StepPRM-RTL: Stepwise Process-Reward Guided LLM Fine-Tuning for Enhanced RTL Synthesis
Pith reviewed 2026-06-28 09:33 UTC · model grok-4.3
The pith
StepPRM-RTL improves LLM RTL code generation by using process rewards on each intermediate reasoning step instead of only the final result.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
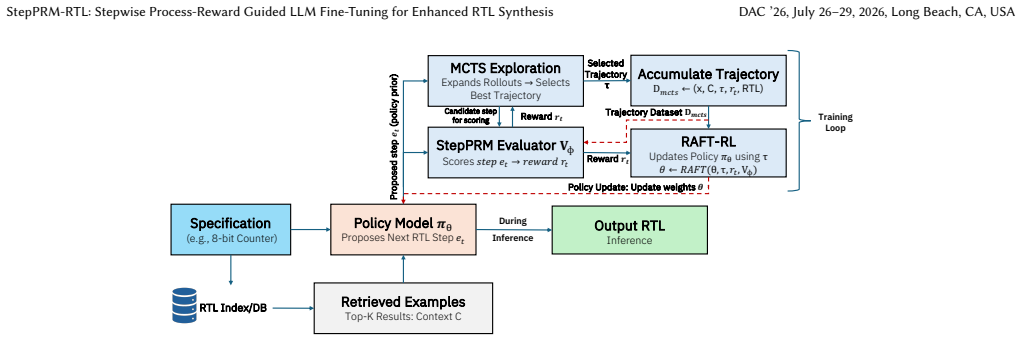
StepPRM-RTL constructs stepwise reasoning trajectories from canonical solutions, where each step contains a rationale and incremental code modification. A Process Reward Model evaluates intermediate steps to provide dense feedback that guides reinforcement-style updates during retrieval-augmented fine-tuning, with Monte Carlo Tree Search used to explore alternative paths. This yields over 10% improvements in functional correctness and reasoning fidelity on Verilog and VHDL benchmarks compared to prior methods.
What carries the argument
The Process Reward Model that scores the correctness of each partial reasoning step and code increment in a trajectory, supplying the dense reward signal for fine-tuning.
If this is right
- The model learns justifications for design choices, not just the choices themselves.
- Performance gains hold for both Verilog and VHDL without separate training.
- Monte Carlo Tree Search enriches the data with high-quality trajectories that standard fine-tuning misses.
- Long-horizon tasks benefit more because sparse final rewards are replaced by step-level guidance.
Where Pith is reading between the lines
- If the reward model can be trained once and reused, it could lower the cost of adapting to new design domains.
- The technique might extend to other code synthesis tasks that require multi-step planning, such as software or mechanical design.
- Interpretability improves because the scored steps make the model's reasoning traceable.
Load-bearing premise
The Process Reward Model can accurately judge the quality of intermediate steps and that those judgments lead to better overall code generation than training on final outcomes alone.
What would settle it
A controlled test where the same model is fine-tuned without the process reward model and shows no improvement or worse results on the functional correctness metrics.
Figures
read the original abstract
Automatic generation of RTL code for digital hardware designs remains challenging due to long-horizon reasoning, multi-step dependencies, and strict correctness constraints in Verilog and VHDL. We present StepPRM-RTL, a novel framework that combines stepwise trajectory modeling, process-reward modeling (PRM), and retrieval-augmented fine-tuning (RAFT) to enhance both the functional correctness and reasoning fidelity of LLM-based RTL code generation. StepPRM-RTL constructs stepwise reasoning trajectories from canonical solutions, where each step contains a rationale and incremental code modification. A Process Reward Model (PRM) evaluates intermediate steps, providing dense feedback that guides reinforcement-style updates during RAFT fine-tuning. Monte Carlo Tree Search (MCTS) explores alternative reasoning paths, enriching the training dataset with high-quality trajectories. This integration of stepwise and outcome-aware rewards allows the model to learn both how and why to construct correct RTL, improving long-horizon reasoning beyond standard supervised or outcome-based training. Experimental evaluation on benchmark Verilog and VHDL datasets demonstrates that StepPRM-RTL outperforms the best prior methods by over 10\% in functional correctness and reasoning fidelity metrics. Ablation studies confirm that the combination of PRM-guided rewards and stepwise trajectory exploration is key to its performance. StepPRM-RTL generalizes across RTL languages and provides a scalable framework for high-fidelity, interpretable code generation, establishing a new standard for LLM-assisted hardware design automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StepPRM-RTL, a framework that constructs stepwise reasoning trajectories from canonical RTL solutions, trains a Process Reward Model (PRM) to score intermediate steps, and applies PRM-guided retrieval-augmented fine-tuning (RAFT) augmented by Monte Carlo Tree Search (MCTS) to improve LLM performance on Verilog and VHDL code generation. The central claim is that this yields >10% gains in functional correctness and reasoning fidelity over prior methods on benchmark datasets, with ablations attributing the gains to the combination of PRM dense feedback and stepwise exploration.
