DRIFT: Difficulty Routing Self-DIstillation with Rhythm-Gated Exploration and Success BuFfer Training
Pith reviewed 2026-06-30 07:15 UTC · model grok-4.3
The pith
DRIFT lets language models improve their own reasoning by routing problems according to learning state and gating exploration to key steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
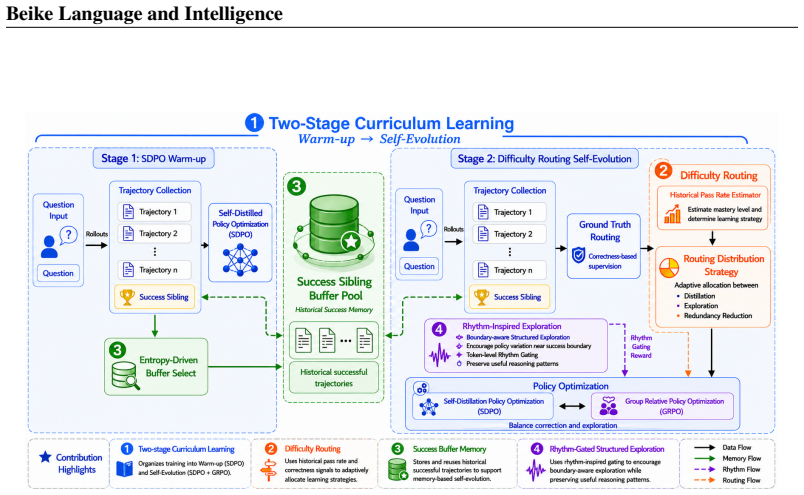
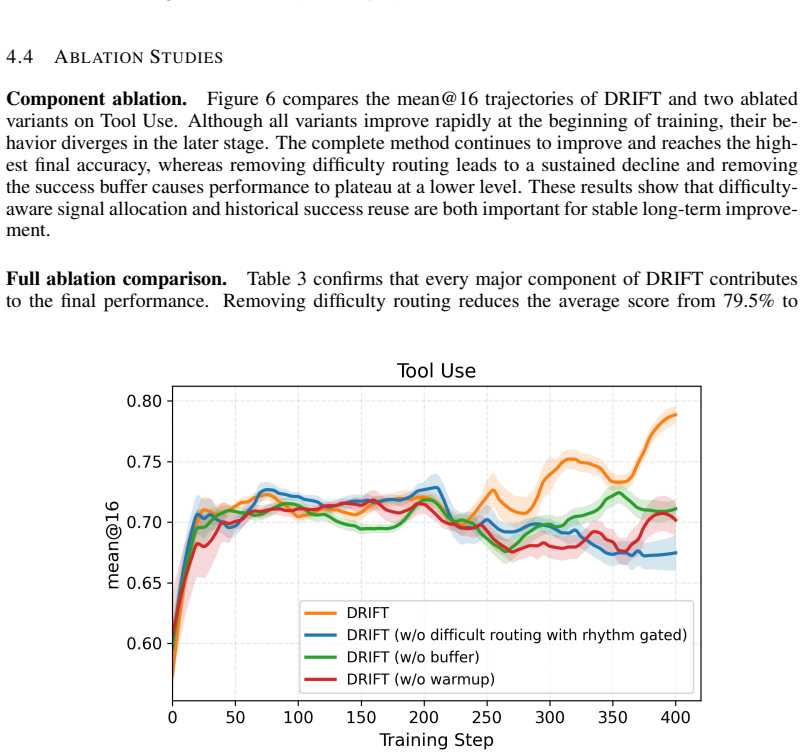
DRIFT is an online self-evolution policy optimization framework for large language models. It regulates the model's self-improvement process through the joint use of Difficulty Routing and Rhythm Gating. The former identifies the model's learning state at the problem level and dynamically allocates self-distillation and reinforcement learning signals, while the latter refines policy updates at the token level, concentrating exploration on critical reasoning positions. By further incorporating a success buffer and a two-stage curriculum learning strategy, DRIFT preserves high-quality historical experience while progressively guiding the model from reliable behavior acquisition toward stable p
What carries the argument
Difficulty Routing, which identifies the model's per-problem learning state to dynamically allocate self-distillation and reinforcement learning signals.
