Rethinking Gating Mechanism in Sparse MoE: Handling Arbitrary Modality Inputs with Confidence-Guided Gate
Pith reviewed 2026-05-19 12:45 UTC · model grok-4.3
The pith
By detaching softmax routing scores to ground-truth confidence, a new gate in sparse MoE models prevents expert collapse when modalities are missing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
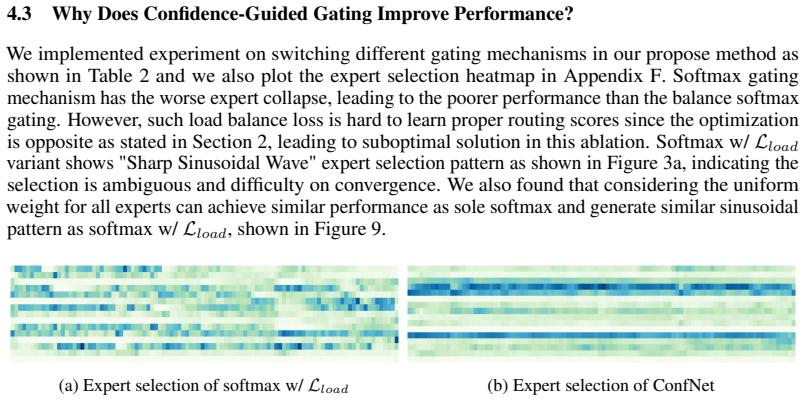
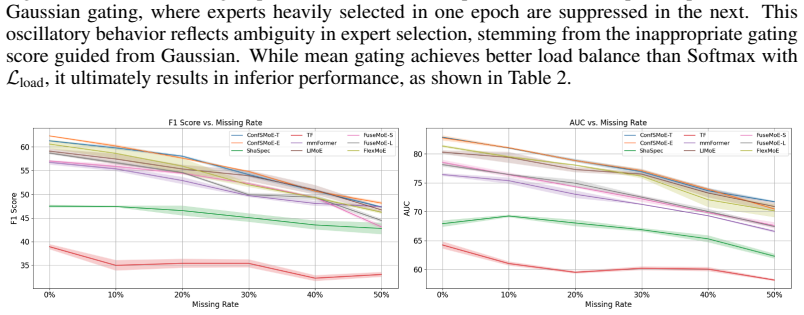
The authors establish that expert collapse arises because standard softmax routing does not tie selection strength to actual task performance against ground truth; detaching the score into an explicit task-confidence value relieves the collapse. They show this holds for the proposed gate and also aligns with Gaussian and Laplacian alternatives. The full ConfSMoE system pairs the gate with a two-stage imputation module that leverages expert opinions to reconstruct missing modalities, and experiments on four real-world datasets under three missing-data regimes confirm improved resistance to incompleteness.
What carries the argument
The confidence-guided gate, which converts the usual softmax routing score into a separate task confidence score measured against ground-truth signals.
If this is right
- SMoE architectures can now accept arbitrary combinations of present and missing modalities through the imputation stage.
- Expert collapse can be mitigated without any auxiliary load-balance loss term.
- The same collapse insight and relief apply to Gaussian and Laplacian gating functions as well.
- Performance remains stable across four real-world datasets and three distinct missing-modality experiment protocols.
- Generalization improves because routing decisions become more directly tied to task correctness rather than raw activation strength.
Where Pith is reading between the lines
- The detachment idea could be ported to other sparse routing schemes that currently rely on softmax or similar probabilities.
- Large-scale multimodal training runs might see lower compute waste once collapse is reduced without extra loss terms.
- Sensor-fusion tasks in autonomous systems could adopt the imputation-plus-gate pattern to cope with intermittent data loss.
- Similar confidence-based adjustments might help address other forms of expert under-utilization in non-MoE architectures.
Load-bearing premise
The two-stage imputation module can reliably reconstruct missing modality values from the opinions of the remaining experts.
What would settle it
A controlled test on a dataset with known missing modalities where the imputation produces clearly inaccurate reconstructions yet the new gate still shows lower collapse and better accuracy than baselines.
