Soft-NBCE: Entropy-Weighted Chunk Fusion for Long-Context
Pith reviewed 2026-06-28 17:37 UTC · model grok-4.3
The pith
Soft-NBCE replaces hard chunk selection with entropy-weighted soft fusion plus consistency distillation to improve multi-hop reasoning on long contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
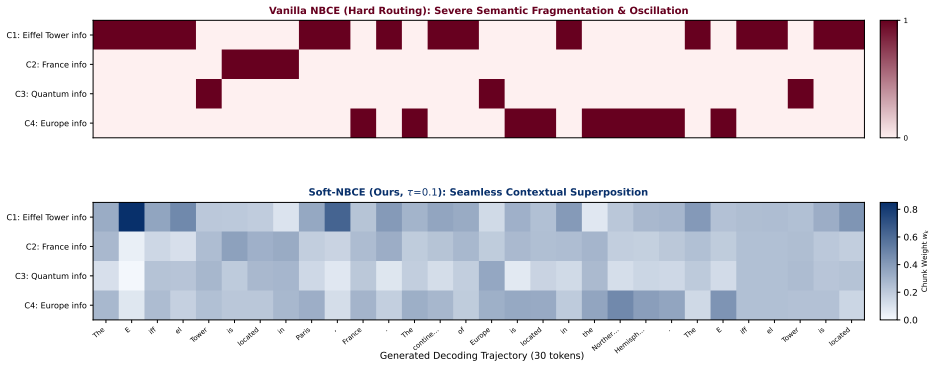
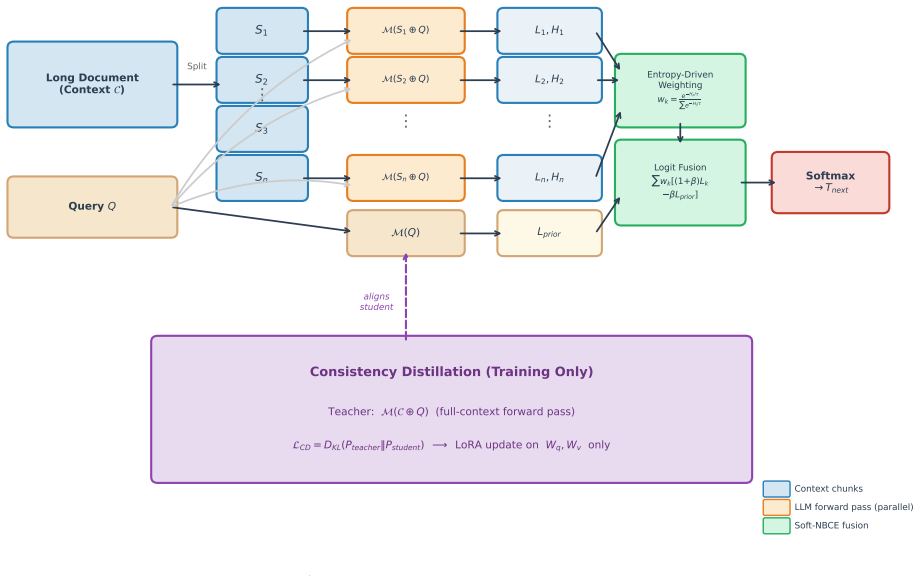
Soft-NBCE replaces the hard-selection strategy of NBCE with soft entropy-weighted chunk fusion using temperature-scaled softmax over predictive entropies for log-space aggregation across chunk-conditioned distributions, and introduces Consistency Distillation via LoRA-based self-distillation that constrains the chunked logit distribution toward a full-context teacher via KL-divergence, producing higher F1 on MuSiQue and HotpotQA while preserving NIAH accuracy at O(L^2/n) memory.
What carries the argument
Soft entropy-weighted chunk fusion, in which continuous weights from a temperature-scaled softmax over chunk entropies are used to aggregate all chunk-conditioned distributions in log space, together with Consistency Distillation that aligns the result to a full-context teacher.
