PixVOD: Pixel-Distributed Direct Visual Odometry and Depth Estimation
Pith reviewed 2026-06-28 10:13 UTC · model grok-4.3
The pith
Pixels can estimate camera motion and scene depth by exchanging Gaussian beliefs locally on the sensor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
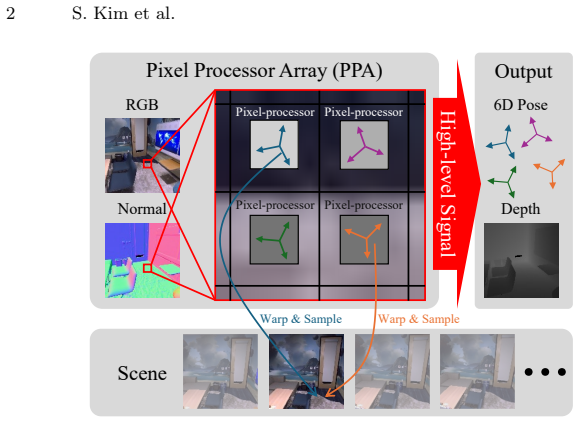
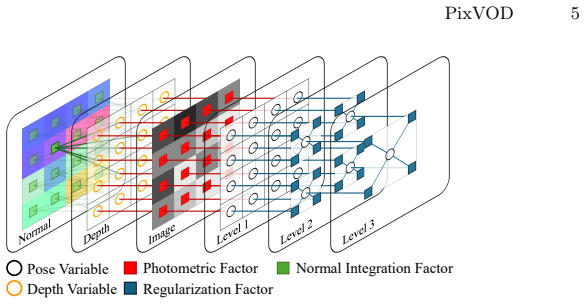
Gaussian Belief Propagation enables a fully parallelizable form of visual odometry and depth estimation across pixels, where sensor-processors exchange information to achieve consensus about camera motion and infer depth from per-pixel photometric observations and a surface normal prior, with keyframe-like anchoring regulating the effective baseline to maintain geometric stability.
What carries the argument
Gaussian Belief Propagation (GBP) messages exchanged between pixels for consensus on motion and depth, together with keyframe-like anchoring to control baseline.
Load-bearing premise
Gaussian Belief Propagation messages can be exchanged and converged efficiently inside focal-plane sensor-processors, and the surface normal prior plus photometric observations suffice to produce usable depth and motion estimates without external calibration or additional sensors.
What would settle it
A focal-plane hardware implementation where GBP messages fail to converge within frame timing or yield depth and motion estimates that diverge from ground truth on standard datasets.
Figures
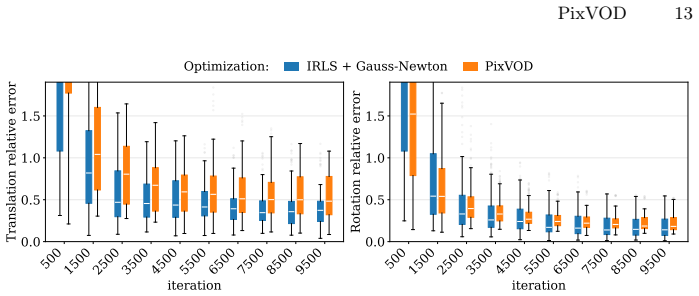
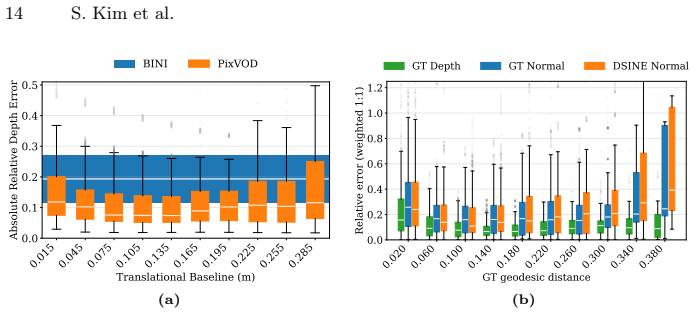
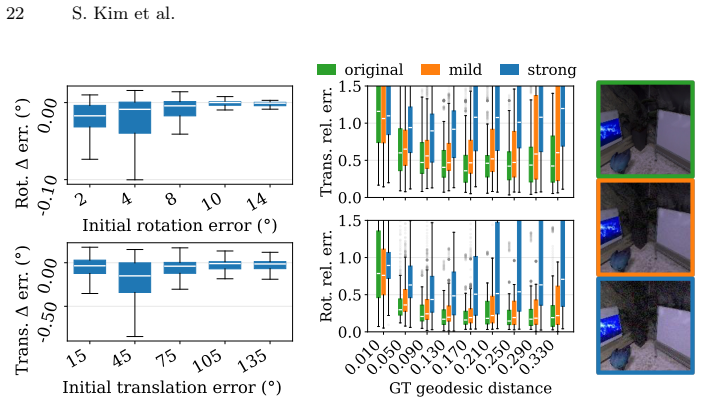
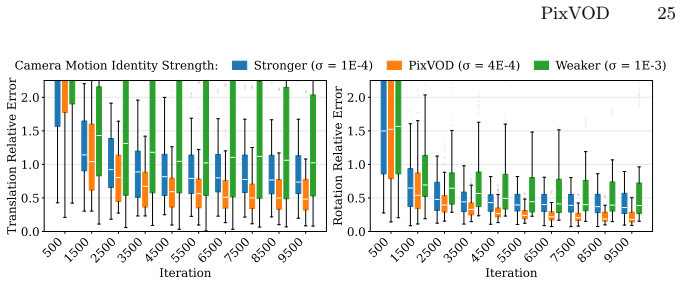
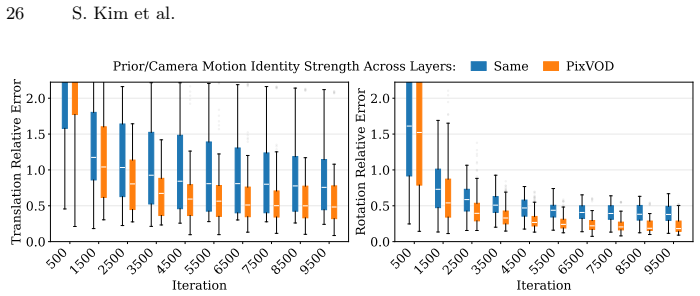
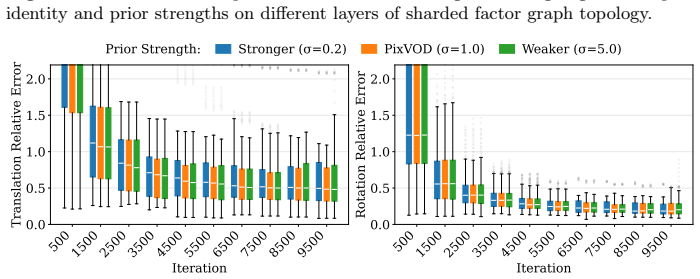
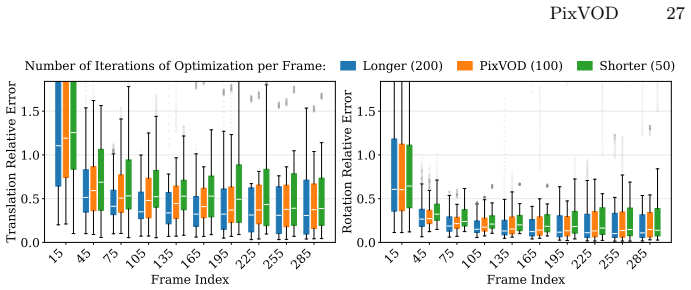
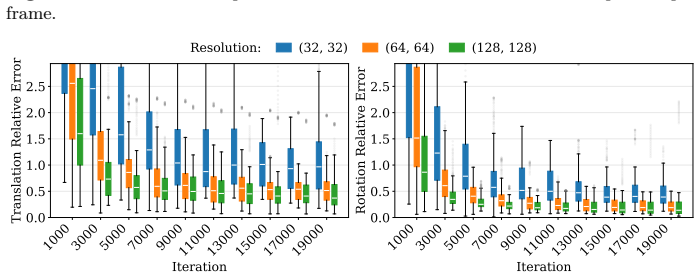
read the original abstract
