UR-JEPA: Uniform Rectifiability as a Regularizer for Joint-Embedding Predictive Architectures
Pith reviewed 2026-06-28 17:13 UTC · model grok-4.3
The pith
Targeting uniform rectifiability in JEPA training produces embeddings concentrated on low-dimensional manifolds with comparable accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
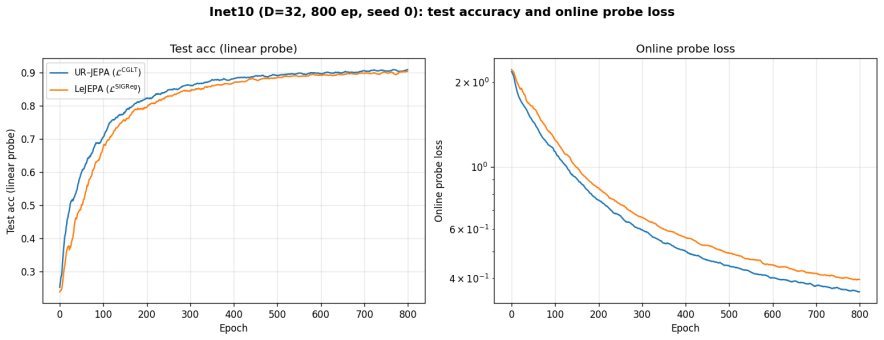
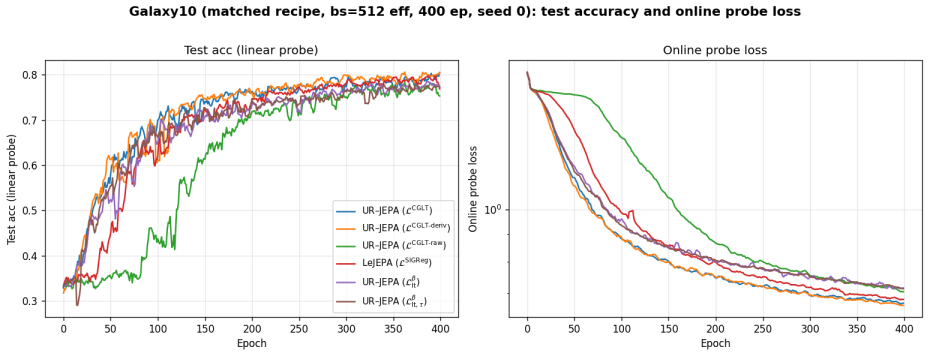
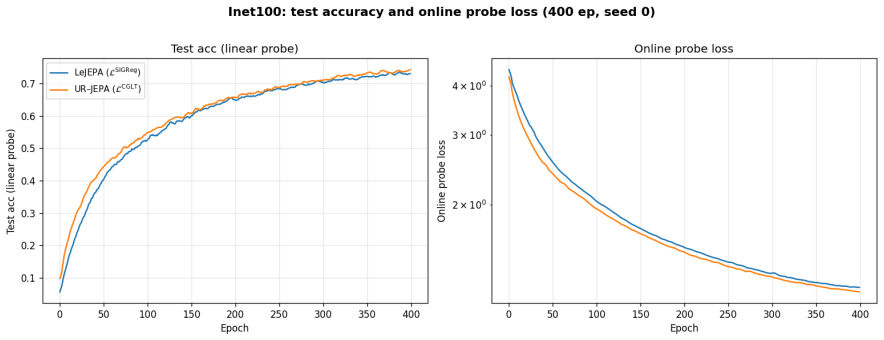
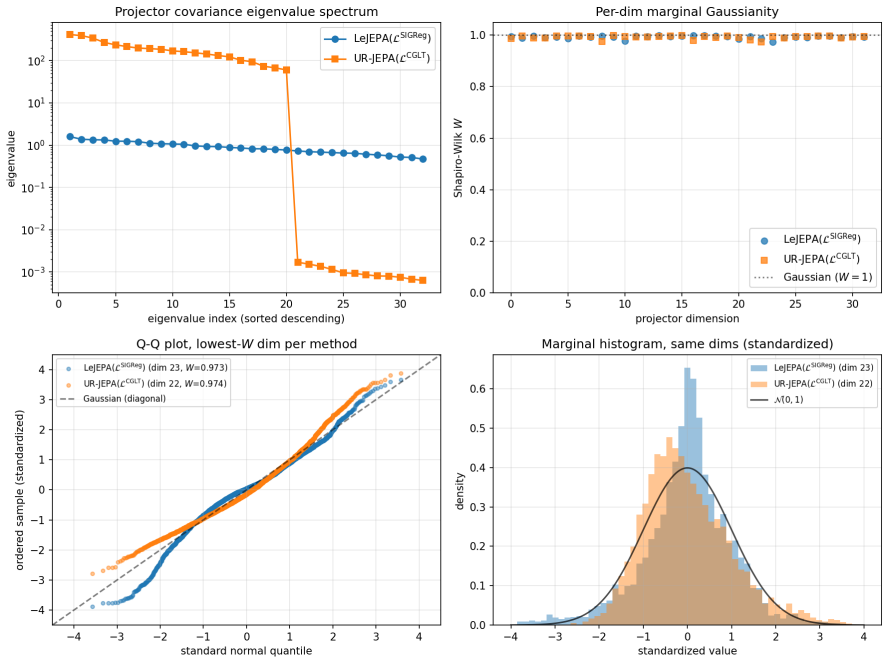
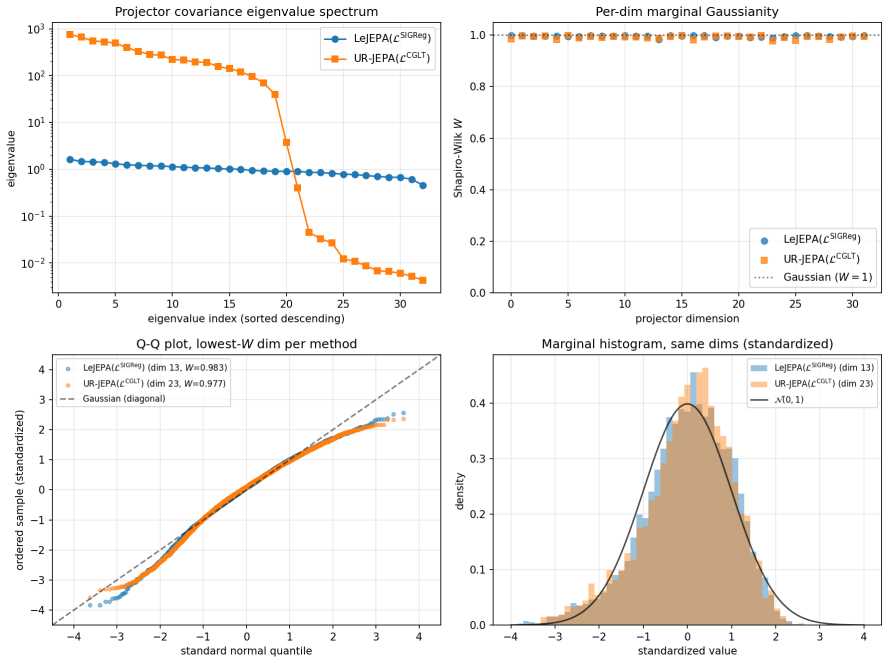
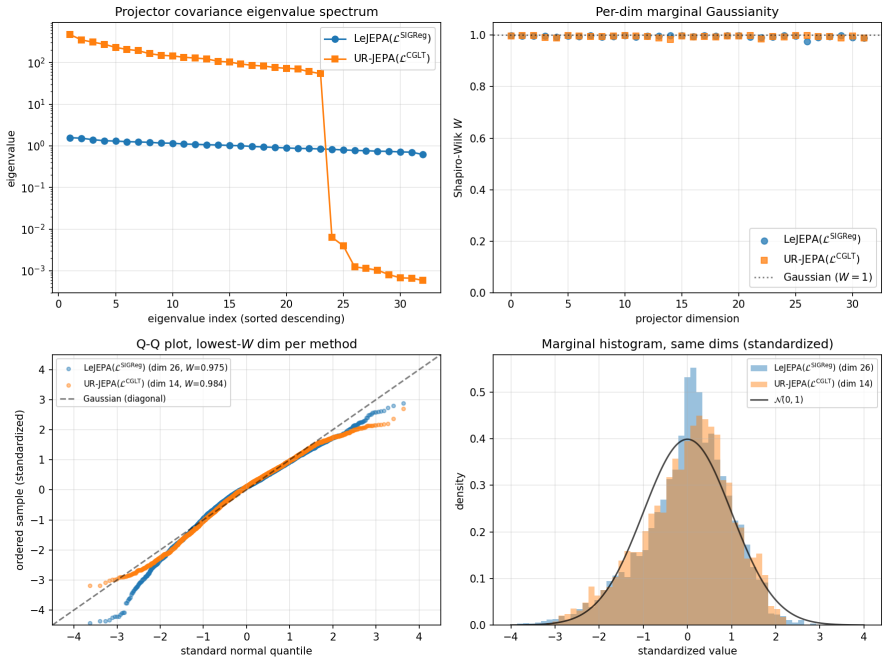
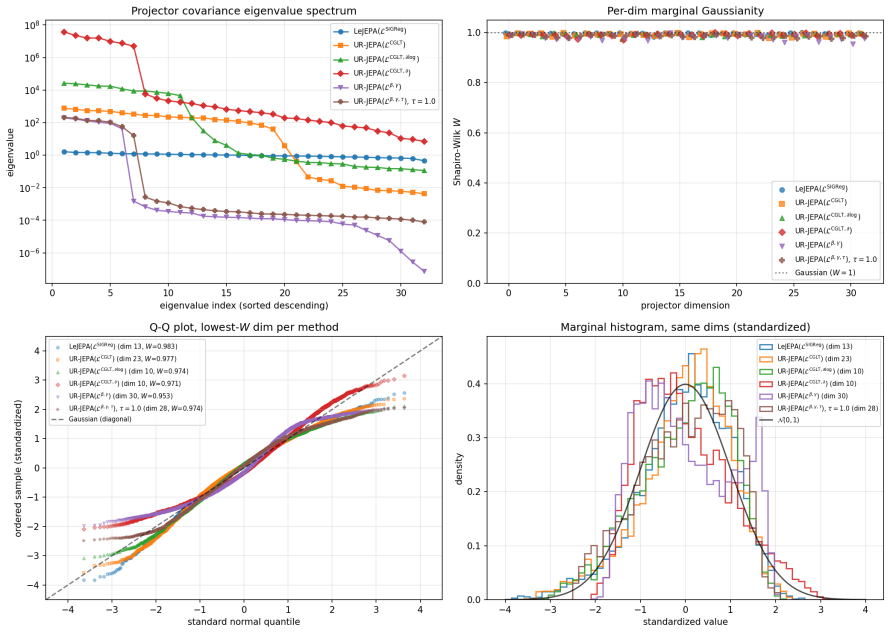
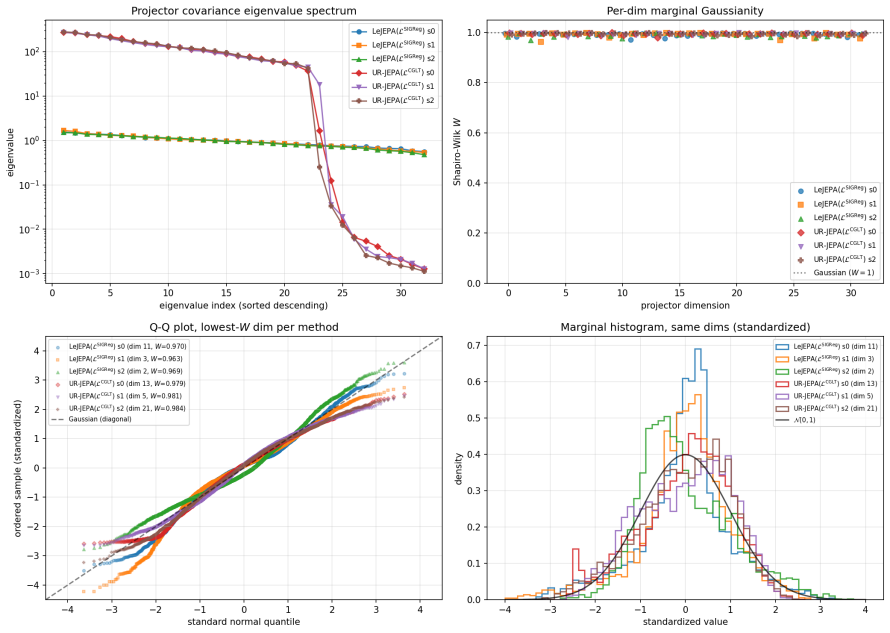
UR-JEPA targets a uniformly n-rectifiable measure of local tangent dimension n at small scales, realized through a Gaussian-kernel smoothed Carleson-type square function L^CGLT, with a complementary Jones β-number formulation. On Inet10, UR-JEPA(L^CGLT) attains 0.9141 ± 0.0014 for a +0.83 pp gain over LeJEPA(L^SIGReg) with ~30% lower seed standard deviation. On matched-recipe Galaxy10 SDSS, a single-seed ImageNet-100 run, and a 3-seed EuroSAT remote-sensing run, the two methods lie in the same peak-accuracy band at convergence, with UR-JEPA retaining its lower-seed-variance signature. The distinction is geometric: UR-JEPA(L^CGLT) produces a global PCA spectrum with a 4 to 5 order-of-magnitud
What carries the argument
