DeblurNVS: Geometric Latent Diffusion for Novel View Synthesis from Sparse Motion-Blurred Images
Pith reviewed 2026-06-28 17:26 UTC · model grok-4.3
The pith
DeblurNVS restores geometric representations from sparse motion-blurred images via latent diffusion to synthesize sharp novel views without per-scene optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
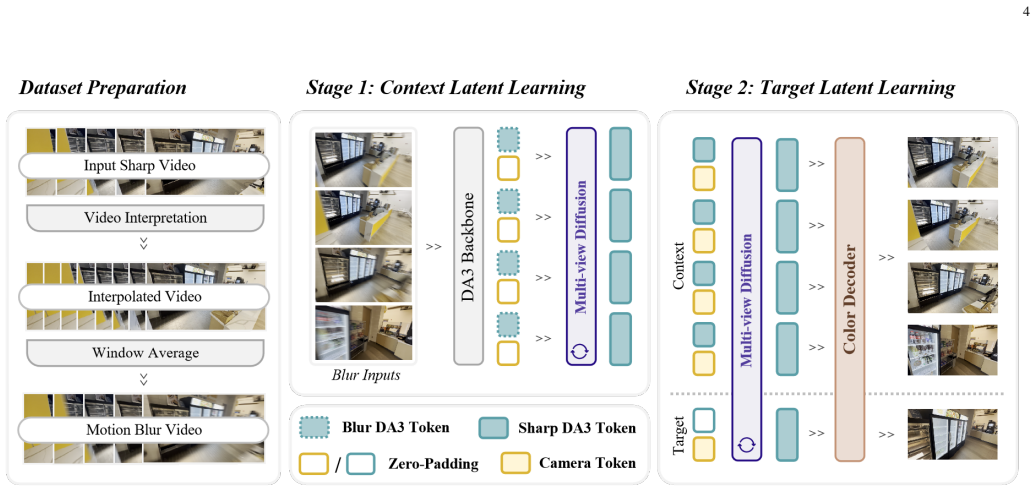
DeblurNVS restores the intermediate geometric representations needed for multi-view reasoning from blurred inputs, enabling the synthesis of high-fidelity novel views directly from sparse motion-blurred images without