If this is right
- The framework produces higher scores than prior self-distillation and reinforcement methods across five reasoning benchmarks.
- It reaches new peak accuracy on tool-use tasks.
- The approach supports stable evolution across multiple model scales without external supervision.
- The success buffer and curriculum together enable retention of high-quality experience during progressive training.
Where Pith is reading between the lines
- The per-problem routing idea could extend to other adaptive training settings where progress varies widely across examples.
- If the routing works as described, similar state-tracking might reduce the amount of hand-designed curricula needed in reinforcement learning for language models.
- Separate tests that turn routing on and off while holding other components fixed would isolate its contribution to any observed stability gains.
Load-bearing premise
Difficulty Routing can reliably identify each problem's learning state for the model and the gating plus buffer will produce stable policy evolution without creating new instabilities.
What would settle it
Training runs in which Difficulty Routing is replaced by random or fixed allocation, then checking whether the reported performance gains over prior methods disappear.
Figures

read the original abstract
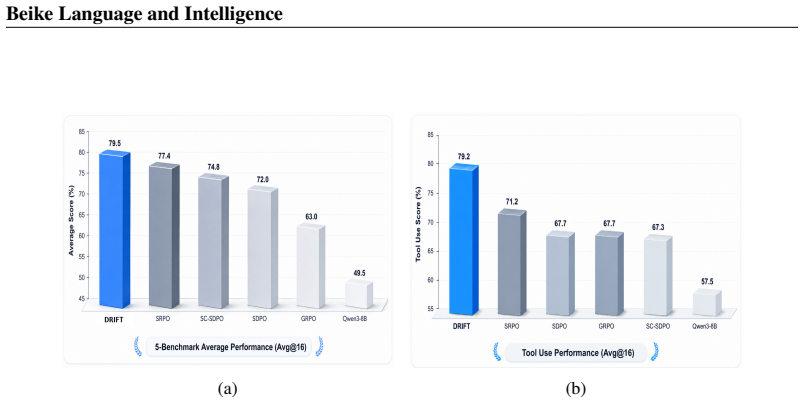
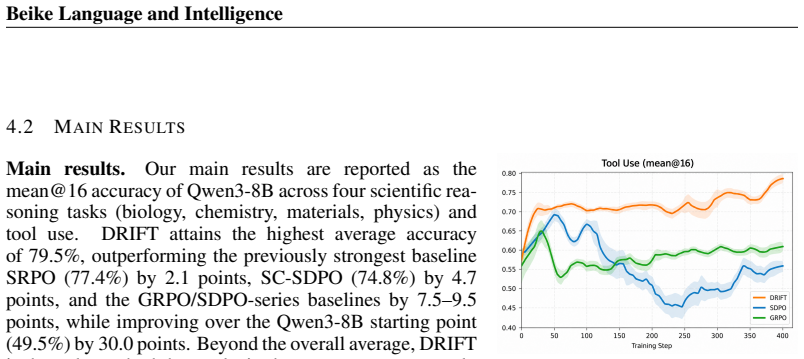
Enabling large language models to achieve stable self-improvement without external expert supervision remains a central challenge in complex reasoning tasks. Existing self-distillation and reinforcement learning methods lack explicit mechanisms for tracking problem-level learning progress and adapting optimization strategies accordingly. Consequently, training may over-optimize easy problems, receive weak supervision from hard problems, and fail to sufficiently explore borderline cases. To resolve these issues, we propose DRIFT, an online self-evolution policy optimization framework for large language models. DRIFT regulates the model's self-improvement process through the joint use of Difficulty Routing and Rhythm Gating. The former identifies the model's learning state at the problem level and dynamically allocates self-distillation and reinforcement learning signals, while the latter refines policy updates at the token level, concentrating exploration on critical reasoning positions. By further incorporating a success buffer and a two-stage curriculum learning strategy, DRIFT preserves high-quality historical experience while progressively guiding the model from reliable behavior acquisition toward stable policy evolution. Evaluated across five benchmarks and three model scales, DRIFT surpasses the peak performance of both GRPO and SDPO across all evaluated metrics. On the average score over the five benchmarks, DRIFT achieves 79.5$\%$, outperforming GRPO by 9.5$\%$ and SDPO by 7.5$\%$, establishing a new state-of-the-art result. Notably, on ToolUse, DRIFT reaches an accuracy of 79.2$\%$, improving over GRPO by 13.5$\%$ and SDPO by 10.7$\%$, setting a new state-of-the-art and substantially outperforming all concurrent methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DRIFT, an online self-evolution policy optimization framework for LLMs that combines Difficulty Routing (to identify per-problem learning states and allocate self-distillation vs. RL signals), Rhythm Gating (for token-level focus on critical reasoning positions), a success buffer (to preserve high-quality historical experience), and a two-stage curriculum. It claims consistent empirical superiority over GRPO and SDPO across five benchmarks and three model scales, with DRIFT reaching 79.5% average score (9.5% above GRPO, 7.5% above SDPO) and 79.2% on ToolUse (13.5% and 10.7% gains respectively), establishing new state-of-the-art results.