Figures










read the original abstract
Effectively managing missing modalities is a fundamental challenge in real-world multimodal learning scenarios, where data incompleteness often results from systematic collection errors or sensor failures. Sparse Mixture-of-Experts (SMoE) architectures have the potential to naturally handle multimodal data, with individual experts specializing in different modalities. However, existing SMoE approach often lacks proper ability to handle missing modality, leading to performance degradation and poor generalization in real-world applications. We propose ConfSMoE to introduce a two-stage imputation module to handle the missing modality problem for the SMoE architecture by taking the opinion of experts and reveal the insight of expert collapse from theoretical analysis with strong empirical evidence. Inspired by our theoretical analysis, ConfSMoE propose a novel expert gating mechanism by detaching the softmax routing score to task confidence score w.r.t ground truth signal. This naturally relieves expert collapse without introducing additional load balance loss function. We show that the insights of expert collapse aligns with other gating mechanism such as Gaussian and Laplacian gate. The proposed method is evaluated on four different real world dataset with three distinct experiment settings to conduct comprehensive analysis of ConfSMoE on resistance to missing modality and the impacts of proposed gating mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ConfSMoE, a sparse Mixture-of-Experts architecture for multimodal learning with missing modalities. It introduces a two-stage imputation module that uses expert opinions to fill missing inputs and a novel gating mechanism that detaches the softmax routing score to a task confidence score derived from the ground-truth signal. This is motivated by a theoretical analysis of expert collapse under standard softmax routing and is claimed to relieve collapse without any additional load-balance loss. The approach is evaluated on four real-world datasets under three experimental settings for missing-modality resistance.
Significance. If the central claims are validated, the work could provide a practical route to robust multimodal MoE models that avoids extra regularization terms while handling arbitrary missing inputs. The reported alignment of collapse insights with Gaussian and Laplacian gates offers a potentially reusable perspective on gating design, and the multi-dataset, multi-setting evaluation supplies useful empirical grounding for real-world applicability.
major comments (3)
- The central claim that detaching the routing score to a ground-truth confidence score relieves expert collapse rests on the theoretical analysis, yet the manuscript provides no explicit fixed-point or stability derivation that incorporates the noise introduced by the two-stage imputation module (see the theoretical analysis and method sections). Without this, the justification for generalization across the three experiment settings remains incomplete.
- The empirical evaluation combines the imputation module and the proposed gate in the same forward pass, so measured reductions in collapse cannot be isolated to the gating change alone. An ablation that disables the new gate while retaining the imputation stage (or vice versa) is needed to support the claim that the gate itself is responsible for collapse relief (Experiments section).
- The task confidence score is defined with respect to the ground-truth signal, but the manuscript does not specify how this score is obtained or approximated when labels are noisy, partially missing, or unavailable at inference time, which directly affects the practical scope of the proposed mechanism.
minor comments (2)
- The abstract states that the insights 'align with' Gaussian and Laplacian gates; a brief equation or table comparing the fixed points or collapse conditions would make this alignment concrete rather than descriptive.
- Exact formulas for the confidence score computation and its scaling/threshold parameters (listed as free parameters in the analysis) should be given explicitly, including any post-hoc choices that affect reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing our responses and indicating the planned revisions.
read point-by-point responses
-
Referee: The central claim that detaching the routing score to a ground-truth confidence score relieves expert collapse rests on the theoretical analysis, yet the manuscript provides no explicit fixed-point or stability derivation that incorporates the noise introduced by the two-stage imputation module (see the theoretical analysis and method sections). Without this, the justification for generalization across the three experiment settings remains incomplete.
Authors: We appreciate this observation on the scope of our theoretical analysis. The fixed-point derivation in the theoretical analysis section establishes collapse under standard softmax routing for clean inputs by showing that the routing probabilities converge to a single expert regardless of modality. The two-stage imputation module operates upstream to estimate missing modalities via expert opinions before gating is applied. While imputation noise is present, the proposed detachment aligns routing scores with task confidence rather than raw (potentially noisy) features, which we argue preserves the collapse-relief property. To strengthen the justification, we will revise the theoretical analysis section to include a qualitative discussion of noise propagation through the detached confidence score and its impact on stability. revision: yes
-
Referee: The empirical evaluation combines the imputation module and the proposed gate in the same forward pass, so measured reductions in collapse cannot be isolated to the gating change alone. An ablation that disables the new gate while retaining the imputation stage (or vice versa) is needed to support the claim that the gate itself is responsible for collapse relief (Experiments section).