requiring per-scene optimization. The restored representations are combined with target camera information to synthesize the target-view representation and reconstruct a sharp RGB novel view.
What carries the argument
Geometric latent diffusion that restores intermediate geometric representations from motion-blurred observations to recover structure and correspondence cues.
If this is right
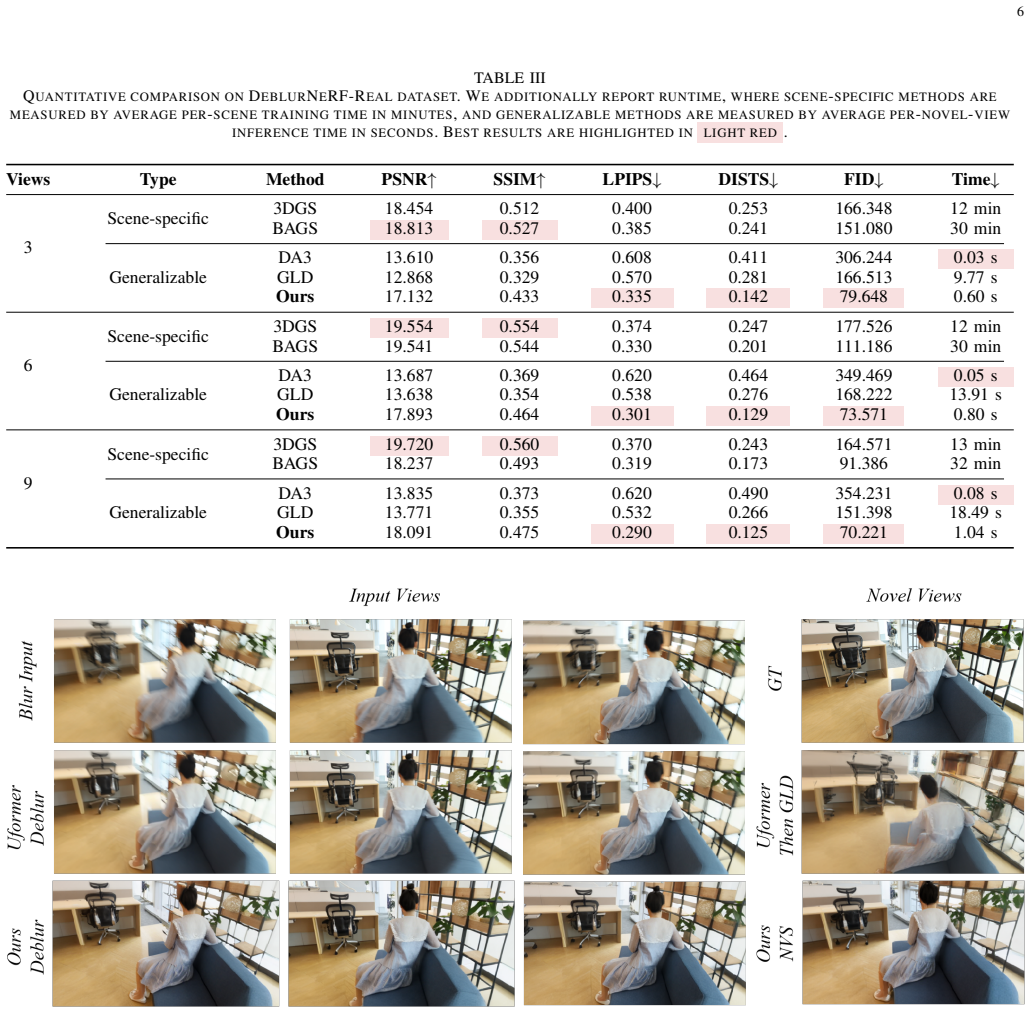
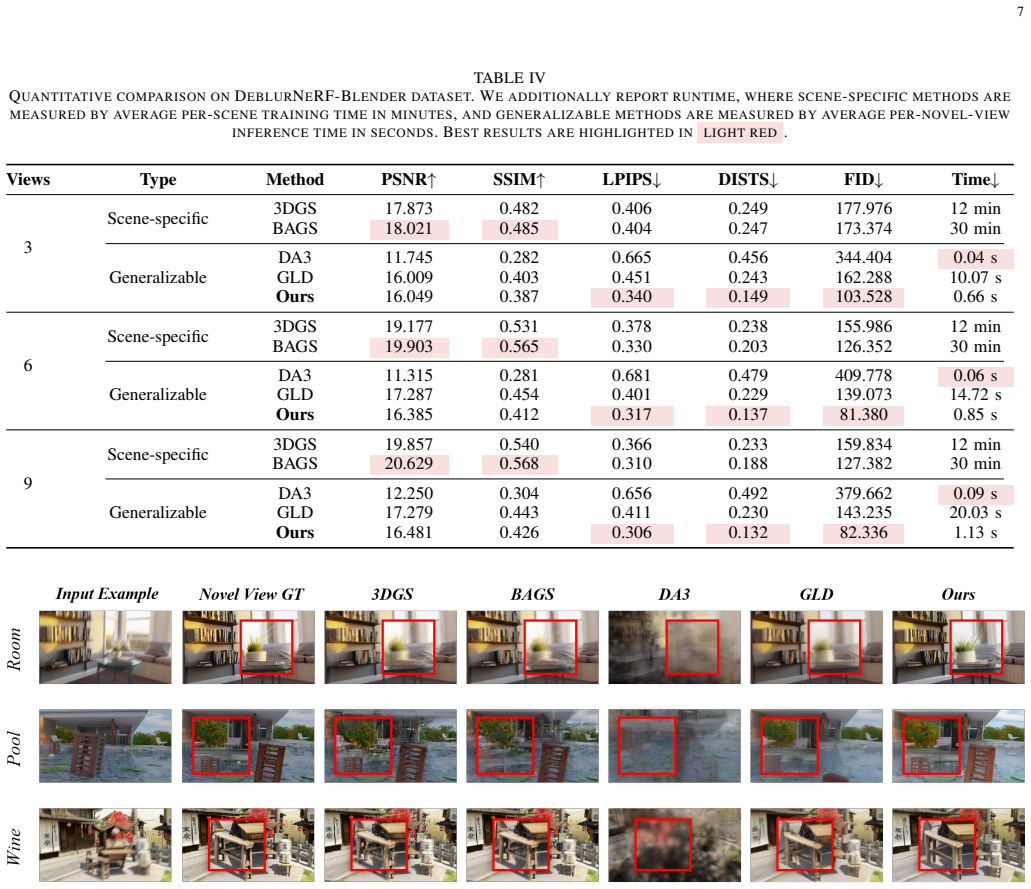
- The method produces perceptually sharper and structurally more stable novel views than existing baselines on synthetic motion-blur benchmarks.