Significance. If the performance claims and the assumption that the PRM supplies accurate, non-leaking dense signals hold after proper validation, the work would provide a concrete advance in process-supervised training for long-horizon code synthesis tasks. The explicit use of MCTS to enrich trajectories and the focus on both functional correctness and reasoning fidelity are positive elements that could influence subsequent work in hardware design automation.
major comments (2)
- [Abstract] Abstract: the claim that StepPRM-RTL 'outperforms the best prior methods by over 10% in functional correctness and reasoning fidelity metrics' is presented with no accompanying experimental results, tables, figures, dataset sizes, error bars, or statistical tests. This is load-bearing for the paper's primary contribution.
- [Abstract / implied methods] Framework and experimental description: no information is given on PRM label construction (human annotation vs. synthetic), inter-rater reliability, or any correlation between PRM scores and either human step-quality judgments or partial-code executability. Without such validation the assertion that PRM supplies useful dense feedback beyond outcome-only training cannot be assessed and directly affects the ablation claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the presentation of results and validation can be strengthened. We respond point-by-point to the major comments and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that StepPRM-RTL 'outperforms the best prior methods by over 10% in functional correctness and reasoning fidelity metrics' is presented with no accompanying experimental results, tables, figures, dataset sizes, error bars, or statistical tests. This is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract would benefit from greater specificity to make the central claim immediately verifiable. In the revised manuscript we will update the abstract to include concrete performance deltas on the primary benchmarks, reference the dataset sizes used, and add explicit pointers to the relevant tables, figures, and statistical details in the experimental section. revision: yes
-
Referee: [Abstract / implied methods] Framework and experimental description: no information is given on PRM label construction (human annotation vs. synthetic), inter-rater reliability, or any correlation between PRM scores and either human step-quality judgments or partial-code executability. Without such validation the assertion that PRM supplies useful dense feedback beyond outcome-only training cannot be assessed and directly affects the ablation claims.
Authors: The current manuscript describes trajectory construction from canonical solutions but does not detail PRM label provenance or provide validation metrics. We will revise the methods section to explicitly state that labels are generated synthetically from canonical solutions using outcome verification. We will also add a new subsection reporting (i) correlation between PRM scores and partial-code executability and (ii) a small-scale human study measuring agreement between PRM scores and step-quality judgments. These additions will directly bolster the ablation analysis. revision: yes
Circularity Check
No circularity: empirical ML framework with benchmark evaluation
full rationale
The paper describes a composite training pipeline (stepwise trajectories, PRM scoring, RAFT, MCTS) and reports performance gains on Verilog/VHDL benchmarks plus ablations. No equations, first-principles derivations, or uniqueness theorems appear in the supplied text. Claims rest on experimental outcomes rather than any reduction of a predicted quantity to a fitted input or self-citation chain. Standard self-citations of prior RLHF/PRM work are not load-bearing for the central empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Jason Blocklove, Siddharth Garg, Ramesh Karri, and Hammond Pearce. 2023. Chip-Chat: Challenges and Opportunities in Conversational Hardware Design. In2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD). IEEE, 1–6
