Before Fusion, Ask What to Keep: Contextual Calibration of Multimodal Signals
Pith reviewed 2026-06-28 15:10 UTC · model grok-4.3
The pith
A calibration module adjusts each modality's features before fusion by extracting summary-level support and conflict cues to modulate instance and dimension responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
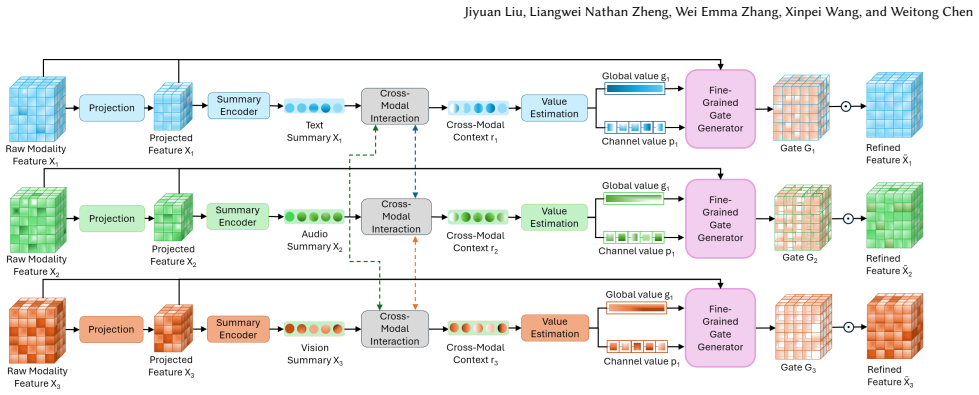
We develop a compact calibration module that compares each modality with the others at the summary level, extracts cues of cross-source support and conflict, and converts these cues into instance-wise and dimension-wise modulation signals. The calibration is applied to the original modality features rather than to already fused representations, enabling the model to suppress misleading components, preserve weak but useful evidence, and emphasize responses that are better supported by the current multimodal context. The module is designed as a plug-in component and can be attached to different fusion backbones without changing their prediction heads.
What carries the argument
The pre-fusion calibration module that extracts cross-modal support and conflict cues at the summary level and converts them into modulation signals applied to the original features.
If this is right
- The calibration improves performance under both sequence-based and convolutional fusion settings.
- Gains appear across sentiment understanding, action recognition, audio-visual event detection, and audio-visual emotion classification.
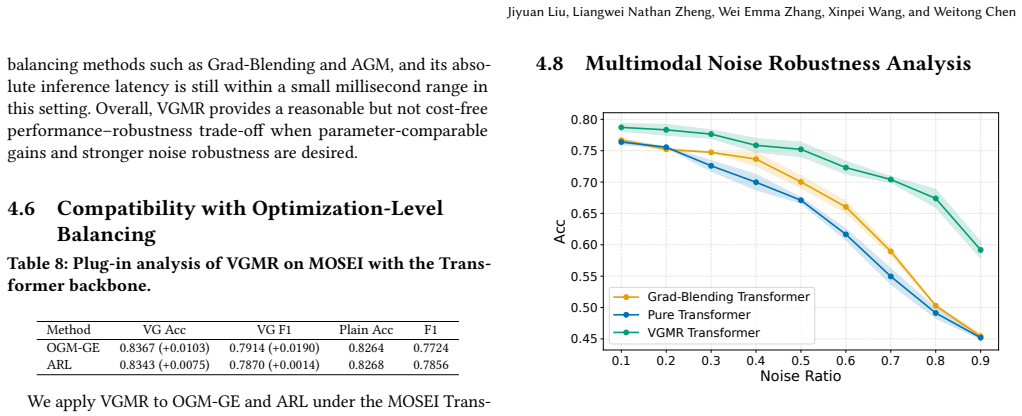
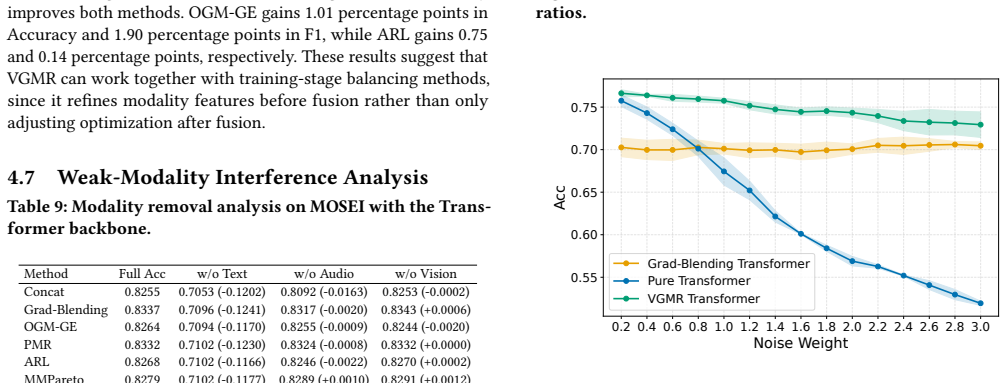
- The approach reduces interference from unreliable modalities when tested with modality removal and synthetic corruption.