Images composed of 2D pixel arrays are the standard input to computer vision algorithms, yet many underlying computations can be distributed across pixels. Transmitting raw, redundant, and noisy pixel data off the sensor remains inefficient, motivating a shift toward focal-plane sensor-processors that perform a significant part of the computation directly within each pixel. We envision pixels synthesizing higher-level signals locally, reducing downstream load, and providing richer inputs for higher-level vision tasks. We propose a fully parallelizable form of visual odometry and depth estimation across pixels, where sensor-processors exchange information through Gaussian Belief Propagation (GBP) to achieve consensus about camera motion and infer depth from per-pixel photometric observations and a surface normal prior. To maintain geometric stability during optimization, we introduce a keyframe-like anchoring mechanism that regulates the effective baseline between frames, enabling consistent motion and depth updates. Our method is evaluated on realistic datasets, demonstrating the feasibility of GBP-based pixel-level distributed odometry and depth estimation with keyframe anchoring on-sensor. Project Page: https://www.shinjeongkim.com/pixvod/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PixVOD, a fully parallelizable pixel-distributed direct visual odometry and depth estimation algorithm in which focal-plane sensor-processors exchange Gaussian Belief Propagation (GBP) messages to reach consensus on camera motion while inferring per-pixel depth from photometric observations and a surface normal prior. A keyframe-like anchoring mechanism is introduced to regulate effective baseline and maintain geometric stability. The method is evaluated on realistic datasets and presented as demonstrating feasibility of GBP-based on-sensor odometry and depth estimation.