- It generalizes from the synthetic training distribution to real motion-blurred scenes.
- It enables efficient sparse-view synthesis by removing the need for costly per-scene optimization at test time.
- A large-scale motion-blurred NVS dataset constructed via interpolation-based finite-exposure blur synthesis supports the training.
Where Pith is reading between the lines
- If geometric restoration proves robust, the same latent-diffusion step could be adapted to other common degradations such as noise or low-light conditions that also weaken multi-view correspondences.
- The separation of restoration and synthesis stages suggests that future work could swap in different diffusion backbones or geometry encoders without retraining the entire pipeline.
- Success on real scenes would imply that large synthetic blur datasets can substitute for hard-to-collect paired real blurred-and-sharp multi-view data in practical capture settings.
Load-bearing premise
Restoring intermediate geometric representations from blurred inputs is sufficient to recover reliable structure and correspondence cues needed for accurate multi-view synthesis.
What would settle it
A side-by-side evaluation on real motion-blurred scenes where novel views from DeblurNVS are compared against both clean-image baselines and ground-truth sharp views of the same scenes, checking whether structural stability and sharpness improve measurably.
Figures





read the original abstract
Novel view synthesis (NVS) is a fundamental problem in computer vision and graphics. Recent advances in neural radiance fields (NeRF), 3D Gaussian Splatting (3DGS), and generative view synthesis have substantially improved its quality. Yet most methods still rely on clean observations, where image structures and cross-view geometric cues are well preserved. Motion blur breaks this assumption by corrupting local details and weakening multi-view correspondences. Such blur commonly arises from camera shake, scene motion, or finite exposure in practical capture. Blur-aware NVS methods address this degradation by modeling image formation, but their reliance on costly per-scene optimization limits efficient and generalizable sparse-view synthesis. To address this, we propose DeblurNVS, a novel framework for synthesizing high-fidelity novel views directly from sparse motion-blurred images, without requiring per-scene optimization. DeblurNVS restores the intermediate geometric representations needed for multi-view reasoning, enabling blurred inputs to recover reliable structure and correspondence cues. The restored representations are then combined with target camera information to synthesize the target-view representation and reconstruct a sharp RGB novel view. To enable the large-scale training, we construct a motion-blurred NVS dataset from DL3DV-10K using interpolation-based finite-exposure blur synthesis. Extensive experiments demonstrate that DeblurNVS outperforms existing baselines on synthetic motion-blur benchmarks and generalizes to real motion-blurred scenes, producing perceptually sharper and structurally more stable novel views while avoiding costly per-scene optimization. Project page: https://github.com/PKU-YuanGroup/DeblurNVS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce DeblurNVS, a framework for novel view synthesis from sparse motion-blurred images using geometric latent diffusion to restore intermediate geometric representations from the blurred inputs. These restored representations are then combined with target camera information to synthesize sharp RGB novel views. The approach is enabled by constructing a motion-blurred NVS dataset from DL3DV-10K using interpolation-based finite-exposure blur synthesis. The authors report that DeblurNVS outperforms existing baselines on synthetic motion-blur benchmarks, generalizes to real motion-blurred scenes, and produces perceptually sharper and structurally more stable novel views without requiring costly per-scene optimization.
Significance. If the results hold, the work would be significant for the field of novel view synthesis as it tackles the practical challenge of motion blur in input images, which is common in real-world captures. By avoiding per-scene optimization and using a trained model, it could lead to more efficient and scalable NVS methods applicable to degraded inputs.
major comments (2)
- [Abstract] The central claim that the geometric latent diffusion step 'restores the intermediate geometric representations needed for multi-view reasoning, enabling blurred inputs to recover reliable structure and correspondence cues' (abstract) is load-bearing for all downstream synthesis. The interpolation-based finite-exposure blur synthesis used to create the training data from DL3DV-10K may not reproduce real blur statistics such as non-linear trajectories, depth variation, and sensor noise; if the restored latents contain geometric errors, the reported gains in structural stability will not hold.
