Physics-Guided Policy Optimization with Self-Distillation
Pith reviewed 2026-06-28 10:47 UTC · model grok-4.3
The pith
An information-modulated step-size multiplier stabilizes self-distilled policy optimization while preserving SGD guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
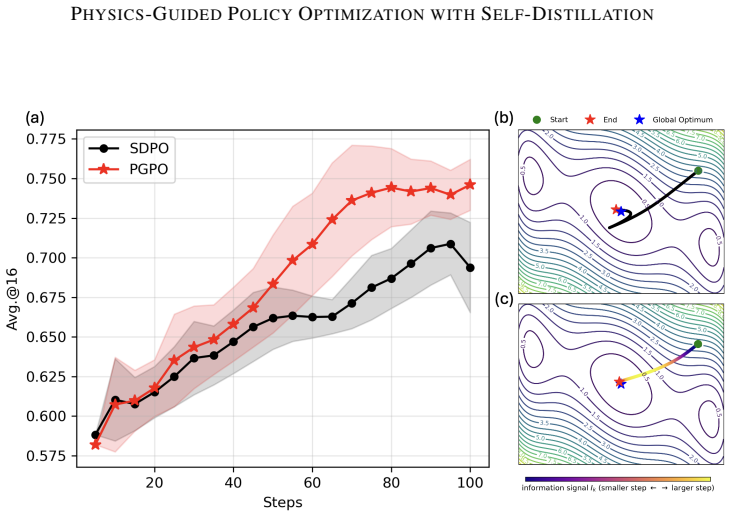
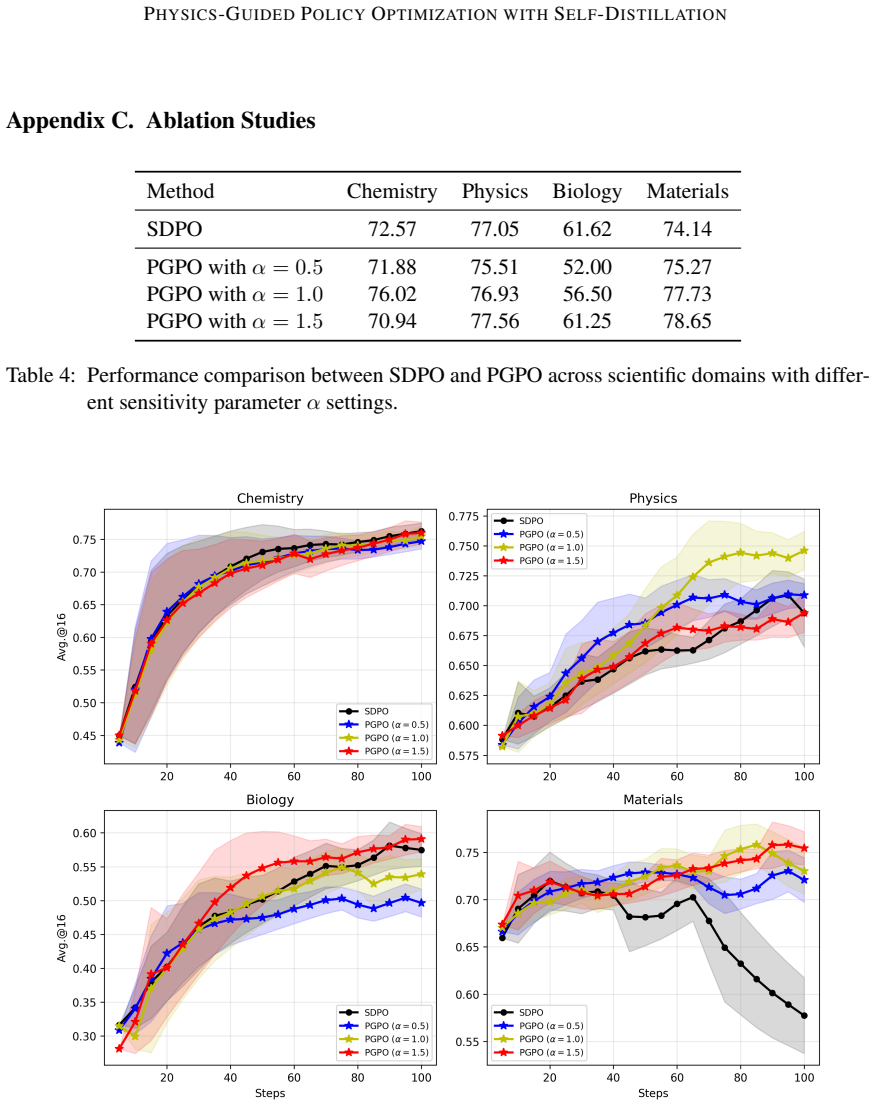
Drawing inspiration from viscous-fluid dynamics and formalizing the analogy at the SDE level, PGPO introduces an information-modulated step-size multiplier derived from a mutual-information estimate between the student's predictions and the feedback-conditioned teacher outputs. This modulation preserves the order-1 weak-approximation guarantees of vanilla SGD and incurs negligible overhead per iteration. Evaluation on the Science-QA dataset shows outperformance on 3 of the 4 domains with gains of up to +4.5 points, while remaining stable in a setting where SDPO collapses late in training.