Gaussian-kernel smoothed Carleson-type square function L^CGLT that targets a uniformly n-rectifiable measure of local tangent dimension n
If this is right
- UR-JEPA achieves a small accuracy gain on Inet10 with substantially lower variance across seeds.
- The embeddings exhibit a sharp PCA spectrum drop indicating low-dimensional concentration.
- Per-dimension marginals are near-Gaussian for both regularizers as a consequence of the Diaconis-Freedman theorem.
- Competitive performance holds on Galaxy10 SDSS, ImageNet-100, and EuroSAT with smaller backbones possible for remote sensing.
- The two methods produce structurally distinct projected representations at matched accuracy.
Where Pith is reading between the lines
- Uniform rectifiability may provide a more natural target for self-supervised learning when data is assumed to lie on manifolds.
- The reduced seed variance could lead to more reliable training in practice.
- Alternative implementations using Jones β-numbers could be explored for computational efficiency.
- This geometric regularization might apply to other predictive or contrastive learning setups to encourage manifold-like representations.
Load-bearing premise
The PCA spectral drop and variance reduction are caused by the L^CGLT loss enforcing uniform rectifiability rather than by unspecified differences in training procedure, hyperparameters, or data processing.
What would settle it
An experiment that exactly matches the training procedures, hyperparameters, and data processing for both UR-JEPA and LeJEPA and then checks whether the 4-5 order-of-magnitude PCA drop at index 20-25 and the 30% lower seed standard deviation still appear.
Figures
read the original abstract
A central difficulty in training Joint-Embedding Predictive Architectures (JEPAs) is preventing representation collapse. LeJEPA addresses this by enforcing an isotropic Gaussian target on the embeddings via Sketched Isotropic Gaussian Regularization (SIGReg). This target is in tension with the manifold hypothesis, which expects embeddings to concentrate on a low-dimensional subset of the ambient space. We propose \emph{UR-JEPA}, which targets a uniformly $n$-rectifiable measure of local tangent dimension $n$ at small scales, realized through a Gaussian-kernel smoothed Carleson-type square function $\mathcal{L}^{\text{CGLT}}$, with a complementary Jones $\beta$-number formulation. On Inet10, UR-JEPA($\mathcal{L}^{\text{CGLT}}$) attains $0.9141 \pm 0.0014$ for a $+0.83$\,pp gain over LeJEPA($\mathcal{L}^{\text{SIGReg}}$) with $\sim 30\%$ lower seed standard deviation; on matched-recipe Galaxy10~SDSS, a single-seed ImageNet-$100$ run, and a $3$-seed EuroSAT remote-sensing run, the two methods lie in the same peak-accuracy band at convergence, with UR-JEPA retaining its lower-seed-variance signature. On EuroSAT the in-domain pair is competitive at $96.0$ to $96.1\%$ with large remote-sensing foundation-model transfer at a $25\times$ smaller backbone. The distinction is geometric: direct visualization of the projector output distribution shows that on all four datasets UR--JEPA($\mathcal{L}^{\text{CGLT}}$) produces a global PCA spectrum with a $4$ to $5$ order-of-magnitude drop at index $\sim 20$ to $25$ out of $D = 32$, while LeJEPA's spectrum is near-flat (top-to-bottom ratio at most $3.6$). Per-dimension marginals are simultaneously near-Gaussian for both methods (mean Shapiro-Wilk $W \in [0.992, 0.996]$) as a Diaconis-Freedman consequence. At matched accuracy the two regularizers therefore yield structurally distinct projected representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UR-JEPA, which replaces the isotropic Gaussian target of LeJEPA (via SIGReg) with a uniformly n-rectifiable target realized by the Gaussian-kernel smoothed Carleson square function loss L^CGLT (and a complementary Jones beta-number formulation). It reports that UR-JEPA(L^CGLT) achieves a +0.83 pp accuracy gain on Inet10 (0.9141 ± 0.0014) with ~30% lower seed standard deviation, lies in the same accuracy band as LeJEPA on matched-recipe runs of Galaxy10 SDSS, ImageNet-100, and EuroSAT, and produces projector outputs whose global PCA spectrum exhibits a 4-5 order-of-magnitude drop at index ~20-25 (D=32) while LeJEPA spectra remain near-flat; both yield near-Gaussian marginals.