If this is right
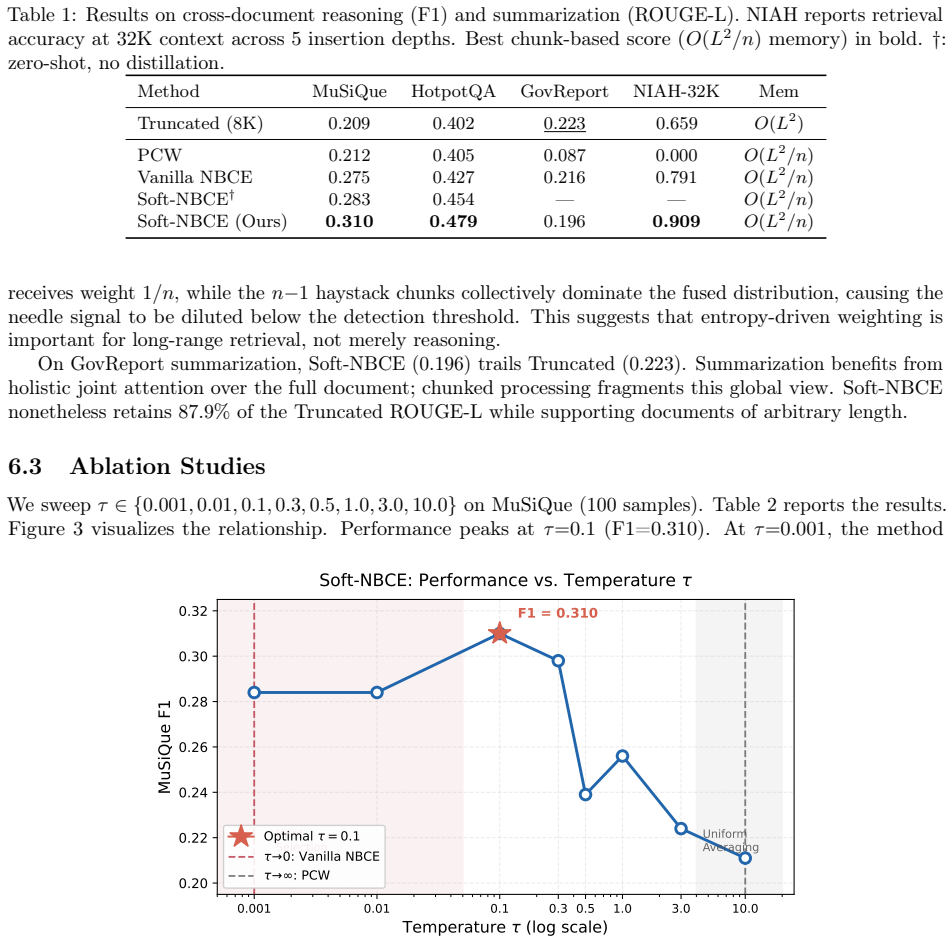
- Multi-hop F1 rises on MuSiQue (0.310 versus 0.275) and HotpotQA (0.479 versus 0.427).
- Needle-in-a-haystack retrieval accuracy holds at 0.909 for 32K contexts.
- Peak memory remains O(L^2/n) where n denotes the number of chunks.
- LoRA-based distillation enables the compensation without retraining the entire model.
Where Pith is reading between the lines
- The soft-fusion idea could be tested on other hard-routing inference schemes that currently switch abruptly between context segments.
- When a full-context teacher is unavailable, alternative regularizers might be needed to keep the compensation effect.
- Gains may increase with context length if the independence penalty grows with the number of chunks.
- The method's log-space aggregation might be combined with existing sparse-attention patterns to further reduce memory.
Load-bearing premise
The conditional independence introduced by chunking can be partially compensated by distilling the chunked logit distribution toward a full-context teacher via KL-divergence.
What would settle it
An ablation that removes Consistency Distillation and shows multi-hop F1 scores returning to vanilla NBCE levels would falsify the claim that distillation compensates for the independence assumption.
Figures
read the original abstract
The quadratic complexity of self-attention remains a bottleneck for Large Language Models (LLMs) processing ultra-long contexts. The Naive Bayes Cognitive Engine (NBCE) parallelizes long-context inference by chunking documents and routing to the lowest-entropy chunk at each decoding step. This hard-selection strategy causes semantic fragmentation during cross-chunk reasoning, as abrupt routing changes between adjacent tokens disrupt the model's contextual grounding. We present Soft-NBCE, a lightweight extension that replaces discrete chunk selection with soft entropy-weighted chunk fusion. A temperature-scaled Softmax over predictive entropies assigns continuous weights to all chunks, enabling log-space aggregation across chunk-conditioned distributions. To partially compensate for the conditional independence assumption introduced by chunking, we propose Consistency Distillation, a LoRA-based self-distillation that constrains the chunked logit distribution toward a full-context teacher via KL-divergence. On LongBench multi-hop benchmarks, Soft-NBCE with Consistency Distillation improves consistently over NBCE-style baselines (MuSiQue F1: 0.310 vs.\ 0.275 for Vanilla NBCE; HotpotQA F1: 0.479 vs.\ 0.427) while maintaining retrieval accuracy (NIAH-32K: 0.909) at O(L^2/n) peak memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Soft-NBCE as an extension to NBCE for long-context LLM inference. It replaces hard chunk selection with temperature-scaled softmax entropy weighting for soft fusion of chunk-conditioned distributions in log space, and adds Consistency Distillation (LoRA self-distillation via KL divergence to a full-context teacher) to mitigate chunking-induced conditional independence. On LongBench, it reports F1 gains on multi-hop tasks (MuSiQue: 0.310 vs. 0.275; HotpotQA: 0.479 vs. 0.427) while preserving NIAH-32K retrieval accuracy (0.909) at O(L²/n) memory.
