Mechanistically Interpreting the Role of Sample Difficulty in RLVR for LLMs
Pith reviewed 2026-06-29 12:08 UTC · model grok-4.3
The pith
Sample difficulty exerts a non-monotonic effect on RLVR, where easy and medium problems drive stable reasoning gains but hard ones can degrade capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
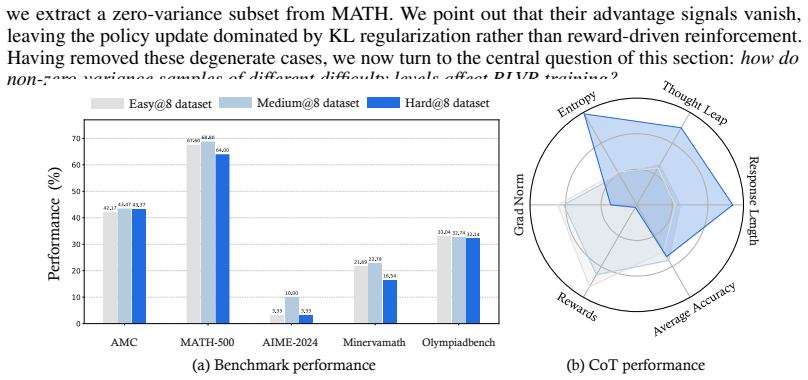
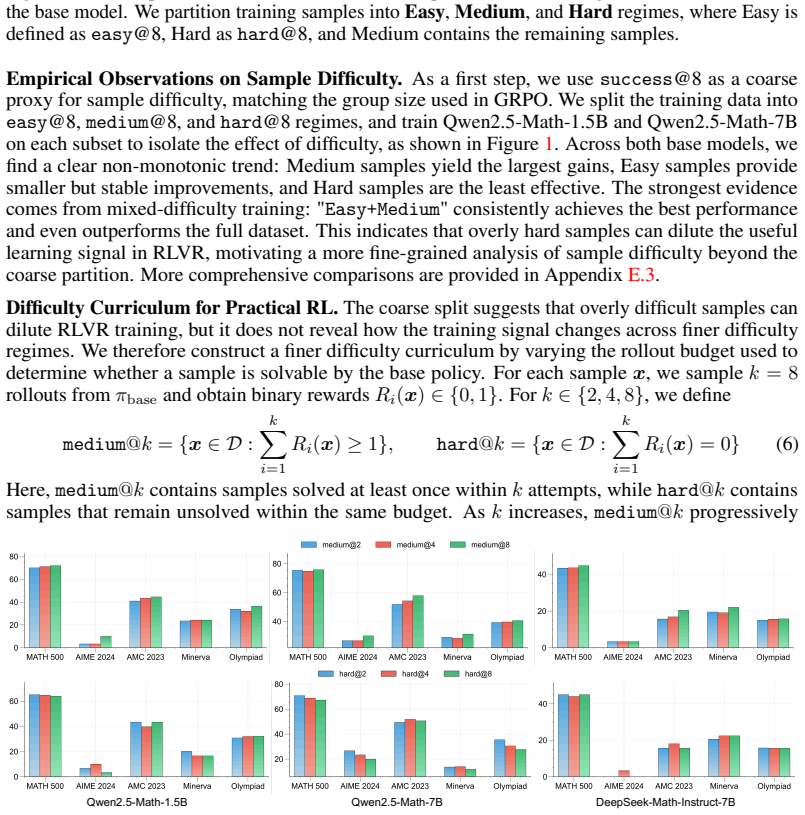
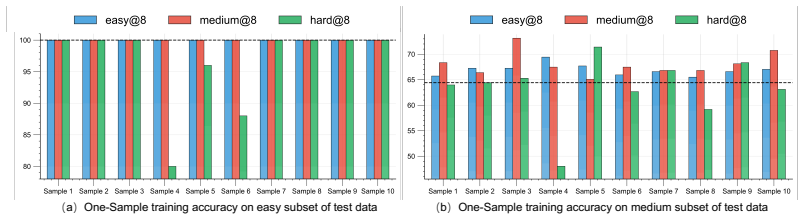
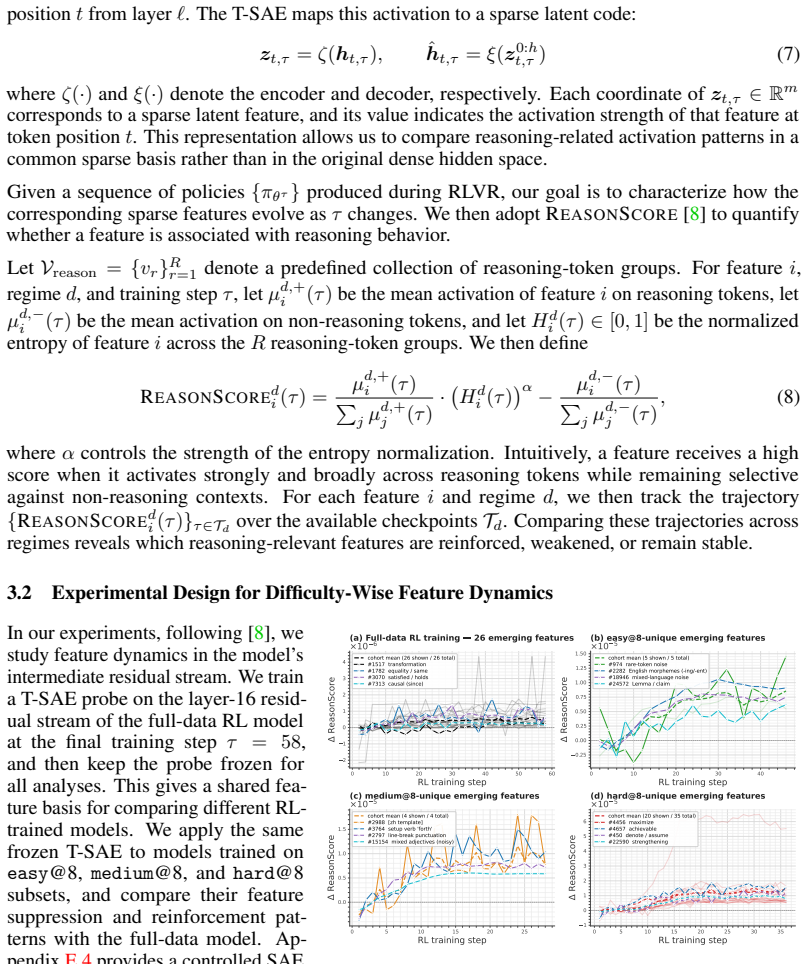
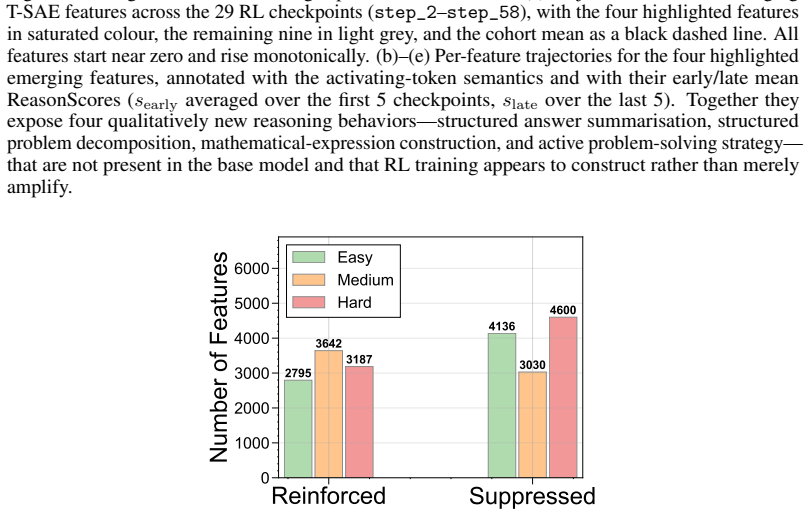
The paper claims that sample difficulty has a non-monotonic effect on RLVR. Easy and medium-difficulty problems yield the strongest and most stable reasoning improvements, whereas overly hard problems often provide weak learning signals, induce degenerate behaviors such as answer repetition or skipping necessary computation, and can ultimately degrade the model's pre-existing capabilities. Internal analysis via Temporal Sparse Autoencoders shows easy problems mainly reinforce direct-answer and basic-computation features while suppressing deliberative-reasoning features; hard problems activate reasoning-related features but become useful only when successful trajectories are sampled; medium-d
What carries the argument
Difficulty-wise and one-sample analysis combined with Temporal Sparse Autoencoders to track feature dynamics across difficulty levels during RLVR training.
If this is right
- Difficulty-adaptive strategies using backward-reasoning reformulation improve reward density for hard samples.
- T-SAE-guided training signals enhance credit assignment during RLVR.
- Medium-difficulty problems strengthen both computation and multi-step reasoning features without suppression.
- Avoiding overly hard samples prevents induction of degenerate behaviors and capability degradation.
Where Pith is reading between the lines
- Curricula that prioritize medium-difficulty samples could make RLVR training more sample-efficient.
- The same non-monotonic pattern may appear in other reinforcement learning setups for LLMs that lack verifiable rewards.
- Internal feature monitoring could serve as a real-time detector for emerging degenerate behaviors.
- The analysis might extend to programming tasks to check whether similar difficulty thresholds govern code-generation improvements.
