MedCase-Structured: A Text-to-FHIR Dataset for Benchmarking Diagnostic Reasoning in Clinically Realistic EHR Settings
Pith reviewed 2026-06-30 11:02 UTC · model grok-4.3
The pith
LLMs achieve lower diagnostic accuracy on structured FHIR clinical data than on plain text cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A staged LLM generation pipeline with terminology-grounded validation produces valid HL7 FHIR R4 bundles from clinician-authored cases, and evaluation on the resulting MedCase-Structured dataset shows consistently lower diagnostic accuracy for LLMs when inputs are provided in structured FHIR format rather than plain text.
What carries the argument
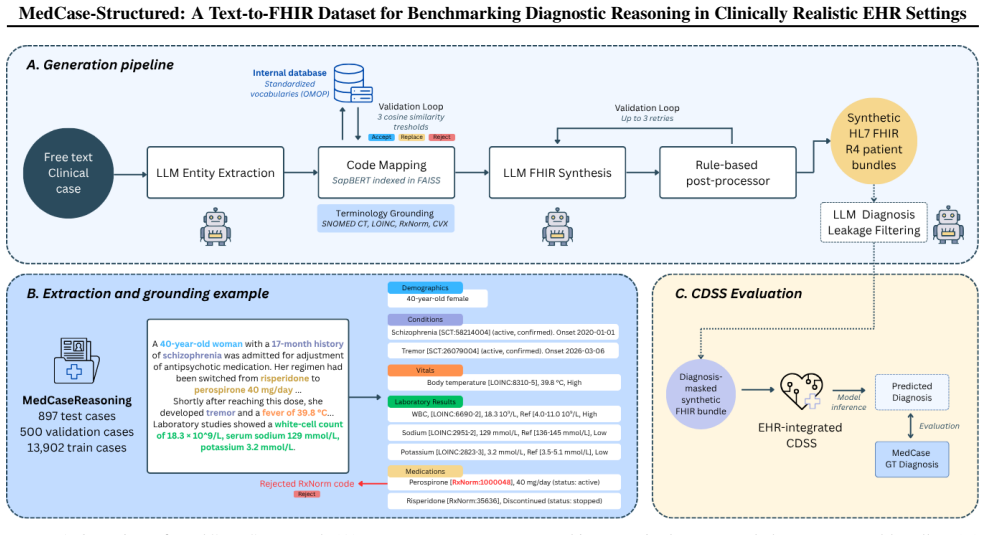
The text-to-FHIR pipeline that combines staged LLM generation with validation and repair to produce clinically aligned HL7 FHIR R4 bundles.
If this is right
- Benchmarks for clinical reasoning models should incorporate structured interoperable formats to match deployment conditions.
- Accuracy measured on plain text alone cannot be assumed to hold when models receive data from actual EHR systems.
- The pipeline enables controlled variation of input structure while preserving the original diagnostic content.
- Deployment of LLM-based decision support will require separate evaluation on structured data to identify format-specific failure modes.
Where Pith is reading between the lines
- Models may need explicit training on FHIR schemas and coded terminology to reduce the performance gap.
- The same generation approach could be applied to other clinical data standards beyond FHIR.
- Longer-term, datasets like this could support automated repair of model outputs to match required interoperability formats.
Load-bearing premise
The generated FHIR bundles are close enough to real electronic health record data that the observed accuracy drop is caused by input format rather than artifacts from the generation process.
What would settle it
A head-to-head test in which the same LLMs process both the generated FHIR bundles and a matched set of real de-identified hospital EHR records, measuring whether the accuracy gap persists or disappears.
Figures
read the original abstract
Large language models (LLMs) show promise for clinical reasoning and decision support, but evaluation in realistic, electronic health record-congruent settings remains limited. Existing benchmarks often rely on static datasets or unstructured inputs that do not reflect the structured, interoperable data formats used in clinical systems. We introduce a pipeline for generating clinically realistic HL7 FHIR R4 bundles from unstructured text, enabling controllable evaluation of clinical decision support systems. The pipeline combines staged LLM generation with terminology-grounded validation and repair to reduce hallucinated codes and enforce structural and semantic consistency. Applying this approach to MedCaseReasoning, we construct MedCase-Structured, a synthetic dataset aligned with clinician-authored diagnostic cases, achieving valid FHIR generation for 82.5% of cases. Evaluation on MedCase-Structured reveals consistently lower diagnostic accuracy for LLMs on structured FHIR inputs than with plain text, highlighting the importance of deployment-aligned benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a pipeline that uses staged LLM generation combined with terminology-grounded validation and repair to convert unstructured clinical cases into HL7 FHIR R4 bundles. Applied to the MedCaseReasoning dataset, this produces the MedCase-Structured collection, reported to achieve valid FHIR output for 82.5% of cases. The central empirical claim is that LLMs exhibit consistently lower diagnostic accuracy when reasoning over the resulting structured FHIR inputs than over the original plain-text cases, motivating the need for deployment-aligned benchmarks.