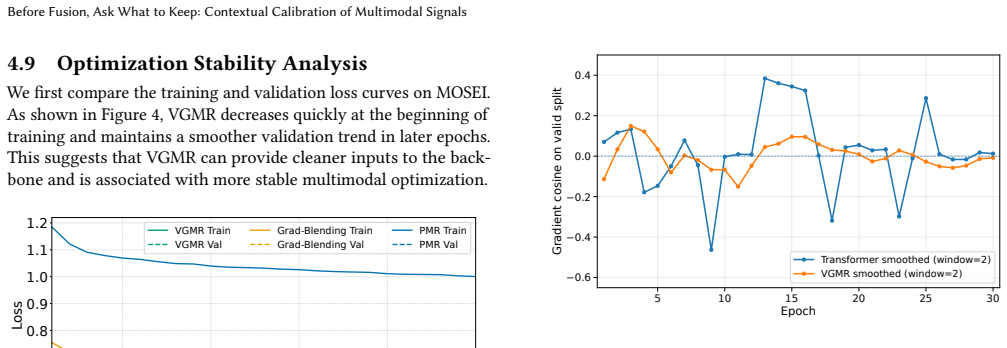
- Training dynamics become more stable after calibration is added.
- Feature visualizations show that modulation emphasizes responses supported by the multimodal context.
Where Pith is reading between the lines
- Pre-fusion modulation may prove more practical than redesigning fusion layers when new modalities are added.
- The summary-level comparison could be extended to handle more than three modalities if the cue extraction scales linearly.
- One could test whether the generated modulation signals can also serve as dynamic weights for modality dropout during inference.
- Localized conflicts inside long sequences might still escape detection if only global summaries are compared.
Load-bearing premise
Summary-level comparisons between modalities produce reliable cues of support and conflict that can be turned into effective modulation signals for the detailed original features.
What would settle it
If inserting the calibration module before fusion produces no accuracy gain or a drop on the five reported benchmarks, particularly when one modality is removed or corrupted, the benefit of pre-combination calibration would not hold.
Figures

read the original abstract
Multimodal systems often benefit from combining information across language, sound, and visual streams, but this benefit is not guaranteed. A modality that is useful for one input may become distracting for another, and local feature responses within the same modality can disagree with evidence from other sources. This work investigates how to adjust multimodal representations before they are merged by a downstream predictor. We develop a compact calibration module that compares each modality with the others at the summary level, extracts cues of cross-source support and conflict, and converts these cues into instance-wise and dimension-wise modulation signals. The calibration is applied to the original modality features rather than to already fused representations, enabling the model to suppress misleading components, preserve weak but useful evidence, and emphasize responses that are better supported by the current multimodal context. The module is designed as a plug-in component and can be attached to different fusion backbones without changing their prediction heads. Across five benchmarks covering sentiment understanding, action recognition, audio-visual event detection, and audio-visual emotion classification, the proposed pre-combination calibration strategy improves performance under both sequence-based and convolutional fusion settings. Additional analyses under modality removal, synthetic corruption, training dynamics, and feature-level visualization show that calibrating signals before fusion can reduce interference from unreliable modalities and produce more stable multimodal optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a plug-in calibration module for multimodal fusion that operates before combination: it compares modalities at the summary level (pooled or CLS tokens) to extract cross-modal support/conflict cues, then generates instance- and dimension-wise modulation signals applied directly to the original modality features. The module is attached to sequence-based or convolutional fusion backbones without altering their predictors. The central claim is that this pre-fusion calibration improves performance across five benchmarks (sentiment understanding, action recognition, audio-visual event detection, audio-visual emotion classification) by suppressing unreliable components and reducing interference, with supporting analyses on modality removal, synthetic corruption, training dynamics, and feature visualizations.
Significance. If the empirical gains hold under the reported conditions, the work offers a lightweight, backbone-agnostic way to mitigate modality interference in multimodal systems, which is a recurring practical issue. The plug-in design and the focus on pre-fusion modulation rather than post-fusion adjustment are conceptually clean; the additional diagnostic experiments (corruption, removal) provide some mechanistic insight beyond aggregate accuracy.
major comments (2)
- [§3] §3 (Calibration Module): The core assumption that summary-level (pooled/CLS) comparisons suffice to produce reliable instance- and dimension-wise modulation for the raw features is load-bearing for all reported gains. For modalities with spatially or temporally heterogeneous responses (video frames, audio spectrograms), global summaries can average away local support/conflict signals that the downstream predictor would otherwise use; the design provides no recovery mechanism for this lost granularity. This directly engages the weakest link in the performance claims under both sequence and convolutional fusion settings.