Load-bearing premise
The chosen difficulty classification of samples accurately reflects the learning signal strength and that T-SAE features reliably track the relevant reasoning processes.
What would settle it
Training a model exclusively on hard samples and observing no rise in degenerate behaviors such as answer repetition and no loss of pre-existing capabilities compared with medium-difficulty training would falsify the non-monotonic claim.
Figures

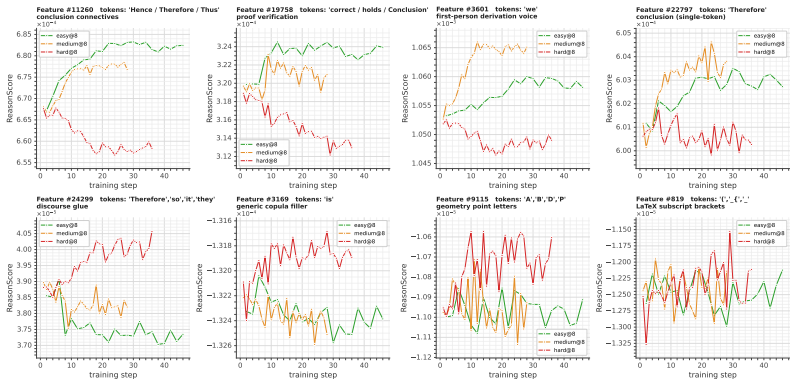
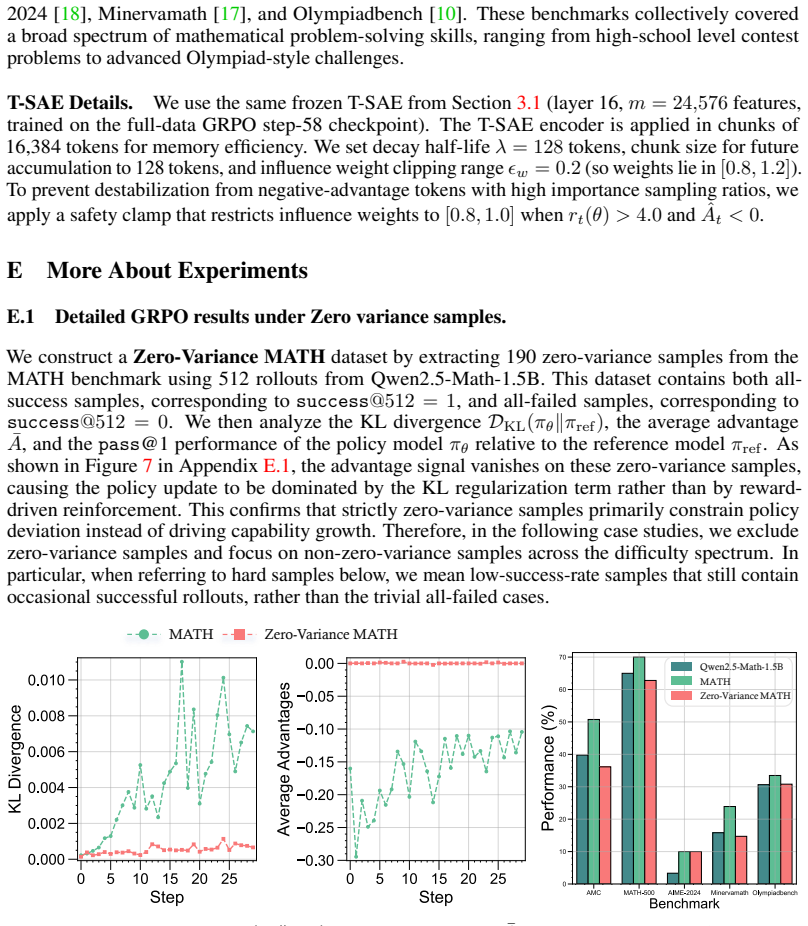
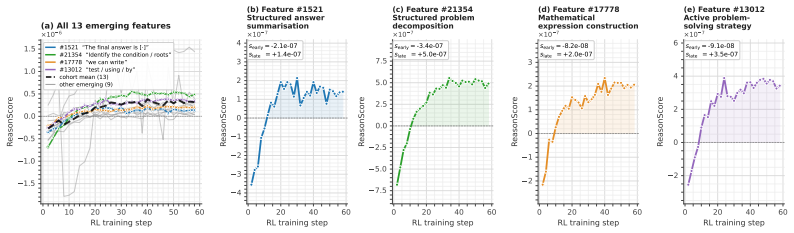
read the original abstract
Reinforcement Learning with Verifiable Reward (RLVR) is empirically shown to notably enhance the reasoning performance of large language models (LLMs), particularly in mathematics and programming. However, the mechanistic role of Sample Difficulty in RLVR remains poorly understood. In this paper, we investigate RLVR through the lens of difficulty-wise and one-sample analysis. We find that sample difficulty has a non-monotonic effect on RLVR: easy and medium-difficulty problems yield the strongest and most stable reasoning improvements, whereas overly hard problems often provide weak learning signals, induce degenerate behaviors such as answer repetition or skipping necessary computation, and can ultimately degrade the model's pre-existing capabilities. Beyond the obverse of response, we further analyze the model's internal feature dynamics using Temporal Sparse Autoencoders (T-SAE). Easy problems mainly reinforce direct-answer and basic-computation features while suppressing deliberative-reasoning features; hard problems activate reasoning-related features but become useful only when successful trajectories are sampled; medium-difficulty problems provide a more balanced signal, strengthening both computation and multi-step reasoning features. Motivated by these findings, we propose difficulty-adaptive strategies for hard-sample utilization, using backward-reasoning reformulation and T-SAE-guided training signals to improve reward density and credit assignment during RLVR. Overall, our results identify sample difficulty as a key factor governing both the optimization dynamics and representation evolution of RLVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
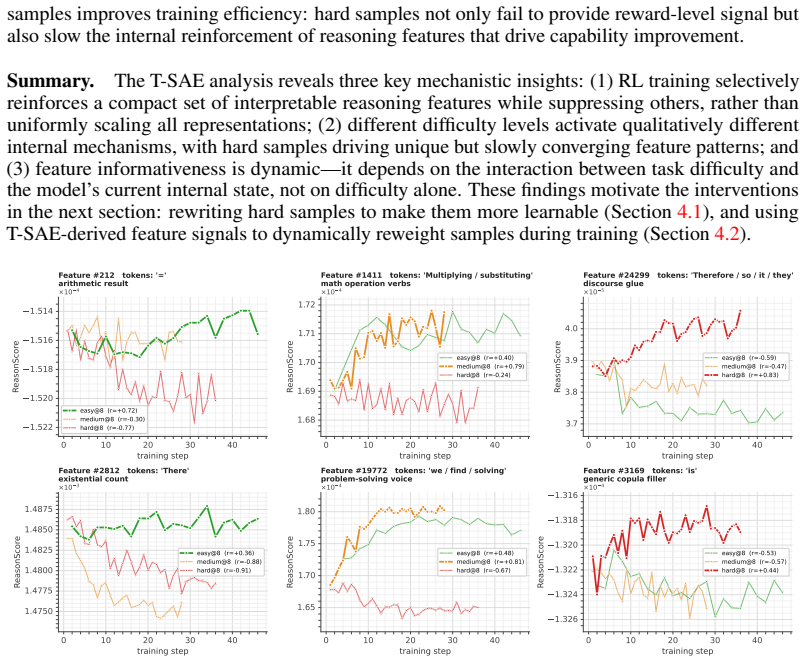
