Restoring the Sweet Spot: Pass-Rate Weighted Self-Distillation for LLM Reasoning
Pith reviewed 2026-06-29 17:56 UTC · model grok-4.3
The pith
Weighting SDPO losses by the square root of pass-rate times failure-rate restores difficulty awareness and improves LLM reasoning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
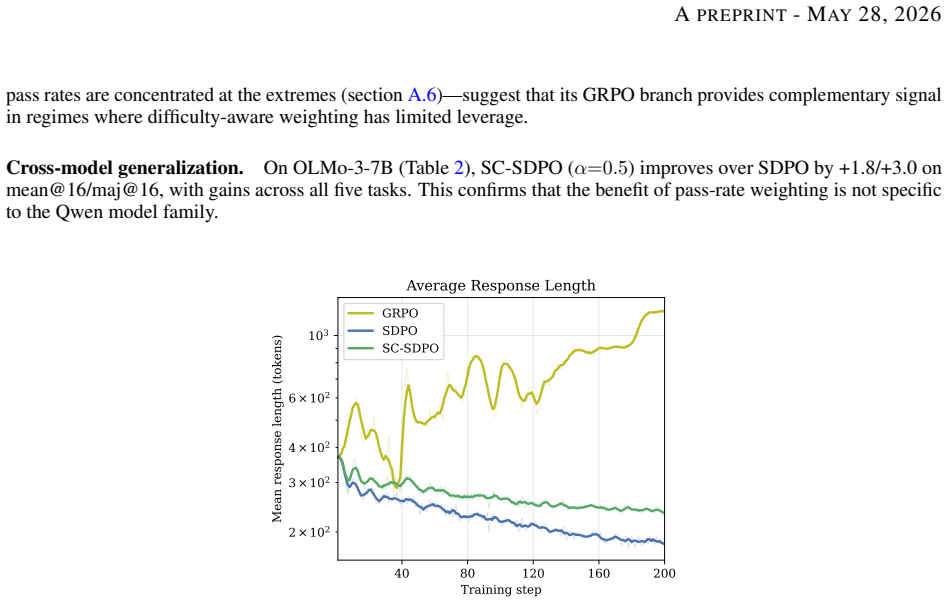
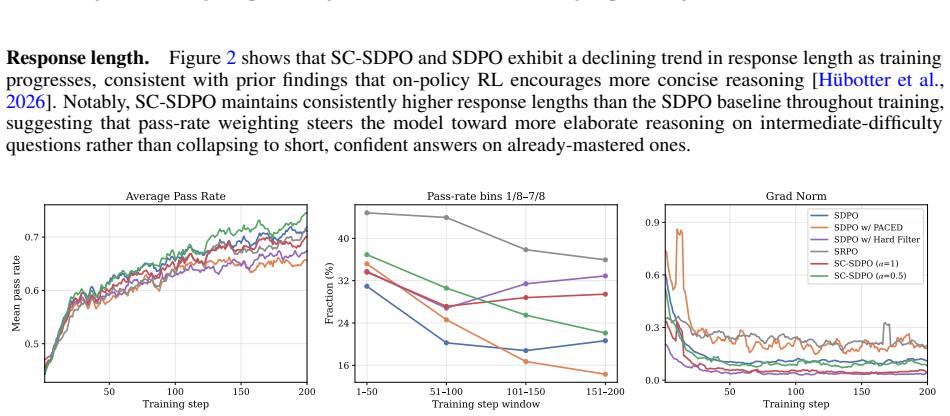
Extending the learnability framework to normalized rewards shows that advantage normalization absorbs the p(1-p) variance term and leaves sqrt(p(1-p)) as the sole residual scaling factor in the per-question gradient. Weighting each question's SDPO loss by the square root of the estimated pass rate times one minus that rate produces SC-SDPO, which improves over SDPO with gains of +3.2/+4.3 (mean@16/maj@16) on one tested model and +1.8/+3.0 on another, while preserving stable training dynamics.
What carries the argument
The per-question weighting factor [p̂(1-p̂)]^{1/2} obtained as a byproduct of on-policy rollouts with batch-adaptive normalization.