- [Experimental section] Experimental section (results tables): The abstract and introduction assert consistent improvements across five benchmarks, yet no quantitative deltas, standard deviations, or per-backbone breakdowns are referenced in the provided description. Without these numbers and controls (e.g., comparison against simple per-modality gating baselines), it is impossible to assess whether the observed gains exceed what could be obtained by cheaper modulation schemes or whether they are driven by particular datasets.
minor comments (1)
- [§3] Notation for the modulation signals (instance-wise vs. dimension-wise) should be introduced with explicit equations early in §3 to avoid ambiguity when reading the implementation details.
Simulated Author's Rebuttal
Thank you for the constructive review and for highlighting key aspects of the calibration module and experimental reporting. We address each major comment below with clarifications drawn from the manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§3] §3 (Calibration Module): The core assumption that summary-level (pooled/CLS) comparisons suffice to produce reliable instance- and dimension-wise modulation for the raw features is load-bearing for all reported gains. For modalities with spatially or temporally heterogeneous responses (video frames, audio spectrograms), global summaries can average away local support/conflict signals that the downstream predictor would otherwise use; the design provides no recovery mechanism for this lost granularity. This directly engages the weakest link in the performance claims under both sequence and convolutional fusion settings.
Authors: We acknowledge that relying on summary-level (pooled or CLS) comparisons is a deliberate design choice that prioritizes efficiency and global cross-modal context over per-token granularity. The module generates modulation signals from these summaries and applies them to the original features, leaving local spatial/temporal details intact for the downstream backbone. Experiments on video (action recognition) and audio-visual tasks show performance gains and reduced interference under both sequence and convolutional fusion, with supporting visualizations and corruption analyses indicating that the global cues are sufficient to suppress unreliable components. We agree this is a potential limitation for highly heterogeneous inputs and will add an explicit limitations paragraph plus an ablation on summary-level versus finer-grained calibration in the revision. revision: partial
-
Referee: [Experimental section] Experimental section (results tables): The abstract and introduction assert consistent improvements across five benchmarks, yet no quantitative deltas, standard deviations, or per-backbone breakdowns are referenced in the provided description. Without these numbers and controls (e.g., comparison against simple per-modality gating baselines), it is impossible to assess whether the observed gains exceed what could be obtained by cheaper modulation schemes or whether they are driven by particular datasets.
Authors: The full manuscript (Section 4 and associated tables) reports mean performance deltas, standard deviations across runs, per-backbone breakdowns for sequence and convolutional settings, and direct comparisons against multiple baselines including per-modality gating and other modulation schemes. Gains are shown consistently across all five benchmarks with controls for modality removal and synthetic corruption. We will revise the abstract and introduction to explicitly cite these quantitative results and table references for clarity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new pre-fusion calibration module that extracts support/conflict cues from summary representations and applies instance- and dimension-wise modulation to raw modality features. This module is explicitly designed as a plug-in independent of the downstream fusion backbones (sequence-based or convolutional), with no equations or claims that reduce by construction to fitted inputs, self-citations, or renamed known results. Performance improvements are reported on five external benchmarks under modality removal and corruption analyses, confirming the derivation chain remains self-contained against external validation rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CREMA -D: Crowd -sourced emotional multimodal actors dataset,
Houwei Cao, David G. Cooper, Michael K. Keutmann, Ruben C. Gur, Ani Nenkova, and Ragini Verma. 2014. CREMA-D: Crowd-Sourced Emotional Multimodal Actors Dataset.IEEE Transactions on Affective Computing5, 4 (2014), 377–390. doi:10.1109/TAFFC.2014.2336244
-
[2]
Yunfeng Fan, Wenchao Xu, Haozhao Wang, Junxiao Wang, and Song Guo. 2023. PMR: Prototypical Modal Rebalance for Multimodal Learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20029– 20038
2023
-
[3]
Wei Han, Hui Chen, and Soujanya Poria. 2021. Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 9180–9192
2021
- [4]
-
[5]
Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. 2020. MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis. InProceedings of the 28th ACM International Conference on Multimedia. 1122–1131