Significance. If the distributed GBP formulation and anchoring mechanism can be shown to converge under realistic focal-plane constraints, the work would offer a concrete route toward reducing raw pixel data transmission by performing VO and depth inference locally. The simulation results on standard datasets provide an initial existence proof for the algorithmic construction, but the hardware-specific claims remain untested.
major comments (2)
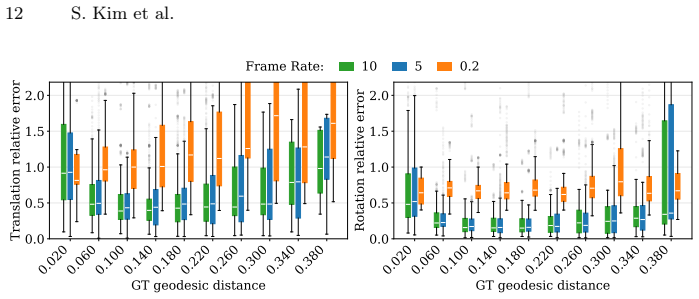
- [Evaluation section] Evaluation section (and abstract): the central claim that GBP message exchange enables on-sensor consensus about global camera motion is supported only by conventional software simulation on standard datasets; no experiments or analysis quantify communication topology, message volume per iteration, iteration count to convergence, bandwidth, or power limits of actual focal-plane sensor-processor arrays.
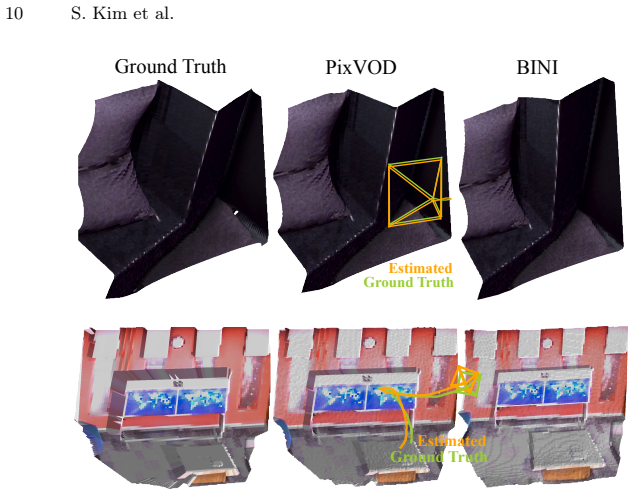
- [Method description] Method description (surface normal prior): the surface normal prior is taken as given per pixel, yet neither its acquisition cost nor its accuracy sensitivity is quantified with respect to the distributed GBP factors; this directly affects whether photometric observations plus the prior suffice without external calibration.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from an explicit statement of the assumed sensor-processor architecture (e.g., interconnect topology and per-pixel compute budget) to make the hardware feasibility claim concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of scope and assumptions in our simulation-based work. We respond point-by-point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): the central claim that GBP message exchange enables on-sensor consensus about global camera motion is supported only by conventional software simulation on standard datasets; no experiments or analysis quantify communication topology, message volume per iteration, iteration count to convergence, bandwidth, or power limits of actual focal-plane sensor-processor arrays.