- [Experiments (implied)] No quantitative results, error bars, ablation studies, or metrics on geometric accuracy (e.g., correspondence error or ray consistency) are referenced. Without such evidence, the attribution of improved sharpness and stability to the geometric restoration step rather than other factors cannot be verified.
minor comments (1)
- The abstract provides a project page link but does not indicate whether code, models, or the constructed dataset will be released to support reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point by point below, clarifying the role of the geometric restoration and the available evidence while noting where revisions are warranted.
read point-by-point responses
-
Referee: [Abstract] The central claim that the geometric latent diffusion step 'restores the intermediate geometric representations needed for multi-view reasoning, enabling blurred inputs to recover reliable structure and correspondence cues' (abstract) is load-bearing for all downstream synthesis. The interpolation-based finite-exposure blur synthesis used to create the training data from DL3DV-10K may not reproduce real blur statistics such as non-linear trajectories, depth variation, and sensor noise; if the restored latents contain geometric errors, the reported gains in structural stability will not hold.
Authors: We acknowledge that interpolation-based blur synthesis is an approximation and does not fully capture real-world effects such as non-linear trajectories or sensor noise. This approach follows common practice in motion deblurring literature for scalable dataset creation. The manuscript demonstrates generalization to real motion-blurred scenes with perceptually sharper and more stable outputs, which provides indirect support for the utility of the restored representations. We will add a dedicated limitations paragraph on the synthetic blur model and include further qualitative analysis on real data to substantiate the structural stability claims. revision: partial
-
Referee: [Experiments (implied)] No quantitative results, error bars, ablation studies, or metrics on geometric accuracy (e.g., correspondence error or ray consistency) are referenced. Without such evidence, the attribution of improved sharpness and stability to the geometric restoration step rather than other factors cannot be verified.
Authors: The manuscript presents quantitative comparisons against baselines on synthetic motion-blur benchmarks using standard image quality metrics, plus qualitative evidence of improved sharpness and stability on both synthetic and real scenes. We agree that direct geometric accuracy metrics and ablations would strengthen attribution to the latent diffusion component. In the revised manuscript we will add error bars, ablation studies isolating the geometric restoration, and new quantitative metrics including correspondence error and ray consistency. revision: yes
Circularity Check
No circularity: empirical training pipeline with independent evaluation
full rationale
The paper describes a supervised generative model (geometric latent diffusion) trained on a synthetically blurred dataset constructed via interpolation-based finite-exposure synthesis from DL3DV-10K. Performance claims rest on empirical comparisons against baselines on held-out synthetic and real scenes, not on any derivation that reduces to fitted parameters renamed as predictions or self-referential definitions. No load-bearing step equates the output to the input by construction; the geometric restoration is learned from data rather than presupposed. This is a standard end-to-end trained CV pipeline whose validity is externally falsifiable via benchmark metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[2]
3d gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, vol. 42, no. 4, July 2023. [Online]. Available: https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[3]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
W. Yu, J. Xing, L. Yuan, W. Hu, X. Li, Z. Huang, X. Gao, T.-T. Wong, Y . Shan, and Y . Tian, “Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis,”arXiv preprint arXiv:2409.02048, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Futuregs: Structured gaussian fields for future-aware dynamic scene modeling,
M. Ding, Z. Wang, J. Wang, T. Han, X. Hu, J. Ding, M. Tan, and Z. Kuang, “Futuregs: Structured gaussian fields for future-aware dynamic scene modeling,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 8322–8331