Summary. The manuscript examines the mechanistic role of sample difficulty in Reinforcement Learning with Verifiable Reward (RLVR) for enhancing reasoning in LLMs. It reports a non-monotonic effect: easy and medium-difficulty problems produce the strongest, most stable gains, while hard problems yield weak signals, induce degenerate behaviors (e.g., repetition or skipping computation), and can degrade prior capabilities. Temporal Sparse Autoencoders (T-SAE) are applied to track internal feature dynamics, revealing that easy problems reinforce direct-answer features while suppressing deliberative ones, hard problems activate reasoning features only on successful trajectories, and medium problems balance both. Motivated by these observations, difficulty-adaptive strategies (backward-reasoning reformulation and T-SAE-guided signals) are proposed to improve reward density and credit assignment.
Significance. If the central empirical claims hold after addressing confounds, the work would provide useful mechanistic insight into RLVR optimization dynamics and representation evolution, moving beyond aggregate performance metrics. The T-SAE analysis is a positive step toward interpretability of training trajectories. The proposed adaptive strategies, if validated, could inform practical improvements in reasoning-model training.
major comments (3)
- [Abstract and difficulty-classification section] The non-monotonic effect and degradation claims rest on the premise that the chosen difficulty bins accurately isolate learning-signal strength. If bins are defined via pre-training pass rates or model-specific success (as is common), they become entangled with the very capabilities RLVR is meant to improve; this risks making the observed degradation on hard samples an artifact of the labeling procedure rather than a property of the RLVR objective. A concrete test (e.g., re-binning by an independent difficulty measure or controlling for initial success rate) is needed in the difficulty-wise analysis section.
- [T-SAE feature-dynamics section] The T-SAE analysis reports differential reinforcement of “direct-answer,” “basic-computation,” and “deliberative-reasoning” features across difficulty levels. Without ablations against random or task-orthogonal feature sets, or controls for architecture/task-format confounds, these associations remain correlational; the claim that hard problems “activate reasoning-related features but become useful only when successful trajectories are sampled” therefore lacks the causal grounding required to support the mechanistic interpretation.