Authors: We agree the evaluation uses conventional software simulation on standard datasets and does not report hardware-specific metrics such as power or bandwidth on physical focal-plane arrays. The manuscript presents an algorithmic construction and existence proof for distributed GBP-based VO and depth estimation. We will revise the abstract and evaluation section to explicitly qualify the simulation setting. We will also add analysis of the simulated GBP process, including iteration counts to convergence, per-iteration message volume, and communication topology statistics derived from the pixel grid. Direct hardware measurements remain outside the paper's scope. revision: partial
-
Referee: [Method description] Method description (surface normal prior): the surface normal prior is taken as given per pixel, yet neither its acquisition cost nor its accuracy sensitivity is quantified with respect to the distributed GBP factors; this directly affects whether photometric observations plus the prior suffice without external calibration.
Authors: The surface normal prior is supplied as a per-pixel factor in the GBP model. We will add a sensitivity study in the revised method and evaluation sections that perturbs the prior normals and reports resulting changes in depth and motion accuracy. We will also include a brief discussion of acquisition approaches (e.g., on-sensor estimation or auxiliary modalities) and their relation to the photometric factors. revision: yes
Circularity Check
No circularity: new algorithmic construction with independent evaluation
full rationale
The paper introduces a distributed GBP-based visual odometry and depth estimation method across pixels, with a novel keyframe-like anchoring mechanism for stability. The abstract and description present this as an original algorithmic proposal evaluated on realistic datasets, without any equations or steps that reduce predictions to fitted inputs by construction, self-definitional loops, or load-bearing self-citations that collapse the central claim. The surface normal prior and GBP consensus are treated as modeling choices with external validation via simulation results, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian Belief Propagation messages can be passed and converged on focal-plane hardware to reach consensus on camera motion and depth
- domain assumption Surface normal prior combined with per-pixel photometric observations is sufficient to infer depth
Reference graph
Works this paper leans on
-
[1]
Communications of the ACM54(10), 105–112 (2011)
Agarwal, S., Furukawa, Y., Snavely, N., Simon, I., Curless, B., Seitz, S.M., Szeliski, R.: Building rome in a day. Communications of the ACM54(10), 105–112 (2011)
2011
-
[2]
In: Fourth Swedish Workshop on Computer Systems Architecture (1992)
Ahlander, A., Svensson, B.: Floating point calculations in bit-serial simd comput- ers. In: Fourth Swedish Workshop on Computer Systems Architecture (1992)
1992
-
[3]
arXiv preprint arXiv:2406.09726 (2024)
Alzugaray, I., Murai, R., Davison, A.: Pixro: Pixel-distributed rotational odometry with gaussian belief propagation. arXiv preprint arXiv:2406.09726 (2024)
-
[4]
In: 2020 57th ACM/IEEE Design Automation Conference (DAC)
Asgari, B., Hadidi, R., Ghaleshahi, N.S., Kim, H.: Pisces: power-aware implemen- tation of slam by customizing efficient sparse algebra. In: 2020 57th ACM/IEEE Design Automation Conference (DAC). pp. 1–6. IEEE (2020)
2020
-
[5]
In: IEEE Conf
Bae, G., Davison, A.J.: Rethinking inductive biases for surface normal estimation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 9535–9545 (2024)
2024
-
[6]
Bishop, C.M., Nasrabadi, N.M.: Pattern recognition and machine learning, vol. 4. Springer (2006)
2006
-
[7]
In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R
Bochkovskiy, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S., Koltun, V.: Depth pro: Sharp monocular metric depth in less than a second. In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R. (eds.) Int. Conf. Learn. Represent. vol. 2025, pp. 75602–75637 (2025),https://proceedings.iclr.cc/paper_files/ paper/2025/file/bc8b2058fd96978a4146f18298c...