2025
-
[5]
Sparse4dgs: 4d gaussian splatting for sparse-frame dynamic scene reconstruction,
C. Shi, C. Yang, X. Hu, M. Chen, W. Pan, Y . Yang, J. Ding, Z. Yu, and J. Yu, “Sparse4dgs: 4d gaussian splatting for sparse-frame dynamic scene reconstruction,” inProceedings of the AAAI Conference on Arti- ficial Intelligence, vol. 40, no. 11, 2026, pp. 8933–8941
2026
-
[6]
Drivingforward: Feed-forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input,
Q. Tian, X. Tan, Y . Xie, and L. Ma, “Drivingforward: Feed-forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input,” inProceedings of the AAAI Conference on Ar- tificial Intelligence, vol. 39, no. 7, 2025, pp. 7374–7382
2025
-
[7]
Dggt: Feedforward 4d reconstruction of dynamic driving scenes using unposed images,
X. Chen, Z. Xiong, Y . Chen, G. Li, N. Wang, H. Luo, L. Chen, H. Sun, B. Wang, G. Chenet al., “Dggt: Feedforward 4d reconstruction of dynamic driving scenes using unposed images,”arXiv preprint arXiv:2512.03004, 2025
-
[8]
Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis,
S. Miao, J. Huang, D. Bai, X. Yan, H. Zhou, Y . Wang, B. Liu, A. Geiger, and Y . Liao, “Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11 286–11 296
2025
-
[9]
Radiance fields in xr: A survey on how radiance fields are envisioned and addressed for xr research,
K. Li, M. Masuda, S. Schmidt, and S. Mori, “Radiance fields in xr: A survey on how radiance fields are envisioned and addressed for xr research,”IEEE Transactions on Visualization and Computer Graphics, 2025
2025
-
[10]
S. Huang, L. Chen, P. Zhou, S. Chen, Z. Jiang, Y . Hu, Y . Liao, P. Gao, H. Li, M. Yaoet al., “Enerverse: Envisioning embodied future space for robotics manipulation,”arXiv preprint arXiv:2501.01895, 2025
-
[11]
Deepverse: 4d autoregressive video generation as a world model,
J. Chen, H. Zhu, X. He, Y . Wang, J. Zhou, W. Chang, Y . Zhou, Z. Li, Z. Fu, J. Panget al., “Deepverse: 4d autoregressive video generation as a world model,”arXiv preprint arXiv:2506.01103, 2025
-
[12]
Aether: Geometric-aware unified world modeling,
H. Zhu, Y . Wang, J. Zhou, W. Chang, Y . Zhou, Z. Li, J. Chen, C. Shen, J. Pang, and T. He, “Aether: Geometric-aware unified world modeling,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 8535–8546
2025
-
[13]
Gaussian grouping: Segment and edit anything in 3d scenes,
M. Ye, M. Danelljan, F. Yu, and L. Ke, “Gaussian grouping: Segment and edit anything in 3d scenes,” inEuropean conference on computer vision. Springer, 2024, pp. 162–179
2024
-
[14]
Gaussianeditor: Editing 3d gaussians delicately with text instructions,
J. Wang, J. Fang, X. Zhang, L. Xie, and Q. Tian, “Gaussianeditor: Editing 3d gaussians delicately with text instructions,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 20 902–20 911
2024
-
[15]
C. Shi, M. Chen, Y . Mao, C. Yang, X. Hu, J. Ding, and Z. Yu, “Realm: An mllm-agent framework for open world 3d reasoning segmentation and editing on gaussian splatting,”arXiv preprint arXiv:2510.16410, 2025
-
[16]
Repurposing geometric foundation models for multi-view diffusion,
W. Jang, S. Jeon, J. Han, J. Choi, M. Kwon, S. Kim, S. Xie, and S. Liu, “Repurposing geometric foundation models for multi-view diffusion,” arXiv preprint arXiv:2603.22275, 2026
-
[17]
Deblur-nerf: Neural radiance fields from blurry images,
L. Ma, X. Li, J. Liao, Q. Zhang, X. Wang, J. Wang, and P. V . Sander, “Deblur-nerf: Neural radiance fields from blurry images,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 12 861–12 870
2022
-
[18]
Bad-nerf: Bundle adjusted deblur neural radiance fields,
P. Wang, L. Zhao, R. Ma, and P. Liu, “Bad-nerf: Bundle adjusted deblur neural radiance fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4170–4179
2023
-
[19]
Sharp-nerf: Grid-based fast deblurring neural radiance fields using sharpness prior,
B. Lee, H. Lee, U. Ali, and E. Park, “Sharp-nerf: Grid-based fast deblurring neural radiance fields using sharpness prior,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2024, pp. 3709–3718
2024
-
[20]
Bad-gaussians: Bundle adjusted de- blur gaussian splatting,
L. Zhao, P. Wang, and P. Liu, “Bad-gaussians: Bundle adjusted de- blur gaussian splatting,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 233–250
2024
-
[21]
Bags: Blur agnostic gaussian splatting through multi-scale kernel modeling,