What carries the argument
Information-modulated step-size multiplier derived from mutual-information estimate between student predictions and feedback-conditioned teacher outputs.
If this is right
- The modulation preserves the order-1 weak-approximation guarantees of vanilla SGD.
- It incurs negligible overhead per iteration.
- PGPO outperforms SDPO on 3 of 4 domains in Science-QA with gains up to 4.5 points.
- PGPO remains stable in settings where SDPO collapses late in training.
Where Pith is reading between the lines
- The SDE-level fluid-dynamics analogy could be applied to adaptive learning rates in other noisy-feedback optimization settings.
- Reliable mutual-information estimation may become a general tool for deciding per-batch trust in teacher-student training loops.
- The method could be tested on other self-distillation tasks beyond Science-QA to check whether the stability benefit generalizes.
Load-bearing premise
The mutual-information estimate between student predictions and feedback-conditioned teacher outputs can be computed reliably enough to serve as a faithful proxy for per-batch trustworthiness.
What would settle it
Replacing the mutual-information estimates with random or constant values and observing that PGPO then loses both its stability advantage and its performance gains over SDPO would falsify the claim that the modulation is responsible for the observed benefits.
Figures
read the original abstract
Self-distilled policy optimization (SDPO) has become a popular paradigm for LLM post-training, where a model learns from its own predictions conditioned on privileged information. SDPO, however, is sensitive to how much each update step should be trusted: corrections from a self-teacher can be highly informative on some batches and misleading on others, and applying them uniformly with a fixed step size can destabilize training. Drawing inspiration from viscous-fluid dynamics and formalizing the analogy at the SDE level, we propose Physics-Guided Policy Optimization (PGPO), which introduces an information-modulated step-size multiplier derived from a mutual-information estimate between the student's predictions and the feedback-conditioned teacher. We show that this modulation preserves the order-1 weak-approximation guarantees of vanilla SGD, and incurs negligible overhead per iteration. We evaluate PGPO on the Science-QA dataset, where it outperforms SDPO on 3 of the 4 domains with gains of up to +4.5 points, while remaining stable in a setting where SDPO collapses late in training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Physics-Guided Policy Optimization (PGPO) for LLM post-training via self-distillation. It introduces an information-modulated step-size multiplier derived from a mutual-information estimate between student predictions and feedback-conditioned teacher outputs, motivated by a viscous-fluid/SDE analogy. The central claims are that this multiplier preserves the order-1 weak-approximation guarantees of vanilla SGD, adds negligible per-iteration cost, and yields empirical gains (up to +4.5 points on 3 of 4 Science-QA domains) while avoiding the late-training collapse seen in SDPO.
Significance. If the SDE preservation result holds under realistic conditions on the MI estimator and the empirical stability advantage generalizes, the work would supply a principled, low-overhead mechanism for modulating trust in self-distilled updates. The explicit link between mutual information and step-size modulation in the SDE limit is a potentially useful conceptual contribution for stabilizing policy optimization in LLMs.
major comments (3)
- [Abstract / theoretical analysis] The abstract asserts that the information-modulated multiplier 'preserves the order-1 weak-approximation guarantees of vanilla SGD,' yet no derivation, moment bounds on the multiplier, or conditions on the MI estimator's variance/smoothness are supplied. Because the multiplier is constructed from the same training signals whose trustworthiness it is meant to modulate, it is unclear whether the resulting SDE remains within the class for which order-1 weak convergence is known to hold.
- [Experiments] The empirical evaluation reports gains on Science-QA but provides no variance across runs, no ablation of the MI estimator itself, and no comparison against other adaptive step-size or trust-modulation baselines. The claim that PGPO 'remains stable in a setting where SDPO collapses late in training' therefore rests on a single dataset without statistical support for the stability advantage.