- [Proposed-strategies section] The proposed difficulty-adaptive strategies (backward-reasoning reformulation and T-SAE-guided training signals) are presented as remedies for weak reward density and poor credit assignment on hard samples. The manuscript must demonstrate, via controlled ablations, that these interventions improve outcomes beyond standard RLVR baselines and that any gains are not simply due to increased successful-trajectory sampling.
minor comments (2)
- Notation for T-SAE features and difficulty bins should be defined once in a dedicated subsection and used consistently thereafter.
- Figure captions for T-SAE activation plots should explicitly state the number of runs, seeds, and statistical tests used to support the reported feature-strength differences.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing clarifications on our methodology and committing to revisions that strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: [Abstract and difficulty-classification section] The non-monotonic effect and degradation claims rest on the premise that the chosen difficulty bins accurately isolate learning-signal strength. If bins are defined via pre-training pass rates or model-specific success (as is common), they become entangled with the very capabilities RLVR is meant to improve; this risks making the observed degradation on hard samples an artifact of the labeling procedure rather than a property of the RLVR objective. A concrete test (e.g., re-binning by an independent difficulty measure or controlling for initial success rate) is needed in the difficulty-wise analysis section.
Authors: We acknowledge the risk of entanglement when difficulty is defined via model-specific success rates. In the current manuscript, bins were constructed from pass rates on a held-out validation set using the base model prior to RLVR training. To directly address the concern, we will add a re-binning analysis using an independent difficulty proxy (problem statement length combined with expert-annotated reasoning-step count) and report results controlling for initial success rate in the revised difficulty-wise section. This will help confirm that the non-monotonic pattern reflects properties of the RLVR objective rather than labeling artifacts. revision: yes
-
Referee: [T-SAE feature-dynamics section] The T-SAE analysis reports differential reinforcement of “direct-answer,” “basic-computation,” and “deliberative-reasoning” features across difficulty levels. Without ablations against random or task-orthogonal feature sets, or controls for architecture/task-format confounds, these associations remain correlational; the claim that hard problems “activate reasoning-related features but become useful only when successful trajectories are sampled” therefore lacks the causal grounding required to support the mechanistic interpretation.
Authors: The T-SAE results are observational and track temporal feature activation aligned with behavioral trajectories. We agree that stronger causal evidence requires additional controls. In revision we will include ablations that compare observed feature dynamics against (i) randomly initialized feature sets and (ii) features extracted from a task-orthogonal auxiliary model, plus controls for prompt format. These will be reported alongside the existing dynamics to better support the mechanistic claims. revision: yes
-
Referee: [Proposed-strategies section] The proposed difficulty-adaptive strategies (backward-reasoning reformulation and T-SAE-guided training signals) are presented as remedies for weak reward density and poor credit assignment on hard samples. The manuscript must demonstrate, via controlled ablations, that these interventions improve outcomes beyond standard RLVR baselines and that any gains are not simply due to increased successful-trajectory sampling.
Authors: The strategies are motivated by the observed dynamics and we report preliminary gains in the current manuscript. However, the referee correctly notes that fuller controlled ablations are required. We will expand the experimental evaluation with (i) direct comparisons to standard RLVR, (ii) a variant that artificially increases successful-trajectory sampling without the adaptive reformulation or T-SAE signals, and (iii) metrics isolating reward density and credit assignment. These results will be added to demonstrate that improvements exceed those attributable to sampling alone. revision: yes
Circularity Check
No circularity; purely empirical analysis
full rationale
The paper reports experimental observations on RLVR training dynamics using difficulty bins and T-SAE feature tracking. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text. All claims rest on direct measurement of model behavior rather than any reduction to inputs by construction. This is the expected non-circular outcome for an observational study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Online difficulty filtering for reasoning oriented reinforcement learning