Significance. If the reported gains prove robust under controlled ablations and statistical testing, the framework could meaningfully advance unsupervised self-improvement methods by explicitly tracking problem difficulty and modulating exploration at both problem and token levels. The joint use of routing and gating addresses a recognized gap in prior self-distillation/RL approaches, though the absence of any mention of reproducibility artifacts (code, seeds, or hyperparameter schedules) limits immediate impact assessment.
major comments (3)
- Abstract: the central claim that DRIFT 'surpasses the peak performance of both GRPO and SDPO across all evaluated metrics' and sets new SOTA is presented without any reference to experimental controls, baseline implementation details, number of runs, variance, or statistical significance testing; this information is load-bearing for the performance numbers (79.5% average, 79.2% ToolUse) and cannot be verified from the given text.
- Abstract (method description): no equations, pseudocode, or implementation details are supplied for Difficulty Routing (how per-problem learning state is quantified) or Rhythm Gating (how token-level critical positions are identified), so it is impossible to assess whether these mechanisms are independent of the fitted training choices that produce the reported gains.
- Abstract: the text states that DRIFT incorporates 'a success buffer and a two-stage curriculum learning strategy' but supplies no ablation results isolating their contribution versus the routing/gating components, undermining attribution of the 9.5%/7.5% average improvements specifically to the proposed innovations.
minor comments (1)
- Abstract: minor typographical inconsistency in 'Self-DIstillation' (capital I in 'DIstillation').
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We provide point-by-point responses to the major comments below, clarifying aspects of the experimental reporting and method descriptions.
read point-by-point responses
-
Referee: Abstract: the central claim that DRIFT 'surpasses the peak performance of both GRPO and SDPO across all evaluated metrics' and sets new SOTA is presented without any reference to experimental controls, baseline implementation details, number of runs, variance, or statistical significance testing; this information is load-bearing for the performance numbers (79.5% average, 79.2% ToolUse) and cannot be verified from the given text.
Authors: We agree that the abstract would benefit from referencing the experimental controls. The manuscript body (Section 4) provides details on baseline implementations, number of runs, variance, and statistical testing. We will revise the abstract to briefly note these aspects for improved verifiability of the claims. revision: yes
-
Referee: Abstract (method description): no equations, pseudocode, or implementation details are supplied for Difficulty Routing (how per-problem learning state is quantified) or Rhythm Gating (how token-level critical positions are identified), so it is impossible to assess whether these mechanisms are independent of the fitted training choices that produce the reported gains.