2025
-
[8]
In: 2016 26th Interna- tional Conference on Field Programmable Logic and Applications (FPL)
Boikos, K., Bouganis, C.S.: Semi-dense slam on an fpga soc. In: 2016 26th Interna- tional Conference on Field Programmable Logic and Applications (FPL). pp. 1–4. IEEE (2016)
2016
-
[9]
In: IEEE Conf
Bose, L., Chen, J., Dudek, P.: Descriptor-in-pixel: Point-feature tracking for pixel processor arrays. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5392–5400 (2025)
2025
-
[10]
In: IEEE Conf
Bose, L., Dudek, P., Carey, S.J., Chen, J.: Live demonstration: Scamp-7. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 3995–3996 (2023)
2023
-
[11]
Cao, X., Santo, H., Shi, B., Okura, F., Matsushita, Y.: Bilateral normal integration. In: Eur. Conf. Comput. Vis. pp. 552–567. Springer (2022)
2022
-
[12]
In: IEEE Conf
Cao, X., Shi, B., Okura, F., Matsushita, Y.: Normal integration via inverse plane fitting with minimum point-to-plane distance. In: IEEE Conf. Comput. Vis. Pat- tern Recog. pp. 2382–2391 (2021)
2021
-
[13]
In: 2013 symposium on VLSI circuits
Carey, S.J., Lopich, A., Barr, D.R., Wang, B., Dudek, P.: A 100,000 fps vision sen- sor with embedded 535gops/w 256×256 simd processor array. In: 2013 symposium on VLSI circuits. pp. C182–C183. IEEE (2013)
2013
-
[14]
Chatterjee, A., Govindu, V.M.: Efficient and robust large-scale rotation averaging. In: Int. Conf. Comput. Vis. pp. 521–528 (2013)
2013
-
[15]
In: IEEE Conf
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5828–5839 (2017)
2017
-
[16]
arXiv preprint arXiv:1910.14139 (2019) 16 S
Davison, A.J., Ortiz, J.: Futuremapping 2: Gaussian belief propagation for spatial ai. arXiv preprint arXiv:1910.14139 (2019) 16 S. Kim et al
-
[17]
Foundations and Trends®in Robotics6(1-2), 1–139 (2017)
Dellaert, F., Kaess, M., et al.: Factor graphs for robot perception. Foundations and Trends®in Robotics6(1-2), 1–139 (2017)
2017
-
[18]
In: IEEE Conf
DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised inter- est point detection and description. In: IEEE Conf. Comput. Vis. Pattern Recog. Worksh. pp. 224–236 (2018)
2018
-
[19]
IEEE Trans
Engel, J., Koltun, V., Cremers, D.: Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell.40(3), 611–625 (2017)
2017
-
[20]
In: 2017 International Conference on Field Programmable Technology (ICFPT)
Fang,W.,Zhang,Y.,Yu,B.,Liu,S.:Fpga-basedorbfeatureextractionforreal-time visual slam. In: 2017 International Conference on Field Programmable Technology (ICFPT). pp. 275–278. IEEE (2017)
2017
-
[21]
IEEE Transactions on Im- age Processing17(10), 1737–1754 (2008).https://doi.org/10.1109/TIP.2008
Foi, A., Trimeche, M., Katkovnik, V., Egiazarian, K.: Practical poissonian-gaussian noise modeling and fitting for single-image raw-data. IEEE Transactions on Im- age Processing17(10), 1737–1754 (2008).https://doi.org/10.1109/TIP.2008. 2001399
-
[22]
In: IEEE Conf