Significance. If the PCA spectral collapse and variance reduction can be isolated to the rectifiability regularizer, the work supplies a geometrically principled alternative to isotropic regularization that aligns with the manifold hypothesis while preserving the Diaconis-Freedman near-Gaussian marginal property. The explicit grounding in Gaussian-smoothed Carleson and Jones beta objects from geometric measure theory is a methodological strength, as is the consistent lower seed variance across four datasets.
major comments (2)
- [Abstract] Abstract: The Inet10 accuracy and variance results are presented without the 'matched-recipe' qualifier that is explicitly attached to the Galaxy10 SDSS, ImageNet-100, and EuroSAT runs. Because the central claim attributes the 4-5 order-of-magnitude PCA drop and ~30% seed-std reduction to L^CGLT enforcing uniform rectifiability, the absence of explicit confirmation that every hyperparameter, augmentation, optimizer schedule, and data pipeline is identical on Inet10 leaves the attribution open to the alternative explanation of uncontrolled procedural differences.
- [Abstract] Abstract (and experimental section): No statistical tests on the seed variances, no ablation removing only the L^CGLT term while holding all other factors fixed, and no verification that the PCA spectra were computed on identically trained models are reported. These omissions are load-bearing for the claim that the observed geometric distinction (top-to-bottom ratio 4-5 orders vs. at most 3.6) is caused by the rectifiability target rather than by other factors.
minor comments (1)
- [Abstract] The notation L^CGLT and L^SIGReg is introduced without an explicit equation reference in the abstract; a pointer to the defining equations would improve readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments regarding clarity and statistical support in our experimental claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The Inet10 accuracy and variance results are presented without the 'matched-recipe' qualifier that is explicitly attached to the Galaxy10 SDSS, ImageNet-100, and EuroSAT runs. Because the central claim attributes the 4-5 order-of-magnitude PCA drop and ~30% seed-std reduction to L^CGLT enforcing uniform rectifiability, the absence of explicit confirmation that every hyperparameter, augmentation, optimizer schedule, and data pipeline is identical on Inet10 leaves the attribution open to the alternative explanation of uncontrolled procedural differences.
Authors: We agree that consistency in qualifiers improves clarity. The Inet10 experiments followed the identical matched-recipe protocol (same hyperparameters, augmentations, optimizer schedule, and data pipeline) as the other datasets, with the sole difference being the regularization term. We will revise the abstract to attach the 'matched-recipe' qualifier to the Inet10 results, thereby making the attribution to the rectifiability target explicit and uniform across all experiments. revision: yes
-
Referee: [Abstract] Abstract (and experimental section): No statistical tests on the seed variances, no ablation removing only the L^CGLT term while holding all other factors fixed, and no verification that the PCA spectra were computed on identically trained models are reported. These omissions are load-bearing for the claim that the observed geometric distinction (top-to-bottom ratio 4-5 orders vs. at most 3.6) is caused by the rectifiability target rather than by other factors.
