thus, contrary to previous beliefs, the paper shows that prior-task forgetting under ES is largely avoidable, positioning ES as a promising approach for continual learning in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prior-task forgetting during ES fine-tuning of LLMs is better described as recoverable performance drift rather than irreversible loss, occurs under RL fine-tuning as well, arises from random-walk dynamics in weakly constrained weight-space directions, and can be mitigated by a new Anchored Weight Decay (AWD) regularizer that anchors parameters to their initial values. AWD is reported to stabilize prior-task performance while preserving target-task gains at lower cost than simply increasing ES population size.
Significance. If the empirical claims hold, the work would reposition ES as a practical method for continual LLM fine-tuning by showing that drift is avoidable via a lightweight parameter-space penalty, with potential advantages in simplicity and scalability over RL-based continual learning. The mechanistic analysis of drift in high-dimensional optimization could inform regularization choices more broadly.
major comments (2)
- [Abstract and the section presenting AWD results] The central claim that AWD 'stabilizes prior-task performance while preserving target-task performance' (abstract) is load-bearing and rests on the assumption that directions needed for the new task are either already well-constrained or that the AWD coefficient can be chosen so target progress is unaffected. If the target task optimum lies primarily along the weakly constrained directions identified in the random-walk analysis, the same L2 penalty to initial weights that halts prior-task drift will also impede target-task improvement; the manuscript must supply quantitative trade-off curves (e.g., target vs. prior performance vs. AWD strength) on tasks where initial and target optima are demonstrably distant.
- [Section comparing ES and RL forgetting] The assertion that drift 'is not a specific failure mode of ES, but can also arise for fine-tuning with RL methods' requires direct side-by-side experiments under matched conditions (same model, tasks, and hyper-parameter regimes) to establish that the phenomenon is comparable in magnitude and mechanism; without such controls the generality claim remains under-supported.
minor comments (2)
- [Method section introducing AWD] Notation for the AWD term (e.g., the precise form of the anchor penalty and how its coefficient is scheduled) should be stated explicitly with an equation number rather than described only in prose.
- [Figures showing performance trajectories] Figure captions and axis labels for any recovery or trade-off plots should explicitly state the population size, number of generations, and AWD coefficient values used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below, indicating where we agree that additional material will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and the section presenting AWD results] The central claim that AWD 'stabilizes prior-task performance while preserving target-task performance' (abstract) is load-bearing and rests on the assumption that directions needed for the new task are either already well-constrained or that the AWD coefficient can be chosen so target progress is unaffected. If the target task optimum lies primarily along the weakly constrained directions identified in the random-walk analysis, the same L2 penalty to initial weights that halts prior-task drift will also impede target-task improvement; the manuscript must supply quantitative trade-off curves (e.g., target vs. prior performance vs. AWD strength) on tasks where initial and target optima are demonstrably distant.
Authors: We appreciate the referee's emphasis on potential trade-offs. Our task selection and random-walk analysis were chosen such that target-task progress occurs without requiring large movement along the weakly constrained directions that drive prior-task drift; the reported AWD results reflect coefficients that achieve this balance. To directly address the concern, we will add quantitative trade-off curves (prior-task and target-task performance versus AWD coefficient) for tasks where the initial and target optima are demonstrably distant. These will be included in the revised manuscript. revision: yes
-
Referee: [Section comparing ES and RL forgetting] The assertion that drift 'is not a specific failure mode of ES, but can also arise for fine-tuning with RL methods' requires direct side-by-side experiments under matched conditions (same model, tasks, and hyper-parameter regimes) to establish that the phenomenon is comparable in magnitude and mechanism; without such controls the generality claim remains under-supported.
Authors: We agree that more tightly matched hyper-parameter regimes would provide stronger evidence. Our existing experiments already employ the same model and tasks for both ES and RL; hyperparameters were tuned separately because the optimizers have fundamentally different requirements. We will add a controlled comparison under more closely aligned hyper-parameter settings and will clarify the mechanistic similarities (random-walk behavior in weakly constrained directions) in the text. This addition will be made in revision. revision: partial
Circularity Check
No significant circularity; central claims rest on empirical results and a new regularization term
full rationale
The paper characterizes forgetting as performance drift via experiments, attributes it to random-walk dynamics in weakly constrained weight directions through analysis of ES training, and introduces Anchored Weight Decay (AWD) as a parameter-space L2 penalty to initial weights. No equations reduce any prediction to a fitted input by construction, no self-citations are load-bearing for the core argument, and the effectiveness of AWD is demonstrated empirically rather than derived tautologically. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ES training dynamics involve random walk behavior in weakly constrained directions of the weight space that produces recoverable performance drift.
Forward citations
Cited by 1 Pith paper
-
Knowing in Advance When an Evolutionary Outer Loop Will Not Help: A Pre-Registered Cheap-Baseline Screening Rule
A screening rule skips evolutionary outer loops when the ratio of best single-shot gain to best cheap gain meets or exceeds 90%, validated on pre-registered lab cases where the gate fired and loops were abandoned.
Reference graph
Works this paper leans on
-
[1]
is using wrap to wrap a pair of skis
-
[2]
is ripping level tiles off
-
[3]
is holding a Rubik’s Cube
-
[4]
PIQAevaluates physical commonsense understanding, requiring the model to choose solutions that are feasible in real-world scenarios
starts pulling up roofing on a roof. PIQAevaluates physical commonsense understanding, requiring the model to choose solutions that are feasible in real-world scenarios. Published under Academic Free License v.3.0 in the official codebase of Bisk et al. [2020]. 3https://huggingface.co/datasets/tasksource/proofwriter 17 Answer format Extraction logic <0/1/...
2020
-
[5]
Provide the guinea pig with a cage full of a few inches of bedding made of ripped paper strips, you will also need to supply it with a water bottle and a food dish
-
[6]
Answer format Extraction logic <1/2> The strict format is satisfied only if the entire output is exactly1 or2 up to surrounding whitespace
Provide the guinea pig with a cage full of a few inches of bedding made of ripped jeans material, you will also need to supply it with a water bottle and a food dish. Answer format Extraction logic <1/2> The strict format is satisfied only if the entire output is exactly1 or2 up to surrounding whitespace. For answer extraction, the first standalone 1 or 2...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.