Authors: We agree that isolating the gating mechanism's contribution is essential to support the central claim. The Experiments section reports results for the complete ConfSMoE pipeline across the four datasets and three missing-modality settings. During development we performed internal checks, but these were not presented clearly. In the revised manuscript we will add a dedicated ablation subsection that evaluates (i) the imputation module paired with standard softmax gating and (ii) the confidence-guided gate on complete-modality inputs (where imputation is not required). Collapse will be quantified using expert utilization entropy and selection variance to demonstrate the gate's independent effect. revision: yes
-
Referee: The task confidence score is defined with respect to the ground-truth signal, but the manuscript does not specify how this score is obtained or approximated when labels are noisy, partially missing, or unavailable at inference time, which directly affects the practical scope of the proposed mechanism.
Authors: We acknowledge that the manuscript should more explicitly address the computation and applicability of the task confidence score. During training the score is computed directly from ground-truth labels as described in the method. At inference we approximate it via a jointly trained lightweight confidence head that takes the imputed features and model predictions as input. For noisy or partially missing labels we currently assume clean supervision; this is a limitation of the present evaluation. We will clarify the inference-time procedure in the revised method section and add a short discussion of robustness considerations, including potential use of label smoothing or uncertainty-aware training as future extensions. revision: partial
Circularity Check
Theoretical motivation for detached confidence gate is internally derived but does not reduce the reported gains to a fit or self-citation by construction
full rationale
The paper presents a theoretical analysis of expert collapse under standard softmax routing, then proposes detaching the routing score to a ground-truth confidence score as a direct response. This chain is self-contained within the manuscript's own derivations and does not rely on load-bearing self-citations or fitted parameters renamed as predictions. The two-stage imputation module is described as operating alongside the new gate, but the manuscript does not equate the collapse relief to the imputation step by definition; empirical results across datasets are presented as separate validation. No equation is shown to be equivalent to its input by algebraic reduction or by renaming a known pattern. Minor self-reference to the authors' collapse analysis exists but is not the sole justification for the performance claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- task confidence score threshold or scaling
axioms (1)
- domain assumption Standard SMoE gating leads to expert collapse when modalities are missing
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Jacobian of softmax ... Jload = [1/H(g)² (log(g)+1)⊤] · (diag(g)−gg⊤) ... opposite gradient direction to softmax router
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
detaching the softmax routing score to task confidence score w.r.t ground truth signal ... relieves expert collapse without introducing additional load balance loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Publicly Available Clinical BERT Embeddings
Emily Alsentzer, John R Murphy, Willie Boag, Wei-Hung Weng, Di Jin, Tristan Naumann, and Matthew McDermott. Publicly available clinical bert embeddings. arXiv preprint arXiv:1904.03323, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[2]
Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph
AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. In Iryna Gurevych and Yusuke Miyao, editors, Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pag...