Significance. If the accuracy drop is shown to arise from the structured format rather than generation artifacts, the work would be significant for clinical NLP by supplying both a reproducible text-to-FHIR pipeline and a benchmark that better matches real EHR interoperability requirements. The pipeline itself is a concrete engineering contribution that could be reused for other datasets.
major comments (2)
- [Abstract] Abstract: the 82.5% validity rate is stated without any description of the validity criteria, the precise validation/repair steps, inter-annotator agreement, or quantitative checks (e.g., clinician review of realism or information-content comparison) that would establish the bundles are free of systematic artifacts.
- [Evaluation] Evaluation (implied by the accuracy-drop claim): the comparison of diagnostic accuracy between plain-text and FHIR inputs provides no information on the LLMs tested, number of cases, exact accuracy metric, presence of baselines, error bars, or statistical tests, rendering it impossible to determine whether the reported drop is attributable to input format rather than dataset-construction effects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where additional detail is needed to strengthen the presentation of the validity criteria and evaluation protocol. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 82.5% validity rate is stated without any description of the validity criteria, the precise validation/repair steps, inter-annotator agreement, or quantitative checks (e.g., clinician review of realism or information-content comparison) that would establish the bundles are free of systematic artifacts.
Authors: We agree that the abstract does not describe the validity criteria or validation/repair steps. The full manuscript (Section 3) specifies the staged generation process, terminology-grounded validation against FHIR StructureDefinitions and terminology servers (SNOMED CT, LOINC, RxNorm), and automated repair for structural and code validity. No inter-annotator agreement applies because validation is rule-based and automated; no clinician review of realism was performed. We will revise the abstract to include a concise statement of the validity criteria and key validation steps. revision: yes
-
Referee: [Evaluation] Evaluation (implied by the accuracy-drop claim): the comparison of diagnostic accuracy between plain-text and FHIR inputs provides no information on the LLMs tested, number of cases, exact accuracy metric, presence of baselines, error bars, or statistical tests, rendering it impossible to determine whether the reported drop is attributable to input format rather than dataset-construction effects.
Authors: The referee is correct that the provided manuscript text does not include these evaluation details. We will revise the manuscript to explicitly report the LLMs evaluated, the number of cases, the precise accuracy metric, any baselines, error bars, and statistical tests. This revision will also clarify that the plain-text and FHIR comparisons use identical case content to isolate format effects. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an LLM-based pipeline to convert text cases into FHIR bundles (with validation/repair steps) and then reports an empirical accuracy comparison between plain-text and structured inputs on the resulting dataset. No equations, fitted parameters, or predictions are present. No self-citations are invoked as load-bearing premises for the central claim. The observed accuracy drop is presented as a direct measurement on the constructed data rather than a quantity derived by construction from prior fitted values or self-referential definitions. The derivation chain is therefore self-contained and does not reduce to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Staged LLM generation combined with terminology-grounded validation produces clinically realistic and semantically consistent FHIR bundles
Reference graph
Works this paper leans on
-
[1]
ISSN 1527-974X. doi: 10.1093/jamia/ocad002. URL https://doi.org/10.1093/jamia/ocad002. Frei, J., Feldhus, N., Raithel, L., Roller, R., Meyer, A., and Kramer, F. Infherno: End-to-end Agent-based FHIR Resource Synthesis from Free-form Clinical Notes. In Croce, D., Leidner, J., and Moosavi, N. S. (eds.),Pro- ceedings of the 19th Conference of the European Ch...
-
[2]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Shi, J., Wang, X., He, X., and Chua, T
Association for Computational Linguistics. ISBN 979-8-89176-382-1. doi: 10.18653/v1/ 2026.eacl-demo.13. URL https://aclanthology. org/2026.eacl-demo.13/. HL7 International. FHIR R4 (v4.0.1). URL https:// hl7.org/fhir/R4/index.html. Johnson, A. E. W., Bulgarelli, L., Shen, L., Gayles, A., Shammout, A., Horng, S., Pollard, T. J., Hao, S., Moody, B., Gow, B....