Significance. If the performance deltas are attributable to the soft weighting and distillation mechanism rather than unstated factors, the work would provide a practical, low-overhead route to sub-quadratic long-context inference that preserves cross-chunk reasoning. The O(L²/n) memory scaling and retention of retrieval accuracy are concrete strengths; however, the absence of isolating experiments leaves the central compensation claim unverified.
major comments (2)
- [Abstract / Methods] Abstract and methods description: the reported F1 improvements on MuSiQue and HotpotQA are presented as evidence that Consistency Distillation compensates for conditional independence, yet no ablation (with vs. without the KL term), no pre/post-distillation logit alignment metric (KL or TV distance), and no control using only soft weighting are provided. This makes it impossible to attribute the +0.035 / +0.052 deltas to the claimed mechanism.
- [Abstract] The distillation target is a full-context model from the same family; combined with entropy weights derived from the chunked model's own predictions, this introduces partial circular dependence that is not quantified or controlled for in the reported results.
minor comments (2)
- [Abstract] The temperature hyper-parameter is listed as the sole free parameter but its value and sensitivity are not reported.
- [Abstract] No variance, standard deviation, or number of runs is given for the benchmark numbers, contrary to standard practice for F1 reporting on LongBench.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on attribution and potential dependencies. We address each major comment below and will revise the manuscript accordingly to strengthen the claims with additional controls and discussion.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods description: the reported F1 improvements on MuSiQue and HotpotQA are presented as evidence that Consistency Distillation compensates for conditional independence, yet no ablation (with vs. without the KL term), no pre/post-distillation logit alignment metric (KL or TV distance), and no control using only soft weighting are provided. This makes it impossible to attribute the +0.035 / +0.052 deltas to the claimed mechanism.
Authors: We agree that the current manuscript lacks the isolating ablations needed to attribute the F1 gains specifically to Consistency Distillation. In the revised version we will add: (i) Soft-NBCE without the KL term, (ii) soft weighting alone (no distillation), and (iii) pre/post-distillation logit alignment metrics (KL divergence and total variation distance) on the multi-hop tasks. These experiments will be reported in a new table or appendix section. revision: yes
-
Referee: [Abstract] The distillation target is a full-context model from the same family; combined with entropy weights derived from the chunked model's own predictions, this introduces partial circular dependence that is not quantified or controlled for in the reported results.
Authors: The full-context teacher is executed independently on the complete input, while entropy weights are computed solely from the chunked model's predictive entropies during inference; thus the dependence is not strictly circular. Nevertheless, shared model-family biases are unquantified in the present results. We will add a dedicated paragraph in the Methods/Discussion section addressing this issue and, where compute permits, include a control using a teacher from a different family or report prediction-overlap statistics. revision: partial
Circularity Check
No significant circularity detected in claimed method or results
full rationale
The paper defines Soft-NBCE via explicit algorithmic steps (temperature-scaled softmax over chunk entropies for soft fusion, followed by LoRA self-distillation with KL to a full-context teacher) and reports empirical benchmark deltas. Entropy weights are computed at inference time from the chunked model's own outputs as part of the proposed procedure, not fitted to target data and then relabeled as a prediction. The distillation target is an external full-context model, supplying an independent reference distribution. No equations reduce by construction to inputs, no self-citation is invoked as a uniqueness theorem, and no ansatz is smuggled via prior work. The central claim rests on observable performance numbers rather than tautological re-expression of the method itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature
axioms (2)
- domain assumption Chunking the input introduces a conditional independence assumption across chunks
- domain assumption Predictive entropy from each chunk-conditioned distribution is a meaningful signal for weighting
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[2]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[3]
Pointer Sentinel Mixture Models
Pointer Sentinel Mixture Models , author=. arXiv preprint arXiv:1609.07843 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
NAACL , year=
Efficient Attentions for Long Document Summarization , author=. NAACL , year=
-
[5]
2023 , howpublished=
Claude's Needle In A Haystack Evaluation , author=. 2023 , howpublished=
2023
-
[6]
Extending Context Window of Large Language Models via Positional Interpolation
Extending context window of large language models via positional interpolation , author=. arXiv preprint arXiv:2306.15595 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
The Twelfth International Conference on Learning Representations (ICLR) , year=
YaRN: Efficient context window extension of large language models , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[8]
The Twelfth International Conference on Learning Representations (ICLR) , year=
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[9]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year=
Parallel Context Windows for Large Language Models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[10]
arXiv preprint arXiv:2308.16137 , year=
LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models , author=. arXiv preprint arXiv:2308.16137 , year=
-
[11]
2023 , howpublished=
NBCE: Naive Bayes Cognitive Engine for Context Extension , author=. 2023 , howpublished=
2023
-
[12]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
LongBench: A bilingual, multitask benchmark for long context understanding , author=. arXiv preprint arXiv:2308.14508 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2305.14196 , year=
ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding , author=. arXiv preprint arXiv:2305.14196 , year=
-
[14]
Transactions of the Association for Computational Linguistics (TACL) , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics (TACL) , volume=
-
[15]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[16]
International Conference on Learning Representations (ICLR) , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.