Sanghwan Bae, Jiwoo Hong, Min Young Lee, Hanbyul Kim, JeongYeon Nam, and Donghyun Kwak. Online difficulty filtering for reasoning oriented reinforcement learning. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 700–719, 2026
2026
-
[3]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009
2009
-
[4]
Temporal sparse autoencoders: Leveraging the sequential nature of language for interpretability
Usha Bhalla, Alex Oesterling, Claudio Mayrink Verdun, Himabindu Lakkaraju, and Flavio Calmon. Temporal sparse autoencoders: Leveraging the sequential nature of language for interpretability. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Hansen, Duo Peng, Yuhui Zhang, Alejandro Lozano, Min Woo Sun, Emma Lundberg, and Serena Yeung-Levy
James Burgess, Jan N. Hansen, Duo Peng, Yuhui Zhang, Alejandro Lozano, Min Woo Sun, Emma Lundberg, and Serena Yeung-Levy. Papersearchqa: Learning to search and reason over scientific papers with rlvr.arXiv preprint arXiv:2601.18207, 2026
-
[6]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence.arXiv preprint arXiv:2508.15260, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
I have covered all the bases here: Interpreting reasoning features in large language models via sparse autoencoders
Andrey V Galichin, Alexey Dontsov, Polina Druzhinina, Anton Razzhigaev, Oleg Rogov, Elena Tutubalina, and Ivan Oseledets. I have covered all the bases here: Interpreting reasoning features in large language models via sparse autoencoders. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30771–30779, 2026
2026
-
[9]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InInterna- tional Conference on Learning Representations, 2025
2025
-
[10]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
2024
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. Reinforce++: An efficient rlhf algorithm with robustness to both prompt and reward models.arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InInternational Conference on Learning Representations, 2024
2024
-
[14]
Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang. VCRL: Variance-based curriculum reinforcement learning for large language models.arXiv preprint arXiv:2509.19803, 2025. 11
-
[15]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Hajishirz...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Le, Myeongho Jeon, Kim Vu, Viet Dac Lai, and Eunho Yang
Thanh-Long V . Le, Myeongho Jeon, Kim Vu, Viet Dac Lai, and Eunho Yang. No prompt left behind: Exploiting zero-variance prompts in LLM reinforcement learning via entropy-guided advantage shaping. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[17]
Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
2022
-
[18]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 2024
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 2024
2024
-
[19]
QuestA: Expanding reasoning capacity in LLMs via question augmentation
Jiazheng Li, Hongzhou Lin, Hong Lu, Kaiyue Wen, Zaiwen Yang, Jiaxuan Gao, Yi Wu, and Jingzhao Zhang. QuestA: Expanding reasoning capacity in LLMs via question augmentation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models.arXiv preprint arXiv:2310.10505, 2023
-
[21]
Xiao Liang, Zhongzhi Li, Yeyun Gong, Yelong Shen, Ying Nian Wu, Zhijiang Guo, and Weizhu Chen. Beyond pass@1: Self-play with variational problem synthesis sustains rlvr.arXiv preprint arXiv:2508.14029, 2025
-
[22]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2.arXiv preprint arXiv:2408.05147, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
P^2O: Joint Policy and Prompt Optimization
Xinyu Lu, Kaiqi Zhang, Jinglin Yang, Boxi Cao, Yaojie Lu, Hongyu Lin, Min He, Xianpei Han, and Le Sun. P 2O: Joint policy and prompt optimization.arXiv preprint arXiv:2603.21877, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 2025
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, et al. Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 2025
2025
-
[28]
Bissyande, Haoye Tian, and Bach Le
Wenqiang Luo, Jacky Wai Keung, Boyang Yang, Jacques Klein, Tegawende F. Bissyande, Haoye Tian, and Bach Le. Unlocking llm repair capabilities through cross-language translation and multi-agent refinement, 2025. 12
2025
-
[29]
Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. InInternational Conference on Learning Representations, 2025
2025
-
[30]
Sparse autoencoder.CS294A Lecture notes, 72(2011):1–19, 2011
Andrew Ng et al. Sparse autoencoder.CS294A Lecture notes, 72(2011):1–19, 2011
2011
-
[31]
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning.arXiv preprint arXiv:2502.19634, 2025
-
[32]
Shubham Parashar, Shurui Gui, Xiner Li, Hongyi Ling, Sushil Vemuri, Blake Olson, Eric Li, Yu Zhang, James Caverlee, Dileep Kalathil, et al. Curriculum reinforcement learning from easy to hard tasks improves llm reasoning.arXiv preprint arXiv:2506.06632, 2025
-
[33]
Automatically interpreting millions of features in large language models