Authors: We will incorporate formal statistical tests (e.g., Levene's test) on the reported seed variances in the revised experimental section. The direct head-to-head comparison of LeJEPA($\mathcal{L}^{\text{SIGReg}}$) versus UR-JEPA($\mathcal{L}^{\text{CGLT}}$) with every other factor held fixed already functions as the requested ablation isolating the rectifiability regularizer. We will add an explicit verification statement confirming that all PCA spectra were computed on the projector outputs of models trained under these matched conditions. These textual and statistical additions will be included in the revision. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines the core L^CGLT loss directly from standard geometric measure theory primitives (Gaussian-smoothed Carleson square function and Jones beta numbers) applied to projector outputs, without any reduction to fitted parameters, self-referential equations, or load-bearing self-citations. Empirical claims (accuracy gains, PCA spectral drop, variance reduction) are presented as observed outcomes on specific datasets rather than predictions forced by construction from the inputs. No ansatz smuggling, renaming of known results, or uniqueness theorems imported from prior author work appear in the provided text. The central geometric distinction is therefore independent of the reported measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The manifold hypothesis applies to learned embeddings in JEPA models
invented entities (1)
-
L^CGLT regularizer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
R. Balestriero and Y. LeCun,LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics, arXiv:2511.08544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
Revisiting Feature Prediction for Learning Visual Representations from Video
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y. LeCun, M. Assran, and N. Ballas,Re- visiting Feature Prediction for Learning Visual Representations from Video, arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido et al.,V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction, and Planning, arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
- [6]
-
[7]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton,A Simple Framework for Contrastive Learn- ing of Visual Representations, ICML 2020; arXiv:2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [8]
- [9]
-
[10]
X. Chen and K. He,Exploring Simple Siamese Representation Learning, CVPR 2021; arXiv:2011.10566
-
[11]
Emerging Properties in Self-Supervised Vision Transformers
M. Caron, H. Touvron, I. Misra, H. J´ egou, J. Mairal, P. Bojanowski, and A. Joulin,Emerging Properties in Self-Supervised Vision Transformers, ICCV 2021; arXiv:2104.14294
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet et al.,DINOv2: Learning Robust Visual Features without Supervision, TMLR 2023; arXiv:2304.07193. 1https://access-ci.org/ 2https://www.rcac.purdue.edu/anvil 32
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
J. Zbontar, L. Jing, I. Misra, Y. LeCun, and S. Deny,Barlow Twins: Self-Supervised Learning via Redundancy Reduction, ICML 2021; arXiv:2103.03230
-
[14]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
A. Bardes, J. Ponce, and Y. LeCun,VICReg: Variance–Invariance–Covariance Regularization for Self-Supervised Learning, ICLR 2022; arXiv:2105.04906
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
A. Ermolov, A. Siarohin, E. Sangineto, and N. Sebe,Whitening for Self-Supervised Represen- tation Learning, ICML 2021; arXiv:2007.06346
-
[16]
T. Wang and P. Isola,Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere, ICML 2020; arXiv:2005.10242
- [17]
- [18]
- [19]
- [20]
- [21]
-
[22]
A. Ansuini, A. Laio, J. H. Macke, and D. Zoccolan,Intrinsic Dimension of Data Representa- tions in Deep Neural Networks, NeurIPS 2019; arXiv:1905.12784
-
[23]
Facco, M
E. Facco, M. d’Errico, A. Rodriguez, and A. Laio,Estimating the Intrinsic Dimension of Datasets by a Minimal Neighborhood Information, Sci. Rep.7, 12140 (2017)
2017
-
[24]
Square functions and uniform rectifiability