-
[3]
doi: 10.1038/ s41597-022-01899-x
ISSN 2052-4463. doi: 10.1038/ s41597-022-01899-x. URL https://www.nature. com/articles/s41597-022-01899-x. Johnson, J., Douze, M., and J´egou, H. Billion-scale similar- ity search with GPUs, February
2052
-
[4]
Billion-scale similarity search with GPUs
URL http:// arxiv.org/abs/1702.08734. arXiv:1702.08734 [cs]. Lee, G., Bach, E., Yang, E., Pollard, T., Johnson, A., Choi, E., jia, Y ., and Lee, J. H. FHIR-AgentBench: Bench- marking LLM Agents for Realistic Interoperable EHR Question Answering, November
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URL http:// arxiv.org/abs/2509.19319. arXiv:2509.19319 [cs]. Li, L., Zhou, J., Gao, Z., Hua, W., Fan, L., Yu, H., Hagen, L., Zhang, Y ., Assimes, T. L., Hemphill, L., and Ma, S. A scoping review of using Large Language Models (LLMs) to investigate Electronic Health Records (EHRs), May 2024a. URL http://arxiv.org/abs/2405. 03066. arXiv:2405.03066 [cs]. Li,...
-
[6]
URL http://arxiv. org/abs/2010.11784. arXiv:2010.11784 [cs]. Mansoor, I., Abdullah, M., Rizwan, M. D., and Fraz, M. M. Reasoning with large language models in medicine: a systematic review of techniques, challenges and clinical integration.Health Information Science and Systems, 14 (1):6, November
-
[7]
doi: 10.1007/ s13755-025-00403-0
ISSN 2047-2501. doi: 10.1007/ s13755-025-00403-0. URL https://doi.org/10. 1007/s13755-025-00403-0. Navarro, D. F., Magrabi, F., and Coiera, E. Eval- uation format, not model capability, drives triage failure in the assessment of consumer health AI, March
2047
-
[8]
URL http://arxiv.org/abs/ 2603.11413. arXiv:2603.11413 [cs]. Shool, S., Adimi, S., Saboori Amleshi, R., Bitaraf, E., Golpira, R., and Tara, M. A systematic review of large language model (LLM) evaluations in clinical medicine.BMC medical informatics and decision mak- ing, 25(1):117, March
-
[9]
doi: 10.1186/s12911-025-02954-4
ISSN 1472-6947. doi: 10.1186/s12911-025-02954-4. Walonoski, J., Kramer, M., Nichols, J., Quina, A., Moe- sel, C., Hall, D., Duffett, C., Dube, K., Gallagher, T., and McLachlan, S. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record.Jour- nal of the American Medical Informat...
-
[10]
ISSN 1527-974X. doi: 10.1093/jamia/ocx079. URL https://doi.org/10. 1093/jamia/ocx079. Wang, Y ., Wang, L., Rastegar-Mojarad, M., Moon, S., Shen, F., Afzal, N., Liu, S., Zeng, Y ., Mehrabi, S., Sohn, S., and Liu, H. Clinical Information Extraction Applications: A 5 MedCase-Structured: A Text-to-FHIR Dataset for Benchmarking Diagnostic Reasoning in Clinical...
-
[11]
doi: 10.1016/ j.jbi.2017.11.011
ISSN 1532-0464. doi: 10.1016/ j.jbi.2017.11.011. URL https://pmc.ncbi.nlm. nih.gov/articles/PMC5771858/. Wu, K., Wu, E., Thapa, R., Wei, K., Zhang, A., Suresh, A., Tao, J. J., Sun, M. W., Lozano, A., and Zou, J. MedCaseReasoning: Evaluating and learn- ing diagnostic reasoning from clinical case reports, May
2017
- [12]
-
[13]
URL http://arxiv.org/abs/ 2511.08206. arXiv:2511.08206 [cs]. 6 MedCase-Structured: A Text-to-FHIR Dataset for Benchmarking Diagnostic Reasoning in Clinically Realistic EHR Settings A. MedCase-Structured Sample Listing 1 shows the truncated version of a representative structured patient bundle from MedCase-Structured. The full sample is available athttps:/...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.