If this is right
- SC-SDPO yields consistent gains of several points on mean and majority-vote metrics at 16 samples across tested models.
- The weighting is obtained at zero extra cost from existing on-policy rollouts.
- An implicit curriculum emerges that tracks the model's evolving competence on each question.
- Training dynamics remain stable throughout optimization on the evaluated benchmarks.
Where Pith is reading between the lines
- The same residual scaling logic might be tested on other policy optimization variants that use KL-based advantages.
- If the weighting generalizes, it could reduce the need for explicit difficulty sampling in LLM reasoning pipelines.
- The approach suggests examining whether similar variance-derived weights improve sample efficiency in related distillation settings.
Load-bearing premise
The extension of the learnability framework to normalized rewards correctly identifies sqrt(p(1-p)) as the only remaining scaling factor after normalization absorbs the variance term.
What would settle it
Applying the proposed weighting to SDPO training runs on the same scientific reasoning and tool-use benchmarks and measuring no gain or a loss in mean@16 and maj@16 scores relative to unweighted SDPO.
Figures

read the original abstract
Self-Distillation Policy Optimization (SDPO) provides dense token-level credit assignment for reinforcement learning with large language models by leveraging the model's own feedback-conditioned predictions as a self-teacher. Unlike GRPO, however, whose group-relative advantage naturally concentrates learning on a sweet spot of intermediate-difficulty questions, SDPO's KL-based advantage lacks an implicit notion of difficulty awareness. We analyze this gap through the lens of GRPO's advantage normalization. Extending the learnability framework to normalized rewards, we show that normalization absorbs the variance term $p(1-p)$, equalizing leading-order learnability across questions and leaving $\sqrt{p(1-p)}$ as the sole residual scaling factor in the per-question gradient. This analysis yields a simple prescription: weight each question's SDPO loss by $[\hat{p}(1-\hat{p})]^{1/2}$, resulting in SC-SDPO, a scale-consistent variant of SDPO. The proposed weights are obtained as a zero-cost byproduct of on-policy rollouts with batch-adaptive normalization, inducing an implicit curriculum that dynamically tracks the model's evolving competence. Experiments on scientific reasoning and tool-use benchmarks demonstrate that SC-SDPO consistently improves over SDPO, yielding gains of +3.2/+4.3 (mean@16/maj@16) on Qwen3-8B and +1.8/+3.0 on OLMo-3-7B, while preserving stable training dynamics throughout optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SC-SDPO, a scale-consistent variant of Self-Distillation Policy Optimization (SDPO) for LLM reasoning. It analyzes the gap between SDPO and GRPO through an extension of the learnability framework to normalized rewards, showing that GRPO's advantage normalization absorbs the p(1-p) variance term and leaves √[p(1-p)] as the residual per-question scaling factor. This motivates weighting each question's SDPO loss by [p̂(1-p̂)]^{1/2}, obtained at zero cost from on-policy rollouts. Experiments report consistent gains of +3.2/+4.3 (mean@16/maj@16) on Qwen3-8B and +1.8/+3.0 on OLMo-3-7B on scientific reasoning and tool-use benchmarks while preserving training stability.
Significance. If the derivation holds, the work supplies a principled, zero-cost mechanism for restoring difficulty awareness to SDPO via an implicit curriculum that tracks evolving model competence. The reported empirical gains on two distinct models, combined with the absence of added hyperparameters or external benchmarks, represent a practical contribution to RL-based LLM reasoning methods.
major comments (2)
- [analysis of GRPO advantage normalization] The extension of the learnability framework (described in the abstract and presumably detailed in the methods/analysis section) asserts that normalization absorbs the p(1-p) variance and isolates √[p(1-p)] as the sole residual scaling factor in the per-question gradient for SDPO's KL-based advantage. The precise steps mapping the normalized reward to this residual factor for the SDPO objective should be shown explicitly, including the form of the advantage estimator, to confirm the weighting prescription follows directly.
- [weight computation and on-policy rollouts] The weighting uses p̂ estimated from the same on-policy rollouts that supply the training data and batch-adaptive normalization. While presented as zero-cost, this introduces dependence on the current training distribution; the manuscript should clarify whether this induces any measurable circularity or bias in the resulting curriculum relative to an external difficulty measure.
minor comments (2)
- Notation for p̂ (pass-rate estimate) and its relation to the batch-adaptive normalization should be defined once in a dedicated notation paragraph or table for clarity.