Gonçalo Santos Paulo, Alex Troy Mallen, Caden Juang, and Nora Belrose. Automatically interpreting millions of features in large language models. InInternational Conference on Machine Learning, pages 48393–48421. PMLR, 2025
2025
-
[34]
Near-Future Policy Optimization
Chuanyu Qin, Chenxu Yang, Qingyi Si, Naibin Gu, Dingyu Yao, Zheng Lin, Peng Fu, Nan Duan, and Jiaqi Wang. Near-future policy optimization.arXiv preprint arXiv:2604.20733, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Towards high data efficiency in reinforcement learning with verifiable reward
Xinyu Tang, Zhenduo Zhang, Yurou Liu, Xin Zhao, zujie wen, Zhiqiang Zhang, and JUN ZHOU. Towards high data efficiency in reinforcement learning with verifiable reward. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[39]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, et al. Reinforcement learning for reasoning in large language models with one training example.arXiv preprint arXiv:2504.20571, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Learn hard problems during RL with reference guided fine-tuning
Yangzhen Wu, Shanda Li, Zixin Wen, Xin Zhou, Ameet Talwalkar, Yiming Yang, Wenhao Huang, and Tianle Cai. Learn hard problems during RL with reference guided fine-tuning. arXiv preprint arXiv:2603.01223, 2026
-
[41]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, and Ping Luo. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Dcpo: Dynamic clipping policy optimization.arXiv preprint arXiv:2509.02333, 2025
Shihui Yang, Chengfeng Dou, Peidong Guo, Kai Lu, Qiang Ju, Fei Deng, and Rihui Xin. Dcpo: Dynamic clipping policy optimization.arXiv preprint arXiv:2509.02333, 2025
-
[44]
Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration
Zhicheng Yang, Zhijiang Guo, Yinya Huang, Yongxin Wang, Dongchun Xie, Hanhui Li, Yiwei Wang, Xiaodan Liang, and Jing Tang. Depth-breadth synergy in rlvr: Unlocking llm reasoning gains with adaptive exploration.arXiv preprint arXiv:2508.13755, 2026. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. MetaMath: Bootstrap your own mathematical questions for large language models. InInternational Conference on Learning Representations, 2024
2024
-
[46]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Wong, and Yu Cheng
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F. Wong, and Yu Cheng. ExGRPO: Learning to reason from experience. InInternational Conference on Learning Representations, 2026
2026
-
[50]
Scaf-GRPO: Scaffolded group relative policy optimization for enhancing LLM reasoning
Xichen Zhang, Sitong Wu, Yinghao Zhu, Haoru Tan, Shaozuo Yu, Ziyi He, and Jiaya Jia. Scaf-GRPO: Scaffolded group relative policy optimization for enhancing LLM reasoning. In International Conference on Learning Representations, 2026
2026
-
[51]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
AbsTopK: Rethinking sparse au- toencoders for bidirectional features
Xudong Zhu, Mohammad Mahdi Khalili, and Zhihui Zhu. AbsTopK: Rethinking sparse au- toencoders for bidirectional features. InInternational Conference on Learning Representations, 2026. 14 Appendix A Related Work Reinforcement Learning with Verifiable Reward.Reinforcement Learning from Verifiable Rewards has been proposed as a promising framework for enhanc...
2026
-
[54]
Calculate the total number of situps Shawna has done so far: \[ \text{Total situps done so far} = 12 + 19 = 31 \]
-
[55]
Therefore, she doesn ’t need to do any more situps on Wednesday to meet her goal
Since Shawna’s goal is 30 situps, she has already exceeded her goal by 1 situp. Therefore, she doesn ’t need to do any more situps on Wednesday to meet her goal. However, if we interpret the problem as finding out how many situps she would need to do on Wednesday to make up for the ones she didn’t do (which is not possible since she has already exceeded h...
-
[56]
\boxed{{{situps_needed_wednesday}}}
The number of situps Shawna needs to do on Wednesday to make up for the ones she didn’t do is: \[ \text{Situps needed on Wednesday} = 30 - (12 + 19) = 30 - 31 = -1 \] Since it’s not possible to do a negative number of situps, the answer is 0. Let’s confirm this with Python code. ‘‘‘python # Shawna’s goal goal = 30 # Situps done on Monday and Tuesday situp...
-
[57]
Henry takes 9 pills a day for 14 days, so the total number of pills he takes is \(9 \times 14 = 126\)
-
[58]
Out of these 9 pills, 4 pills cost $1.50 each, and the other 5 pills cost $1.50 + $5.50 = $7.00 each
-
[59]
The total cost for the 4 pills is \(4 \times 1.50 = 6.00\)
-
[60]
The total cost for the 5 pills is \(5 \times 7.00 = 35.00\)
-
[61]
The total cost for the 9 pills is \(6.00 + 35.00 = 41.00\)
-
[62]
\boxed{{{int(total_cost)}}}
Since Henry takes these 9 pills every day for 14 days, the total cost for all the pills is \(41.00 \ times 14 = 574.00\). Now, let’s write the Python code to verify this calculation. ‘‘‘python # Number of pills per day 18 pills_per_day = 9 # Number of days days = 14 # Cost of 4 pills cost_4_pills = 4 * 1.50 # Cost of 5 pills cost_5_pills = 5 * (1.50 + 5.5...