C. Peng, Y . Tang, Y . Zhou, N. Wang, X. Liu, D. Li, and R. Chellappa, “Bags: Blur agnostic gaussian splatting through multi-scale kernel modeling,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 293–310
2024
-
[22]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.- J. Cham, and J. Cai, “Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,” inEuropean conference on computer vision. Springer, 2024, pp. 370–386
2024
-
[23]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,
L. Jiang, Y . Mao, L. Xu, T. Lu, K. Ren, Y . Jin, X. Xu, M. Yu, J. Pang, F. Zhaoet al., “Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,”ACM Transactions on Graphics (TOG), vol. 44, no. 6, pp. 1–16, 2025
2025
-
[24]
Mvsplat360: Feed-forward 360 scene synthesis from sparse views,
Y . Chen, C. Zheng, H. Xu, B. Zhuang, A. Vedaldi, T.-J. Cham, and J. Cai, “Mvsplat360: Feed-forward 360 scene synthesis from sparse views,” in Advances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[25]
Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models,
M. Yu, W. Hu, J. Xing, and Y . Shan, “Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models,” inPro- ceedings of the IEEE/CVF international conference on computer vision, 2025, pp. 100–111
2025
-
[26]
Deep multi-scale convolutional neural network for dynamic scene deblurring,
S. Nah, T. Hyun Kim, and K. Mu Lee, “Deep multi-scale convolutional neural network for dynamic scene deblurring,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3883–3891
2017
-
[27]
Human- aware motion deblurring,
Z. Shen, W. Wang, X. Lu, J. Shen, H. Ling, T. Xu, and L. Shao, “Human- aware motion deblurring,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5572–5581
2019
-
[28]
Real-world blur dataset for learning and benchmarking deblurring algorithms,
J. Rim, H. Lee, J. Won, and S. Cho, “Real-world blur dataset for learning and benchmarking deblurring algorithms,” inProceedings of the European Conference on Computer Vision, 2020, pp. 184–201
2020
-
[29]
Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study,
S. Nah, S. Baik, S. Hong, G. Moon, S. Son, R. Timofte, and K. M. Lee, “Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019
2019
-
[30]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision,
L. Ling, Y . Sheng, Z. Tu, W. Zhao, C. Xin, K. Wan, L. Yu, Q. Guo, Z. Yu, Y . Luet al., “Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 160–22 169
2024
-
[31]
Instant neural graphics primitives with a multiresolution hash encoding,
T. M ¨uller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,”ACM transactions on graphics (TOG), vol. 41, no. 4, pp. 1–15, 2022
2022
-
[32]
Tensorf: Tensorial radiance fields,
A. Chen, Z. Xu, A. Geiger, J. Yu, and H. Su, “Tensorf: Tensorial radiance fields,” inEuropean conference on computer vision. Springer, 2022, pp. 333–350
2022
-
[33]
Mip-nerf: A multiscale representation for anti- aliasing neural radiance fields,
J. T. Barron, B. Mildenhall, M. Tancik, P. Hedman, R. Martin-Brualla, and P. P. Srinivasan, “Mip-nerf: A multiscale representation for anti- aliasing neural radiance fields,” inProceedings of the IEEE/CVF inter- national conference on computer vision, 2021, pp. 5855–5864
2021
-
[34]
Synsin: End-to-end view synthesis from a single image,
O. Wiles, G. Gkioxari, R. Szeliski, and J. Johnson, “Synsin: End-to-end view synthesis from a single image,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7467– 7477
2020
-
[35]
Pixelsynth: Generating a 3d-consistent experience from a single image,
C. Rockwell, D. F. Fouhey, and J. Johnson, “Pixelsynth: Generating a 3d-consistent experience from a single image,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 104–14 113
2021
-
[36]
Bridging implicit and explicit geometric transformation for single-image view synthesis,
B. Park, H. Go, and C. Kim, “Bridging implicit and explicit geometric transformation for single-image view synthesis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 9, pp. 6326– 6340, 2024
2024
-
[37]
Stereo Magnification: Learning View Synthesis using Multiplane Images
T. Zhou, R. Tucker, J. Flynn, G. Fyffe, and N. Snavely, “Stereo magnification: Learning view synthesis using multiplane images,”arXiv preprint arXiv:1805.09817, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[39]
pixelnerf: Neural radiance fields from one or few images,