Authors: The abstract summarizes the approach at a high level. Full equations, quantification details for Difficulty Routing and Rhythm Gating, and pseudocode are provided in Section 3 of the manuscript. We will update the abstract to include a concise description of how the learning state and critical positions are identified. revision: partial
-
Referee: Abstract: the text states that DRIFT incorporates 'a success buffer and a two-stage curriculum learning strategy' but supplies no ablation results isolating their contribution versus the routing/gating components, undermining attribution of the 9.5%/7.5% average improvements specifically to the proposed innovations.
Authors: Ablation results isolating the contributions of the success buffer and two-stage curriculum are included in Section 5 and the appendix of the manuscript. We will revise the abstract to reference these ablations to better attribute the performance gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical proposal of a training framework (Difficulty Routing + Rhythm Gating + success buffer + two-stage curriculum) whose central claims consist of measured performance gains on five benchmarks versus GRPO and SDPO. No derivation chain, equations, or uniqueness theorems are presented that reduce to fitted parameters or self-citations by construction. The reported improvements are external benchmark results whose independence from the training choices is not internally contradicted by the given text; the method is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Reinforcement Learning from Rich Feedback with Distributional DAgger
Rishabh Agrawal, Jacob Fein-Ashley, and Paria Rashidinejad. Reinforcement learning from rich feedback with distributional dagger.arXiv preprint arXiv:2606.05152,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Andrei Baroian and Rutger Berger. Prompt replay: Speeding up grpo with on-policy reuse of high- signal prompts.arXiv preprint arXiv:2603.21177,
-
[3]
The Unlearnability Phenomenon in RLVR for Language Models
URLhttps://arxiv.org/abs/2605.16787. Yue Cheng, Jiajun Zhang, Xiaohui Gao, Weiwei Xing, Zheng Wang, and Zhanxing Zhu. Mech- anistically interpreting the role of sample difficulty in rlvr for llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Mechanistically Interpreting the Role of Sample Difficulty in RLVR for LLMs
URLhttps: //arxiv.org/abs/2605.28388. 13 Beike Language and Intelligence Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next genera- tion agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-V4: Towards highly efficient million-token context intelligence,
URLhttps://arxiv.org/abs/2606.19348. Kehua Feng, Keyan Ding, Weijie Wang, Xiang Zhuang, Zeyuan Wang, Ming Qin, Yu Zhao, Jianhua Yao, Qiang Zhang, and Huajun Chen. Sciknoweval: Evaluating multi-level scientific knowledge of large language models.arXiv preprint arXiv:2406.09098,
-
[8]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