-
[63]
With 3 foxes, the total number of weasels caught per week is \(3 \times 4 = 12\) weasels, and the total number of rabbits caught per week is \(3 \ times 2 = 6\) rabbits
Each fox catches 4 weasels and 2 rabbits per week. With 3 foxes, the total number of weasels caught per week is \(3 \times 4 = 12\) weasels, and the total number of rabbits caught per week is \(3 \ times 2 = 6\) rabbits
-
[64]
Over 3 weeks, the total number of weasels caught is \(12 \times 3 = 36\) weasels, and the total number of rabbits caught is \(6 \times 3 = 18\) rabbits
-
[65]
The initial number of weasels is 100, so after 3 weeks, the number of weasels left is \(100 - 36 = 64\)
-
[66]
The initial number of rabbits is 50, so after 3 weeks, the number of rabbits left is \(50 - 18 = 32\)
-
[67]
\boxed{{{int(weasels_left)} {int(rabbits_left)}}}
The final answer should be boxed. Let’s implement this in Python to ensure the calculations are correct. ‘‘‘python # Initial number of weasels and rabbits initial_weasels = 100 initial_rabbits = 50 # Number of foxes and their catch rates foxes = 3 weasels_per_fox_per_week = 4 rabbits_per_fox_per_week = 2 # Total number of weasels and rabbits caught per we...
-
[68]
Calculate the total number of calories in the cake: \[ \text{Total calories in cake} = 8 \text{ slices} \times 347 \text{ calories/slice} \]
-
[69]
Calculate the total number of calories in the pan of brownies: \[ \text{Total calories in brownies} = 6 \text{ brownies} \times 375 \text{ calories/brownie} \]
-
[70]
\boxed{{{int(difference)}}}
Find the difference between the total number of calories in the cake and the total number of calories in the pan of brownies: \[ \text{Difference} = \text{Total calories in cake} - \text{Total calories in brownies} \] Let’s calculate this using Python code. ‘‘‘python # Calculate the total number of calories in the cake total_calories_cake = 8 * 347 # Calc...
-
[71]
So, \( T = A - 20 \)
Amaya scored 20 marks fewer in Maths than she scored in Arts. So, \( T = A - 20 \)
-
[72]
So, \( S = M + 10 \)
She scored 10 marks more in Social Studies than she got in Music. So, \( S = M + 10 \)
-
[73]
So, \( M = 70 \)
She scored 70 in Music. So, \( M = 70 \)
-
[74]
She scored \( \frac{1}{10} \) less in Maths than in Arts. So, \( T = A - \frac{1}{10}A = \frac {9}{10}A \). Using the value of \( M \), we can find \( S \): \[ S = 70 + 10 = 80 \] Now, using the value of \( T \) and the relationship \( T = \frac{9}{10}A \), we can find \( A \): \[ A - 20 = \frac{9}{10}A \] \[ A - \frac{9}{10}A = 20 \] \[ \frac{1}{10}A = 2...
-
[75]
Suppose that a+ (1/b) and b+ (1/a) are the roots of the equationx 2 −px+q= 0
Let a and b be the roots of the equation x2 −mx+z= 0 . Suppose that a+ (1/b) and b+ (1/a) are the roots of the equationx 2 −px+q= 0. The value ofqis 9 2 . What is the value ofz? (Answer:2)
-
[76]
Suppose that a+ (z/b) and b+ (1/a) are the roots of the equationx 2 −px+q= 0
Let a and b be the roots of the equation x2 −mx+ 2 = 0 . Suppose that a+ (z/b) and b+ (1/a) are the roots of the equationx 2 −px+q= 0. The value ofqis 9 2 . What is the value ofz? (Answer:1)
-
[77]
Suppose that a+ (1/b) and b+ (z/a) are the roots of the equationx 2 −px+q= 0
Let a and b be the roots of the equation x2 −mx+ 2 = 0 . Suppose that a+ (1/b) and b+ (z/a) are the roots of the equationx 2 −px+q= 0. The value ofqis 9 2 . What is the value ofz? (Answer:1) FOBAR:
-
[78]
Suppose that a+ (1/b) and b+ (1/a) are the roots of the equation x2 −px+q= 0
Let a and b be the roots of the equation x2 −mx+z= 0 . Suppose that a+ (1/b) and b+ (1/a) are the roots of the equation x2 −px+q= 0 . What is q? If we know the answer to the above question is 9 2 , what is the value ofz? (Answer:2)
-
[79]
Suppose that a+ (z/b) and b+ (1/a) are the roots of the equation x2 −px+q= 0
Let a and b be the roots of the equation x2 −mx+ 2 = 0 . Suppose that a+ (z/b) and b+ (1/a) are the roots of the equation x2 −px+q= 0 . What is q? If we know the answer to the above question is 9 2 , what is the value ofz? (Answer:1)
-
[80]
Suppose that a+ (1/b) and b+ (z/a) are the roots of the equation x2 −px+q= 0
Let a and b be the roots of the equation x2 −mx+ 2 = 0 . Suppose that a+ (1/b) and b+ (z/a) are the roots of the equation x2 −px+q= 0 . What is q? If we know the answer to the above question is 9 2 , what is the value ofz? (Answer:1) G Limitations Our study has several limitations. First, our difficulty notion is empirical and policy-dependent. A hard@8 s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.