A. Yu, V . Ye, M. Tancik, and A. Kanazawa, “pixelnerf: Neural radiance fields from one or few images,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4578– 4587
2021
-
[40]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d re- construction,
D. Charatan, S. L. Li, A. Tagliasacchi, and V . Sitzmann, “pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d re- construction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 457–19 467
2024
-
[41]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294– 5306. 11
2025
-
[42]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He, “π 3: Permutation-equivariant visual geometry learning,”arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Depth anything with any prior,
Z. Wang, S. Chen, L. Yang, J. Wang, Z. Zhang, H. Zhao, and Z. Zhao, “Depth anything with any prior,”arXiv preprint arXiv:2505.10565, 2025
-
[44]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
Y . Shen, Z. Zhang, Y . Qu, X. Zheng, J. Ji, S. Zhang, and L. Cao, “Fastvggt: Training-free acceleration of visual geometry transformer,” arXiv preprint arXiv:2509.02560, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[48]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[49]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[50]
Generative novel view synthesis with 3d-aware diffusion models,
E. R. Chan, K. Nagano, M. A. Chan, A. W. Bergman, J. J. Park, A. Levy, M. Aittala, S. De Mello, T. Karras, and G. Wetzstein, “Generative novel view synthesis with 3d-aware diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4217–4229
2023
-
[51]
Zero-1-to-3: Zero-shot one image to 3d object,
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. V on- drick, “Zero-1-to-3: Zero-shot one image to 3d object,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 9298–9309
2023
-
[52]
Zeronvs: Zero-shot 360- degree view synthesis from a single image,
K. Sargent, Z. Li, T. Shah, C. Herrmann, H.-X. Yu, Y . Zhang, E. R. Chan, D. Lagun, L. Fei-Fei, D. Sunet al., “Zeronvs: Zero-shot 360- degree view synthesis from a single image,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9420–9429
2024
-
[53]
Reconfusion: 3d reconstruction with diffusion priors,
R. Wu, B. Mildenhall, P. Henzler, K. Park, R. Gao, D. Watson, P. P. Srinivasan, D. Verbin, J. T. Barron, B. Pooleet al., “Reconfusion: 3d reconstruction with diffusion priors,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 21 551–21 561
2024
-
[54]
Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connec- tions,
X. Mao, C. Shen, and Y .-B. Yang, “Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connec- tions,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[55]
Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,
K. Zhang, W. Zuo, Y . Chen, D. Meng, and L. Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,”IEEE transactions on image processing, vol. 26, no. 7, pp. 3142–3155, 2017
2017
-
[56]
Enhanced deep residual networks for single image super-resolution,
B. Lim, S. Son, H. Kim, S. Nah, and K. Mu Lee, “Enhanced deep residual networks for single image super-resolution,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 136–144
2017
-
[57]
S. Liu, C. Bao, Z. Cui, X. Chu, B. Ren, L. Gu, X. Chen, M. Li, L. Ma, M. V . Condeet al., “Ntire 2026 3d restoration and reconstruction in real-world adverse conditions: Realx3d challenge results,”arXiv preprint arXiv:2604.04135, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
R3evision: A survey on robust rendering, restoration, and enhancement for 3d low-level vision,
W. Kwon, J. Sung, M. Jeon, C. Eom, and J. Oh, “R3evision: A survey on robust rendering, restoration, and enhancement for 3d low-level vision,” arXiv preprint arXiv:2506.16262, 2025
-
[59]
Breaking the vicious cycle: Coherent 3d gaussian splatting from sparse and motion-blurred views,
Z. Xu*, C. Feng*, Y . Li, J. Zhao, J. Yang, W. Yu, L. Yuan, and Y . Tian, “Breaking the vicious cycle: Coherent 3d gaussian splatting from sparse and motion-blurred views,”arXiv preprint arXiv:2512.10369, 2025
-
[60]
Evagaussians: Event stream assisted gaussian splatting from blurry images,
W. Yu*, C. Feng*, J. Li, J. Tang, J. Yang, Z. Tang, M. Cao, X. Jia, Y . Yang, L. Yuanet al., “Evagaussians: Event stream assisted gaussian splatting from blurry images,” inICCV 2025, 2025
2025
-
[61]
Denoisesplat: Feed-forward gaussian splatting for noisy 3d scene reconstruction,