2020
-
[6]
Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7132–7141
2018
-
[7]
Hong Li, Xingyu Li, Pengbo Hu, Yinuo Lei, Chunxiao Li, and Yi Zhou. 2023. Boosting Multi-Modal Model Performance with Adaptive Gradient Modulation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22157–22167
2023
-
[8]
González
John Edison Arevalo Ovalle, Thamar Solorio, Manuel Montes y Gómez, and Fabio A. González. 2017. Gated Multimodal Units for Information Fusion. InPro- ceedings of the 5th International Conference on Learning Representations, Workshop Track
2017
-
[9]
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. 2022. Balanced Multimodal Learning via On-the-fly Gradient Modulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8228–8237
2022
-
[10]
Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Mohammed E
Wasifur Rahman, Md. Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Mohammed E. Hoque. 2020. Inte- grating Multimodal Information in Large Pretrained Transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2359– 2369
2020
-
[11]
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. 2012. UCF101: A Dataset of 101 Human Actions Classes From Videos in the Wild.CoRR abs/1212.0402 (2012). arXiv:1212.0402
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[12]
Yibo Sun, Weitong Chen, and Zhe Sun. 2025. Multi-modal Learning Methods in Medical Imaging Area: A Survey.Digital Signal Processing167 (2025), 105441
2025
-
[13]
Xingyu Tan, Xiaoyang Wang, Qing Liu, Xiwei Xu, Xin Yuan, Liming Zhu, and Wenjie Zhang. 2026. MemoTime: Memory-Augmented Temporal Knowledge Graph Enhanced Large Language Model Reasoning. InProceedings of the ACM Web Conference 2026. 4220–4231
2026
- [14]
-
[15]
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chenliang Xu. 2018. Audio- Visual Event Localization in Unconstrained Videos. InProceedings of the European Conference on Computer Vision. 252–268
2018
-
[16]
Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J. Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. Multimodal Transformer for Un- aligned Multimodal Language Sequences. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 6558–6569
2019
-
[17]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30. 5998–6008
2017
-
[18]
Di Wang, Xutong Guo, Yumin Tian, Jinhui Liu, Lihuo He, and Xuemei Luo
-
[19]
TETFN: A Text Enhanced Transformer Fusion Network for Multimodal Sentiment Analysis.Pattern Recognition136 (2023), 109259
2023
-
[20]
Weiyao Wang, Du Tran, and Matt Feiszli. 2020. What Makes Training Multi- Modal Classification Networks Hard?. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12692–12702
2020
- [21]
-
[22]
Yake Wei and Di Hu. 2024. MMPareto: Boosting Multimodal Learning with Innocent Unimodal Assistance. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 52559–52572
2024
-
[23]
Yake Wei, Siwei Li, Ruoxuan Feng, and Di Hu. 2024. Diagnosing and Re-learning for Balanced Multimodal Learning. InProceedings of the European Conference on Computer Vision. Springer Nature Switzerland, 71–86
2024
-
[24]
Nonnegative Decomposition of Multivariate Information
Paul L. Williams and Randall D. Beer. 2010. Nonnegative Decomposition of Multivariate Information.CoRRabs/1004.2515 (2010)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
Wenmeng Yu, Hua Xu, Ziqi Yuan, and Jiele Wu. 2021. Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for Multimodal Senti- ment Analysis. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 10790–10797
2021
-
[26]
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 1103–1114
2017
-
[27]
Amir Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2018. Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics. 2236–2246
2018
-
[28]
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. 2016. MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos.CoRRabs/1606.06259 (2016). arXiv:1606.06259
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
Zian Zhai, Fan Li, Xingyu Tan, Xiaoyang Wang, and Wenjie Zhang. 2025. Graph is a Natural Regularization: Revisiting Vector Quantization for Graph Represen- tation Learning.CoRRabs/2508.06588 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Abul Bashar
Duoyi Zhang, Richi Nayak, and Md. Abul Bashar. 2024. Pre-gating and Contextual Attention Gate: A New Fusion Method for Multi-modal Data Tasks.Neural Networks179 (2024), 106553
2024
-
[31]
Xiaohui Zhang, Jaehong Yoon, Mohit Bansal, and Huaxiu Yao. 2024. Multimodal Representation Learning by Alternating Unimodal Adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 27446– 27456
2024
-
[32]
Liangwei Nathan Zheng, Wei Emma Zhang, Mingyu Guo, Miao Xu, Olaf Maennel, and Weitong Chen. 2025. Rethinking Gating Mechanism in Sparse MoE: Handling Arbitrary Modality Inputs with Confidence-Guided Gate.CoRRabs/2505.19525 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Heqing Zou, Meng Shen, Chen Chen, Yuchen Hu, Deepu Rajan, and Eng Siong Chng. 2023. UniS-MMC: Multimodal Classification via Unimodality-Supervised Multimodal Contrastive Learning. InFindings of the Association for Computational Linguistics: ACL 2023. 659–672
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.