-
[3]
Multimodal machine learning: A survey and taxonomy
Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal machine learning: A survey and taxonomy. IEEE transactions on pattern analysis and machine intelligence, 41(2):423–443, 2018
work page 2018
-
[4]
Multiple kernel learning for visual object recognition: A review
Serhat S Bucak, Rong Jin, and Anil K Jain. Multiple kernel learning for visual object recognition: A review. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(7):1354–1369, 2013
work page 2013
-
[5]
Mixtures of experts for audio-visual learning
Ying Cheng, Yang Li, Junjie He, and Rui Feng. Mixtures of experts for audio-visual learning. Advances in Neural Information Processing Systems, 37:219–243, 2024
work page 2024
-
[6]
On the representation collapse of sparse mixture of experts
Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, et al. On the representation collapse of sparse mixture of experts. Advances in Neural Information Processing Systems, 35:34600–34613, 2022
work page 2022
-
[7]
Torchxrayvision: A library of chest x-ray datasets and models
Joseph Paul Cohen, Joseph D Viviano, Paul Bertin, Paul Morrison, Parsa Torabian, Matteo Guarrera, Matthew P Lungren, Akshay Chaudhari, Rupert Brooks, Mohammad Hashir, et al. Torchxrayvision: A library of chest x-ray datasets and models. In International Conference on Medical Imaging with Deep Learning, pages 231–249. PMLR, 2022
work page 2022
-
[8]
Semi-supervised deep generative modelling of incomplete multi-modality emotional data
Changde Du, Changying Du, Hao Wang, Jinpeng Li, Wei-Long Zheng, Bao-Liang Lu, and Huiguang He. Semi-supervised deep generative modelling of incomplete multi-modality emotional data. In Proceedings of the 26th ACM international conference on Multimedia, pages 108–116, 2018
work page 2018
-
[9]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022
work page 2022
-
[10]
On the Properties of the Softmax Function with Application in Game Theory and Reinforcement Learning
Bolin Gao and Lacra Pavel. On the properties of the softmax function with application in game theory and reinforcement learning. arXiv preprint arXiv:1704.00805, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Deep multimodal representation learning: A survey
Wenzhong Guo, Jianwen Wang, and Shiping Wang. Deep multimodal representation learning: A survey. Ieee Access, 7:63373–63394, 2019
work page 2019
-
[12]
Xing Han, Huy Nguyen, Carl Harris, Nhat Ho, and Suchi Saria. Fusemoe: Mixture-of-experts transformers for fleximodal fusion. arXiv preprint arXiv:2402.03226, 2024
-
[13]
Multitask learning and benchmarking with clinical time series data
Hrayr Harutyunyan, Hrant Khachatrian, David C Kale, Greg Ver Steeg, and Aram Galstyan. Multitask learning and benchmarking with clinical time series data. Scientific data, 6(1):96, 2019
work page 2019
-
[14]
Medfuse: Multi-modal fusion with clinical time- series data and chest x-ray images
Nasir Hayat, Krzysztof J Geras, and Farah E Shamout. Medfuse: Multi-modal fusion with clinical time- series data and chest x-ray images. In Machine Learning for Healthcare Conference, pages 479–503. PMLR, 2022
work page 2022
-
[15]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. In European conference on computer vision, pages 709–727. Springer, 2022
work page 2022
-
[16]
Mimic-iii, a freely accessible critical care database
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. Mimic-iii, a freely accessible critical care database. Scientific data, 3(1):1–9, 2016
work page 2016
-
[17]
Mimic-iv, a freely accessible electronic health record dataset
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset. Scientific data, 10(1):1, 2023. 10
work page 2023
-
[18]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022
work page 2022
-
[20]
Smil: Multimodal learning with severely missing modality
Mengmeng Ma, Jian Ren, Long Zhao, Sergey Tulyakov, Cathy Wu, and Xi Peng. Smil: Multimodal learning with severely missing modality. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 35, pages 2302–2310, 2021
work page 2021
-
[21]
Mixture of experts: a literature survey
Saeed Masoudnia and Reza Ebrahimpour. Mixture of experts: a literature survey. Artificial Intelligence Review, 42:275–293, 2014
work page 2014
-
[22]
Multimodal contrastive learning with limoe: the language-image mixture of experts
Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby. Multimodal contrastive learning with limoe: the language-image mixture of experts. Advances in Neural Information Processing Systems, 35:9564–9576, 2022
work page 2022
-
[23]
Mixture-of-linear-experts for long-term time series forecasting
Ronghao Ni, Zinan Lin, Shuaiqi Wang, and Giulia Fanti. Mixture-of-linear-experts for long-term time series forecasting. In International Conference on Artificial Intelligence and Statistics, pages 4672–4680. PMLR, 2024
work page 2024
-
[24]