2023
-
[4]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences.Advances in neural information processing systems30 (2017)
2017
-
[5]
Yonggan Fu, Yongan Zhang, Zhongzhi Yu, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, and Yingyan Celine Lin. 2023. GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models. In2023 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE
2023
-
[6]
Sagar Imambi, Kolla Bhanu Prakash, and GR Kanagachidambaresan. 2021. Py- Torch. InProgramming with TensorFlow: solution for edge computing applications. Springer, 87–104
2021
-
[7]
Marco Kemmerling, Daniel Lütticke, and Robert H Schmitt. 2024. Beyond games: a systematic review of neural Monte Carlo tree search applications.Applied Intelligence54, 1 (2024), 1020–1046
2024
-
[8]
Yao Lai, Jinxin Liu, Zhentao Tang, Bin Wang, Jianye Hao, and Ping Luo. 2023. ChiPFormer: transferable chip placement via offline decision transformer. In Proceedings of the 40th International Conference on Machine Learning (ICML), Vol. 202. PMLR, 18346–18364
2023
-
[9]
Qingyao Li, Xinyi Dai, Xiangyang Li, Weinan Zhang, Yasheng Wang, Ruiming Tang, and Yong Yu. 2025. CodePRM: Execution Feedback-enhanced Process Re- ward Model for Code Generation. InFindings of the Association for Computational Linguistics: ACL 2025
2025
- [10]
-
[11]
Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023. Ver- ilogEval: Evaluating Large Language Models for Verilog Code Generation. In2023 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE
2023
-
[12]
Shang Liu, Wenji Fang, Yao Lu, Jing Wang, Qijun Zhang, Hongce Zhang, and Zhiyao Xie. 2024. RTLCoder: Fully open-source and efficient LLM-assisted RTL code generation technique.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems(2024)
2024
-
[13]
OpenAI. 2024. ChatGPT. https://chatgpt.com/
2024
-
[14]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[15]
Maciej Świechowski, Konrad Godlewski, Bartosz Sawicki, and Jacek Mańdziuk
-
[16]
Artificial Intelligence Review56, 3 (2023), 2497–2562
Monte Carlo tree search: A review of recent modifications and applications. Artificial Intelligence Review56, 3 (2023), 2497–2562
2023
-
[17]
Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan- Gavitt, Ramesh Karri, and Siddharth Garg. 2024. VeriGen: A Large Language Model for Verilog Code Generation.ACM Transactions on Design Automation of Electronic Systems (TODAES)29, 3 (2024), 1–31
2024
-
[18]
Prashanth Vijayaraghavan, Apoorva Nitsure, Charles Mackin, Luyao Shi, Stefano Ambrogio, Arvind Haran, Viresh Paruthi, Ali Elzein, Dan Coops, David Beymer, et al. 2024. Chain-of-Descriptions: Improving Code LLMs for VHDL Code Gen- eration and Summarization. InProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD. 1–10
2024
- [19]
-
[20]
Ziyu Wan, Xidong Feng, Muning Wen, Stephen Marcus Mcaleer, Ying Wen, Weinan Zhang, and Jun Wang. 2024. AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training. InInternational Conference on Machine Learning. PMLR, 49890–49920
2024
-
[21]
Teixeira, Ke Wang, Caroline Trippel, and Alex Aiken
Anjiang Wei, Huanmi Tan, Tarun Suresh, Daniel Mendoza, Thiago S.F.X. Teixeira, Ke Wang, Caroline Trippel, and Alex Aiken. 2025. VeriCoder: Enhancing LLM- Based RTL Code Generation Through Functional Correctness Validation. InarXiv preprint arXiv:2504.15659
-
[22]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Yufan Ye, Ting Zhang, Wenbin Jiang, and Hua Huang. 2025. Process-Supervised Reinforcement Learning for Code Generation. InEMNLP
2025
- [24]
-
[25]
Tianjun Zhang, Shishir G Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E Gonzalez. 2024. RAFT: Adapting Language Model to Domain Specific RAG.CoRR(2024)
2024
-
[26]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Yang Zhao, Di Huang, Chongxiao Li, Pengwei Jin, Ziyuan Nan, Tianyun Ma, Lei Qi, Yansong Pan, Zhenxing Zhang, Rui Zhang, Xishan Zhang, Zidong Du, Qi Guo, Xing Hu, and Yunji Chen. 2024. CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization. arXiv:2407.10424 [cs.PL]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.