- [Method / information-modulated multiplier] The mutual-information estimate is described as a 'faithful proxy for per-batch trustworthiness,' but the manuscript supplies no quantitative bounds on its estimation error, bias under discrete high-dimensional outputs, or sensitivity to batch size. If the estimator is noisy, the derived multiplier can violate the regularity assumptions needed for the SDE guarantee and can re-introduce the very instability the method aims to prevent.
minor comments (2)
- [Method] Notation for the MI estimator and the resulting multiplier should be introduced with an explicit equation rather than inline description.
- [Theoretical analysis] The paper should cite the specific weak-convergence results for SGD (e.g., the precise theorem on order-1 approximation under additive noise) that are being extended.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that strengthen the theoretical grounding, experimental rigor, and analysis of the MI estimator.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] The abstract asserts that the information-modulated multiplier 'preserves the order-1 weak-approximation guarantees of vanilla SGD,' yet no derivation, moment bounds on the multiplier, or conditions on the MI estimator's variance/smoothness are supplied. Because the multiplier is constructed from the same training signals whose trustworthiness it is meant to modulate, it is unclear whether the resulting SDE remains within the class for which order-1 weak convergence is known to hold.
Authors: We agree that the abstract states the preservation claim without sufficient supporting detail. While the manuscript contains a section deriving the SDE limit from the viscous-fluid analogy and arguing that the modulated update retains the order-1 weak approximation property of SGD, explicit moment bounds on the multiplier and regularity conditions on the MI estimator are not stated. In the revision we will expand the theoretical analysis to supply these bounds, state the required assumptions on estimator variance and smoothness, and clarify the conditions under which the guarantee continues to hold despite the multiplier depending on training signals. revision: yes
-
Referee: [Experiments] The empirical evaluation reports gains on Science-QA but provides no variance across runs, no ablation of the MI estimator itself, and no comparison against other adaptive step-size or trust-modulation baselines. The claim that PGPO 'remains stable in a setting where SDPO collapses late in training' therefore rests on a single dataset without statistical support for the stability advantage.
Authors: We acknowledge that the reported results lack variance estimates, ablations, and baseline comparisons, limiting the strength of the stability claim. In the revised manuscript we will include standard deviations over multiple random seeds, an ablation isolating the MI estimator, and comparisons against representative adaptive step-size and trust-modulation methods. The stability observation will be qualified or supported by additional runs or datasets as appropriate. revision: yes
-
Referee: [Method / information-modulated multiplier] The mutual-information estimate is described as a 'faithful proxy for per-batch trustworthiness,' but the manuscript supplies no quantitative bounds on its estimation error, bias under discrete high-dimensional outputs, or sensitivity to batch size. If the estimator is noisy, the derived multiplier can violate the regularity assumptions needed for the SDE guarantee and can re-introduce the very instability the method aims to prevent.
Authors: We agree that quantitative characterization of the MI estimator is required to support both the theoretical guarantee and the practical stability claim. The current text motivates the estimator via the fluid analogy but provides no error bounds, bias analysis for discrete outputs, or batch-size sensitivity study. In the revision we will add a dedicated subsection supplying these bounds where possible, discussing potential bias in high-dimensional token spaces, and reporting empirical sensitivity to batch size, together with any safeguards that keep the multiplier within the regularity regime needed for the SDE result. revision: yes
Circularity Check
No circularity: modulation derived from external MI estimate; guarantee claim is independent analysis
full rationale
The abstract states that the step-size multiplier is derived from a mutual-information estimate between student predictions and teacher outputs, then asserts that this modulation preserves order-1 weak-approximation guarantees of vanilla SGD. No equations, self-citations, or definitional steps are supplied that reduce the multiplier or the preservation claim to a fitted input renamed as prediction, a self-referential definition, or a load-bearing self-citation chain. The MI quantity is presented as computed from training signals rather than defined in terms of the target result, leaving the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The training dynamics can be approximated at the SDE level by a viscous-fluid model whose damping term is proportional to mutual information.
invented entities (1)
-
information-modulated step-size multiplier
no independent evidence
Forward citations
Cited by 1 Pith paper
-
DRIFT: Difficulty Routing Self-DIstillation with Rhythm-Gated Exploration and Success BuFfer Training
DRIFT is an online self-evolution policy optimization framework using Difficulty Routing, Rhythm Gating, success buffers, and two-stage curriculum learning that reports new SOTA results on five reasoning benchmarks.