F. Jiang, Z. Li, and Y . Zhang, “Denoisesplat: Feed-forward gaussian splatting for noisy 3d scene reconstruction,” inProceedings of the 2026 International Conference on Human-Computer Interaction, Neural Networks and Deep Learning, 2026, pp. 63–71
2026
-
[62]
Srgs: Super-resolution 3d gaussian splatting,
X. Feng, Y . He, L. Chen, Y . Yang, C. Wang, Y . Chen, Y . Zhong, Z. Kuang, X. Yin, Y . Zhuet al., “Srgs: Super-resolution 3d gaussian splatting,”arXiv preprint arXiv:2404.10318, 2024
-
[63]
Srsplat: Feed-forward super-resolution gaussian splatting from sparse multi-view images,
X. Hu, C. Shi, C. Yang, M. Chen, J. Ding, T. Wei, C. Wei, Z. Yu, and M. Tan, “Srsplat: Feed-forward super-resolution gaussian splatting from sparse multi-view images,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 6, 2026, pp. 4950–4958
2026
-
[64]
Sr3r: Rethinking super-resolution 3d reconstruction with feed-forward gaussian splatting,
X. Feng, X. Wang, T. Zhong, C. Wang, Y . Zhao, T. Xu, Z. Kuang, F. Qin, X. Yin, and Y . Zhu, “Sr3r: Rethinking super-resolution 3d reconstruction with feed-forward gaussian splatting,”arXiv preprint arXiv:2602.24020, 2026
-
[65]
Learning to extract a video sequence from a single motion-blurred image,
M. Jin, G. Meishvili, and P. Favaro, “Learning to extract a video sequence from a single motion-blurred image,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6334–6342
2018
-
[66]
Scale-recurrent network for deep image deblurring,
X. Tao, H. Gao, X. Shen, J. Wang, and J. Jia, “Scale-recurrent network for deep image deblurring,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8174–8182
2018
-
[67]
Deblurgan-v2: De- blurring (orders-of-magnitude) faster and better,
O. Kupyn, T. Martyniuk, J. Wu, and Z. Wang, “Deblurgan-v2: De- blurring (orders-of-magnitude) faster and better,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 8878– 8887
2019
-
[68]
Deep video deblurring for hand-held cameras,
S. Su, M. Delbracio, J. Wang, G. Sapiro, W. Heidrich, and O. Wang, “Deep video deblurring for hand-held cameras,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1279–1288
2017
-
[69]
Cascaded deep video deblurring using temporal sharpness prior,
J. Pan, H. Bai, and J. Tang, “Cascaded deep video deblurring using temporal sharpness prior,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 3043–3051
2020
-
[70]
Dynamic scene deblurring with parameter selective sharing and nested skip connections,
H. Gao, X. Tao, X. Shen, and J. Jia, “Dynamic scene deblurring with parameter selective sharing and nested skip connections,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3848–3856
2019
-
[71]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5728–5739
2022
-
[72]
Deblurdiff: Real-word image deblurring with generative diffusion models,
L. Kong, D. Zou, F. L. Wang, J. Ren, X. Wu, J. Dong, J. Pan et al., “Deblurdiff: Real-word image deblurring with generative diffusion models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[73]
Mvgenmaster: Scaling multi-view generation from any image via 3d priors enhanced diffusion model,
C. Cao, C. Yu, S. Liu, F. Wang, X. Xue, and Y . Fu, “Mvgenmaster: Scaling multi-view generation from any image via 3d priors enhanced diffusion model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6045–6056
2025
-
[74]
Aligned novel view image and geometry synthesis via cross-modal attention instillation,
M.-S. Kwak, J. Kim, S. Yun, D. Han, T. Kim, S. Kim, and J.-H. Kim, “Aligned novel view image and geometry synthesis via cross-modal attention instillation,”arXiv preprint arXiv:2506.11924, 2025
-
[75]
Genwarp: Single image to novel views with semantic-preserving generative warping,
J. Seo, K. Fukuda, T. Shibuya, T. Narihira, N. Murata, S. Hu, C.- H. Lai, S. Kim, and Y . Mitsufuji, “Genwarp: Single image to novel views with semantic-preserving generative warping,”Advances in Neural Information Processing Systems, vol. 37, pp. 80 220–80 243, 2024
2024
-
[76]
Revisiting adaptive convolutions for video frame interpolation,
S. Niklaus, L. Mai, and O. Wang, “Revisiting adaptive convolutions for video frame interpolation,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 1099–1109
2021
-
[77]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[78]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[79]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
2014
-
[80]
Image quality assessment: From error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,”IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.