Guan, T., Wang, C., Liu, Y.H.: Neural markov random field for stereo matching. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5459–5469 (2024)
2024
-
[23]
Handa, A., Newcombe, R.A., Angeli, A., Davison, A.J.: Real-time camera tracking: When is high frame-rate best? In: Eur. Conf. Comput. Vis. pp. 222–235. Springer (2012)
2012
-
[24]
Heep, M., Zell, E.: An adaptive screen-space meshing approach for normal integra- tion. In: Eur. Conf. Comput. Vis. pp. 445–461. Springer (2024)
2024
-
[25]
International Journal of Computer Vision129(2), 517–547 (2021)
Jin, Y., Mishkin, D., Mishchuk, A., Matas, J., Fua, P., Yi, K.M., Trulls, E.: Image matching across wide baselines: From paper to practice. International Journal of Computer Vision129(2), 517–547 (2021)
2021
-
[26]
Trinity College Dublin5, 4 (2006)
Kavan, L., Collins, S., O’Sullivan, C., Zara, J.: Dual quaternions for rigid trans- formation blending. Trinity College Dublin5, 4 (2006)
2006
-
[27]
In: IEEE Conf
Kim, H., Jung, Y., Lee, S.: Discontinuity-preserving normal integration with aux- iliary edges. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 11915–11923 (2024)
2024
-
[28]
Krähenbühl, P., Koltun, V.: Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inform. Process. Syst.24(2011)
2011
-
[29]
IEEE Transactions on Circuits and Systems for Video Technology26(8), 1563–1577 (2015)
Lentaris, G., Stamoulias, I., Soudris, D., Lourakis, M.: Hw/sw codesign and fpga acceleration of visual odometry algorithms for rover navigation on mars. IEEE Transactions on Circuits and Systems for Video Technology26(8), 1563–1577 (2015)
2015
-
[30]
arXiv preprint arXiv:2505.04612 (2025)
Li, J., Wang, H., Irshad, M.Z., Vasiljevic, I., Walter, M.R., Guizilini, V.C., Shakhnarovich, G.: Fastmap: Revisiting structure from motion through first-order optimization. arXiv preprint arXiv:2505.04612 (2025)
-
[31]
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: Lightglue: Local feature matching at light speed. In: Int. Conf. Comput. Vis. pp. 17627–17638 (2023)
2023
-
[32]
In: IEEE Conf
Liu, S., Yu, Y., Pautrat, R., Pollefeys, M., Larsson, V.: 3d line mapping revisited. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21445–21455 (2023)
2023
-
[33]
Frontiers in Neuroscience16(2022)
Liu, Y., Bose, L., Fan, R., Dudek, P., Mayol-Cuevas, W.: On-sensor binarized CNN inference with dynamic model swapping in pixel processor arrays. Frontiers in Neuroscience16(2022)
2022
-
[34]
https://www.graphcore.ai/products/ipu
Ltd, G.: IPU Processors. https://www.graphcore.ai/products/ipu
-
[35]
In: 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE)
Mandal, D.K., Jandhyala, S., Omer, O.J., Kalsi, G.S., George, B., Neela, G., Rethi- nagiri, S.K., Subramoney, S., Hacking, L., Radford, J., et al.: Visual inertial odom- etry at the edge: A hardware-software co-design approach for ultra-low latency and power. In: 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE). pp. 960–963. IEEE (2...