Soujanya Poria, Erik Cambria, and Alexander Gelbukh. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis. In Proceedings of the 2015 conference on empirical methods in natural language processing, pages 2539–2544, 2015
work page 2015
-
[25]
Integrating multimodal information in large pretrained transformers
Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, Amir Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque. Integrating multimodal information in large pretrained transformers. In Proceedings of the conference. Association for computational linguistics. Meeting, volume 2020, page 2359, 2020
work page 2020
-
[26]
Vigan: Missing view imputation with generative adversarial networks
Chao Shang, Aaron Palmer, Jiangwen Sun, Ko-Shin Chen, Jin Lu, and Jinbo Bi. Vigan: Missing view imputation with generative adversarial networks. In 2017 IEEE International conference on big data (Big Data), pages 766–775. IEEE, 2017
work page 2017
-
[27]
Similar modality completion-based multimodal sentiment analysis under uncertain missing modalities
Yuhang Sun, Zhizhong Liu, Quan Z Sheng, Dianhui Chu, Jian Yu, and Hongxiang Sun. Similar modality completion-based multimodal sentiment analysis under uncertain missing modalities. Information Fusion, 110: 102454, 2024
work page 2024
-
[28]
Multimodal transformer for unaligned multimodal language sequences
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the conference. Association for computational linguistics. Meeting, volume 2019, page 6558, 2019
work page 2019
-
[29]
Multi-modal learning with missing modality via shared-specific feature modelling
Hu Wang, Yuanhong Chen, Congbo Ma, Jodie Avery, Louise Hull, and Gustavo Carneiro. Multi-modal learning with missing modality via shared-specific feature modelling. In Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 15878–15887, 2023
work page 2023
-
[30]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts. arXiv preprint arXiv:2408.15664, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Visual question answering: A survey of methods and datasets
Qi Wu, Damien Teney, Peng Wang, Chunhua Shen, Anthony Dick, and Anton Van Den Hengel. Visual question answering: A survey of methods and datasets. Computer Vision and Image Understanding, 163:21–40, 2017
work page 2017
-
[32]
Multimodal learning with transformers: A survey
Peng Xu, Xiatian Zhu, and David A Clifton. Multimodal learning with transformers: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):12113–12132, 2023
work page 2023
-
[33]
Bo Yang and Lijun Wu. How to leverage multimodal ehr data for better medical predictions? arXiv preprint arXiv:2110.15763, 2021
-
[34]
Wenfang Yao, Kejing Yin, William K Cheung, Jia Liu, and Jing Qin. Drfuse: Learning disentangled representation for clinical multi-modal fusion with missing modality and modal inconsistency. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 16416–16424, 2024
work page 2024
-
[35]
Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts, 2024
Sukwon Yun, Inyoung Choi, Jie Peng, Yangfan Wu, Jingxuan Bao, Qiyiwen Zhang, Jiayi Xin, Qi Long, and Tianlong Chen. Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts. arXiv preprint arXiv:2410.08245, 2024
-
[36]
MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv preprint arXiv:1606.06259, 2016. 11
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[37]
Tensor Fusion Network for Multimodal Sentiment Analysis
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Tensor fusion network for multimodal sentiment analysis. arXiv preprint arXiv:1707.07250, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Improving medical predictions by irregular multimodal electronic health records modeling
Xinlu Zhang, Shiyang Li, Zhiyu Chen, Xifeng Yan, and Linda Ruth Petzold. Improving medical predictions by irregular multimodal electronic health records modeling. In International Conference on Machine Learning, pages 41300–41313. PMLR, 2023
work page 2023
-
[39]
Liangwei Nathan Zheng, Chang George Dong, Wei Emma Zhang, Xin Chen, Lin Yue, and Weitong Chen. Devil in the tail: A multi-modal framework for drug-drug interaction prediction in long tail distinction. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 3395–3404, 2024
work page 2024
-
[40]
Revisited large language model for time series analysis through modality alignment
Liangwei Nathan Zheng, Chang George Dong, Wei Emma Zhang, Lin Yue, Miao Xu, Olaf Maennel, and Weitong Chen. Revisited large language model for time series analysis through modality alignment. arXiv preprint arXiv:2410.12326, 2024
-
[41]
Liangwei Nathan Zheng, Zhengyang Li, Chang George Dong, Wei Emma Zhang, Lin Yue, Miao Xu, Olaf Maennel, and Weitong Chen. Irregularity-informed time series analysis: Adaptive modelling of spatial and temporal dynamics. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 3405–3414, 2024. A Notation Table 5...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.