Reference graph
Works this paper leans on
-
[1]
McGraw Hill, 2013
Yunus Cengel and John Cimbala.Ebook: Fluid mechanics fundamentals and applications (si units). McGraw Hill, 2013
2013
-
[2]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[3]
Sciknoweval: Evaluating multi-level scientific knowledge of large language models,
Kehua Feng, Xinyi Shen, Weijie Wang, Xiang Zhuang, Yuqi Tang, Qiang Zhang, and Keyan Ding. Sciknoweval: Evaluating multi-level scientific knowledge of large language models,
-
[4]
URLhttps://arxiv.org/abs/2406.09098
-
[5]
Reinforcement learning via self-distillation, 2026
Jonas H ¨ubotter, Frederike L ¨ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation, 2026. URLhttps://arxiv.org/ abs/2601.20802
Pith/arXiv arXiv 2026
-
[6]
Why does self-distillation (sometimes) degrade the rea- soning capability of llms?, 2026
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the rea- soning capability of llms?, 2026. URLhttps://arxiv.org/abs/2603.24472
Pith/arXiv arXiv 2026
-
[7]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
Pith/arXiv arXiv 2017
-
[8]
Numerical solution of stochastic differential equations springer
PE Kloden and E Platen. Numerical solution of stochastic differential equations springer. Berlin, Germany, 1992
1992
-
[9]
Scaling reasoning efficiently via relaxed on-policy distillation, 2026
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation, 2026. URLhttps://arxiv.org/ abs/2603.11137
arXiv 2026
-
[10]
Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, 6 PHYSICS-GUIDEDPOLICYOPTIMIZATION WITHSELF-DISTILLATION Chris Wilhelm, Luca Soldaini, Noah A. Sm...
Pith/arXiv arXiv 2025
-
[11]
Unifying group-relative and self-distillation policy optimization via sample routing, 2026
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing, 2026. URLhttps://arxiv.org/abs/2604.02288
arXiv 2026
-
[12]
Stochastic modified equations and adaptive stochastic gradient algorithms, 2017
Qianxiao Li, Cheng Tai, and Weinan E. Stochastic modified equations and adaptive stochastic gradient algorithms, 2017. URLhttps://arxiv.org/abs/1511.06251
Pith/arXiv arXiv 2017
-
[13]
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe, 2026. URLhttps: //arxiv.org/abs/2604.13016
Pith/arXiv arXiv 2026
-
[14]
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Con- nectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy- distillation
-
[15]
Numerical integration of stochastic differential equations, 1997
Riccardo Mannella. Numerical integration of stochastic differential equations, 1997. URL https://arxiv.org/abs/cond-mat/9709326
Pith/arXiv arXiv 1997
-
[16]
Self-distillation enables continual learning, 2026
Idan Shenfeld, Mehul Damani, Jonas H ¨ubotter, and Pulkit Agrawal. Self-distillation enables continual learning, 2026. URLhttps://arxiv.org/abs/2601.19897
Pith/arXiv arXiv 2026
-
[17]
A survey of on-policy distillation for large language models,
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models,
-
[18]
URLhttps://arxiv.org/abs/2604.00626
-
[19]
Andrew Bagnell, Aarti Singh, and Andrea Zanette
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J. Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback, 2026. URLhttps://arxiv.org/abs/2602.02482
arXiv 2026
-
[20]
Mimo-v2-flash technical report, 2026
Core Team, Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, Gang Xie, Hailin Zhang, Hanglong Lv, Hanyu Li, Heyu Chen, Hongshen Xu, Houbin Zhang, Huaqiu Liu, Jiangshan Duo, Jianyu Wei, Jiebao Xiao, Jinhao Dong, Jun Shi, Junhao Hu, Kainan Bao, Kang Zhou, Lei Li, Liang Zhao, Linghao Zhang,...
Pith/arXiv arXiv 2026
-
[21]
Springer, 2004
Larry Wasserman.All of statistics: a concise course in statistical inference, volume 26. Springer, 2004
2004
-
[22]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[23]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr, 2026. URLhttps: //arxiv.org/abs/2604.03128
Pith/arXiv arXiv 2026
-
[24]
On-policy context distillation for language models, 2026
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models, 2026. URLhttps://arxiv.org/abs/2602.12275
Pith/arXiv arXiv 2026
-
[25]
Self-distilled reasoner: On-policy self-distillation for large language models, 2026
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models, 2026. URLhttps://arxiv.org/abs/2601.18734. 8 PHYSICS-GUIDEDPOLICYOPTIMIZATION WITHSELF-DISTILLATION Appendix A. Weak Convergence Guarantees We now show that PGPO admits an order-1 weak ...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.