2019
-
[36]
In: IEEE Conf
Mazur, K., Bae, G., Davison, A.J.: Superprimitive: Scene reconstruction at a prim- itive level. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 4979–4989 (2024)
2024
-
[37]
IEEE Robot
Murai, R., Alzugaray, I., Kelly, P.H., Davison, A.J.: Distributed simultaneous lo- calisation and auto-calibration using gaussian belief propagation. IEEE Robot. and Auto. Letters9(3), 2136–2143 (2024)
2024
-
[38]
IEEE Trans
Murai, R., Ortiz, J., Saeedi, S., Kelly, P.H., Davison, A.J.: A robot web for dis- tributed many-device localization. IEEE Trans. on Robotics40, 121–138 (2023)
2023
-
[39]
In: IEEE/RSJ Int
Murai, R., Saeedi, S., Kelly, P.H.: Bit-vo: Visual odometry at 300 fps using bi- nary features from the focal plane. In: IEEE/RSJ Int. Conf. on Intell. Robots and Systems. pp. 8579–8586. IEEE (2020)
2020
-
[40]
arXiv preprint arXiv:2311.14649 (2023)
Nabarro, S., Van Der Wilk, M., Davison, A.J.: Learning in deep factor graphs with gaussian belief propagation. arXiv preprint arXiv:2311.14649 (2023)
-
[41]
In: IEEE Conf
Nagata, J., Sekikawa, Y.: Tangentially elongated gaussian belief propagation for event-based incremental optical flow estimation. In: IEEE Conf. Comput. Vis. Pat- tern Recog. pp. 21940–21949 (2023)
2023
-
[42]
Newcombe, R.A., Lovegrove, S.J., Davison, A.J.: Dtam: Dense tracking and map- ping in real-time. In: Int. Conf. Comput. Vis. pp. 2320–2327. IEEE (2011)
2011
-
[43]
In: IEEE Int
Nikolic, J., Rehder, J., Burri, M., Gohl, P., Leutenegger, S., Furgale, P.T., Sieg- wart, R.: A synchronized visual-inertial sensor system with fpga pre-processing for accurate real-time slam. In: IEEE Int. Conf. Robot. Autom. pp. 431–437. IEEE (2014)
2014
-
[44]
arXiv preprint arXiv:2107.02308 (2021)
Ortiz, J., Evans, T., Davison, A.J.: A visual introduction to gaussian belief prop- agation. arXiv preprint arXiv:2107.02308 (2021)
-
[45]
In: IEEE Conf
Ortiz,J.,Pupilli,M.,Leutenegger,S.,Davison,A.J.:Bundleadjustmentonagraph processor. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 2416–2425 (2020)
2020
-
[46]
Pan, L., Baráth, D., Pollefeys, M., Schönberger, J.L.: Global structure-from-motion revisited. In: Eur. Conf. Comput. Vis. pp. 58–77. Springer (2024)
2024
-
[47]
In: IEEE Conf
Pataki, Z., Sarlin, P.E., Schönberger, J.L., Pollefeys, M.: Mp-sfm: Monocular sur- face priors for robust structure-from-motion. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21891–21901 (2025)
2025
-
[48]
Elsevier (2014)
Pearl, J.: Probabilistic reasoning in intelligent systems: networks of plausible in- ference. Elsevier (2014)
2014
-
[49]
Neural Networks2(6), 475–494 (1989)
Peterson, C., Hartman, E.: Explorations of the mean field theory learning algo- rithm. Neural Networks2(6), 475–494 (1989)
1989
-
[50]
In: IEEE Conf
Qi, X., Liao, R., Liu, Z., Urtasun, R., Jia, J.: Geonet: Geometric neural network for joint depth and surface normal estimation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 283–291 (2018)
2018
-
[51]
IEEE Trans
Qi, X., Liu, Z., Liao, R., Torr, P.H., Urtasun, R., Jia, J.: Geonet++: Iterative geometric neural network with edge-aware refinement for joint depth and surface normal estimation. IEEE Trans. Pattern Anal. Mach. Intell.44(2), 969–984 (2020)
2020
-
[52]
In: 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM)
Qin, S., Liu, Q., Yu, B., Liu, S.:π-ba: Bundle adjustment acceleration on embedded fpgas with co-observation optimization. In: 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM). pp. 100–108. IEEE (2019)
2019
-
[53]
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning featurematchingwithgraphneuralnetworks.In:IEEEConf.Comput.Vis.Pattern Recog. pp. 4938–4947 (2020)
2020
-
[54]
In: IEEE Conf
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 4104–4113 (2016) 18 S. Kim et al
2016
-
[55]
IEEE Robot
Scona, R., Matsuki, H., Davison, A.: From scene flow to visual odometry through local and global regularisation in markov random fields. IEEE Robot. and Auto. Letters7(2), 4299–4306 (2022)