V. Chousionis, J. Garnett, T. Le, and X. Tolsa,Square functions and uniform rectifiability, arXiv:1401.3382, 2014; Trans. Amer. Math. Soc.368(2016), no. 8, 6063–6102
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[25]
P. W. Jones,Rectifiable sets and the traveling salesman problem, Invent. Math.102(1990), no. 1, 1–15
1990
-
[26]
G. Lerman,How to partition a low-dimensional data set into disjoint clusters of different geometric structures, Workshop on Clustering High-Dimensional Data and its Applications, SIAM International Conference on Data Mining, Arlington, VA, 2002.https://www-users. cse.umn.edu/~lerman/reports/geo_clust.pdf
2002
-
[27]
Lerman,Quantifying curvelike structures of measures by usingL 2 Jones quantities, Comm
G. Lerman,Quantifying curvelike structures of measures by usingL 2 Jones quantities, Comm. Pure Appl. Math.56(2003), no. 9, 1294–1365
2003
-
[28]
Tolsa,Characterization ofn-rectifiability in terms of Jones’ square function: Part I, Calc
X. Tolsa,Characterization ofn-rectifiability in terms of Jones’ square function: Part I, Calc. Var. Partial Differential Equations54(2015), no. 4, 3643–3665
2015
-
[29]
Azzam and X
J. Azzam and X. Tolsa,Characterization ofn-rectifiability in terms of Jones’ square function: Part II, Geom. Funct. Anal.25(2015), no. 5, 1371–1412. 33
2015
-
[30]
Martikainen and T
H. Martikainen and T. Orponen,Boundedness of the density-normalized Jones’ square function does not imply1-rectifiability, J. Math. Pures Appl. (9)110(2018), 71–92
2018
-
[31]
Helber, B
P. Helber, B. Bischke, A. Dengel, and D. Borth,EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.12(2019), no. 7, 2217–2226
2019
-
[32]
Corley, C
I. Corley, C. Robinson, A. Ortiz, and J. Lavista Ferres,Revisiting Pre-trained Remote Sensing Model Benchmarks: Resizing and Normalization Matters, CVPR 2024 Workshop on Perception Beyond the Visible Spectrum (PBVS), 2024
2024
-
[33]
David and S
G. David and S. Semmes,Analysis of and on Uniformly Rectifiable Sets, Math. Surveys Monogr. 38, AMS, 1993
1993
-
[34]
Pajot,Analytic Capacity, Rectifiability, Menger Curvature and the Cauchy Integral, Lecture Notes in Math
H. Pajot,Analytic Capacity, Rectifiability, Menger Curvature and the Cauchy Integral, Lecture Notes in Math. 1799, Springer, 2002
2002
-
[35]
Tolsa,Analytic Capacity, the Cauchy Transform, and Non-homogeneous Calder´ on– Zygmund Theory, Progress in Math
X. Tolsa,Analytic Capacity, the Cauchy Transform, and Non-homogeneous Calder´ on– Zygmund Theory, Progress in Math. 307, Birkh¨ auser, 2014
2014
-
[36]
Le Cam,An approximation theorem for the Poisson binomial distribution, Pacific J
L. Le Cam,An approximation theorem for the Poisson binomial distribution, Pacific J. Math. 10(1960), 1181–1197
1960
-
[37]
Davis and W
C. Davis and W. M. Kahan,The rotation of eigenvectors by a perturbation. III, SIAM J. Numer. Anal.7(1970), 1–46
1970
-
[38]
Y. Yu, T. Wang, and R. J. Samworth,A useful variant of the Davis–Kahan theorem for statisticians, Biometrika102(2015), no. 2, 315–323
2015
-
[39]
Diaconis and D
P. Diaconis and D. Freedman,Asymptotics of graphical projection pursuit, Ann. Statist.12 (1984), no. 3, 793–815
1984
-
[40]
S. S. Shapiro and M. B. Wilk,An analysis of variance test for normality (complete samples), Biometrika52(1965), no. 3/4, 591–611
1965
-
[41]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei,ImageNet: A Large-Scale Hier- archical Image Database, CVPR 2009
2009
-
[42]
Howard,Imagenette: A smaller subset of 10 easily classified classes from ImageNet, GitHub, 2019.https://github.com/fastai/imagenette
J. Howard,Imagenette: A smaller subset of 10 easily classified classes from ImageNet, GitHub, 2019.https://github.com/fastai/imagenette
2019
- [43]
-
[44]
H. W. Leung and J. Bovy,Galaxy10 SDSS Dataset, astroNN documentation, 2018.https: //astronn.readthedocs.io/en/latest/galaxy10sdss.html
2018
-
[45]
C. J. Lintott, K. Schawinski, A. Slosar, K. Land, S. Bamford, D. Thomas, M. J. Raddick, R. C. Nichol, A. Szalay, D. Andreescu, P. Murray, and J. Vandenberg,Galaxy Zoo: morphologies derived from visual inspection of galaxies from the Sloan Digital Sky Survey, Mon. Not. R. Astron. Soc.389(2008), no. 3, 1179–1189. 34
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.