URLhttps://arxiv.org/abs/2603.25562. Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: On-policy distillation of large lan- guage models.arXiv preprint arXiv:2306.08543,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
MiniLLM: On-Policy Distillation of Large Language Models
URLhttps://arxiv.org/abs/ 2306.08543. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Reinforcement Learning via Self-Distillation
Jonas H ¨ubotter, Frederike L ¨ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Re- inforcement learning via self-distillation.arXiv preprint arXiv:2601.20802,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Aaron Jaech et al. Learning to reason with llms.arXiv preprint arXiv:2501.19393,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Entropy-Aware On-Policy Distillation of Language Models
URLhttps://arxiv.org/abs/2603.07079. Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimiza- tion via sample routing.arXiv preprint arXiv:2604.02288, 2026a. Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Zehao Liu, Yuanpu Cao, Jinghui Chen, and Vasant G. Honavar. Restoring the sweet spot: Pass-rate weighted self-distillation for llm reasoning.arXiv preprint arXiv:2605.27765,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URLhttps://arxiv.org/abs/2512.13961. Leyi Pan, Shuchang Tao, Yunpeng Zhai, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Aiwei Liu, and Lijie Wen. RLCSD: Reinforcement learning with contrastive on-policy self-distillation.arXiv preprint arXiv:2606.11709,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
RLCSD: Reinforcement Learning with Contrastive On-Policy Self-Distillation
URLhttps://arxiv.org/abs/2606.11709. Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. In International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases.arXiv preprint arXiv:2306.05301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Physics-Guided Policy Optimization with Self-Distillation
14 Beike Language and Intelligence Ke Wang, Yuning Wu, Haoran Liu, Chaoqun Jia, Devin Chen, and Kai Wei. Physics-guided policy optimization with self-distillation.arXiv preprint arXiv:2606.03620,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F. Wong, and Yu Cheng. Exgrpo: Learning to reason from experience.arXiv preprint arXiv:2510.02245,
-
[22]
Jixiao Zhang and Chunsheng Zuo
URLhttps: //arxiv.org/abs/2507.07451. Jixiao Zhang and Chunsheng Zuo. Grpo-lead: A difficulty-aware reinforcement learning approach for concise mathematical reasoning in language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 5642–5654,
-
[23]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
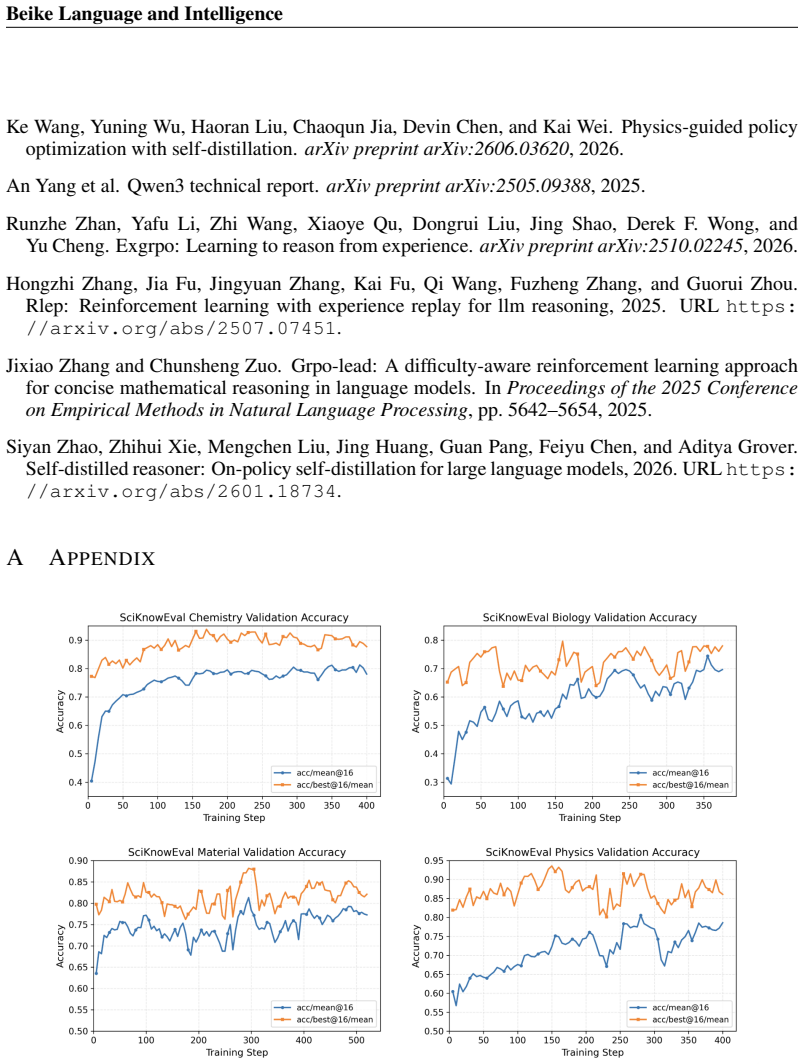
URLhttps: //arxiv.org/abs/2601.18734. A APPENDIX Figure 7:Validation performance on the STEM datasets.In addition to improvements in mean@16, best@16 also increases steadily throughout training. Table 4:Best@16 performance on Qwen3-8B.DRIFT outperforms SDPO and GRPO across all five tasks, with particularly pronounced gains on materials and tool use. Metho...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.