2022
-
[56]
In: Proceedings of the 12th annual conference on Computer graphics and interactive techniques
Shoemake, K.: Animating rotation with quaternion curves. In: Proceedings of the 12th annual conference on Computer graphics and interactive techniques. pp. 245– 254 (1985)
1985
-
[57]
In: IEEE Conf
So, H.M., Bose, L., Dudek, P., Wetzstein, G.: Pixelrnn: in-pixel recurrent neural networks for end-to-end-optimized perception with neural sensors. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 25233–25244 (2024)
2024
-
[58]
A micro lie theory for state estimation in robotics,
Sola, J., Deray, J., Atchuthan, D.: A micro lie theory for state estimation in robotics. arXiv preprint arXiv:1812.01537 (2018)
-
[59]
The Replica Dataset: A Digital Replica of Indoor Spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al.: The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[60]
Sucar, E., Liu, S., Ortiz, J., Davison, A.J.: imap: Implicit mapping and positioning in real-time. In: Int. Conf. Comput. Vis. pp. 6229–6238 (2021)
2021
-
[61]
Teed, Z., Deng, J.: Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. Adv. Neural Inform. Process. Syst.34, 16558–16569 (2021)
2021
-
[62]
In: 2022 International Conference on Field-Programmable Technology (ICFPT)
Vemulapati, V., Chen, D.: Fslam: an efficient and accurate slam accelerator on soc fpgas. In: 2022 International Conference on Field-Programmable Technology (ICFPT). pp. 1–9. IEEE (2022)
2022
-
[63]
In: IEEE Conf
Wang, R., Xu, S., Dai, C., Xiang, J., Deng, Y., Tong, X., Yang, J.: Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5261–5271 (2025)
2025
-
[64]
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Adv. Neural Inform. Process. Syst.37, 21875–21911 (2024)
2024
-
[65]
In: IEEE/RSJ Int
Yi, B., Lee, M.A., Kloss, A., Martín-Martín, R., Bohg, J.: Differentiable factor graph optimization for learning smoothers. In: IEEE/RSJ Int. Conf. on Intell. Robots and Systems. pp. 1339–1345. IEEE (2021)
2021
-
[66]
In: IEEE Conf
Yu, Y., Liu, S., Pautrat, R., Pollefeys, M., Larsson, V.: Relative pose estimation through affine corrections of monocular depth priors. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 16706–16716 (2025)
2025
-
[67]
In: IEEE Conf
Yuan, W., Gu, X., Dai, Z., Zhu, S., Tan, P.: Neural window fully-connected crfs for monocular depth estimation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 3916–3925 (2022)
2022
-
[68]
IEEE Transactions on signal processing40(10), 2570–2583 (2002)
Zhang, J.: The mean field theory in em procedures for markov random fields. IEEE Transactions on signal processing40(10), 2570–2583 (2002)
2002
-
[69]
In: Robotics: Science and Systems
Zhang, Z., Suleiman, A.A., Carlone, L., Sze, V., Karaman, S.: Visual-inertial odom- etry on chip: An algorithm-and-hardware co-design approach. In: Robotics: Science and Systems. vol. 13. Robotics: Science and Systems (2017)
2017
-
[70]
In: 2024 International Conference on 3D Vision (3DV)
Zhu, Z., Peng, S., Larsson, V., Cui, Z., Oswald, M.R., Geiger, A., Pollefeys, M.: Nicer-slam: Neural implicit scene encoding for rgb slam. In: 2024 International Conference on 3D Vision (3DV). pp. 42–52. IEEE (2024)
2024
-
[71]
In: IEEE Conf
Zhu, Z., Peng, S., Larsson, V., Xu, W., Bao, H., Cui, Z., Oswald, M.R., Pollefeys, M.: Nice-slam: Neural implicit scalable encoding for slam. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 12786–12796 (2022)
2022
-
[72]
Zhuang, B., Cheong, L.F., Lee, G.H.: Baseline desensitizing in translation averag- ing. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 4539–4547 (2018) PixVOD 19 A Qualitative Results In the second part of the accompanying videopixvod.mp4, we demonstrate how the proposed method accumulates a trajectory in the Replica scene. Starting from the first frame a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.