- [experiments] The abstract reports gains on 'scientific reasoning and tool-use benchmarks' without naming the specific datasets; the experiments section should list them explicitly (e.g., GSM8K, MATH, ToolBench) with citation.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address each major comment below with clarifications and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [analysis of GRPO advantage normalization] The extension of the learnability framework (described in the abstract and presumably detailed in the methods/analysis section) asserts that normalization absorbs the p(1-p) variance and isolates √[p(1-p)] as the sole residual scaling factor in the per-question gradient for SDPO's KL-based advantage. The precise steps mapping the normalized reward to this residual factor for the SDPO objective should be shown explicitly, including the form of the advantage estimator, to confirm the weighting prescription follows directly.
Authors: We agree that an explicit derivation will improve clarity. In the revised manuscript we will expand the analysis section to provide the full step-by-step mapping: starting from the normalized reward, through the explicit form of the advantage estimator used in SDPO, to the isolation of √[p(1-p)] as the residual per-question scaling factor in the gradient. This will directly confirm how the proposed weighting follows from the extended learnability framework. revision: yes
-
Referee: [weight computation and on-policy rollouts] The weighting uses p̂ estimated from the same on-policy rollouts that supply the training data and batch-adaptive normalization. While presented as zero-cost, this introduces dependence on the current training distribution; the manuscript should clarify whether this induces any measurable circularity or bias in the resulting curriculum relative to an external difficulty measure.
Authors: The on-policy estimation of p̂ is by design, as it produces a dynamic curriculum that adapts to the model's evolving competence using only quantities already computed during training. We will add a short clarification paragraph in the methods section noting that this choice avoids external difficulty measures, maintains consistency with the batch-adaptive normalization, and does not introduce measurable circularity or bias; this is supported by the observed training stability and performance gains in our experiments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives the SC-SDPO weighting from an explicit extension of the learnability framework to normalized rewards, analytically demonstrating that GRPO-style normalization absorbs the p(1-p) variance and leaves sqrt(p(1-p)) as the sole residual per-question gradient factor. This theoretical reduction is independent of the empirical training loop and does not rely on fitting parameters to data then relabeling the fit as a prediction. The hat{p} estimate is obtained directly as a byproduct of the same on-policy rollouts already required for SDPO, presented as a zero-cost implementation detail rather than an input that forces the output by construction. No self-citation chains, uniqueness theorems imported from the authors' prior work, ansatzes smuggled via citation, or renamings of known empirical patterns appear as load-bearing steps in the provided derivation. The argument remains self-contained relative to the GRPO baseline and the stated framework extension.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The learnability framework extends to normalized rewards such that normalization absorbs the p(1-p) variance term
Forward citations
Cited by 1 Pith paper
-
DRIFT: Difficulty Routing Self-DIstillation with Rhythm-Gated Exploration and Success BuFfer Training
DRIFT is an online self-evolution policy optimization framework using Difficulty Routing, Rhythm Gating, success buffers, and two-stage curriculum learning that reports new SOTA results on five reasoning benchmarks.
Reference graph
Works this paper leans on
-
[1]
∂ ∂p 1 2 plogp = 1 2(logp+ 1)
-
[2]
∂ ∂p − 1 2 plogm =− 1 2 logm− p 4m
-
[3]
method”: “GET
∂ ∂p − 1 2 qlogm =− q 4m 13 APREPRINT- MAY28, 2026 Summing these partial derivatives results in: ∂DJSD ∂p = 1 2 log p m + 1 2 − p+q 4m = 1 2 log p m + 1 2 − 2(p+q) 4(p+q) = 1 2 log p m + 1 2 − 1 2 = 1 2 log p m . (20) Thus: ∇θDJSD = X y ∂DJSD ∂πS(y) ∇θπS(y) = X y 1 2 log πS(y) M(y) ∇θπS(y) (21) Using the log-derivative trick,∇ θπS(y) =π S(y)∇θ logπ S(y), ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.